Zasady dotyczące architektury
Napiwek
Ta zawartość jest fragmentem książki eBook, architekta nowoczesnych aplikacji internetowych z platformą ASP.NET Core i platformą Azure, dostępnym na platformie .NET Docs lub jako bezpłatny plik PDF do pobrania, który można odczytać w trybie offline.

"Jeśli budowniczowie zbudowali budynki w sposób, w jaki programiści pisali programy, to pierwszy dzięcioł, który przyszedł, zniszczy cywilizację."
- Gerald Weinberg
Należy zaprojektować i zaprojektować rozwiązania programowe z myślą o łatwość konserwacji. Zasady opisane w tej sekcji mogą pomóc w podejmowaniu decyzji dotyczących architektury, które spowodują czyszczenie i konserwację aplikacji. Ogólnie rzecz biorąc, te zasady prowadzą cię do tworzenia aplikacji z odrębnych składników, które nie są ściśle powiązane z innymi częściami aplikacji, ale raczej komunikują się za pośrednictwem jawnych interfejsów lub systemów obsługi komunikatów.
Typowe zasady projektowania
Separacja obaw
Wiodącą zasadą podczas opracowywania jest separacja obaw. Ta zasada potwierdza, że oprogramowanie powinno być oddzielone na podstawie rodzaju wykonywanej pracy. Rozważmy na przykład aplikację, która zawiera logikę identyfikowania godnych uwagi elementów do wyświetlenia użytkownikowi oraz formatuje takie elementy w określony sposób, aby były bardziej zauważalne. Zachowanie odpowiedzialne za wybór elementów do sformatowania powinny być oddzielone od zachowania odpowiedzialnego za formatowanie elementów, ponieważ te zachowania są oddzielnymi problemami, które są tylko przypadkowo powiązane ze sobą.
Architekturą aplikacje mogą być tworzone logicznie, aby postępować zgodnie z tą zasadą, oddzielając podstawowe zachowania biznesowe od infrastruktury i logiki interfejsu użytkownika. W idealnym przypadku reguły biznesowe i logika powinny znajdować się w osobnym projekcie, który nie powinien zależeć od innych projektów w aplikacji. Ta separacja pomaga zagwarantować, że model biznesowy jest łatwy do przetestowania i może ewoluować bez ścisłego połączenia ze szczegółami implementacji niskiego poziomu (pomaga również, jeśli problemy z infrastrukturą zależą od abstrakcji zdefiniowanych w warstwie biznesowej). Separacja problemów jest kluczowym zagadnieniem dotyczącym używania warstw w architekturach aplikacji.
Hermetyzacja
Różne części aplikacji powinny używać hermetyzacji , aby odizolować je od innych części aplikacji. Składniki i warstwy aplikacji powinny być w stanie dostosować swoją implementację wewnętrzną bez przerywania współpracy, o ile umowy zewnętrzne nie zostaną naruszone. Odpowiednie zastosowanie hermetyzacji pomaga osiągnąć luźne sprzężenie i modułowość w projektach aplikacji, ponieważ obiekty i pakiety można zastąpić alternatywnymi implementacjami, o ile ten sam interfejs jest utrzymywany.
W klasach hermetyzacja jest osiągana przez ograniczenie dostępu zewnętrznego do stanu wewnętrznego klasy. Jeśli zewnętrzny aktor chce manipulować stanem obiektu, powinien to zrobić za pomocą dobrze zdefiniowanej funkcji (lub ustawiacza właściwości), a nie bezpośredniego dostępu do stanu prywatnego obiektu. Podobnie same składniki aplikacji i aplikacje powinny uwidaczniać dobrze zdefiniowane interfejsy dla swoich współpracowników, a nie zezwalać na bezpośrednie modyfikowanie ich stanu. Takie podejście zwalnia wewnętrzny projekt aplikacji do rozwoju w miarę upływu czasu, nie martwiąc się, że spowoduje to przerwanie współpracowników, tak długo, jak umowy publiczne są utrzymywane.
