Typowe architektury aplikacji internetowych
Napiwek
Ta zawartość jest fragmentem książki eBook, architekta nowoczesnych aplikacji internetowych z platformą ASP.NET Core i platformą Azure, dostępnym na platformie .NET Docs lub jako bezpłatny plik PDF do pobrania, który można odczytać w trybie offline.

"Jeśli uważasz, że dobra architektura jest kosztowna, spróbuj użyć złej architektury". - Brian Foote i Joseph Yoder
Większość tradycyjnych aplikacji platformy .NET jest wdrażana jako pojedyncze jednostki odpowiadające plikowi wykonywalnemu lub pojedynczej aplikacji internetowej działającej w ramach jednej domeny aplikacji usług IIS. Takie podejście jest najprostszym modelem wdrażania i bardzo dobrze obsługuje wiele wewnętrznych i mniejszych aplikacji publicznych. Jednak nawet biorąc pod uwagę tę pojedynczą jednostkę wdrożenia, większość aplikacji biznesowych niebłądnych korzysta z pewnego logicznego rozdzielenia na kilka warstw.
Co to jest aplikacja monolityczna?
Aplikacja monolityczna to aplikacja, która jest całkowicie samodzielna, pod względem jego zachowania. Może on wchodzić w interakcje z innymi usługami lub magazynami danych w trakcie wykonywania operacji, ale rdzeń jego zachowania działa we własnym procesie, a cała aplikacja jest zwykle wdrażana jako pojedyncza jednostka. Jeśli taka aplikacja musi być skalowana w poziomie, zazwyczaj cała aplikacja jest duplikowana na wielu serwerach lub maszynach wirtualnych.
Wszystkie aplikacje jednokrotne
Najmniejsza możliwa liczba projektów dla architektury aplikacji to jedna. W tej architekturze cała logika aplikacji jest zawarta w jednym projekcie, skompilowanym w jednym zestawie i wdrożona jako pojedyncza jednostka.
Nowy projekt ASP.NET Core, utworzony w programie Visual Studio lub z poziomu wiersza polecenia, zaczyna się od prostego monolitu "all-in-one". Zawiera on wszystkie zachowania aplikacji, w tym prezentację, firmę i logikę dostępu do danych. Rysunek 5–1 przedstawia strukturę plików aplikacji jednoprojektowej.
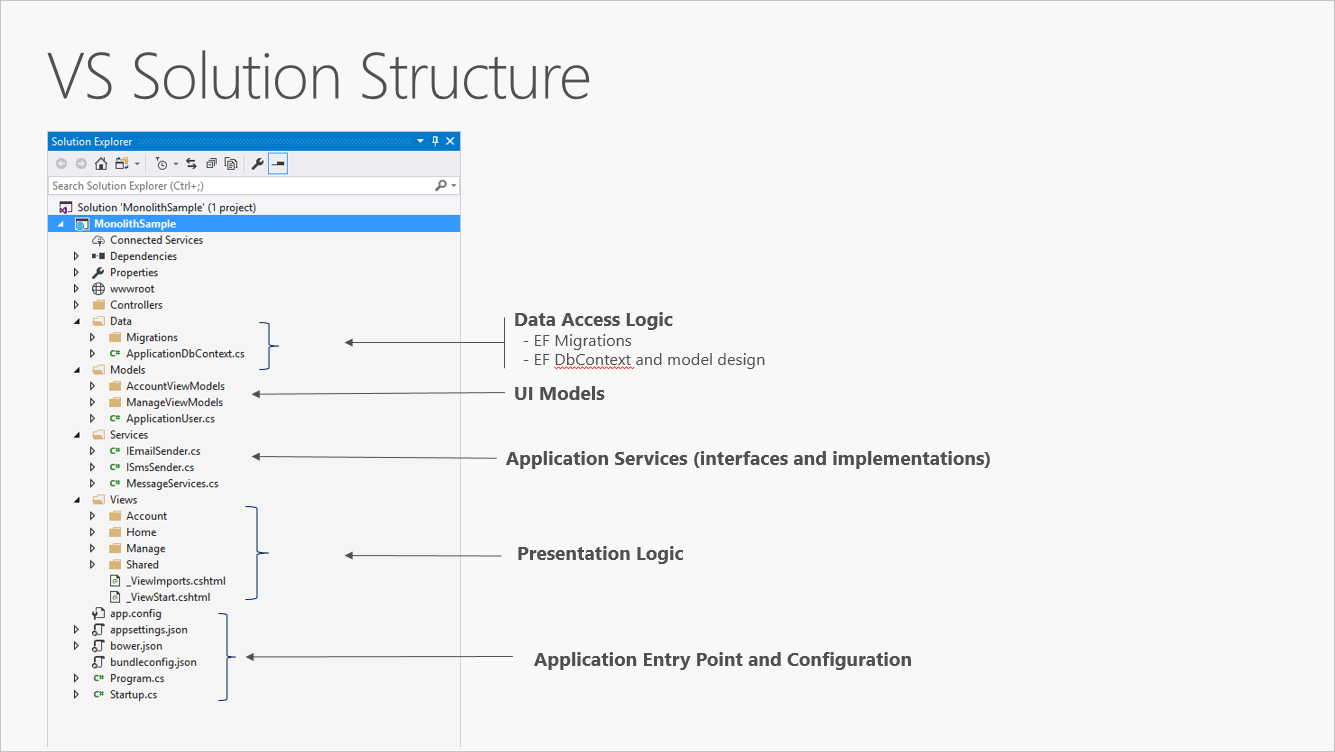
Rysunek 5–1. Pojedynczy projekt ASP.NET Core.
