Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku pokazano, jak używać wstępnie wytrenowanego modelu TensorFlow do klasyfikowania tonacji w komentarzach do witryny internetowej. Klasyfikator tonacji binarnej to aplikacja konsolowa języka C# opracowana przy użyciu programu Visual Studio.
Model TensorFlow używany w tym samouczku został wytrenowany przy użyciu recenzji filmów z bazy danych IMDB. Po zakończeniu tworzenia aplikacji będzie można podać tekst recenzji filmu, a aplikacja poinformuje Cię, czy recenzja ma pozytywną, czy negatywną tonację.
W tym poradniku nauczysz się, jak:
- Ładowanie wstępnie wytrenowanego modelu TensorFlow
- Przekształcanie tekstu komentarza witryny internetowej w funkcje odpowiednie dla modelu
- Przewidywanie przy użyciu modelu
Kod źródłowy tego samouczka można znaleźć w repozytorium dotnet/samples .
Wymagania wstępne
- Program Visual Studio 2022 lub nowszy z zainstalowanym obciążeniem Programowanie aplikacji klasycznych .NET.
Konfiguracja
Tworzenie aplikacji
Utwórz aplikację konsolową języka C# o nazwie "TextClassificationTF". Kliknij przycisk Next (Dalej).
Wybierz platformę .NET 8 jako platformę do użycia. Kliknij przycisk Utwórz.
Utwórz katalog o nazwie Dane w projekcie, aby zapisać pliki zestawu danych.
Zainstaluj pakiet NuGet Microsoft.ML:
Uwaga / Notatka
W tym przykładzie użyto najnowszej stabilnej wersji pakietów NuGet wymienionych, chyba że określono inaczej.
W Eksploratorze rozwiązań kliknij prawym przyciskiem myszy projekt i wybierz polecenie Zarządzaj pakietami NuGet. Wybierz pozycję "nuget.org" jako źródło pakietu, a następnie wybierz kartę Przeglądaj . Wyszukaj Microsoft.ML, wybierz odpowiedni pakiet, a następnie wybierz pozycję Zainstaluj. Kontynuuj instalację, zgadzając się na postanowienia licencyjne wybranego pakietu. Powtórz te kroki dla Microsoft.ML.TensorFlow, Microsoft.ML.SampleUtils i SciSharp.TensorFlow.Redist.
Dodawanie modelu TensorFlow do projektu
Uwaga / Notatka
Model tego samouczka pochodzi z repozytorium dotnet/machinelearning-testdata w usłudze GitHub. Model jest w formacie TensorFlow SavedModel.
Pobierz plik zip sentiment_model i rozpakuj plik.
Plik zip zawiera:
-
saved_model.pb: sam model TensorFlow. Model przyjmuje tablicę całkowitą o stałej długości (rozmiar 600) cech reprezentujących tekst w ciągu recenzji IMDB i zwraca dwa prawdopodobieństwa, które sumują się do 1: prawdopodobieństwo, że recenzja wejściowa ma pozytywny sentyment, oraz prawdopodobieństwo, że recenzja wejściowa ma negatywny sentyment. -
imdb_word_index.csv: mapowanie poszczególnych słów na wartość całkowitą. Mapowanie służy do generowania funkcji wejściowych dla modelu TensorFlow.
-
Skopiuj zawartość najbardziej wewnętrznego
sentiment_modelkatalogu do katalogu projektusentiment_model. Ten katalog zawiera model i dodatkowe pliki pomocy technicznej potrzebne do tego samouczka, jak pokazano na poniższej ilustracji: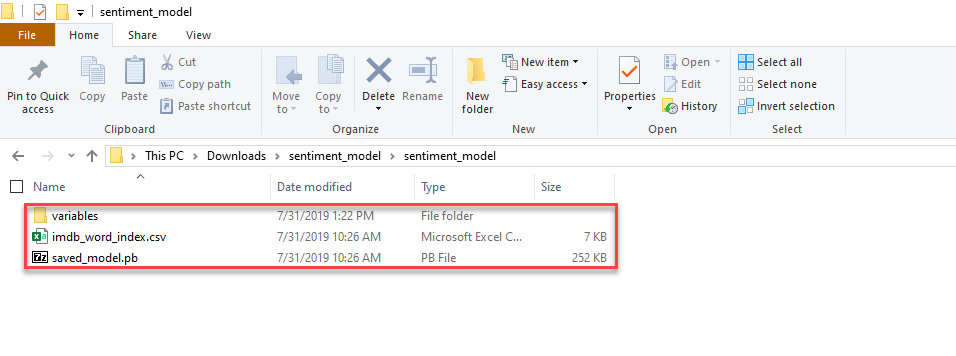
W Eksploratorze rozwiązań kliknij prawym przyciskiem myszy każdy z plików w katalogu i podkatalogu
sentiment_model, a następnie wybierz polecenie Właściwości. W obszarze Zaawansowane zmień wartość Kopiuj do katalogu wyjściowego na Kopiuj, jeśli nowsze.