Modyfikowalny stan globalny jest antytetyczny do hermetyzacji. Nie można polegać na wartości pobranej z modyfikowalnego stanu globalnego w jednej funkcji, aby mieć tę samą wartość w innej funkcji (lub jeszcze bardziej w tej samej funkcji). Zrozumienie problemów z modyfikowalnym stanem globalnym jest jednym z powodów, dla których języki programowania, takie jak C#, obsługują różne reguły określania zakresu, które są używane wszędzie od instrukcji do metod do klas. Warto zauważyć, że architektury oparte na danych, które opierają się na centralnej bazie danych na potrzeby integracji między aplikacjami, są same w sobie zależne od modyfikowalnego stanu globalnego reprezentowanego przez bazę danych. Kluczową kwestią w projektowaniu opartym na domenie i czystej architekturze jest sposób hermetyzacji dostępu do danych oraz zapewnienia, że stan aplikacji nie jest nieprawidłowy przez bezpośredni dostęp do formatu trwałości.
Inwersja zależności
Kierunek zależności w aplikacji powinien być w kierunku abstrakcji, a nie szczegółów implementacji. Większość aplikacji jest napisana w taki sposób, że przepływy zależności czasu kompilacji w kierunku wykonywania środowiska uruchomieniowego, generując wykres zależności bezpośredniej. Oznacza to, że jeśli klasa A wywołuje metodę klasy B i klasy B wywołuje metodę klasy C, wówczas w kompilowaniu klasa A będzie zależeć od klasy B, a klasa B będzie zależeć od klasy C, jak pokazano na rysunku 4-1.
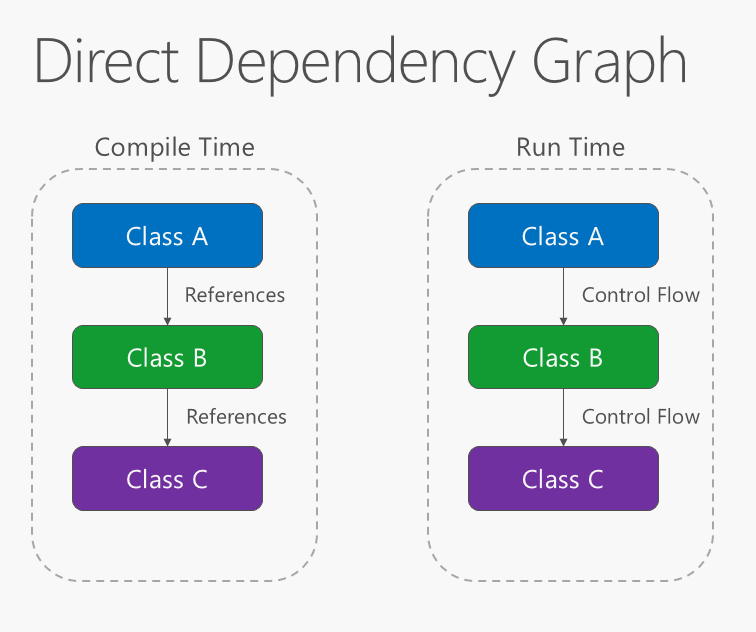
Rysunek 4–1. Wykres zależności bezpośrednich.
Zastosowanie zasady inwersji zależności umożliwia A wywołanie metod na abstrakcji implementowanej przez B, dzięki czemu można wywołać B w czasie wykonywania, ale aby B zależeć od interfejsu kontrolowanego przez A w czasie kompilacji (w związku z tym odwracając typową zależność czasu kompilacji). W czasie wykonywania przepływ wykonywania programu pozostaje niezmieniony, ale wprowadzenie interfejsów oznacza, że różne implementacje tych interfejsów można łatwo podłączyć.
