Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, jak utworzyć model wykrywania obiektów przy użyciu ML.NET Model Builder i usługi Azure Machine Learning w celu wykrywania i lokalizowania logowania się na obrazach.
Ten samouczek zawiera informacje na temat wykonywania następujących czynności:
- Przygotowywanie i zrozumienie danych
- Tworzenie pliku konfiguracji programu Model Builder
- Wybieranie scenariusza
- Wybieranie środowiska szkoleniowego
- Ładowanie danych
- Trenowanie modelu
- Ocena modelu
- Korzystanie z modelu na potrzeby przewidywań
Wymagania wstępne
Aby uzyskać listę wymagań wstępnych i instrukcji instalacji, zapoznaj się z przewodnikiem instalacji narzędzia Model Builder.
Omówienie wykrywania obiektów w programie Model Builder
Wykrywanie obiektów jest problemem z przetwarzaniem obrazów. Ściśle związane z klasyfikacją obrazów wykrywanie obiektów wykonuje klasyfikację obrazów na bardziej szczegółową skalę. Wykrywanie obiektów lokalizuje i kategoryzuje jednostki na obrazach. Modele wykrywania obiektów są często trenowane przy użyciu uczenia głębokiego i sieci neuronowych. Aby uzyskać więcej informacji, zobacz Uczenie głębokie a uczenie maszynowe .
Użyj wykrywania obiektów, gdy obrazy zawierają wiele obiektów różnych typów.

Niektóre przypadki użycia wykrywania obiektów obejmują:
- samochody Self-Driving
- Robotyka
- Wykrywanie twarzy
- Bezpieczeństwo w miejscu pracy
- Zliczanie obiektów
- Rozpoznawanie działań
Ten przykład tworzy aplikację konsolową platformy .NET Core w języku C#, która wykrywa zatrzymywanie logowania się obrazów przy użyciu modelu uczenia maszynowego utworzonego za pomocą narzędzia Model Builder. Kod źródłowy tego samouczka można znaleźć w repozytorium dotnet/machinelearning-samples GitHub.
Przygotowywanie i zrozumienie danych
Zestaw danych Stop Sign składa się z 50 obrazów pobranych z funkcji Unsplash, z których każdy zawiera co najmniej jeden znak zatrzymania.
Tworzenie nowego projektu VoTT
Pobierz zestaw danych przedstawiający 50 obrazów podpisywania i rozpakuj.
Pobierz narzędzie VoTT (Visual Object Tagging Tool).
Otwórz voTT i wybierz pozycję Nowy projekt.
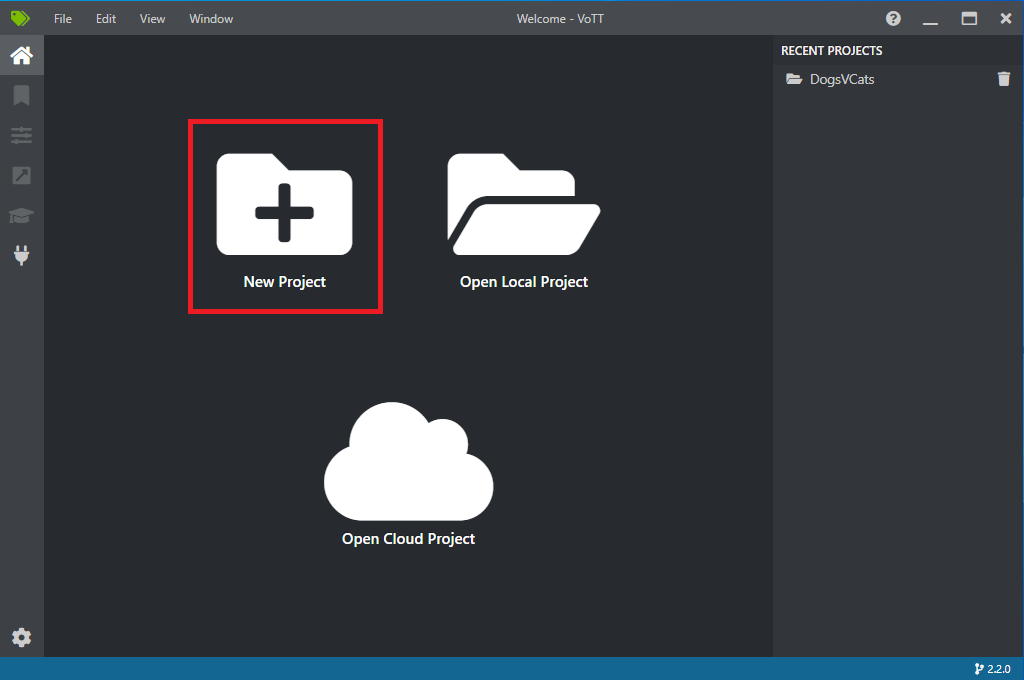
W obszarze Ustawienia projektu zmień nazwę wyświetlaną na "StopSignObjDetection".
Zmień token zabezpieczeń , aby wygenerować nowy token zabezpieczający.
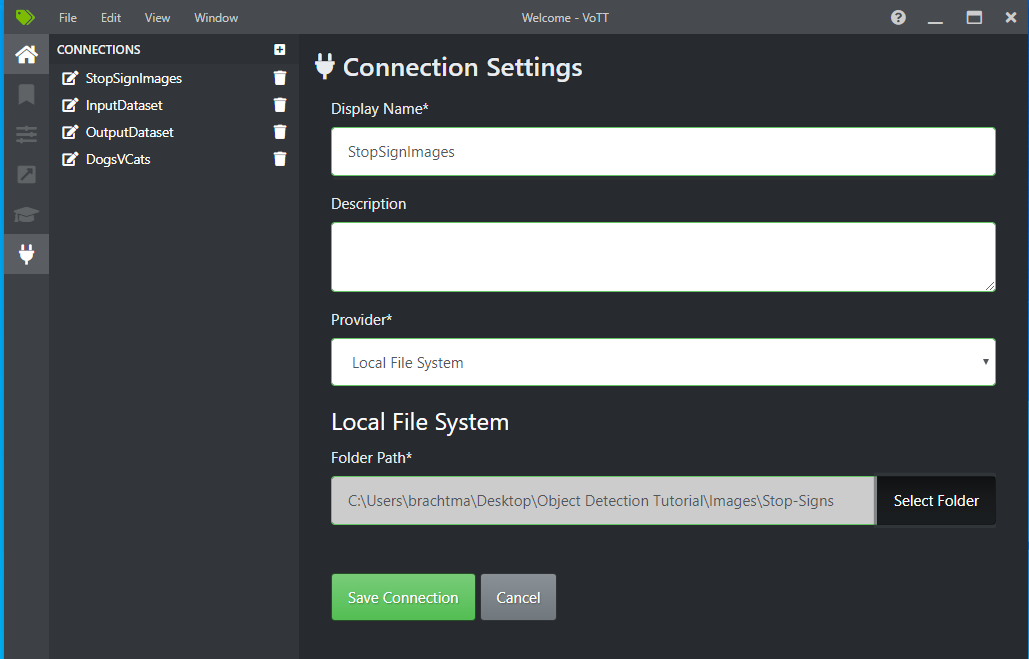
Obok pozycji Połączenie źródłowe wybierz pozycję Dodaj połączenie.