W jednym scenariuszu projektu separacja problemów jest osiągana za pomocą folderów. Szablon domyślny zawiera oddzielne foldery dla obowiązków wzorca MVC modeli, widoków i kontrolerów, a także dodatkowe foldery dla danych i usług. W tym układzie szczegóły prezentacji powinny być ograniczone jak najwięcej do folderu Widoki, a szczegóły implementacji dostępu do danych powinny być ograniczone do klas przechowywanych w folderze Dane. Logika biznesowa powinna znajdować się w usługach i klasach w folderze Modele.
Chociaż proste, jednoprojektowe rozwiązanie monolityczne ma pewne wady. Wraz ze wzrostem rozmiaru i złożoności projektu liczba plików i folderów będzie nadal rosła. Problemy dotyczące interfejsu użytkownika (modele, widoki, kontrolery) znajdują się w wielu folderach, które nie są grupowane alfabetycznie. Ten problem pogarsza się tylko wtedy, gdy dodatkowe konstrukcje na poziomie interfejsu użytkownika, takie jak Filtry lub ModelBinders, są dodawane we własnych folderach. Logika biznesowa jest rozproszona między folderami Modele i usługi i nie ma wyraźnego wskazania, które klasy, w których folderach powinny zależeć od innych. Ten brak organizacji na poziomie projektu często prowadzi do spaghetti kodu.
Aby rozwiązać te problemy, aplikacje często ewoluują w rozwiązania wieloprojektowe, w których każdy projekt jest uznawany za znajdujący się w określonej warstwie aplikacji.
Co to są warstwy logiczne?
W miarę zwiększania złożoności aplikacji jednym ze sposobów zarządzania tym złożonością jest podzielenie aplikacji zgodnie z jej obowiązkami lub obawami. Takie podejście jest zgodne z zasadą separacji zagadnień i może pomóc utrzymać rosnącą bazę kodu zorganizowaną tak, aby deweloperzy mogli łatwo znaleźć miejsce implementacji niektórych funkcji. Architektura warstwowa oferuje jednak wiele zalet poza organizacją kodu.
Organizując kod w warstwach, typowe funkcje niskiego poziomu mogą być ponownie używane w całej aplikacji. Ponowne użycie jest korzystne, ponieważ oznacza to, że należy napisać mniej kodu i ponieważ może umożliwić aplikacji standaryzację w ramach jednej implementacji, zgodnie z zasadą nie powtarzaj się (DRY).
W przypadku architektury warstwowej aplikacje mogą wymuszać ograniczenia dotyczące warstw, na których warstwy mogą komunikować się z innymi warstwami. Ta architektura pomaga osiągnąć hermetyzację. W przypadku zmiany lub zastąpienia warstwy należy mieć wpływ tylko na te warstwy, które z nią współpracują. Ograniczając warstwy zależne od innych warstw, można ograniczyć wpływ zmian, aby jedna zmiana nie wpływała na całą aplikację.
Warstwy (i hermetyzacja) znacznie ułatwiają zastępowanie funkcji w aplikacji. Na przykład aplikacja może początkowo używać własnej bazy danych programu SQL Server do trwałości, ale później może użyć strategii trwałości opartej na chmurze lub jednej za internetowym interfejsem API. Jeśli aplikacja prawidłowo hermetyzowała implementację trwałości w warstwie logicznej, może zostać zastąpiona przez nową warstwę, która implementuje ten sam interfejs publiczny.
Oprócz możliwości zamiany implementacji w odpowiedzi na przyszłe zmiany wymagań warstwy aplikacji mogą również ułatwić zamianę implementacji na potrzeby testowania. Zamiast pisać testy, które działają względem rzeczywistej warstwy danych lub warstwy interfejsu użytkownika aplikacji, te warstwy można zastąpić w czasie testowania fałszywymi implementacjami, które zapewniają znane odpowiedzi na żądania. Takie podejście zwykle znacznie ułatwia pisanie testów i znacznie szybsze uruchamianie w porównaniu z uruchamianiem testów względem rzeczywistej infrastruktury aplikacji.
Warstwy logiczne to powszechna technika ulepszania organizacji kodu w aplikacjach oprogramowania dla przedsiębiorstw i istnieje kilka sposobów organizowania kodu w warstwy.
Uwaga
Warstwy reprezentują separację logiczną w aplikacji. W przypadku, gdy logika aplikacji jest fizycznie dystrybuowana do oddzielnych serwerów lub procesów, te oddzielne obiekty docelowe wdrożenia fizycznego są określane jako warstwy. Jest to możliwe i dość powszechne, aby mieć aplikację N-Warstwową, która jest wdrażana w jednej warstwie.
Tradycyjne aplikacje architektury "N-Layer"
Najbardziej typową organizacją logiki aplikacji na warstwy jest pokazana na rysunku 5–2.