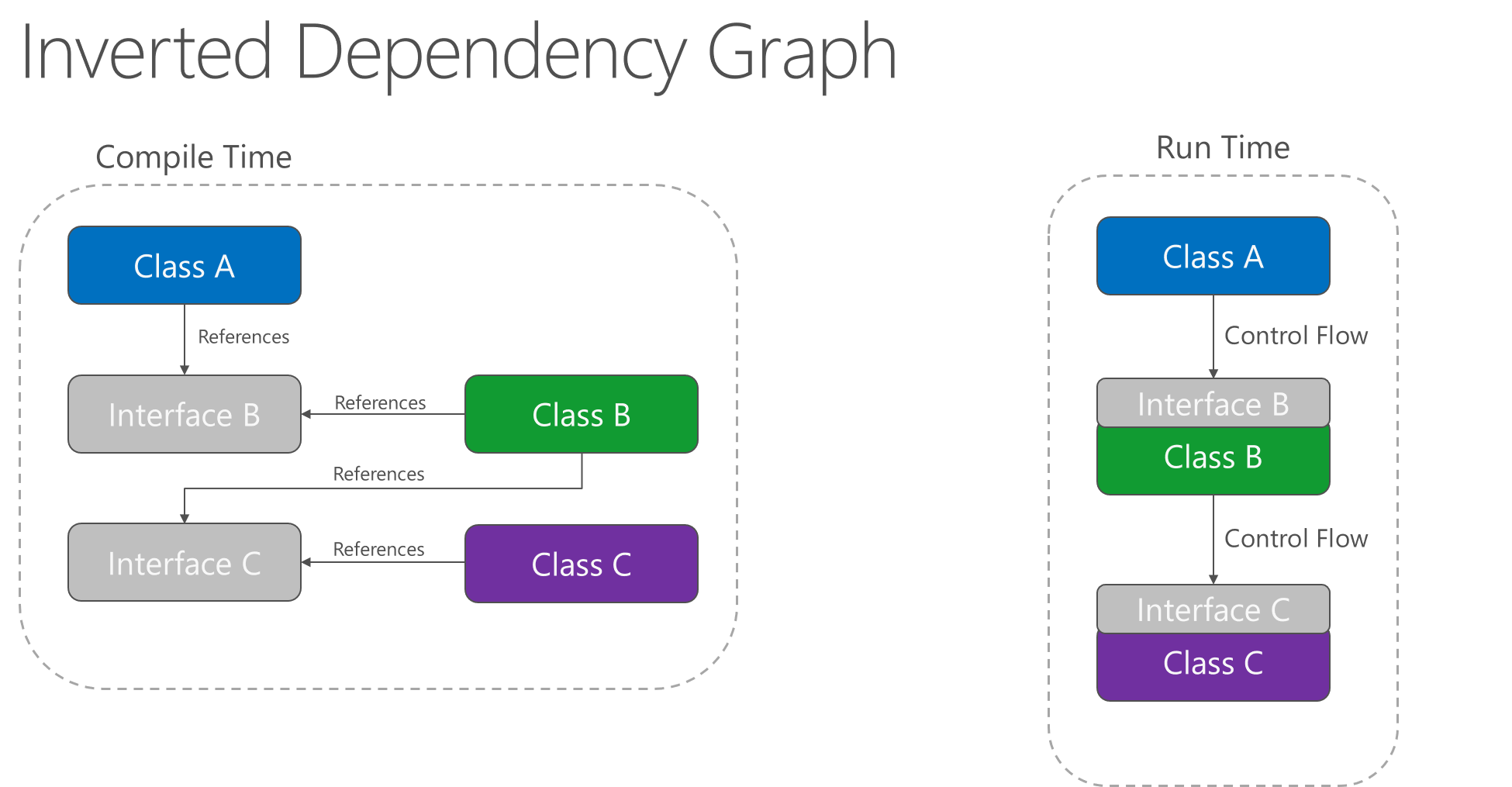
Rysunek 4–2. Odwrócony wykres zależności.