W obszarze Ustawienia połączenia zmień nazwę wyświetlaną połączenia źródłowego na "StopSignImages", a następnie wybierz pozycję Lokalny system plików jako dostawca. W polu Ścieżka folderu wybierz folder Stop-Signs zawierający 50 obrazów treningowych, a następnie wybierz pozycję Zapisz połączenie.
W obszarze Ustawienia projektu zmień połączenie źródłowe na StopSignImages (właśnie utworzone połączenie).
Zmień również połączenie docelowe na StopSignImages . Ustawienia projektu powinny teraz wyglądać podobnie do tego zrzutu ekranu:
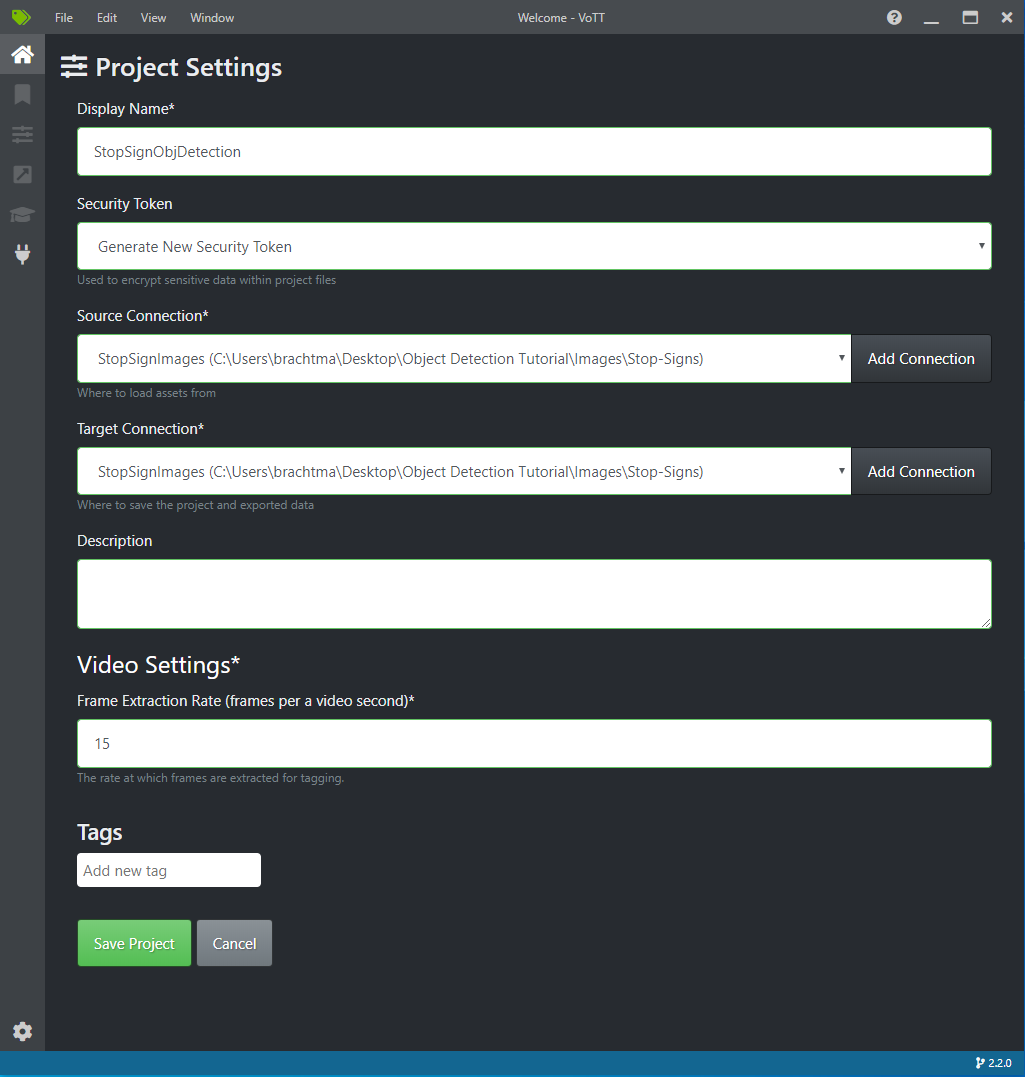