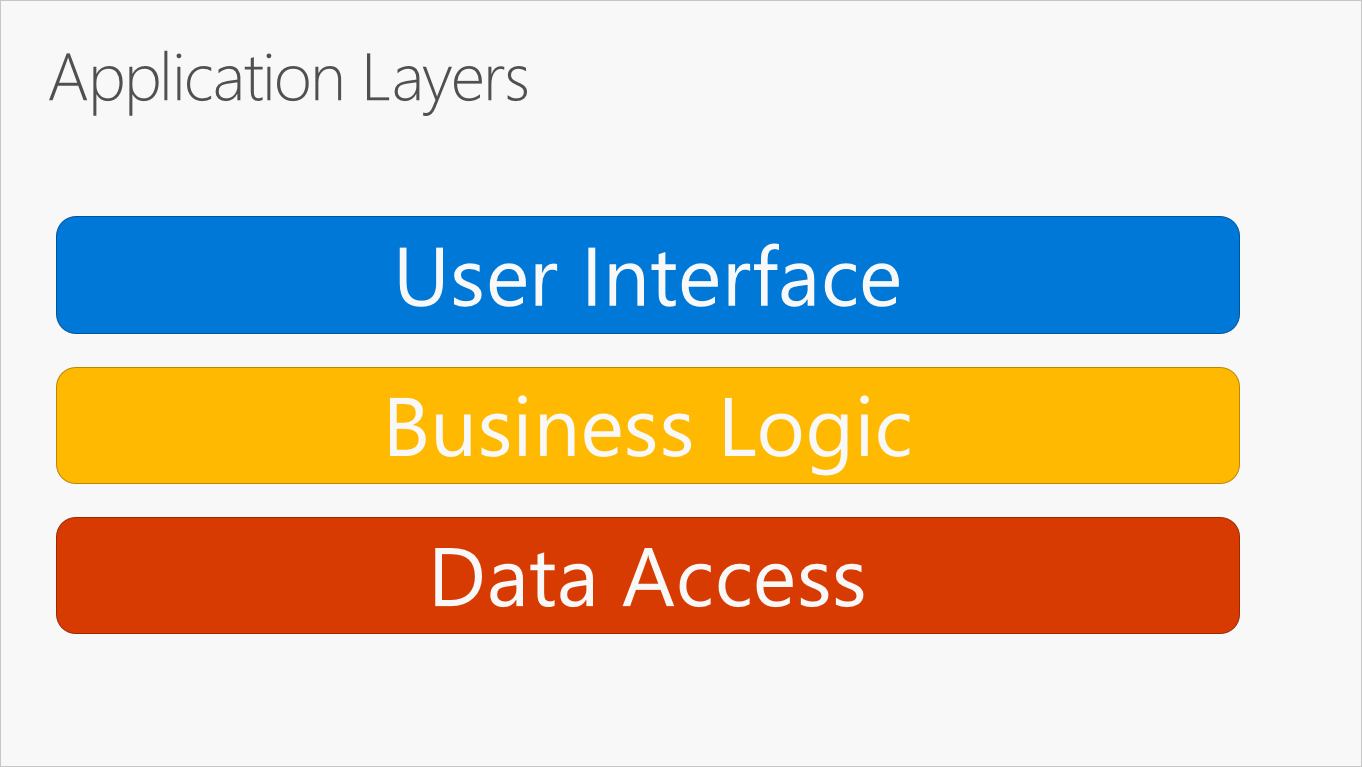
Rysunek 5–2. Typowe warstwy aplikacji.
Te warstwy są często skracane jako interfejs użytkownika, BLL (warstwa logiki biznesowej) i DAL (warstwa dostępu do danych). Korzystając z tej architektury, użytkownicy wysyłają żądania za pośrednictwem warstwy interfejsu użytkownika, która współdziała tylko z usługą BLL. Z kolei BLL może wywołać dal dla żądań dostępu do danych. Warstwa interfejsu użytkownika nie powinna bezpośrednio wysyłać żadnych żądań do dal ani nie powinna bezpośrednio korzystać z trwałości za pośrednictwem innych środków. Podobnie BLL powinien współdziałać tylko z trwałością, przechodząc przez DAL. W ten sposób każda warstwa ma własną dobrze znaną odpowiedzialność.
Jedną z wad tego tradycyjnego podejścia warstwowego jest to, że zależności czasu kompilacji są uruchamiane od góry do dołu. Oznacza to, że warstwa interfejsu użytkownika zależy od biblioteki BLL, która zależy od dal. Oznacza to, że usługa BLL, która zwykle przechowuje najważniejszą logikę w aplikacji, jest zależna od szczegółów implementacji dostępu do danych (i często od istnienia bazy danych). Testowanie logiki biznesowej w takiej architekturze jest często trudne i wymaga testowej bazy danych. Reguła inwersji zależności może służyć do rozwiązania tego problemu, jak pokazano w następnej sekcji.
Rysunek 5–3 przedstawia przykładowe rozwiązanie, które dzieli aplikację na trzy projekty według odpowiedzialności (lub warstwy).
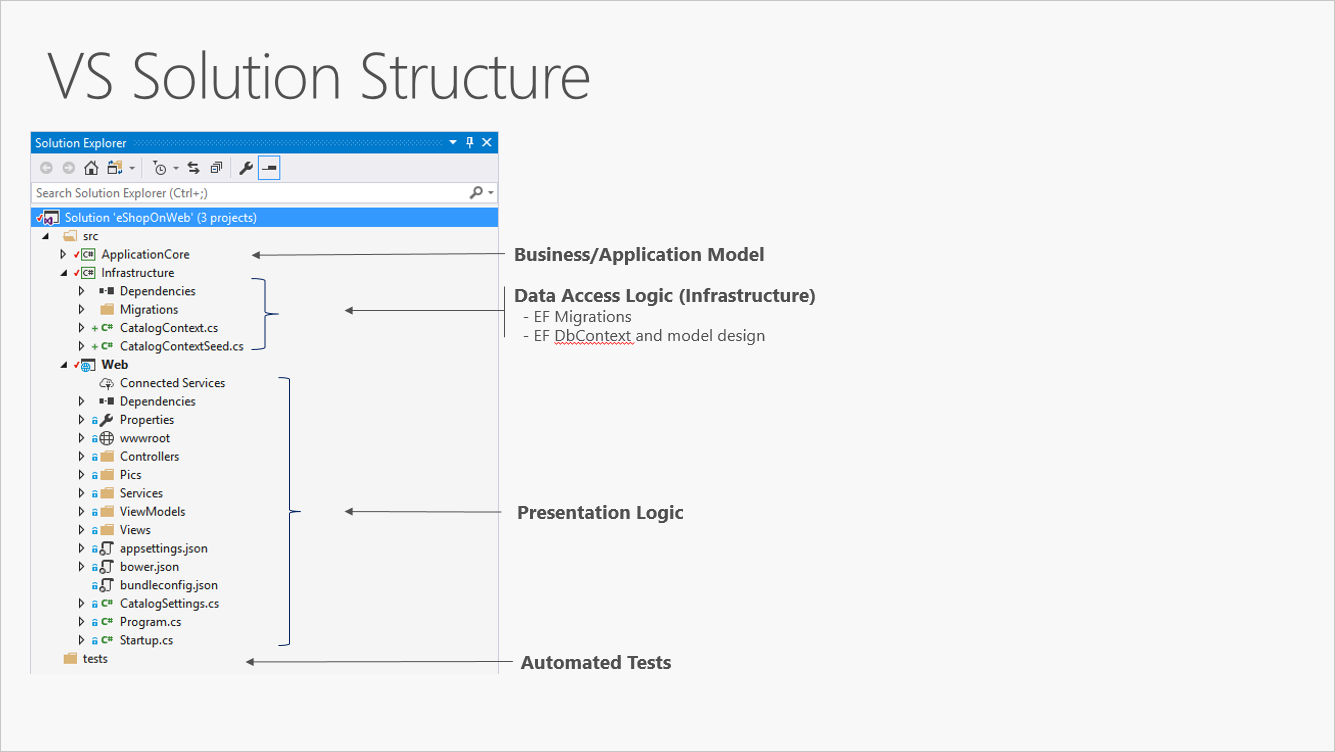
Rysunek 5–3. Prosta aplikacja monolityczna z trzema projektami.
Mimo że ta aplikacja używa kilku projektów do celów organizacyjnych, jest ona nadal wdrażana jako pojedyncza jednostka, a jej klienci będą z nią korzystać jako pojedyncza aplikacja internetowa. Umożliwia to bardzo prosty proces wdrażania. Rysunek 5–4 pokazuje, jak taka aplikacja może być hostowana przy użyciu platformy Azure.
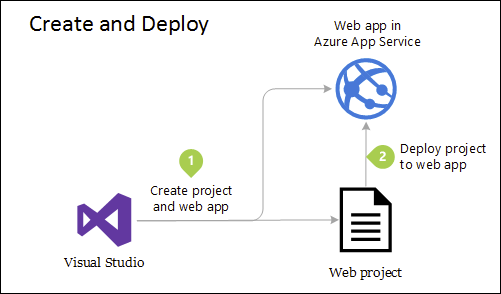
Rysunek 5–4. Proste wdrażanie aplikacji internetowej platformy Azure
W miarę rozwoju potrzeb aplikacji może być wymagane bardziej złożone i niezawodne rozwiązania wdrożeniowe. Rysunek 5–5 przedstawia przykład bardziej złożonego planu wdrażania, który obsługuje dodatkowe możliwości.
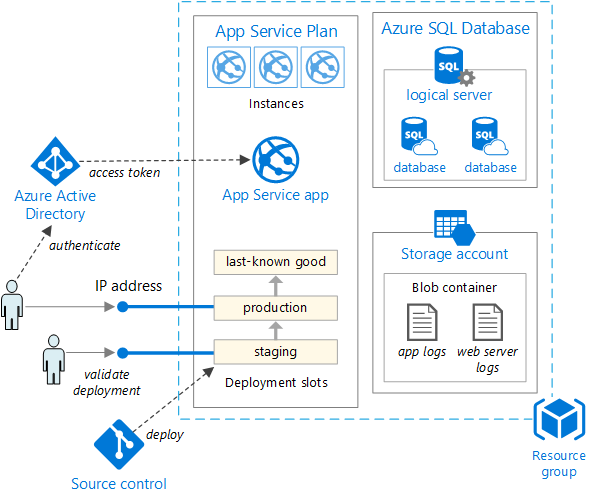
Rysunek 5–5. Wdrażanie aplikacji internetowej w usłudze aplikacja systemu Azure
Wewnętrznie organizacja tego projektu w wielu projektach w oparciu o odpowiedzialność zwiększa łatwość utrzymania aplikacji.
Tę jednostkę można skalować w górę lub w poziomie, aby korzystać ze skalowalności opartej na chmurze. Skalowanie w górę oznacza dodanie dodatkowego procesora CPU, pamięci, miejsca na dysku lub innych zasobów do serwerów hostujących aplikację. Skalowanie w poziomie oznacza dodanie dodatkowych wystąpień takich serwerów, niezależnie od tego, czy są to serwery fizyczne, maszyny wirtualne czy kontenery. Gdy aplikacja jest hostowana w wielu wystąpieniach, moduł równoważenia obciążenia służy do przypisywania żądań do poszczególnych wystąpień aplikacji.
Najprostszym podejściem do skalowania aplikacji internetowej na platformie Azure jest skonfigurowanie skalowania ręcznego w planie usługi App Service aplikacji. Rysunek 5–6 przedstawia odpowiedni ekran pulpitu nawigacyjnego platformy Azure w celu skonfigurowania liczby wystąpień obsługujących aplikację.