Dodawanie using dyrektyw i zmiennych globalnych
Dodaj następujące dodatkowe
usingdyrektywy na początku pliku Program.cs :using Microsoft.ML; using Microsoft.ML.Data; using Microsoft.ML.Transforms;Utwórz zmienną globalną bezpośrednio po dyrektywach
usingw celu przechowywania zapisanej ścieżki pliku modelu.string _modelPath = Path.Combine(Environment.CurrentDirectory, "sentiment_model");-
_modelPathto ścieżka pliku wytrenowanego modelu.
-
Modelowanie danych
Recenzje filmów są wolną formą tekstu. Aplikacja konwertuje tekst na format wejściowy oczekiwany przez model w wielu dyskretnych etapach.
Pierwszym z nich jest podzielenie tekstu na osobne wyrazy i użycie dostarczonego pliku mapowania w celu mapowania każdego wyrazu na kodowanie liczb całkowitych. Wynikiem tej transformacji jest tablica całkowita o zmiennej długości z długością odpowiadającą liczbie wyrazów w zdaniu.
| Majątek | Wartość | Typ |
|---|---|---|
| Tekst przeglądu | ten film jest naprawdę dobry | ciąg |
| VariableLengthFeatures | 14,22,9,66,78,... | int[] |
Tablica funkcji o zmiennej długości jest następnie zmieniana na stałą długość 600. Jest to długość oczekiwana przez model TensorFlow.
| Majątek | Wartość | Typ |
|---|---|---|
| Tekst przeglądu | ten film jest naprawdę dobry | ciąg |
| VariableLengthFeatures | 14,22,9,66,78,... | int[] |
| Funkcje | 14,22,9,66,78,... | int[600] |
Utwórz klasę dla danych wejściowych w dolnej części pliku Program.cs :
/// <summary> /// Class to hold original sentiment data. /// </summary> public class MovieReview { public string? ReviewText { get; set; } }Klasa danych wejściowych,
MovieReview, ma elementstringdla komentarzy użytkownika (ReviewText).Utwórz klasę dla cech o zmiennej długości po klasie
MovieReview./// <summary> /// Class to hold the variable length feature vector. Used to define the /// column names used as input to the custom mapping action. /// </summary> public class VariableLength { /// <summary> /// This is a variable length vector designated by VectorType attribute. /// Variable length vectors are produced by applying operations such as 'TokenizeWords' on strings /// resulting in vectors of tokens of variable lengths. /// </summary> [VectorType] public int[]? VariableLengthFeatures { get; set; } }Właściwość
VariableLengthFeaturesma atrybut VectorType , aby wyznaczyć go jako wektor. Wszystkie elementy wektorów muszą być tego samego typu. W zestawach danych z dużą liczbą kolumn ładowanie wielu kolumn jako pojedynczego wektora zmniejsza liczbę danych przekazywaną podczas stosowania przekształceń danych.Ta klasa jest używana w
ResizeFeaturesakcji. Nazwy jego właściwości (w tym przypadku tylko jedna) służą do wskazywania, które kolumny w widoku danych DataView mogą być używane jako dane wejściowe akcji mapowania niestandardowego.Utwórz klasę dla funkcji o stałej
VariableLengthdługości po klasie:/// <summary> /// Class to hold the fixed length feature vector. Used to define the /// column names used as output from the custom mapping action, /// </summary> public class FixedLength { /// <summary> /// This is a fixed length vector designated by VectorType attribute. /// </summary> [VectorType(Config.FeatureLength)] public int[]? Features { get; set; } }Ta klasa jest używana w
ResizeFeaturesakcji. Nazwy jego właściwości (w tym przypadku tylko jedna) są używane do wskazania, które kolumny w DataView mogą być używane jako wyjście dla niestandardowej akcji mapowania.Należy pamiętać, że nazwa właściwości
Featuresjest określana przez model TensorFlow. Nie można zmienić tej nazwy właściwości.Utwórz klasę przewidywania po
FixedLengthklasie:/// <summary> /// Class to contain the output values from the transformation. /// </summary> public class MovieReviewSentimentPrediction { [VectorType(2)] public float[]? Prediction { get; set; } }MovieReviewSentimentPredictionto klasa przewidywania używana po trenowaniu modelu.MovieReviewSentimentPredictionma jednąfloattablicęPrediction(VectorType) i atrybut.Utwórz inną klasę do przechowywania wartości konfiguracji, takich jak długość wektora funkcji:
static class Config { public const int FeatureLength = 600; }
Tworzenie MLContext, słownika odnośników i akcji w celu skalowania cech
Klasa MLContext jest punktem wyjścia dla wszystkich operacji ML.NET. Inicjowanie mlContext tworzy nowe środowisko ML.NET, które może być współużytkowane przez obiekty przepływu pracy tworzenia modelu. Jest ona podobna, koncepcyjnie, do DBContext w programie Entity Framework.