Wybierz pozycję Zapisz projekt.
Dodawanie tagów i obrazów etykiet
Powinno zostać wyświetlone okno z obrazami podglądu wszystkich obrazów treningowych po lewej stronie, podglądem wybranego obrazu w środku i kolumną Tagi po prawej stronie. Ten ekran jest edytorem tagów.
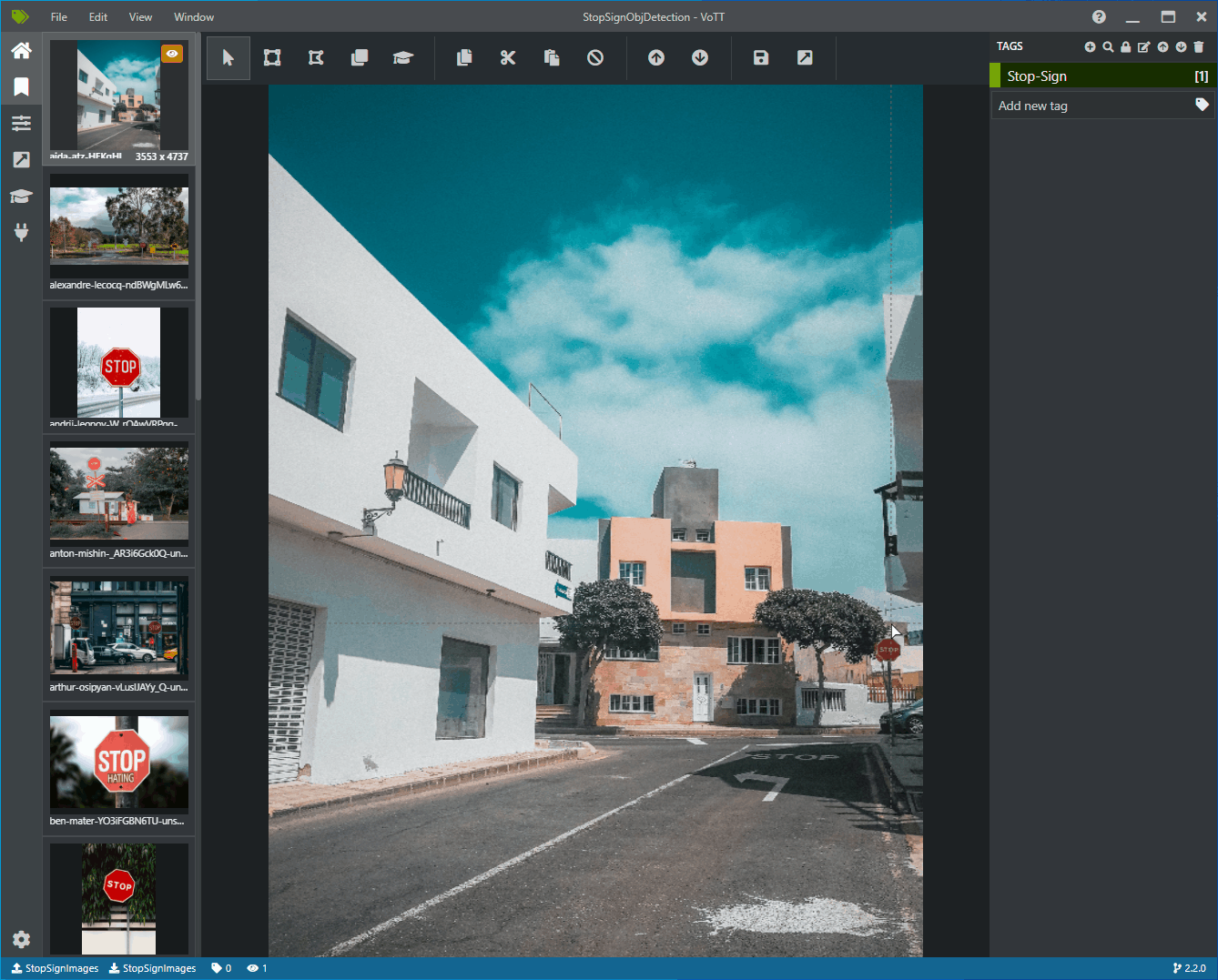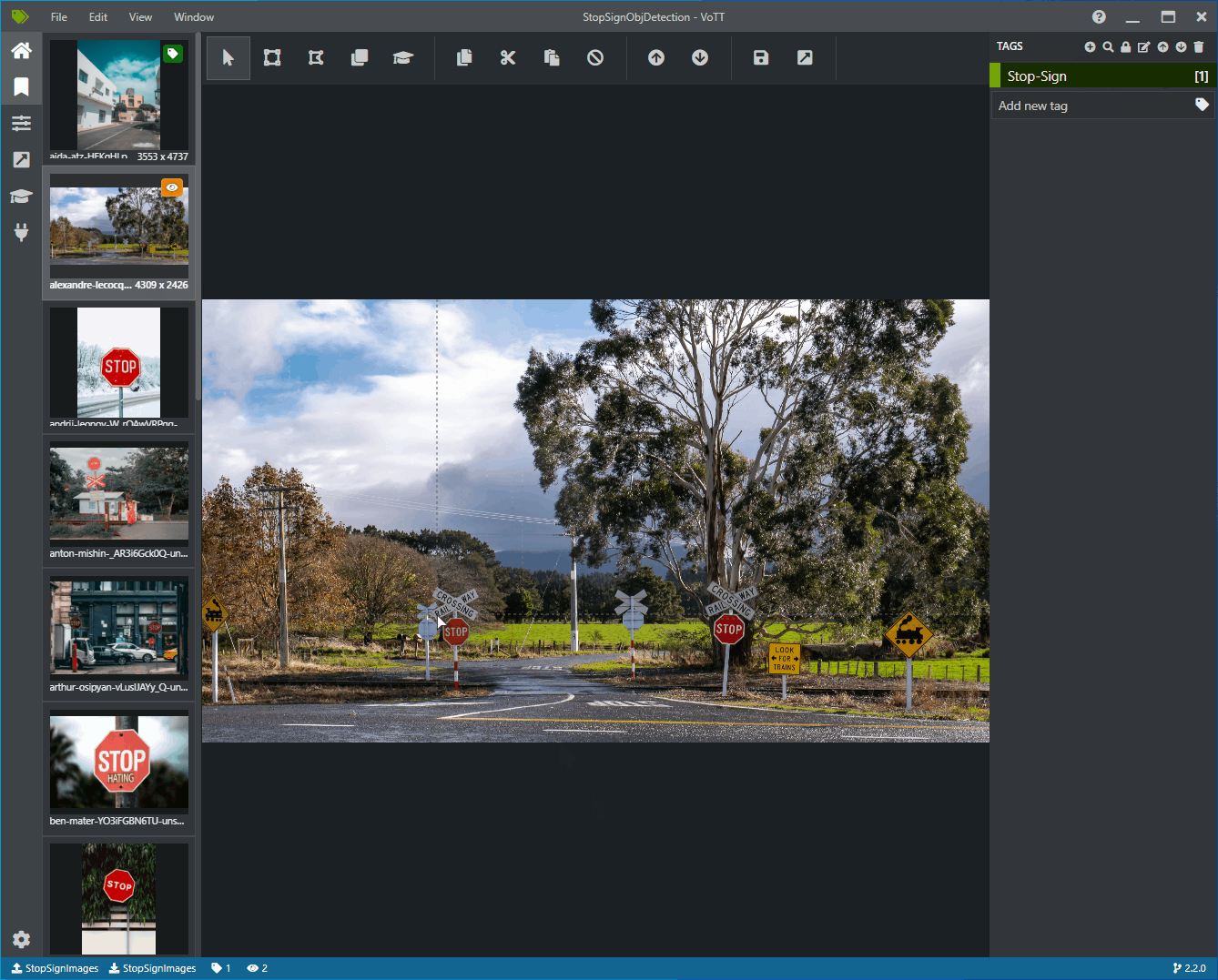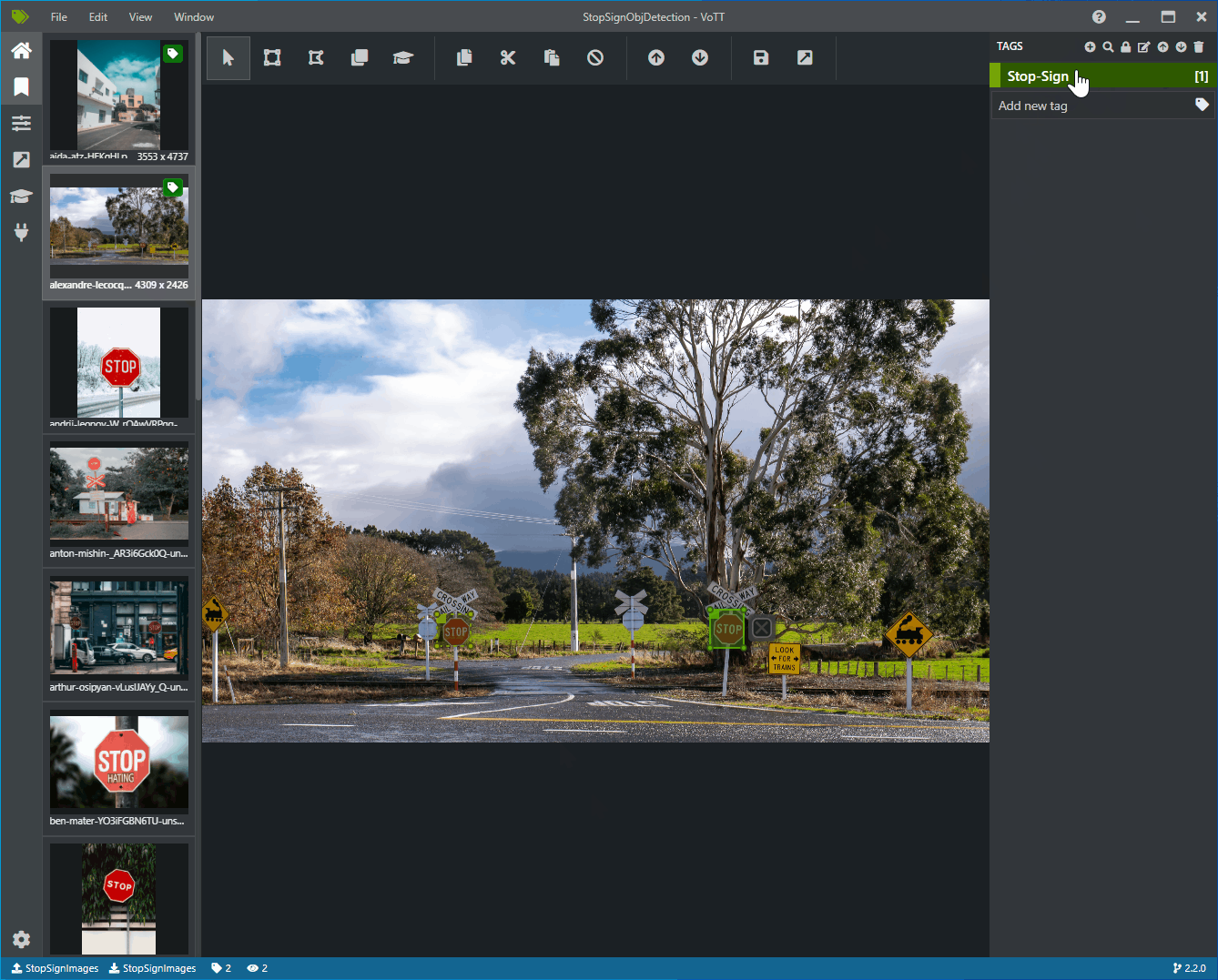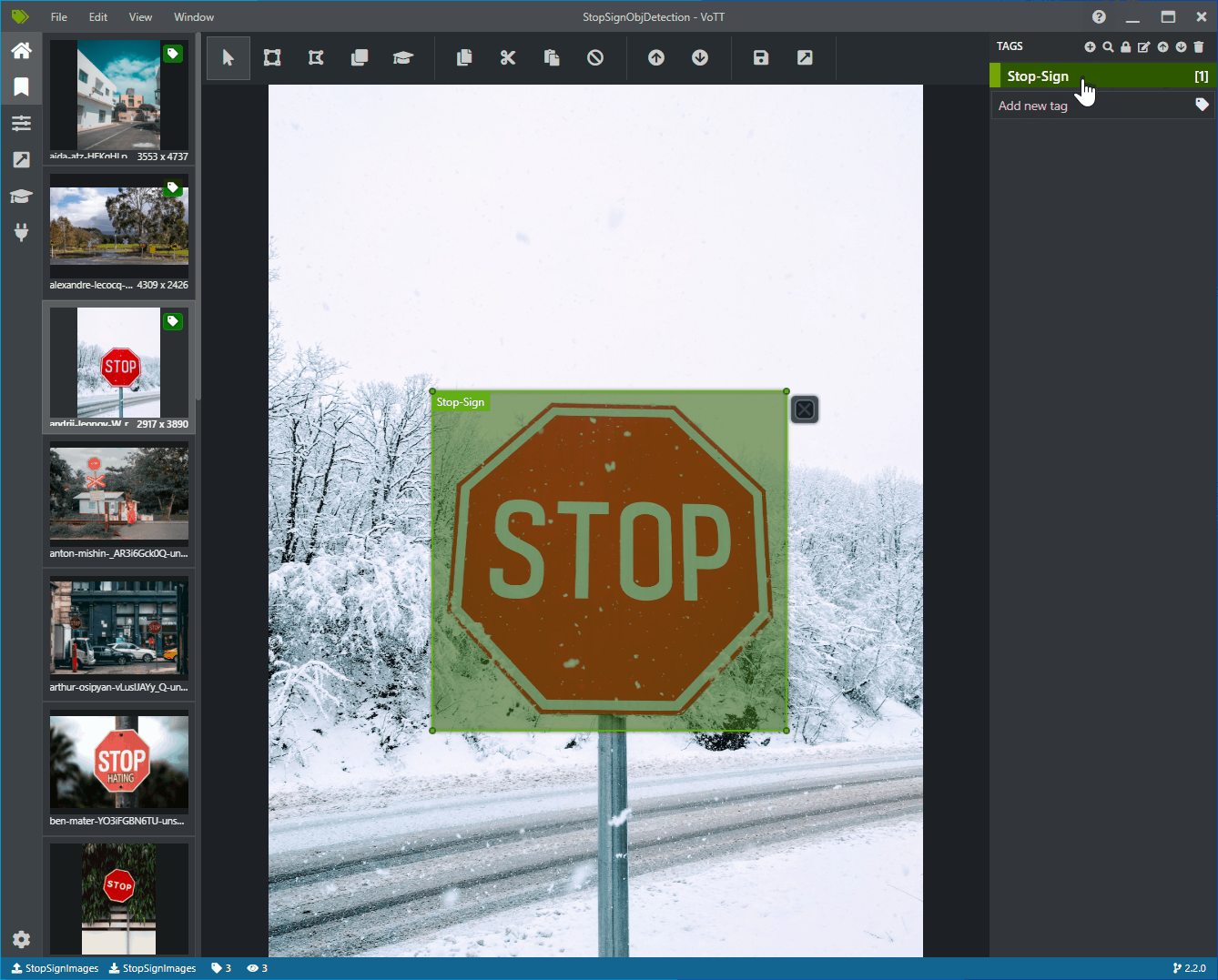
Wybierz pierwszą ikonę (w kształcie plusa) na pasku narzędzi Tagi , aby dodać nowy tag.

Nadaj tagowi nazwę "Stop-Sign" i naciśnij klawisz Enter na klawiaturze.

Kliknij i przeciągnij, aby narysować prostokąt wokół każdego znaku zatrzymania na obrazie. Jeśli kursor nie pozwala narysować prostokąta, spróbuj wybrać narzędzie Rysuj prostokąt z paska narzędzi u góry lub użyć skrótu klawiaturowego R.
Po rysunku prostokąta wybierz tag Stop-Sign utworzony w poprzednich krokach, aby dodać tag do pola ograniczenia.
Kliknij obraz podglądu dla następnego obrazu w zestawie danych i powtórz ten proces.
Wykonaj kroki od 3 do 4 dla każdego logowania zatrzymanego na każdym obrazie.