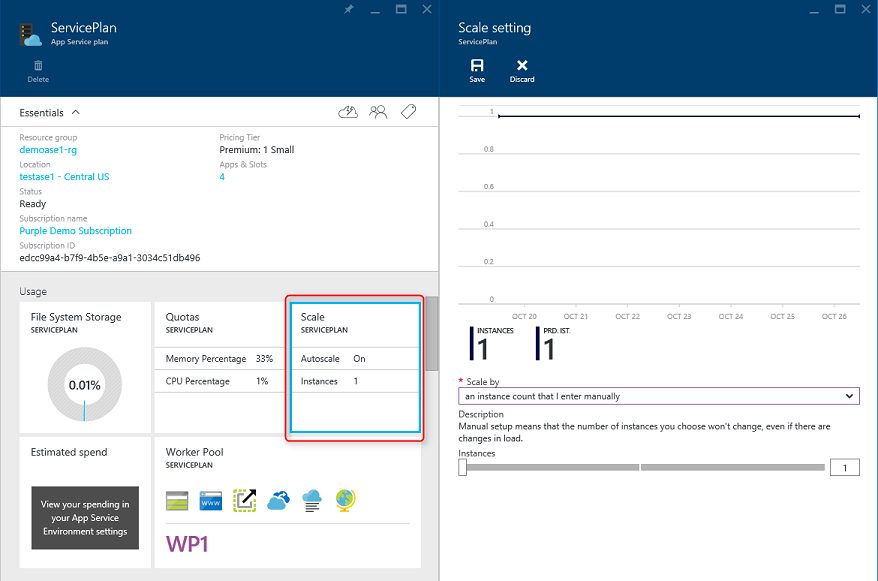
Rysunek 5–6. Skalowanie planu usługi App Service na platformie Azure.
Czysta architektura
Aplikacje zgodne z zasadą inwersji zależności, a także zasady projektowania opartego na domenie (DDD) zwykle docierają do podobnej architektury. Ta architektura minęła wiele nazw od lat. Jedną z pierwszych nazw była architektura sześciokątna, a następnie porty i karty. Ostatnio cytowano ją jako architekturę cebuli lub czystą architekturę. Ta ostatnia nazwa, Clean Architecture, jest używana jako nazwa tej architektury w tej książce e-book.
Aplikacja referencyjna eShopOnWeb używa podejścia Clean Architecture w organizowaniu kodu w projektach. Szablon rozwiązania można znaleźć jako punkt wyjścia dla własnych rozwiązań ASP.NET Core w repozytorium GitHub ardalis/cleanarchitecture lub instalując szablon z narzędzia NuGet.
Czysta architektura umieszcza logikę biznesową i model aplikacji w centrum aplikacji. Zamiast logiki biznesowej zależy od dostępu do danych lub innych problemów z infrastrukturą, ta zależność jest odwrócona: szczegóły infrastruktury i implementacji zależą od rdzenia aplikacji. Ta funkcja jest osiągana przez zdefiniowanie abstrakcji lub interfejsów w rdzeniu aplikacji, które są następnie implementowane przez typy zdefiniowane w warstwie infrastruktury. Typowym sposobem wizualizacji tej architektury jest użycie serii okręgów koncentrycznych, podobnych do cebuli. Rysunek 5–7 przedstawia przykład tego stylu reprezentacji architektury.
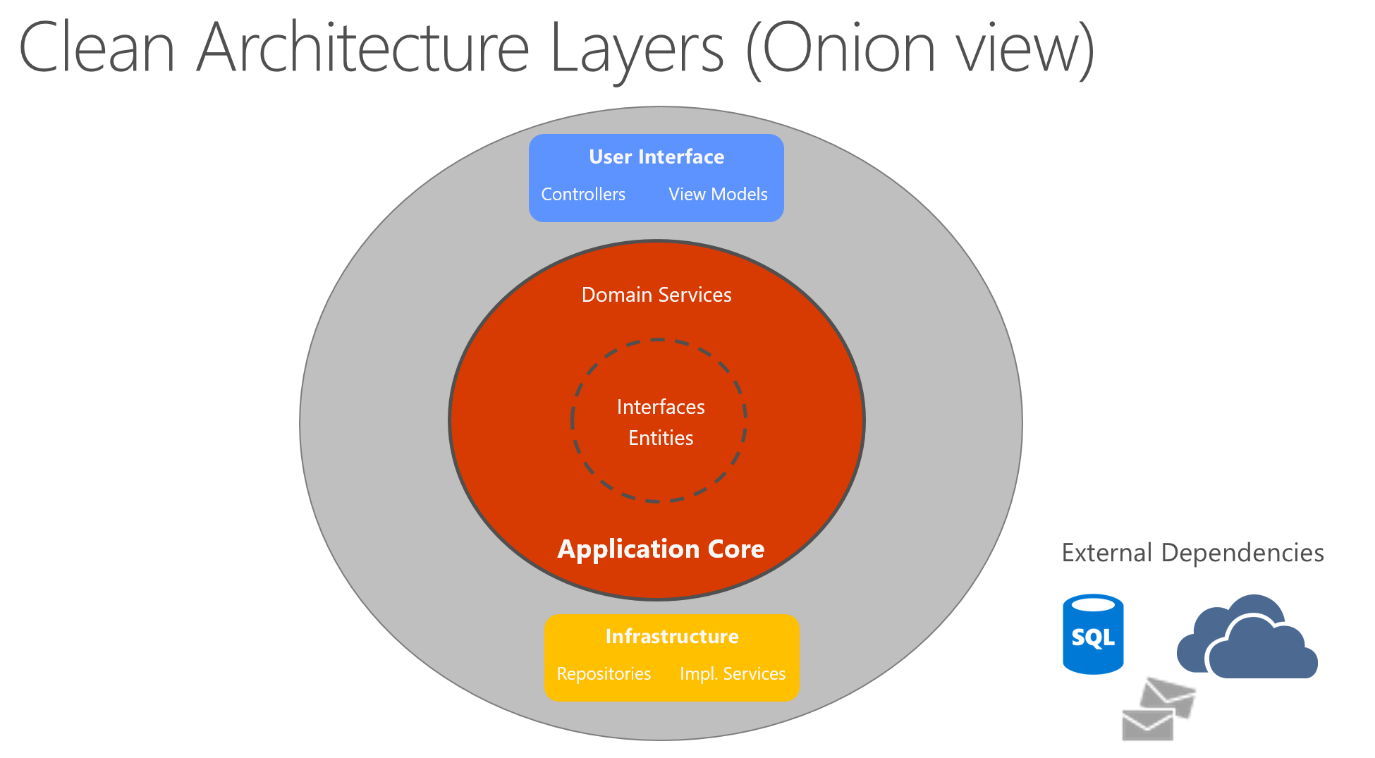
Rysunek 5–7. Czysta architektura; widok cebuli
Na tym diagramie zależności przepływają w kierunku najbardziej wewnętrznego okręgu. Aplikacja Application Core przyjmuje swoją nazwę z pozycji na rdzeniu tego diagramu. Na diagramie widać, że platforma Application Core nie ma zależności od innych warstw aplikacji. Jednostki i interfejsy aplikacji znajdują się w samym centrum. Tuż na zewnątrz, ale nadal w aplikacji Core, są usługami domenowymi, które zwykle implementują interfejsy zdefiniowane w kole wewnętrznym. Poza rdzeniem aplikacji zarówno interfejs użytkownika, jak i warstwy infrastruktury zależą od rdzenia aplikacji, ale nie od siebie (koniecznie).