Zastąp
Console.WriteLine("Hello World!")wiersz następującym kodem, aby zadeklarować i zainicjować zmienną mlContext:MLContext mlContext = new MLContext();Utwórz słownik do kodowania wyrazów jako liczby całkowite, używając metody
LoadFromTextFiledo załadowania danych mapowania z pliku, jak pokazano w poniższej tabeli.Słowo Index Dzieci 362 chcieć 181 błędny 355 Efekty 302 uczucie 547 Dodaj poniższy kod, aby utworzyć mapę wyszukiwania.
var lookupMap = mlContext.Data.LoadFromTextFile(Path.Combine(_modelPath, "imdb_word_index.csv"), columns: new[] { new TextLoader.Column("Words", DataKind.String, 0), new TextLoader.Column("Ids", DataKind.Int32, 1), }, separatorChar: ',' );Dodaj
Actionaby zmienić rozmiar tablicy liczb całkowitych o zmiennej długości na tablicę liczb całkowitych o stałym rozmiarze, korzystając z poniższych linii kodu.Action<VariableLength, FixedLength> ResizeFeaturesAction = (s, f) => { var features = s.VariableLengthFeatures; Array.Resize(ref features, Config.FeatureLength); f.Features = features; };
Ładowanie wstępnie wytrenowanego modelu TensorFlow
Dodaj kod, aby załadować model TensorFlow:
TensorFlowModel tensorFlowModel = mlContext.Model.LoadTensorFlowModel(_modelPath);Po załadowaniu modelu można wyodrębnić jego schemat wejściowy i wyjściowy. Schematy są wyświetlane tylko dla zainteresowań i nauki. Nie potrzebujesz tego kodu, aby aplikacja końcowa działała:
DataViewSchema schema = tensorFlowModel.GetModelSchema(); Console.WriteLine(" =============== TensorFlow Model Schema =============== "); var featuresType = (VectorDataViewType)schema["Features"].Type; Console.WriteLine($"Name: Features, Type: {featuresType.ItemType.RawType}, Size: ({featuresType.Dimensions[0]})"); var predictionType = (VectorDataViewType)schema["Prediction/Softmax"].Type; Console.WriteLine($"Name: Prediction/Softmax, Type: {predictionType.ItemType.RawType}, Size: ({predictionType.Dimensions[0]})");Schemat wejściowy jest tablicą o stałej długości zakodowanych wyrazów całkowitych. Schemat danych wyjściowych to tablica zmiennoprzecinkowa prawdopodobieństwa wskazująca, czy tonacja recenzji jest ujemna, czy dodatnia. Te wartości sumują się do 1, ponieważ prawdopodobieństwo pozytywnego wyniku jest dopełnieniem prawdopodobieństwa negatywnego sentymentu.
Tworzenie potoku ML.NET
Utwórz potok i podziel tekst wejściowy na wyrazy za pomocą przekształcenia TokenizeIntoWords, jak w następnym wierszu kodu:
IEstimator<ITransformer> pipeline = // Split the text into individual words mlContext.Transforms.Text.TokenizeIntoWords("TokenizedWords", "ReviewText")Przekształcenie TokenizeIntoWords używa spacji do analizowania tekstu/ciągu w słowa. Tworzy nową kolumnę i dzieli każdy ciąg wejściowy na wektor podciągów na podstawie separatora zdefiniowanego przez użytkownika.
Przypisz wyrazy do ich kodowania liczbami całkowitymi, używając tabeli odwzorowań zadeklarowanej powyżej.
// Map each word to an integer value. The array of integer makes up the input features. .Append(mlContext.Transforms.Conversion.MapValue("VariableLengthFeatures", lookupMap, lookupMap.Schema["Words"], lookupMap.Schema["Ids"], "TokenizedWords"))Zmień rozmiar kodowań liczb całkowitych o zmiennej długości na stałą długość wymaganą przez model:
// Resize variable length vector to fixed length vector. .Append(mlContext.Transforms.CustomMapping(ResizeFeaturesAction, "Resize"))Klasyfikuj dane wejściowe za pomocą załadowanego modelu TensorFlow:
// Passes the data to TensorFlow for scoring .Append(tensorFlowModel.ScoreTensorFlowModel("Prediction/Softmax", "Features"))Dane wyjściowe modelu TensorFlow są nazywane .