Eksportowanie pliku JSON voTT
Po oznaczeniu etykietą wszystkich obrazów szkoleniowych można wyeksportować plik, który będzie używany przez program Model Builder do trenowania.
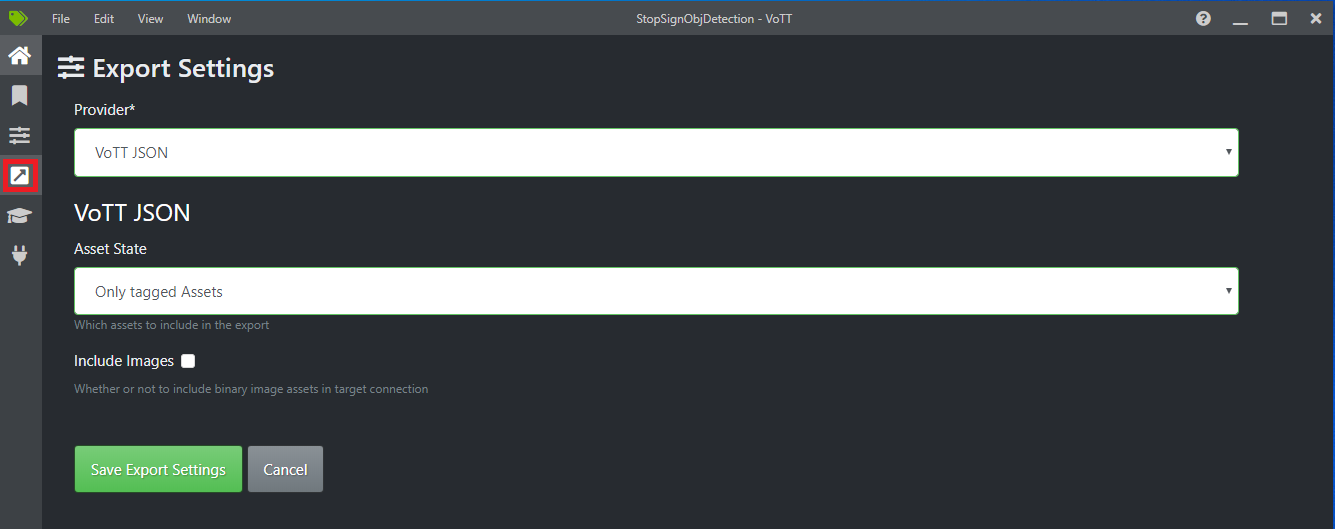
Wybierz czwartą ikonę na lewym pasku narzędzi (ta ze strzałką ukośną w polu), aby przejść do pozycji Ustawienia eksportu.
Pozostaw wartość Dostawca jako plik JSON VoTT.
Zmień stan zasobu na Tylko otagowane zasoby.
Usuń zaznaczenie pola wyboru Dołącz obrazy. Jeśli dołączysz obrazy, obrazy szkoleniowe zostaną skopiowane do wygenerowanego folderu eksportu, co nie jest konieczne.
Wybierz pozycję Zapisz ustawienia eksportu.
Wstecz do edytora Tagi (druga ikona na lewym pasku narzędzi w kształcie wstążki). Na górnym pasku narzędzi wybierz ikonę Eksportuj projekt (ostatnia ikona w kształcie strzałki w polu) lub użyj skrótu klawiaturowego Ctrl+E.

Ten eksport spowoduje utworzenie nowego folderu o nazwie vott-json-export w folderze Stop-Sign-Images i wygeneruje plik JSON o nazwie StopSignObjDetection-export w tym nowym folderze. Ten plik JSON zostanie użyty w następnych krokach do trenowania modelu wykrywania obiektów w narzędziu Model Builder.
Tworzenie aplikacji konsolowej
W programie Visual Studio utwórz aplikację konsolową platformy .NET Core w języku C# o nazwie StopSignDetection.
mbconfig Tworzenie pliku
- W Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt StopSignDetection, a następnie wybierz pozycję Dodaj>model uczenia maszynowego... aby otworzyć interfejs użytkownika konstruktora modeli.
- W oknie dialogowym nadaj projektowi Model Builder nazwę StopSignDetection, a następnie kliknij przycisk Dodaj.
Wybieranie scenariusza
W tym przykładzie scenariusz jest wykrywaniem obiektów. W kroku Scenariusz konstruktora modelu wybierz scenariusz wykrywania obiektów .
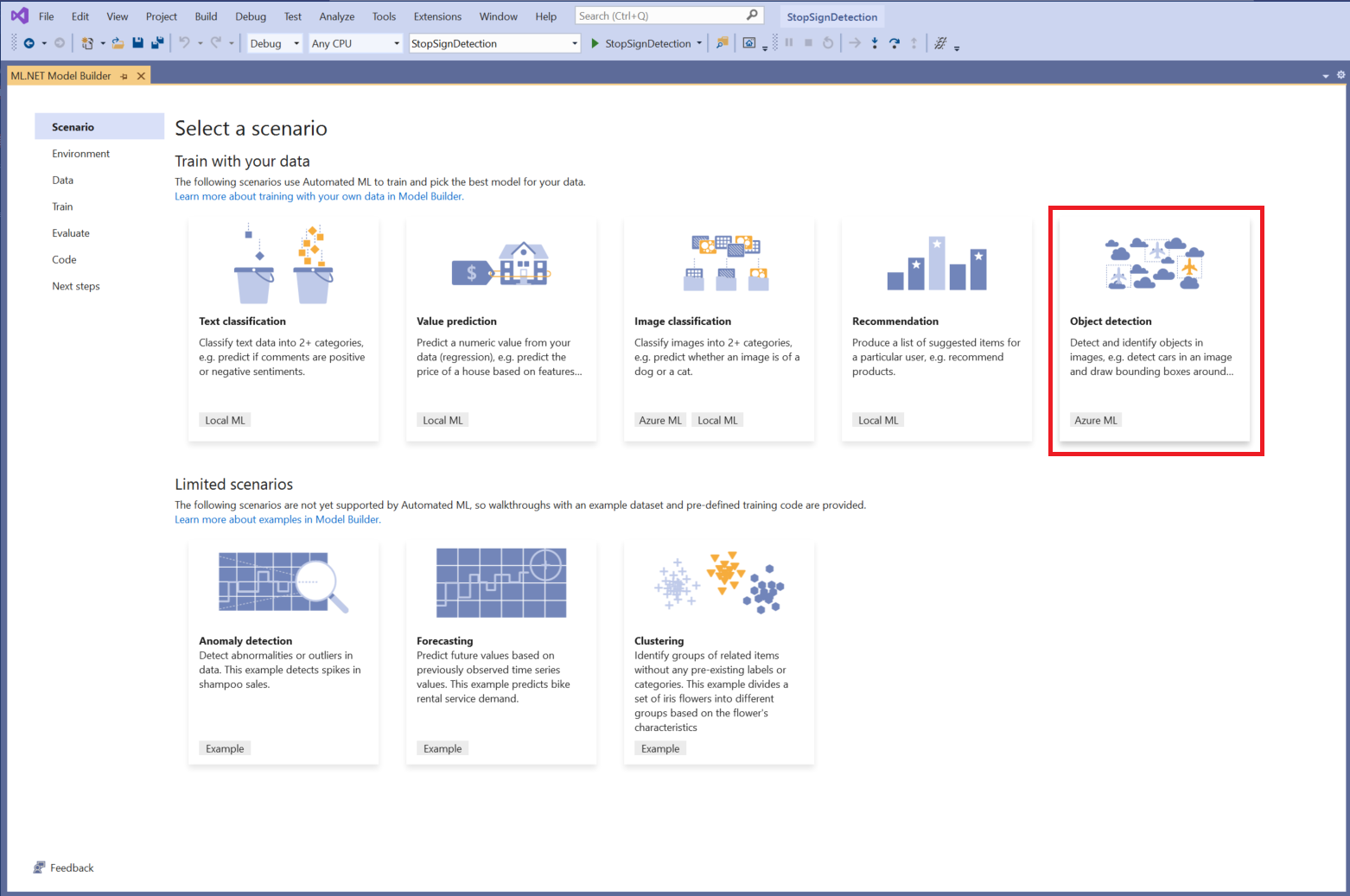
Jeśli na liście scenariuszy nie widzisz pozycji Wykrywanie obiektów , może być konieczne zaktualizowanie wersji programu Model Builder.