Rysunek 5–8 przedstawia bardziej tradycyjny diagram warstwy poziomej, który lepiej odzwierciedla zależność między interfejsem użytkownika a innymi warstwami.
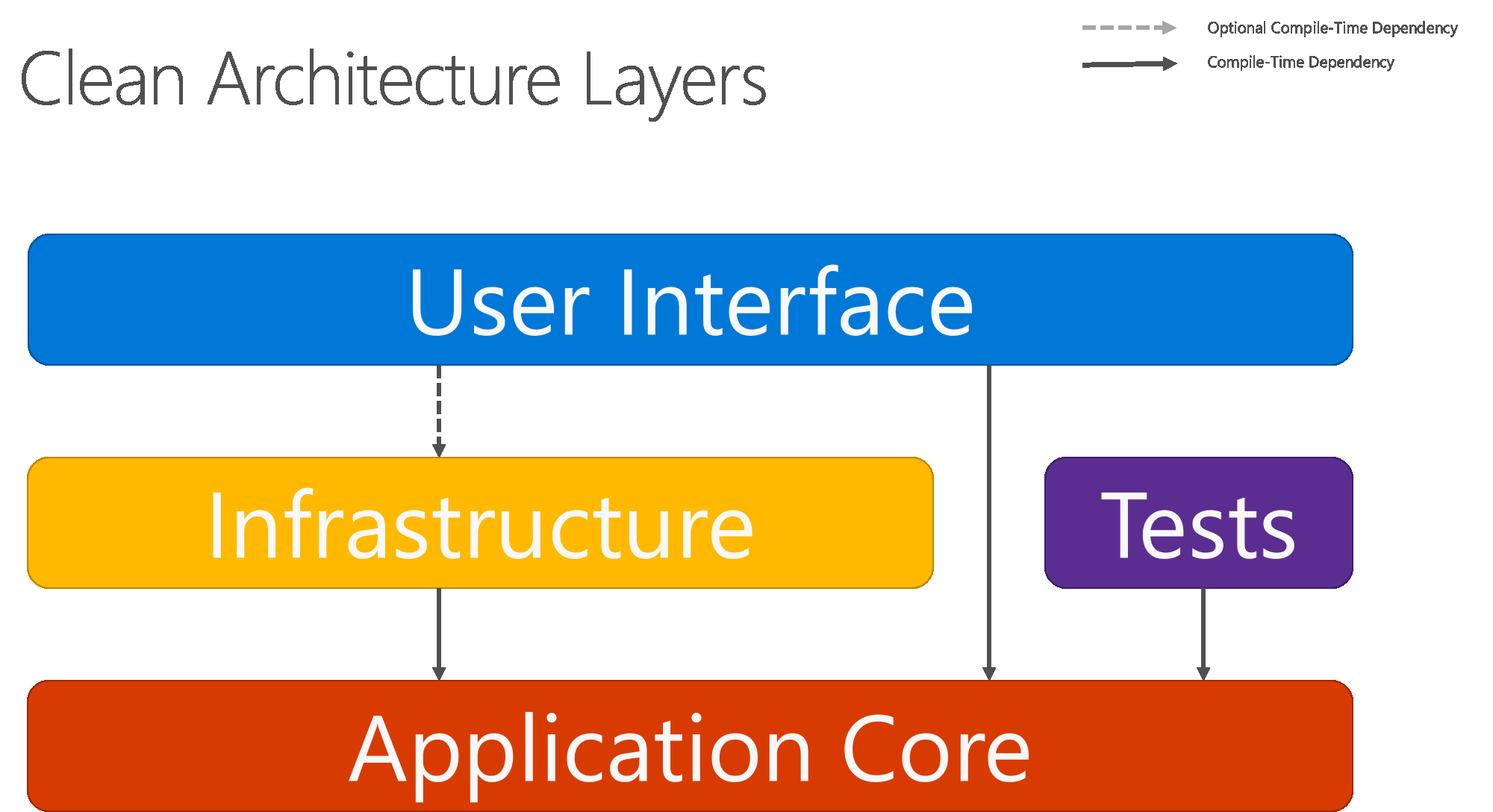
Rysunek 5–8. Czysta architektura; widok warstwy poziomej
Zwróć uwagę, że strzałki stałe reprezentują zależności czasu kompilacji, a strzałka przerywana reprezentuje zależność tylko do środowiska uruchomieniowego. W przypadku czystej architektury warstwa interfejsu użytkownika współdziała z interfejsami zdefiniowanymi w rdzeniu aplikacji w czasie kompilacji i najlepiej nie powinna wiedzieć o typach implementacji zdefiniowanych w warstwie infrastruktury. Jednak w czasie wykonywania te typy implementacji są wymagane do wykonania przez aplikację, dlatego muszą być obecne i połączone z interfejsami Application Core za pośrednictwem wstrzykiwania zależności.
Rysunek 5–9 przedstawia bardziej szczegółowy widok architektury aplikacji ASP.NET Core podczas tworzenia poniższych zaleceń.
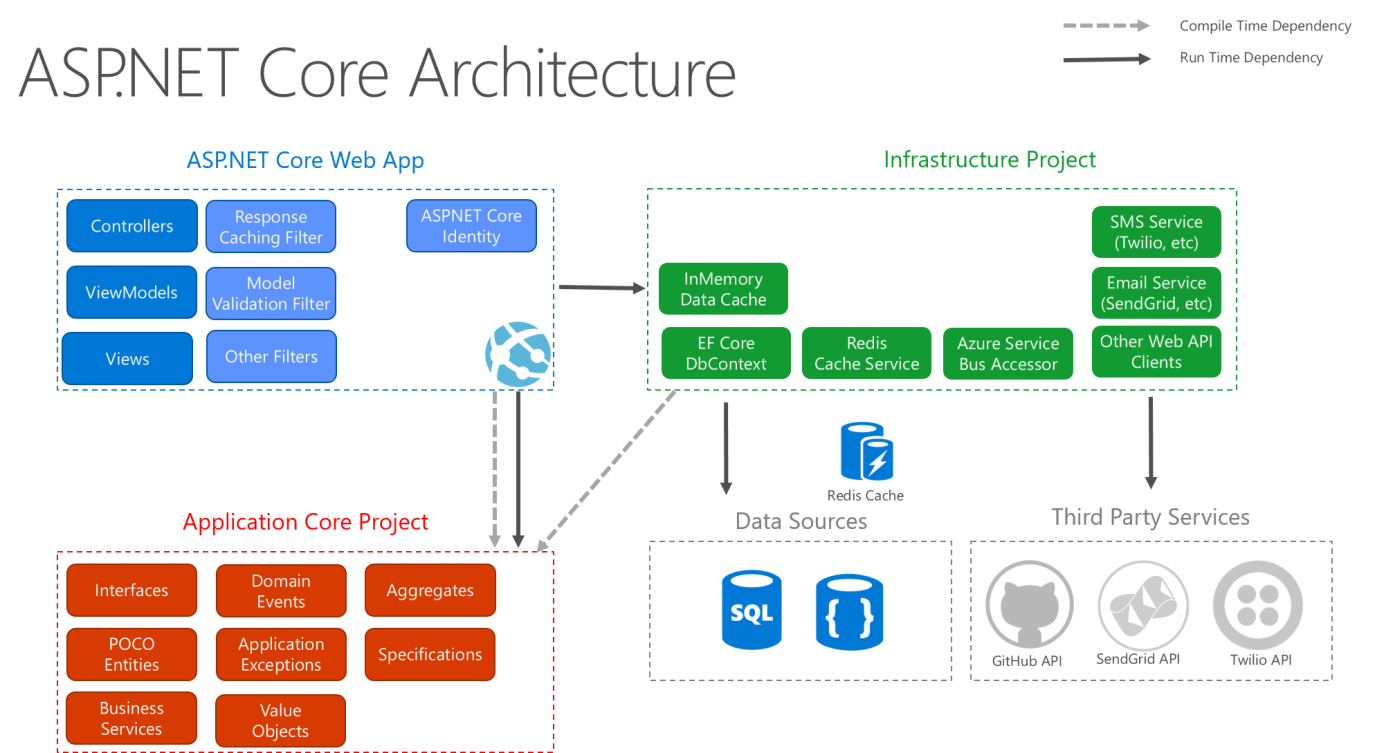
Rysunek 5–9. ASP.NET Diagram architektury podstawowej zgodnie z czystą architekturą.
Ponieważ rdzeń aplikacji nie zależy od infrastruktury, bardzo łatwo jest pisać zautomatyzowane testy jednostkowe dla tej warstwy. Na rysunkach 5-10 i 5-11 pokazano, jak testy pasują do tej architektury.
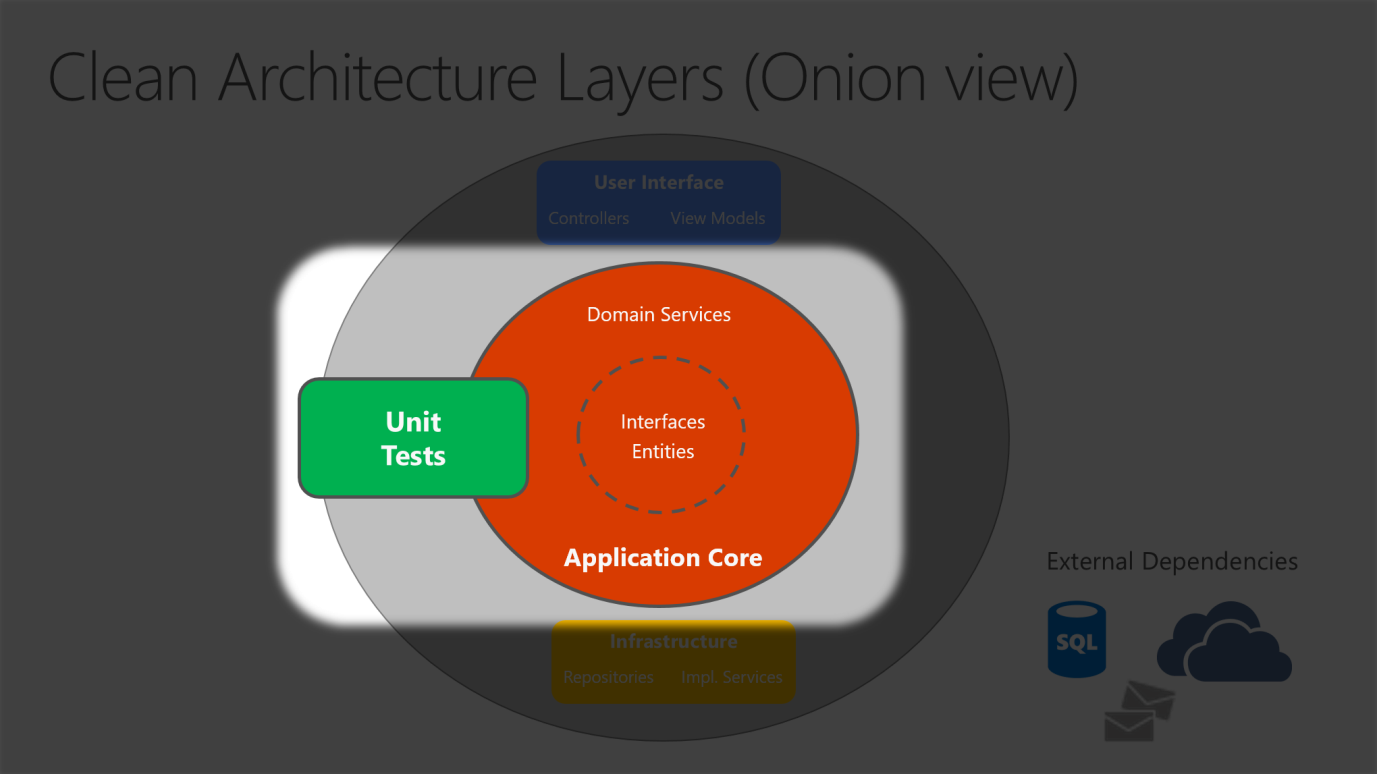
Rysunek 5–10. Testowanie jednostkowe aplikacji Core w izolacji.
