Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, jak utworzyć aplikację wykrywania anomalii dla danych sprzedaży produktów. Ten samouczek tworzy aplikację konsolową platformy .NET przy użyciu języka C# w programie Visual Studio.
W tym poradniku nauczysz się, jak:
- Ładowanie danych
- Tworzenie przekształcenia na potrzeby wykrywania anomalii skokowej
- Wykrywanie anomalii skoków za pomocą transformacji
- Tworzenie przekształcenia na potrzeby wykrywania anomalii w punkcie zmian
- Wykrywanie anomalii punktów zmian za pomocą przekształcenia
Kod źródłowy tego samouczka można znaleźć w repozytorium dotnet/samples .
Wymagania wstępne
Program Visual Studio 2022 lub nowszy z zainstalowanym obciążeniem Programowanie aplikacji klasycznych .NET.
Uwaga / Notatka
Format danych w programie product-sales.csv jest oparty na zbiorze danych „Shampoo Sales Over a Three Year Period”, który pierwotnie pochodzi z DataMarket i jest dostarczany przez Bibliotekę Danych Szeregów Czasowych (TSDL), utworzoną przez Roba Hyndmana.
Zestaw danych "Shampoo Sales Over a Three Year Period" (Sprzedaż szamponu w okresie trzech lat) licencjonowany w ramach domyślnej licencji DataMarket Open License.
Tworzenie aplikacji konsolowej
Utwórz aplikację konsolową języka C# o nazwie "ProductSalesAnomalyDetection". Kliknij przycisk Next (Dalej).
Wybierz platformę .NET 8 jako platformę do użycia. Kliknij przycisk Utwórz.
Utwórz katalog o nazwie Dane w projekcie, aby zapisać pliki zestawu danych.
Zainstaluj pakiet NuGet Microsoft.ML:
Uwaga / Notatka
W tym przykładzie użyto najnowszej stabilnej wersji pakietów NuGet wymienionych, chyba że określono inaczej.
W Eksploratorze rozwiązań kliknij prawym przyciskiem myszy projekt i wybierz polecenie Zarządzaj pakietami NuGet. Wybierz pozycję "nuget.org" jako źródło pakietu, wybierz kartę Przeglądaj, wyszukaj Microsoft.ML i wybierz pozycję Zainstaluj. Wybierz przycisk OK w oknie dialogowym Podgląd zmian , a następnie wybierz przycisk Akceptuję w oknie dialogowym Akceptacja licencji , jeśli zgadzasz się z postanowieniami licencyjnymi dla pakietów wymienionych. Powtórz te kroki dla zestawu Microsoft.ML.TimeSeries.
Dodaj następujące
usingdyrektywy w górnej części pliku Program.cs :using Microsoft.ML; using ProductSalesAnomalyDetection;
Pobierz swoje dane
Pobierz zestaw danych i zapisz go w utworzonym wcześniej folderze Dane :
Kliknij prawym przyciskiem myszy product-sales.csv i wybierz pozycję "Zapisz łącze (lub element docelowy) Jako..."
Upewnij się, że zapiszesz plik *.csv w folderze Dane lub po zapisaniu go w innym miejscu przenieś plik *.csv do folderu Dane .
W Eksploratorze rozwiązań kliknij prawym przyciskiem myszy plik *.csv i wybierz polecenie Właściwości. W sekcji Zaawansowane zmień wartość kopiuj do katalogu wyjściowego na kopiuj, jeśli nowsze.
Poniższa tabela zawiera podgląd danych z pliku *.csv:
| Miesiąc | ProductSales |
|---|---|
| 1 stycznia | 271 |
| 2 stycznia | 150.9 |
| ..... | ..... |
| 1–luty | 199.3 |
| ..... | ..... |
Tworzenie klas i definiowanie ścieżek
Następnie zdefiniuj struktury danych klasy wejściowej i przewidywania.
Dodaj nową klasę do projektu:
W Eksploratorze rozwiązań kliknij prawym przyciskiem myszy projekt, a następnie wybierz polecenie Dodaj > nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Klasa i zmień pole Nazwa na ProductSalesData.cs. Następnie wybierz pozycję Dodaj.
Plik ProductSalesData.cs zostanie otwarty w edytorze kodu.
Dodaj następującą
usingdyrektywę na początku ProductSalesData.cs:using Microsoft.ML.Data;Usuń istniejącą definicję klasy i dodaj następujący kod, który ma dwie klasy
ProductSalesDataiProductSalesPrediction, do pliku ProductSalesData.cs :public class ProductSalesData { [LoadColumn(0)] public string? Month; [LoadColumn(1)] public float numSales; } public class ProductSalesPrediction { //vector to hold alert,score,p-value values [VectorType(3)] public double[]? Prediction { get; set; } }ProductSalesDataokreśla klasę danych wejściowych. Atrybut LoadColumn określa, które kolumny (według indeksu kolumn) w zestawie danych powinny zostać załadowane.ProductSalesPredictionokreśla klasę danych przewidywania. W przypadku wykrywania anomalii przewidywanie składa się z alertu wskazującego, czy istnieje anomalia, nieprzetworzona ocena i wartość p. Im bliżej wartości p wynosi 0, tym bardziej prawdopodobne jest wystąpienie anomalii.Utwórz dwa pola globalne do przechowywania ostatnio pobranej ścieżki pliku zestawu danych i zapisanej ścieżki pliku modelu:
-
_dataPathzawiera ścieżkę do zestawu danych używanego do trenowania modelu. -
_docsizezawiera liczbę rekordów w pliku zestawu danych. Użyjesz_docSizepolecenia , aby obliczyćpvalueHistoryLengthwartość .
-
Dodaj następujący kod do wiersza bezpośrednio poniżej dyrektyw,
usingaby określić te ścieżki:string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv"); //assign the Number of records in dataset file to constant variable const int _docsize = 36;
Inicjowanie zmiennych
Zastąp
Console.WriteLine("Hello World!")wiersz następującym kodem, aby zadeklarować i zainicjować zmiennąmlContext:MLContext mlContext = new MLContext();Klasa MLContext jest punktem wyjścia dla wszystkich operacji ML.NET, a inicjowanie
mlContexttworzy nowe środowisko ML.NET, które może być współużytkowane przez obiekty przepływu pracy tworzenia modelu. Jest ona podobna, koncepcyjnie, doDBContextw programie Entity Framework.
Ładowanie danych
Dane w ML.NET są reprezentowane jako interfejs IDataView.
IDataView to elastyczny, wydajny sposób opisywania danych tabelarycznych (liczbowych i tekstowych). Dane można załadować z pliku tekstowego lub z innych źródeł (na przykład bazy danych SQL lub plików dziennika) do IDataView obiektu.
Dodaj następujący kod po utworzeniu zmiennej
mlContext:IDataView dataView = mlContext.Data.LoadFromTextFile<ProductSalesData>(path: _dataPath, hasHeader: true, separatorChar: ',');Element LoadFromTextFile() definiuje schemat danych i odczytuje go w pliku. Pobiera zmienne ścieżki danych i zwraca wartość
IDataView.
Wykrywanie anomalii szeregów czasowych
Wykrywanie anomalii flaguje nieoczekiwane lub nietypowe zdarzenia lub zachowania. Daje wskazówki, gdzie szukać problemów i pomaga odpowiedzieć na pytanie "Czy to dziwne?".

Wykrywanie anomalii to proces identyfikacji nietypowych wzorców w danych szeregów czasowych; punkty na danym szeregu czasowym, gdzie zachowanie odbiega od oczekiwań lub jest "nietypowe".
Wykrywanie anomalii może być przydatne na wiele sposobów. Przykład:
Jeśli masz samochód, możesz chcieć wiedzieć: Czy ten miernik oleju odczytuje normalnie, czy mam wyciek? Jeśli monitorujesz zużycie energii, warto wiedzieć: Czy wystąpiła awaria?
Istnieją dwa typy anomalii szeregów czasowych, które można wykryć:
Spiki wskazują na tymczasowe wybuchy nietypowego zachowania w systemie.
Punkty zmian wskazują początek trwałych zmian w czasie w systemie.
W ML.NET algorytmy wykrywania szczytów IID lub wykrywania punktów zmian IID są odpowiednie dla niezależnych i identycznie rozłożonych zestawów danych. Zakładają oni, że dane wejściowe to sekwencja punktów danych, które są niezależnie próbkowane z jednego rozkładu stacjonarnego.
W przeciwieństwie do modeli w innych samouczkach, przekształcenia detektora anomalii szeregów czasowych działają bezpośrednio na danych wejściowych. Metoda IEstimator.Fit() nie wymaga danych treningowych w celu utworzenia transformacji. Wymaga to jednak schematu danych, który jest dostarczany przez widok danych wygenerowany na podstawie pustej ProductSalesDatalisty .
Przeanalizujesz te same dane sprzedaży produktów, aby wykryć skoki i punkty zmian. Proces tworzenia i trenowania modelu jest taki sam w przypadku wykrywania skoków i wykrywania punktów zmian; główną różnicą jest używany określony algorytm wykrywania.
Wykrywanie skoków
Celem wykrywania skoków jest zidentyfikowanie nagłych, ale tymczasowych wzrostów, które znacznie różnią się od większości wartości danych szeregów czasowych. Ważne jest, aby w odpowiednim czasie wykrywać te podejrzane rzadkie elementy, zdarzenia lub obserwacje, aby je zminimalizować. Poniższe podejście może służyć do wykrywania różnych anomalii, takich jak: awarie, cyberataki lub wirusowa zawartość internetowa. Na poniższej ilustracji przedstawiono przykład skoków w zestawie danych szeregów czasowych:
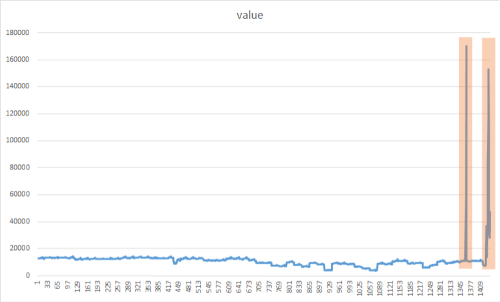
Dodawanie metody CreateEmptyDataView()
Dodaj następującą metodę do Program.cs:
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
Obiekt CreateEmptyDataView() tworzy pusty obiekt widoku danych z poprawnym schematem, który ma być używany jako dane wejściowe IEstimator.Fit() metody.
Tworzenie metody DetectSpike()
Metoda DetectSpike():
- Tworzy przekształcenie z narzędzia do szacowania.
- Wykrywa skoki na podstawie historycznych danych sprzedaży.
- Wyświetla wyniki.
Utwórz metodę
DetectSpike()w dolnej części pliku Program.cs przy użyciu następującego kodu:DetectSpike(MLContext mlContext, int docSize, IDataView productSales) { }Użyj modułu IidSpikeEstimator , aby wytrenować model na potrzeby wykrywania skoków. Dodaj ją do
DetectSpike()metody przy użyciu następującego kodu:var iidSpikeEstimator = mlContext.Transforms.DetectIidSpike(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, pvalueHistoryLength: docSize / 4);Utwórz transformację wykrywania skoków, dodając poniższy wiersz kodu do metody
DetectSpike():Wskazówka
Parametry
confidenceipvalueHistoryLengthwpływają na sposób wykrywania skoków.confidenceokreśla, jak poufny jest model do skoków. Im niższa pewność siebie, tym bardziej prawdopodobne jest wykrycie "mniejszych" skoków. ParametrpvalueHistoryLengthdefiniuje liczbę punktów danych w oknie przesuwnym. Wartość tego parametru jest zwykle procentem całego zestawu danych. Im niższapvalueHistoryLengthwartość , tym szybciej model zapomina o poprzednich dużych skokach.ITransformer iidSpikeTransform = iidSpikeEstimator.Fit(CreateEmptyDataView(mlContext));Dodaj następujący wiersz kodu, aby przekształcić
productSalesdane jako następny wiersz w metodzieDetectSpike():IDataView transformedData = iidSpikeTransform.Transform(productSales);Poprzedni kod używa metody Transform(), aby przewidywać wiele wierszy wejściowych zestawu danych.
Przekonwertuj element
transformedDatana silnie typizowaneIEnumerable, aby ułatwić wyświetlanie przy użyciu metody CreateEnumerable() z następującym kodem:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Utwórz wiersz nagłówka wyświetlania przy użyciu następującego Console.WriteLine() kodu:
Console.WriteLine("Alert\tScore\tP-Value");W wynikach wykrywania skoków zostaną wyświetlone następujące informacje:
-
Alertwskazuje alert szczytowy dla danego punktu danych. -
ScoreProductSalesto wartość dla danego punktu danych w zestawie danych. -
P-Value"P" oznacza prawdopodobieństwo. Im bliżej wartości p wynosi 0, tym bardziej prawdopodobne jest, że punkt danych jest anomalią.
-
Użyj następującego kodu, aby iterować dane
predictionsIEnumerablei wyświetlać wyniki:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}"; if (p.Prediction[0] == 1) { results += " <-- Spike detected"; } Console.WriteLine(results); } } Console.WriteLine("");Dodaj wywołanie do
DetectSpike()metody poniżej wywołaniaLoadFromTextFile()metody :DetectSpike(mlContext, _docsize, dataView);
Wyniki wykrywania skoków
Wyniki powinny być podobne do poniższych. Podczas przetwarzania są wyświetlane komunikaty. Mogą pojawić się ostrzeżenia lub komunikaty przetwarzania. Niektóre komunikaty zostały usunięte z poniższych wyników, aby uzyskać jasność.
Detect temporary changes in pattern
=============== Training the model ===============
=============== End of training process ===============
Alert Score P-Value
0 271.00 0.50
0 150.90 0.00
0 188.10 0.41
0 124.30 0.13
0 185.30 0.47
0 173.50 0.47
0 236.80 0.19
0 229.50 0.27
0 197.80 0.48
0 127.90 0.13
1 341.50 0.00 <-- Spike detected
0 190.90 0.48
0 199.30 0.48
0 154.50 0.24
0 215.10 0.42
0 278.30 0.19
0 196.40 0.43
0 292.00 0.17
0 231.00 0.45
0 308.60 0.18
0 294.90 0.19
1 426.60 0.00 <-- Spike detected
0 269.50 0.47
0 347.30 0.21
0 344.70 0.27
0 445.40 0.06
0 320.90 0.49
0 444.30 0.12
0 406.30 0.29
0 442.40 0.21
1 580.50 0.00 <-- Spike detected
0 412.60 0.45
1 687.00 0.01 <-- Spike detected
0 480.30 0.40
0 586.30 0.20
0 651.90 0.14
Wykrywanie punktów zmian
Change points są trwałymi zmianami w rozkładie strumienia zdarzeń szeregów czasowych wartości, takich jak zmiany na poziomie i trendy. Te trwałe zmiany trwają znacznie dłużej niż spikes i mogą wskazywać na katastrofalne zdarzenia.
Change points nie są zwykle widoczne dla nagiego oka, ale można je wykryć w danych przy użyciu metod, takich jak w poniższej metodzie. Na poniższej ilustracji przedstawiono przykład wykrywania punktu zmian:
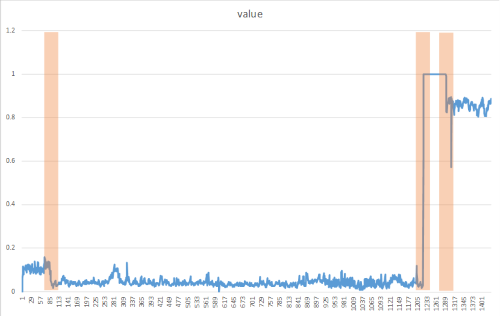
Tworzenie metody DetectChangepoint()
Metoda DetectChangepoint() wykonuje następujące zadania:
- Tworzy przekształcenie z narzędzia do szacowania.
- Wykrywa punkty zmian na podstawie historycznych danych sprzedaży.
- Wyświetla wyniki.
Utwórz metodę
DetectChangepoint()tuż poDetectSpike()deklaracji metody przy użyciu następującego kodu:void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales) { }Utwórz moduł iidChangePointEstimator w metodzie
DetectChangepoint()przy użyciu następującego kodu:var iidChangePointEstimator = mlContext.Transforms.DetectIidChangePoint(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, changeHistoryLength: docSize / 4);Tak jak wcześniej, utwórz przekształcenie z narzędzia do szacowania, dodając następujący wiersz kodu w metodzie
DetectChangePoint():Wskazówka
Wykrywanie punktów zmian występuje z niewielkim opóźnieniem, ponieważ model musi upewnić się, że bieżące odchylenie jest trwałą zmianą, a nie tylko niektóre losowe skoki przed utworzeniem alertu. Ilość tego opóźnienia jest równa parametrowi
changeHistoryLength. Zwiększając wartość tego parametru, alerty wykrywania zmian dotyczące bardziej trwałych zmian, ale kompromis byłby dłuższy.var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));Transform()Użyj metody , aby przekształcić dane, dodając następujący kod doDetectChangePoint()elementu :IDataView transformedData = iidChangePointTransform.Transform(productSales);Tak jak poprzednio, przekonwertuj element
transformedDatana silnie typizowaneIEnumerable, aby ułatwić wyświetlanie przy użyciuCreateEnumerable()metody z następującym kodem:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Utwórz nagłówek wyświetlania z następującym kodem jako następny wiersz w metodzie
DetectChangePoint():Console.WriteLine("Alert\tScore\tP-Value\tMartingale value");W wynikach wykrywania punktów zmian zostaną wyświetlone następujące informacje:
-
Alertwskazuje alert punktu zmiany dla danego punktu danych. -
ScoreProductSalesto wartość dla danego punktu danych w zestawie danych. -
P-Value"P" oznacza prawdopodobieństwo. Im bliżej wartość P wynosi 0, tym bardziej prawdopodobne jest, że punkt danych jest anomalią. -
Martingale valuesłuży do identyfikowania, jak "dziwny" jest punkt danych, na podstawie sekwencji wartości P.
-
Wykonaj iterację po pliku
predictionsIEnumerablei wyświetl wyniki przy użyciu następującego kodu:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}"; if (p.Prediction[0] == 1) { results += " <-- alert is on, predicted changepoint"; } Console.WriteLine(results); } } Console.WriteLine("");Dodaj następujące wywołanie do
DetectChangepoint()metody po wywołaniuDetectSpike()metody :DetectChangepoint(mlContext, _docsize, dataView);
Wyniki wykrywania punktów zmian
Wyniki powinny być podobne do poniższych. Podczas przetwarzania są wyświetlane komunikaty. Mogą pojawić się ostrzeżenia lub komunikaty przetwarzania. Niektóre komunikaty zostały usunięte z poniższych wyników w celu uzyskania jasności.
Detect Persistent changes in pattern
=============== Training the model Using Change Point Detection Algorithm===============
=============== End of training process ===============
Alert Score P-Value Martingale value
0 271.00 0.50 0.00
0 150.90 0.00 2.33
0 188.10 0.41 2.80
0 124.30 0.13 9.16
0 185.30 0.47 9.77
0 173.50 0.47 10.41
0 236.80 0.19 24.46
0 229.50 0.27 42.38
1 197.80 0.48 44.23 <-- alert is on, predicted changepoint
0 127.90 0.13 145.25
0 341.50 0.00 0.01
0 190.90 0.48 0.01
0 199.30 0.48 0.00
0 154.50 0.24 0.00
0 215.10 0.42 0.00
0 278.30 0.19 0.00
0 196.40 0.43 0.00
0 292.00 0.17 0.01
0 231.00 0.45 0.00
0 308.60 0.18 0.00
0 294.90 0.19 0.00
0 426.60 0.00 0.00
0 269.50 0.47 0.00
0 347.30 0.21 0.00
0 344.70 0.27 0.00
0 445.40 0.06 0.02
0 320.90 0.49 0.01
0 444.30 0.12 0.02
0 406.30 0.29 0.01
0 442.40 0.21 0.01
0 580.50 0.00 0.01
0 412.60 0.45 0.01
0 687.00 0.01 0.12
0 480.30 0.40 0.08
0 586.30 0.20 0.03
0 651.90 0.14 0.09
Gratulacje! Udało Ci się utworzyć modele uczenia maszynowego do wykrywania skoków i anomalii punktów zmian w danych sprzedaży.
Kod źródłowy tego samouczka można znaleźć w repozytorium dotnet/samples .
W tym samouczku nauczyłeś się następujących rzeczy:
- Ładowanie danych
- Trenowanie modelu pod kątem wykrywania anomalii skoków
- Wykrywanie anomalii skoków za pomocą wytrenowanego modelu
- Trenowanie modelu na potrzeby wykrywania anomalii w punkcie zmian
- Wykrywanie anomalii punktów zmian za pomocą wytrenowanego trybu
Dalsze kroki
Zapoznaj się z repozytorium GitHub z przykładami Machine Learning, aby odkryć przykład wykrywania anomalii w danych sezonowych.
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.