Wybieranie środowiska szkoleniowego
Obecnie narzędzie Model Builder obsługuje trenowanie modeli wykrywania obiektów tylko za pomocą usługi Azure Machine Learning, więc środowisko szkoleniowe platformy Azure jest domyślnie wybierane.
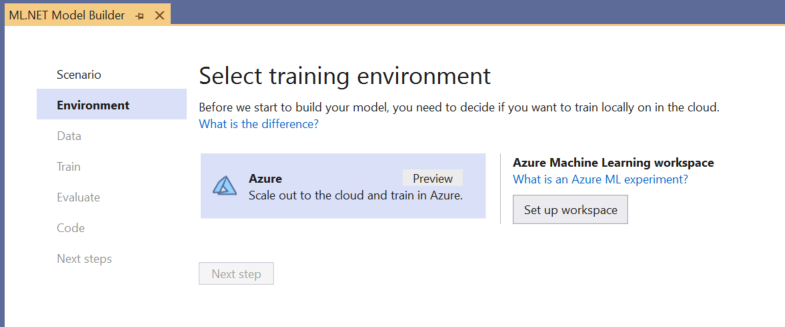
Aby wytrenować model przy użyciu usługi Azure ML, należy utworzyć eksperyment usługi Azure ML z poziomu narzędzia Model Builder.
Eksperyment usługi Azure ML to zasób, który hermetyzuje konfigurację i wyniki dla co najmniej jednego przebiegu trenowania uczenia maszynowego.
Aby utworzyć eksperyment usługi Azure ML, należy najpierw skonfigurować środowisko na platformie Azure. Eksperyment wymaga następującego uruchomienia:
- Subskrypcja platformy Azure
- Obszar roboczy: zasób usługi Azure ML, który zapewnia centralne miejsce dla wszystkich zasobów i artefaktów usługi Azure ML utworzonych w ramach przebiegu trenowania.
- Obliczenia: obliczenia usługi Azure Machine Learning to oparta na chmurze maszyna wirtualna z systemem Linux używana do trenowania. Dowiedz się więcej o typach obliczeniowych obsługiwanych przez program Model Builder.
Konfigurowanie obszaru roboczego usługi Azure ML
Aby skonfigurować środowisko:
Wybierz przycisk Skonfiguruj obszar roboczy .
W oknie dialogowym Tworzenie nowego eksperymentu wybierz subskrypcję platformy Azure.
Wybierz istniejący obszar roboczy lub utwórz nowy obszar roboczy usługi Azure ML.
Podczas tworzenia nowego obszaru roboczego są aprowidowane następujące zasoby:
- Obszar roboczy usługi Azure Machine Learning
- Azure Storage
- Azure Application Insights
- Azure Container Registry
- Azure Key Vault
W związku z tym ten proces może potrwać kilka minut.
Wybierz istniejące zasoby obliczeniowe lub utwórz nowe środowisko obliczeniowe usługi Azure ML. Ten proces może potrwać kilka minut.
Pozostaw domyślną nazwę eksperymentu i wybierz pozycję Utwórz.
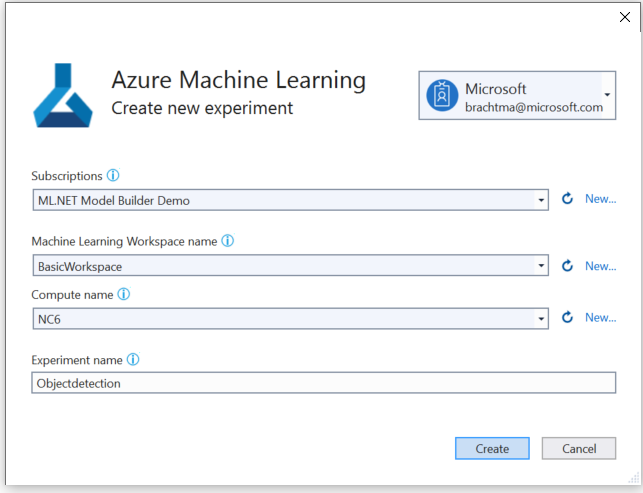
Pierwszy eksperyment zostanie utworzony, a nazwa eksperymentu zostanie zarejestrowana w obszarze roboczym. Wszystkie kolejne przebiegi (jeśli jest używana ta sama nazwa eksperymentu) są rejestrowane w ramach tego samego eksperymentu. W przeciwnym razie zostanie utworzony nowy eksperyment.
Jeśli konfiguracja jest satysfakcjonująca, wybierz przycisk Następny krok w narzędziu Model Builder, aby przejść do kroku Dane .
Ładowanie danych
W kroku Dane w narzędziu Model Builder wybierzesz zestaw danych szkoleniowych.
Ważne
Konstruktor modelu obecnie akceptuje tylko format JSON wygenerowany przez voTT.