Inwersja zależności jest kluczową częścią tworzenia luźno powiązanych aplikacji, ponieważ szczegóły implementacji można zapisywać w taki sposób, aby zależeć od abstrakcji wyższego poziomu i implementować je w inny sposób. Wynikowe aplikacje są bardziej testowalne, modułowe i konserwowalne w rezultacie. Praktyka wstrzykiwania zależności jest możliwa poprzez przestrzeganie zasady inwersji zależności.
Jawne zależności
Metody i klasy powinny jawnie wymagać wszelkich potrzebnych obiektów współpracy w celu poprawnego działania. Jest ona nazywana zasadą jawnych zależności. Konstruktory klas umożliwiają klasom identyfikowanie rzeczy, których potrzebują, aby były w prawidłowym stanie i działały prawidłowo. Jeśli zdefiniujesz klasy, które można skonstruować i wywoływać, ale będą działać prawidłowo tylko wtedy, gdy istnieją pewne składniki globalne lub infrastruktury, te klasy są nieuczciwe dla ich klientów. Kontrakt konstruktora informuje klienta, że potrzebuje tylko określonych elementów (być może nic, jeśli klasa używa tylko konstruktora bez parametrów), ale w czasie wykonywania okazuje się, że obiekt naprawdę potrzebował czegoś innego.
Postępując zgodnie z jawną zasadą zależności, klasy i metody są uczciwe dla swoich klientów o tym, czego potrzebują, aby funkcjonować. Zgodnie z zasadą sprawia, że kod jest bardziej samodzielny, a kontrakty kodowania bardziej przyjazne dla użytkownika, ponieważ użytkownicy będą ufać, że tak długo, jak zapewniają to, co jest wymagane w postaci parametrów metody lub konstruktora, obiekty, z którymi pracują, będą działać prawidłowo w czasie wykonywania.
Pojedyncza odpowiedzialność
Pojedyncza zasada odpowiedzialności ma zastosowanie do projektowania zorientowanego na obiekty, ale można również uznać za zasadę architektury podobną do rozdzielenia zagadnień. Stwierdza, że obiekty powinny mieć tylko jedną odpowiedzialność i że powinny mieć tylko jeden powód do zmiany. W szczególności jedyną sytuacją, w której obiekt powinien ulec zmianie, jest to, że należy zaktualizować sposób, w jaki wykonuje jedną odpowiedzialność. Zgodnie z tą zasadą ułatwia tworzenie luźniej powiązanych i modułowych systemów, ponieważ wiele rodzajów nowych zachowań można zaimplementować jako nowe klasy, a nie przez dodanie dodatkowej odpowiedzialności do istniejących klas. Dodawanie nowych klas jest zawsze bezpieczniejsze niż zmiana istniejących klas, ponieważ żaden kod nie zależy jeszcze od nowych klas.
W aplikacji monolitycznej możemy zastosować pojedynczą zasadę odpowiedzialności na wysokim poziomie do warstw w aplikacji. Odpowiedzialność za prezentację powinna pozostać w projekcie interfejsu użytkownika, podczas gdy odpowiedzialność za dostęp do danych powinna być przechowywana w projekcie infrastruktury. Logika biznesowa powinna być przechowywana w podstawowym projekcie aplikacji, gdzie można ją łatwo przetestować i może ewoluować niezależnie od innych obowiązków.
Gdy ta zasada zostanie zastosowana do architektury aplikacji i zostanie przeniesiona do jej logicznego punktu końcowego, uzyskasz mikrousługi. Dana mikrousługa powinna mieć jedną odpowiedzialność. Jeśli musisz rozszerzyć zachowanie systemu, zwykle lepiej jest to zrobić, dodając dodatkowe mikrousługi, a nie dodając odpowiedzialności za istniejącą.