Prediction/SoftmaxNależy pamiętać, że nazwaPrediction/Softmaxjest określana przez model TensorFlow. Nie można zmienić tej nazwy.Utwórz nową kolumnę dla przewidywania danych wyjściowych:
// Retrieves the 'Prediction' from TensorFlow and copies to a column .Append(mlContext.Transforms.CopyColumns("Prediction", "Prediction/Softmax"));Musisz skopiować kolumnę
Prediction/Softmaxdo jednej z nazwą, która może być używana jako właściwość w klasie C#:Prediction. Znak/nie jest dozwolony w nazwie właściwości języka C#.
Tworzenie modelu ML.NET na podstawie potoku
Dodaj kod, aby utworzyć model z pipeline'u:
// Create an executable model from the estimator pipeline IDataView dataView = mlContext.Data.LoadFromEnumerable(new List<MovieReview>()); ITransformer model = pipeline.Fit(dataView);Model ML.NET jest tworzony z łańcucha estymatorów w potoku przez wywołanie metody
Fit. W takim przypadku nie dopasowujesz żadnych danych do utworzenia modelu, ponieważ model TensorFlow został już wcześniej wytrenowany. Należy podać pusty obiekt widoku danych, aby spełnić wymaganiaFitmetody.
Przewidywanie przy użyciu modelu
Dodaj metodę
PredictSentimentMovieReviewpowyżej klasy:void PredictSentiment(MLContext mlContext, ITransformer model) { }Dodaj następujący kod, aby utworzyć
PredictionEngineelement jako pierwszy wiersz w metodziePredictSentiment():var engine = mlContext.Model.CreatePredictionEngine<MovieReview, MovieReviewSentimentPrediction>(model);PredictionEngine to wygodny interfejs API, który umożliwia przewidywanie pojedynczego wystąpienia danych.
PredictionEnginenie jest bezpieczny wątkowo. Dopuszczalne jest użycie w środowiskach jednowątkowych lub prototypowych. Aby zwiększyć wydajność i bezpieczeństwo wątków w środowiskach produkcyjnych, użyjPredictionEnginePoolusługi, która tworzyObjectPoolPredictionEngineobiekty do użycia w całej aplikacji. Zapoznaj się z tym przewodnikiem dotyczącym używaniaPredictionEnginePoolw internetowym interfejsie API platformy ASP.NET Core.Uwaga / Notatka
PredictionEnginePoolRozszerzenie usługi jest obecnie dostępne w wersji zapoznawczej.Dodaj komentarz, aby przetestować przewidywanie wytrenowanego modelu w metodzie
Predict(), tworząc wystąpienie klasyMovieReview.var review = new MovieReview() { ReviewText = "this film is really good" };Przekaż dane komentarza testowego do elementu
Prediction Engine, dodając kolejne wiersze kodu w metodziePredictSentiment():var sentimentPrediction = engine.Predict(review);Funkcja Predict() tworzy przewidywanie dla jednego wiersza danych:
Majątek Wartość Typ Prediction [0.5459937, 0.454006255] float[] Wyświetl przewidywanie tonacji przy użyciu następującego kodu:
Console.WriteLine($"Number of classes: {sentimentPrediction.Prediction?.Length}"); Console.WriteLine($"Is sentiment/review positive? {(sentimentPrediction.Prediction?[1] > 0.5 ? "Yes." : "No.")}");Dodaj wywołanie metody po
PredictSentimentwywołaniuFit()metody :PredictSentiment(mlContext, model);
Results
Skompiluj i uruchom aplikację.
Wyniki powinny być podobne do poniższych. Podczas przetwarzania są wyświetlane komunikaty. Mogą pojawić się ostrzeżenia lub komunikaty przetwarzania. Te komunikaty zostały usunięte z poniższych wyników w celu uzyskania jasności.
Number of classes: 2
Is sentiment/review positive ? Yes
Gratulacje! Udało Ci się utworzyć model uczenia maszynowego do klasyfikowania i przewidywania tonacji komunikatów przez ponowne korzystanie z wstępnie wytrenowanego TensorFlow modelu w ML.NET.
Kod źródłowy tego samouczka można znaleźć w repozytorium dotnet/samples .
W tym samouczku nauczyłeś się następujących rzeczy:
- Ładowanie wstępnie wytrenowanego modelu TensorFlow
- Przekształcanie tekstu komentarza witryny internetowej w funkcje odpowiednie dla modelu
- Przewidywanie przy użyciu modelu
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.