Wybierz przycisk w sekcji Dane wejściowe i użyj Eksplorator plików, aby znaleźć
StopSignObjDetection-export.jsonelement, który powinien znajdować się w katalogu Stop-Signs/vott-json-export.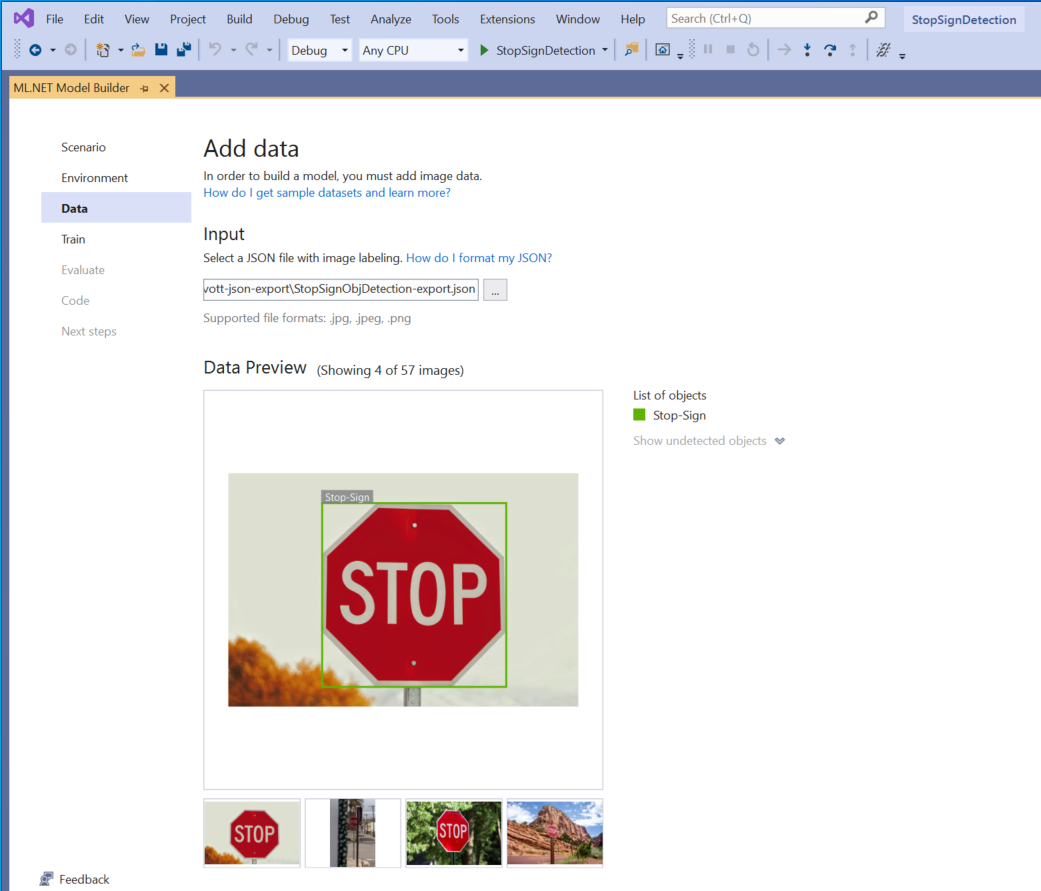
Jeśli dane wyglądają poprawnie w podglądzie danych, wybierz pozycję Następny krok , aby przejść do kroku Trenowanie .
Trenowanie modelu
Następnym krokiem jest trenowanie modelu.
Na ekranie Train (Trenowanie konstruktora modelu) wybierz przycisk Start training (Rozpocznij trenowanie ).
Na tym etapie dane są przekazywane do usługi Azure Storage, a proces trenowania rozpoczyna się w usłudze Azure ML.
Proces trenowania zajmuje trochę czasu, a ilość czasu może się różnić w zależności od rozmiaru wybranego środowiska obliczeniowego, a także ilości danych. Przy pierwszym trenowaniu modelu na platformie Azure można oczekiwać nieco dłuższego czasu trenowania, ponieważ należy aprowizować zasoby. W przypadku tej próbki 50 obrazów szkolenie trwało około 16 minut.
Postęp przebiegów można śledzić w portalu usługi Azure Machine Learning, wybierając link Monitoruj bieżący przebieg w Azure Portal w programie Visual Studio.
Po zakończeniu trenowania wybierz przycisk Następny krok , aby przejść do kroku Ocena .
Ocena modelu
Na ekranie Ocena uzyskasz przegląd wyników procesu trenowania, w tym dokładność modelu.
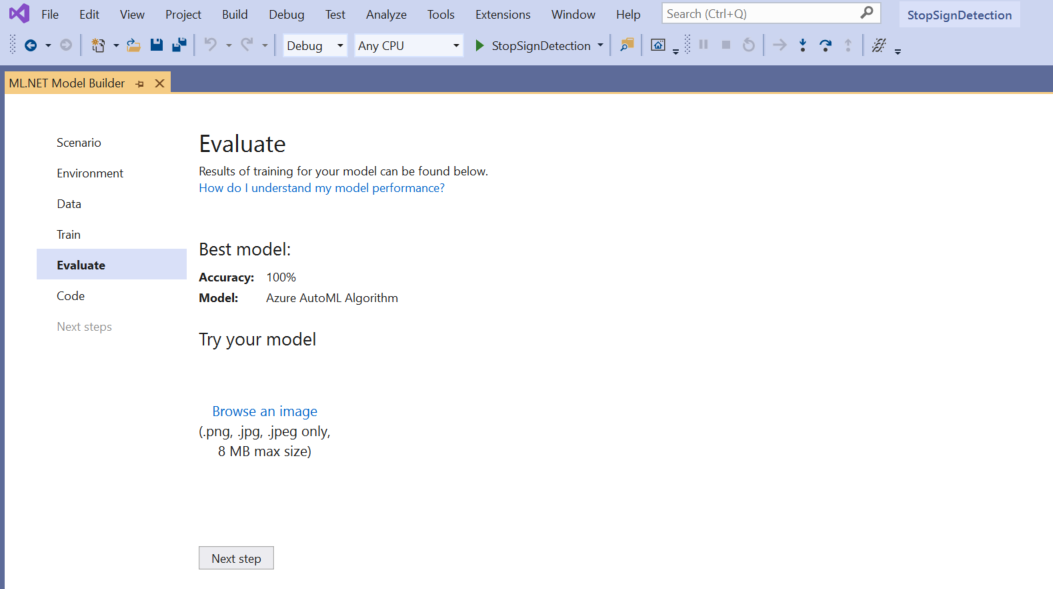
W takim przypadku dokładność wskazuje wartość 100%, co oznacza, że model jest bardziej niż prawdopodobnie nadmierny z powodu zbyt małej liczby obrazów w zestawie danych.
Możesz użyć środowiska Wypróbuj model , aby szybko sprawdzić, czy model działa zgodnie z oczekiwaniami.
Wybierz pozycję Przeglądaj obraz i podaj obraz testowy, najlepiej taki, którego model nie używał w ramach trenowania.