Dowiedz się więcej o architekturze mikrousług
Nie powtarzaj siebie (DRY)
Aplikacja powinna unikać określania zachowania związanego z określoną koncepcją w wielu miejscach, ponieważ jest to częste źródło błędów. W pewnym momencie zmiana wymagań będzie wymagać zmiany tego zachowania. Prawdopodobnie nie będzie można zaktualizować co najmniej jednego wystąpienia zachowania, a system będzie zachowywał się spójnie.
Zamiast duplikować logikę, hermetyzują ją w konstrukcji programowania. Utwórz tę konstrukcję jako pojedynczy urząd nad tym zachowaniem i ma inną część aplikacji, która wymaga tego zachowania, użyj nowej konstrukcji.
Uwaga
Unikaj łączenia ze sobą zachowania, które jest tylko przypadkowo powtarzalne. Na przykład, ponieważ dwie różne stałe mają tę samą wartość, nie oznacza to, że powinna istnieć tylko jedna stała, jeśli koncepcyjnie odwołują się do różnych rzeczy. Duplikowanie zawsze jest preferowane do sprzężenia z niewłaściwą abstrakcją.
Ignorancja trwałości
Ignorancja trwałości odnosi się do typów, które muszą być utrwalane, ale których kod nie ma wpływu na wybór technologii trwałości. Takie typy na platformie .NET są czasami nazywane zwykłymi starymi obiektami CLR (POC), ponieważ nie muszą dziedziczyć z konkretnej klasy bazowej ani implementować określonego interfejsu. Ignorancja trwałości jest cenna, ponieważ umożliwia utrwalanie tego samego modelu biznesowego na wiele sposobów, oferując dodatkową elastyczność aplikacji. Opcje trwałości mogą ulec zmianie w czasie, z jednej technologii bazy danych na inną lub mogą być wymagane dodatkowe formy trwałości oprócz tego, z czym aplikacja została uruchomiona (na przykład przy użyciu pamięci podręcznej Redis lub usługi Azure Cosmos DB oprócz relacyjnej bazy danych).
Oto kilka przykładów naruszeń tej zasady:
Wymagana klasa bazowa.
Wymagana implementacja interfejsu.
Klasy odpowiedzialne za zapisywanie siebie (na przykład wzorzec aktywnego rekordu).
Wymagany konstruktor bez parametrów.
Właściwości wymagające wirtualnego słowa kluczowego.
Wymagane atrybuty specyficzne dla trwałości.
Wymaganie, aby klasy miały jakiekolwiek z powyższych cech lub zachowań, dodaje sprzężenie między typami, które mają być utrwalane, oraz wybór technologii trwałości, co utrudnia wdrażanie nowych strategii dostępu do danych w przyszłości.
Konteksty ograniczone
Powiązane konteksty są centralnym wzorcem w projekcie opartym na domenie. Zapewniają one sposób radzenia sobie ze złożonością w dużych aplikacjach lub organizacjach, dzieląc je na oddzielne moduły koncepcyjne. Każdy moduł koncepcyjny reprezentuje następnie kontekst oddzielony od innych kontekstów (w związku z tym powiązanych) i może ewoluować niezależnie. Każdy ograniczony kontekst powinien być idealnie wolny, aby wybrać własne nazwy pojęć w nim i powinien mieć wyłączny dostęp do własnego magazynu trwałości.
Co najmniej poszczególne aplikacje internetowe powinny dążyć do bycia własnym powiązanym kontekstem, z własnym magazynem trwałości dla modelu biznesowego, a nie udostępnianiem bazy danych innym aplikacjom. Komunikacja między powiązanymi kontekstami odbywa się za pośrednictwem interfejsów programowych, a nie za pośrednictwem udostępnionej bazy danych, co umożliwia wykonywanie logiki biznesowej i zdarzeń w odpowiedzi na zmiany, które mają miejsce. Powiązane konteksty są mapowane ściśle na mikrousługi, które są również najlepiej implementowane jako własne konteksty ograniczone.
Dodatkowe zasoby
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla