Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wskazówka
Ta treść jest fragmentem eBooka "Architektura mikrousług .NET dla konteneryzowanych aplikacji .NET", dostępnego na .NET Docs lub jako bezpłatny plik PDF do pobrania i czytania w trybie offline.

W systemach rozproszonych, takich jak aplikacje oparte na mikrousługach, istnieje stale obecne ryzyko częściowej awarii. Na przykład pojedyncza mikrousługa/kontener może zakończyć się niepowodzeniem lub może nie być dostępna do odpowiadania przez krótki czas albo jedna maszyna wirtualna lub serwer mogą ulec awarii. Ponieważ klienci i usługi są oddzielnymi procesami, usługa może nie odpowiadać w odpowiednim czasie na żądanie klienta. Usługa może być przeciążona i odpowiadać bardzo wolno na żądania lub po prostu nie być dostępna przez krótki czas z powodu problemów z siecią.
Rozważmy na przykład stronę Szczegóły zamówienia z przykładowej aplikacji eShopOnContainers. Jeśli mikrousługa składania zamówień nie odpowiada, gdy użytkownik próbuje przesłać zamówienie, nieprawidłowa implementacja procesu klienta (jak aplikacja internetowa MVC) — na przykład jeśli kod klienta miałby używać synchronicznych wywołań RPC bez limitu czasu — blokowałaby wątki w nieskończoność, czekając na odpowiedź. Oprócz tworzenia złego doświadczenia użytkownika każda nieodpowiadająca oczekiwanie zużywa lub blokuje wątek, a wątki są niezwykle cenne w wysoce skalowalnych aplikacjach. Jeśli istnieje wiele zablokowanych wątków, w końcu środowisko uruchomieniowe aplikacji może zabraknąć wątków. W takim przypadku aplikacja może stać się globalnie nieodpowiadająca zamiast częściowo nieodpowiadającej, co pokazano na rysunku 8-1.
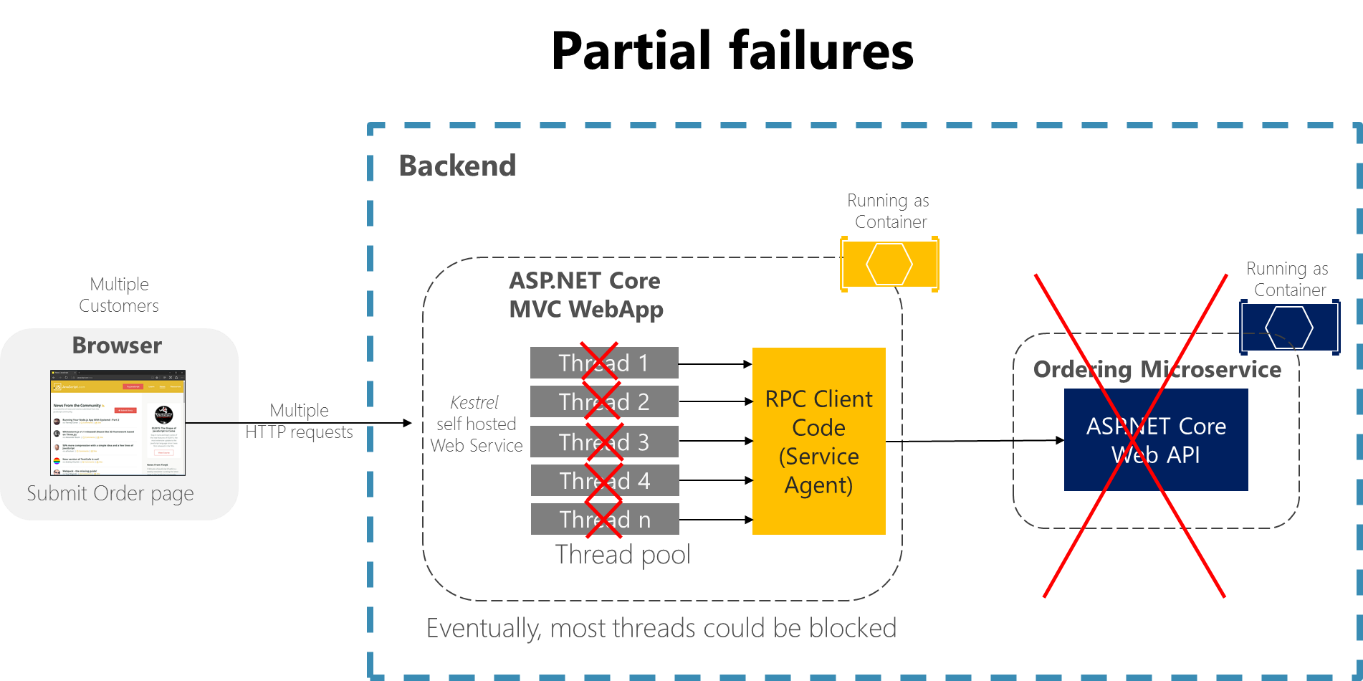
Rysunek 8–1. Częściowe błędy z powodu zależności, które wpływają na dostępność wątku usługi
W dużej aplikacji opartej na mikrousługach wszelkie częściowe awarie mogą zostać wzmocnione, zwłaszcza jeśli większość wewnętrznych interakcji mikrousług jest oparta na synchronicznych wywołaniach HTTP (co jest uważane za antywzór). Pomyśl o systemie, który odbiera miliony połączeń przychodzących dziennie. Jeśli system ma niedopracowany projekt oparty na rozległych łańcuchach synchronicznych wywołań HTTP, te wywołania przychodzące mogą prowadzić do powstania wielu milionów wywołań wychodzących (przyjmując stosunek 1:4) do kilkudziesięciu wewnętrznych jednostek mikroserwisowych jako zależności synchronicznych. Ta sytuacja jest pokazana na rysunku 8–2, zwłaszcza zależności nr 3, która uruchamia łańcuch, wywołując zależność 4, która następnie wywołuje #5.
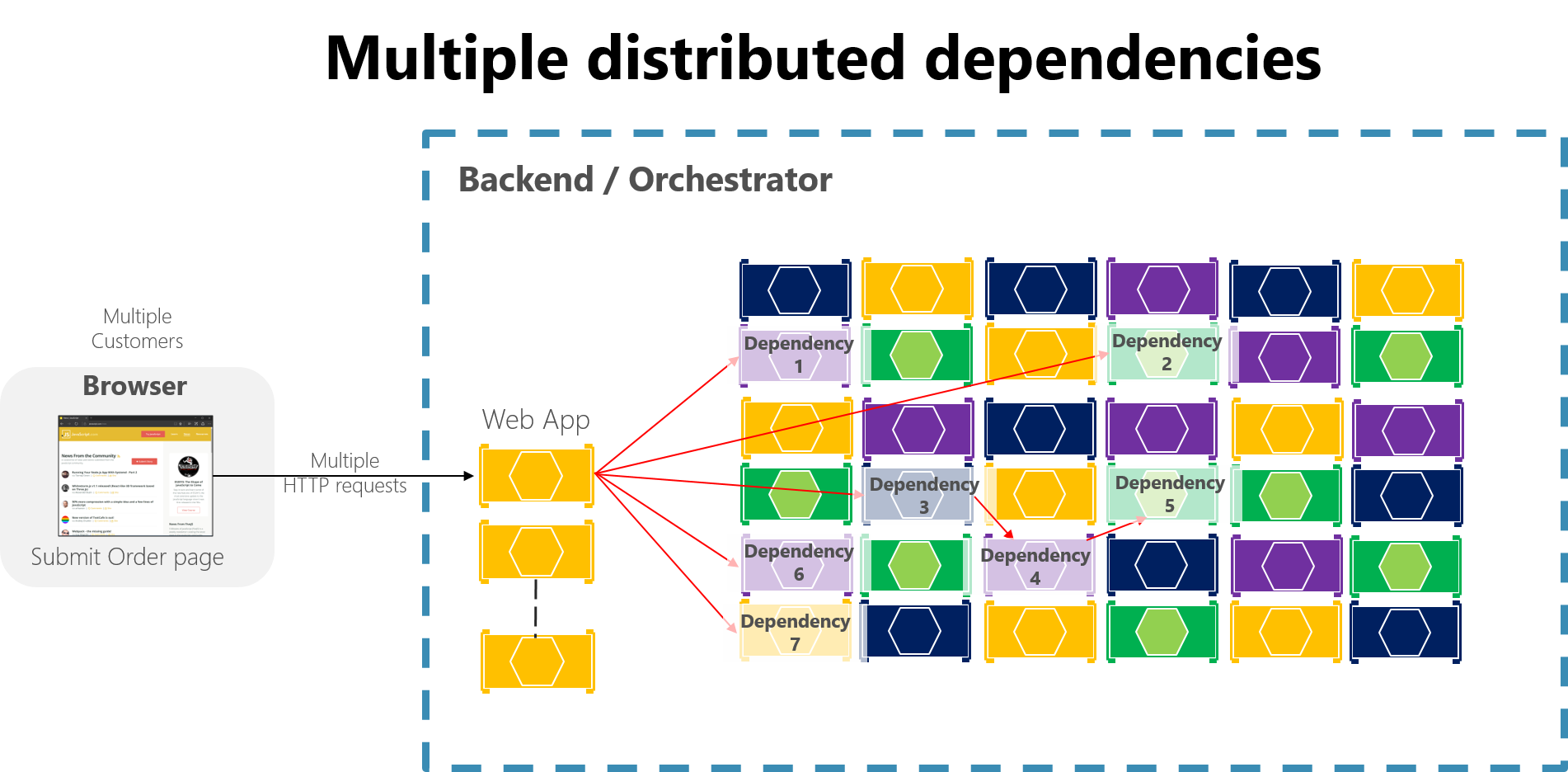
Rysunek 8–2. Wpływ nieprawidłowego projektu z długimi łańcuchami żądań HTTP
Sporadyczne awarie są nieuniknione w rozproszonym i opartym na chmurze systemie, nawet jeśli każda zależność ma wyższą dostępność. To fakt, który należy wziąć pod uwagę.
Jeśli nie projektujesz i implementujesz technik w celu zapewnienia odporności na awarie, nawet małe przestoje mogą się zwiększyć. Na przykład 50 zależności z 99,99% dostępności spowodowałoby kilka godzin przestoju każdego miesiąca z powodu tego efektu falowania. Gdy zależność mikrousługi zawiedzie przy obsłudze dużej liczby żądań, to niepowodzenie może szybko doprowadzić do nasycenia wszystkich dostępnych wątków w każdej usłudze i spowodować awarię całej aplikacji.
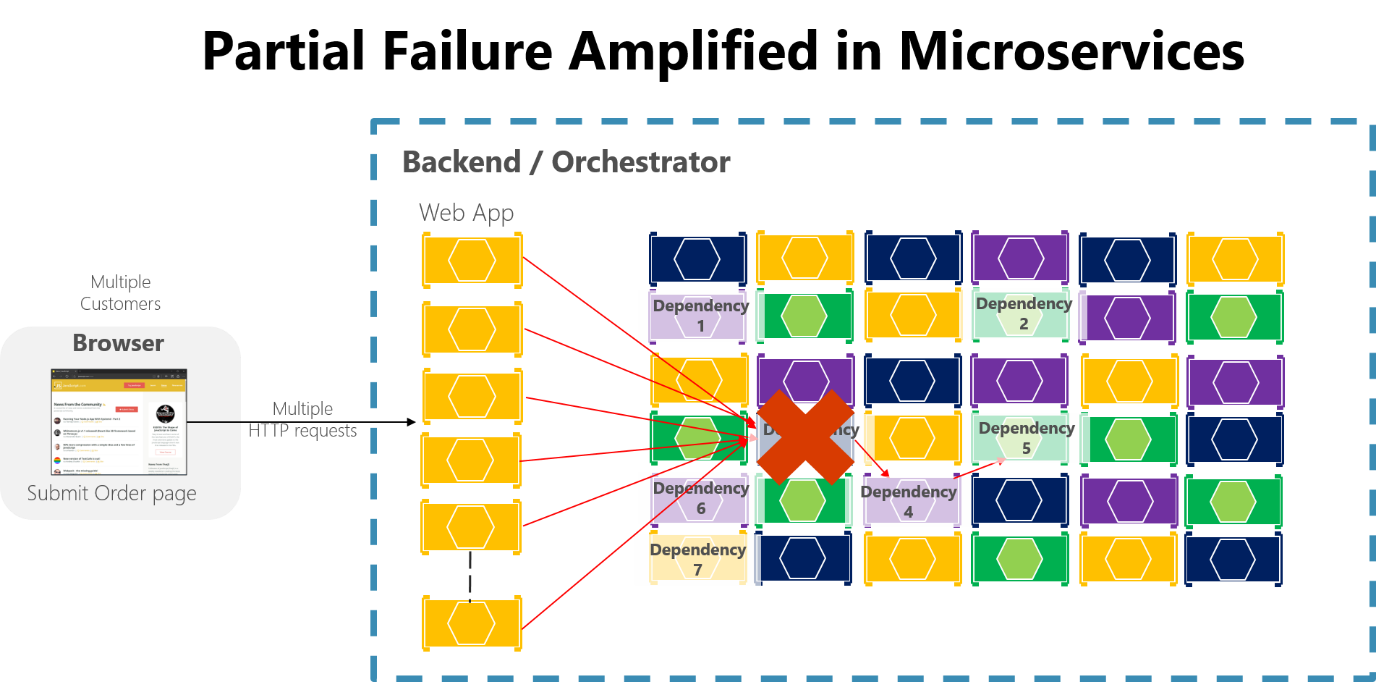
Rysunek 8–3. Częściowa awaria wzmocniona przez mikrousługi z długimi łańcuchami synchronicznych wywołań HTTP
Aby zminimalizować ten problem, w sekcji Asynchroniczna integracja mikrousług wymusza autonomię mikrousługi, ten przewodnik zachęca do korzystania z komunikacji asynchronicznej w ramach wewnętrznych mikrousług.
Ponadto niezbędne jest zaprojektowanie mikrousług i aplikacji klienckich w celu obsługi częściowych błędów — czyli tworzenia odpornych mikrousług i aplikacji klienckich.
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.