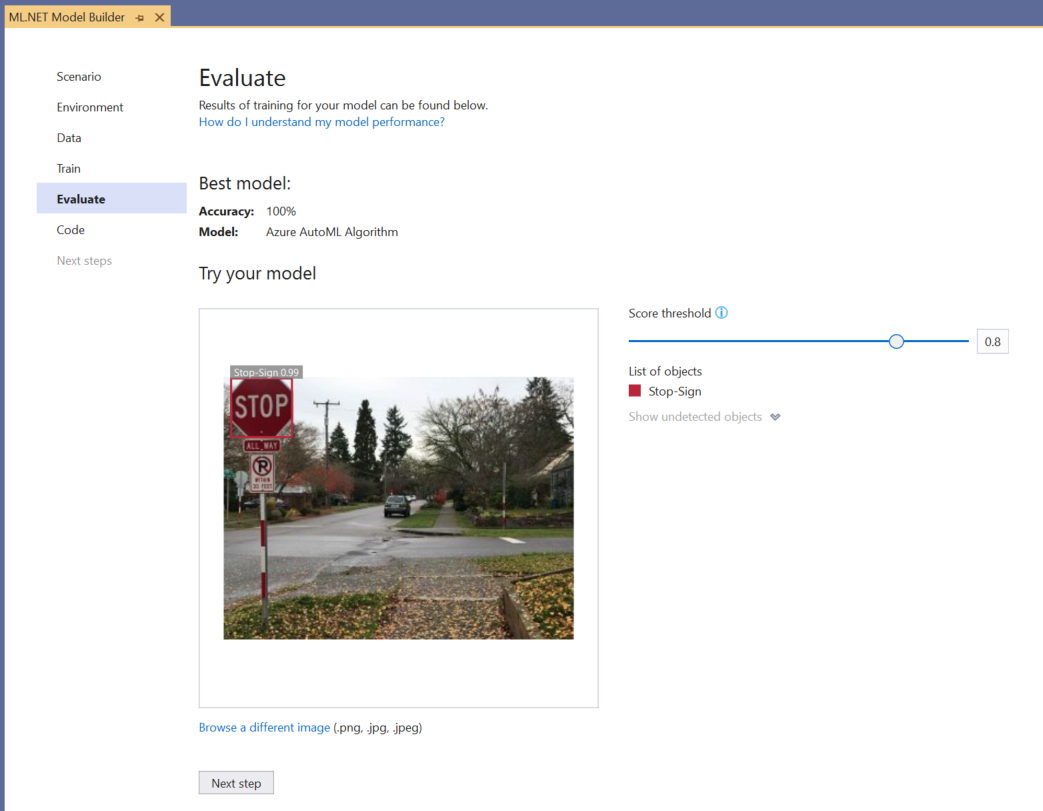
Wynik wyświetlany w każdym wykrytym polu ograniczenia wskazuje pewność wykrytego obiektu. Na przykład na powyższym zrzucie ekranu wynik w polu ograniczenia wokół znaku zatrzymania wskazuje, że model ma 99% pewności, że wykryty obiekt jest znakiem zatrzymania.
Próg oceny, który można zwiększyć lub zmniejszyć za pomocą suwaka progu, doda i usunie wykryte obiekty na podstawie ich wyników. Jeśli na przykład próg wynosi 0,51, model będzie pokazywał tylko obiekty, które mają współczynnik ufności wynoszący 51 lub większą. W miarę zwiększania progu zobaczysz mniej wykrytych obiektów, a po zmniejszeniu progu zobaczysz więcej wykrytych obiektów.
Jeśli metryki dokładności nie są zadowalające, jednym z prostych sposobów na próbę zwiększenia dokładności modelu jest użycie większej ilości danych. W przeciwnym razie wybierz link Następny krok , aby przejść do kroku Korzystanie w narzędziu Model Builder.
(Opcjonalnie) Korzystanie z modelu
Ten krok będzie zawierać szablony projektów, których można użyć do korzystania z modelu. Ten krok jest opcjonalny i można wybrać metodę najlepiej dopasowaną do Twoich potrzeb dotyczących sposobu obsługi modelu.
- Aplikacja konsolowa
- Interfejs API sieci Web
Aplikacja konsolowa
Podczas dodawania aplikacji konsolowej do rozwiązania zostanie wyświetlony monit o nadenie nazwy projektu.
Nadaj projektowi konsoli nazwę StopSignDetection_Console.
Kliknij pozycję Dodaj do rozwiązania , aby dodać projekt do bieżącego rozwiązania.
Uruchom aplikację.
Dane wyjściowe wygenerowane przez program powinny wyglądać podobnie do poniższego fragmentu kodu:
Predicted Boxes: Top: 73.225296, Left: 256.89764, Right: 533.8884, Bottom: 484.24243, Label: stop-sign, Score: 0.9970765
Interfejs API sieci Web
Podczas dodawania internetowego interfejsu API do rozwiązania zostanie wyświetlony monit o nadenie nazwy projektu.
Nadaj projektowi internetowego interfejsu API nazwę StopSignDetection_API.
Kliknij pozycję Dodaj do rozwiązania , aby dodać projekt do bieżącego rozwiązania.
Uruchom aplikację.
Otwórz program PowerShell i wprowadź następujący kod, w którym port to port, na którym nasłuchuje aplikacja.
$body = @{ ImageSource = <Image location on your local machine> } Invoke-RestMethod "https://localhost:<PORT>/predict" -Method Post -Body ($body | ConvertTo-Json) -ContentType "application/json"W przypadku powodzenia dane wyjściowe powinny wyglądać podobnie do poniższego tekstu.
boxes labels scores boundingBoxes ----- ------ ------ ------------- {339.97797, 154.43184, 472.6338, 245.0796} {1} {0.99273646} {}- Kolumna
boxeszawiera współrzędne pola ograniczenia wykrytego obiektu. Wartości w tym miejscu należą odpowiednio do współrzędnych lewej, górnej, prawej i dolnej. - Są
labelsto indeks przewidywanych etykiet. W takim przypadku wartość 1 jest znakiem zatrzymania. - Element
scoresokreśla, jak pewny jest pewność, że model należy do tej etykiety.
Uwaga
(Opcjonalnie) Współrzędne pola ograniczenia są znormalizowane dla szerokości 800 pikseli i wysokości 600 pikseli. Aby skalować współrzędne pola ograniczenia dla obrazu w celu dalszego przetwarzania końcowego, należy wykonać następujące czynności:
- Mnożenie współrzędnych górnej i dolnej przez oryginalną wysokość obrazu oraz mnożenie współrzędnych lewej i prawej przez oryginalną szerokość obrazu.
- Podziel współrzędne górne i dolne o 600 i podziel współrzędne lewe i prawe o 800.
Na przykład, biorąc pod uwagę oryginalne wymiary
actualImageHeightobrazu i , iactualImageWidthModelOutputo nazwieprediction, poniższy fragment kodu pokazuje sposób skalowania współrzędnychBoundingBox:var top = originalImageHeight * prediction.Top / 600; var bottom = originalImageHeight * prediction.Bottom / 600; var left = originalImageWidth * prediction.Left / 800; var right = originalImageWidth * prediction.Right / 800;Obraz może zawierać więcej niż jedno pole ograniczenia, więc ten sam proces należy zastosować do każdego pola ograniczenia na obrazie.
- Kolumna
Gratulacje! Udało Ci się utworzyć model uczenia maszynowego w celu wykrywania logowań na obrazach przy użyciu narzędzia Model Builder. Kod źródłowy tego samouczka można znaleźć w repozytorium GitHub dotnet/machinelearning-samples .
Dodatkowe zasoby
Aby dowiedzieć się więcej o tematach wymienionych w tym samouczku, odwiedź następujące zasoby:
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.