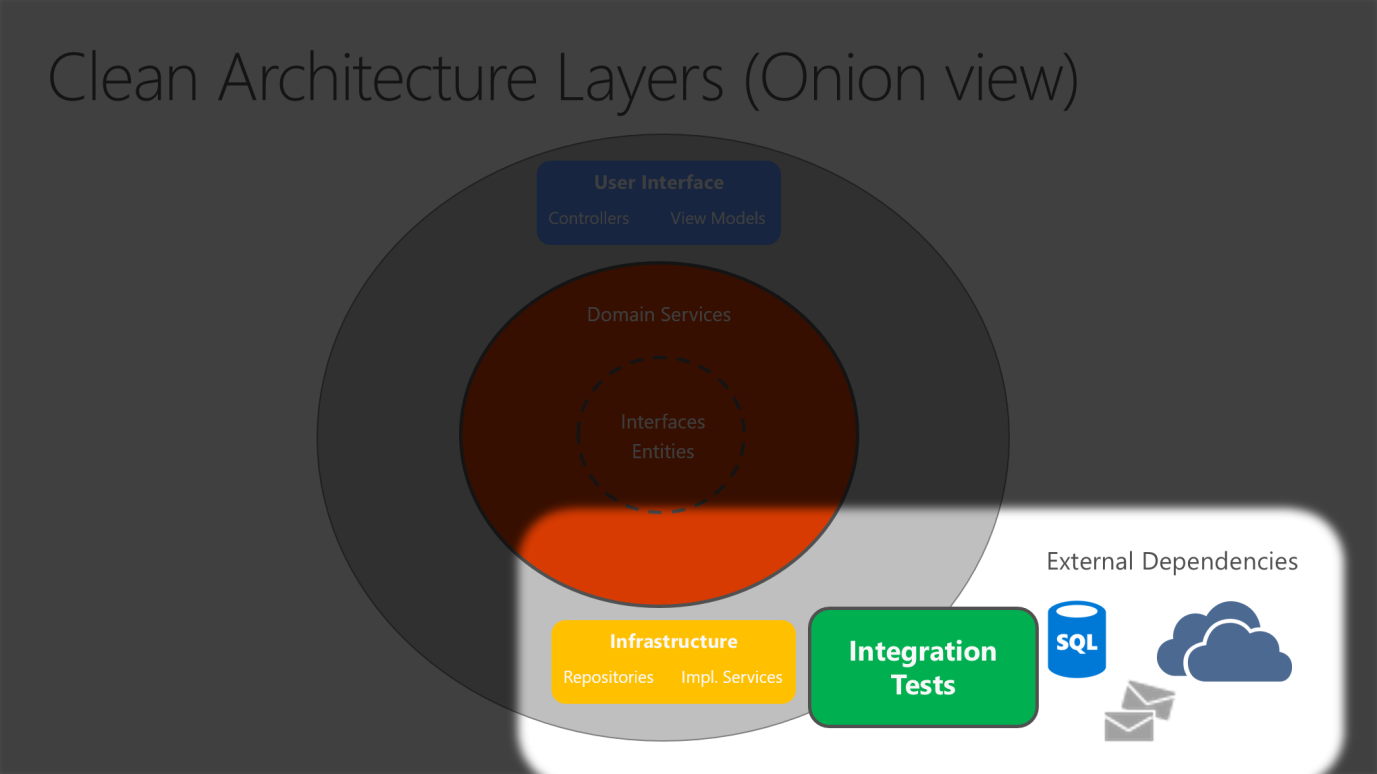
Rysunek 5–11. Implementacje infrastruktury testowania integracji z zależnościami zewnętrznymi.
Ponieważ warstwa interfejsu użytkownika nie ma żadnych bezpośrednich zależności od typów zdefiniowanych w projekcie Infrastruktura, bardzo łatwo jest zamienić implementacje, aby ułatwić testowanie lub w odpowiedzi na zmieniające się wymagania aplikacji. ASP.NET Core wbudowane zastosowanie i obsługa wstrzykiwania zależności sprawia, że ta architektura jest najbardziej odpowiednia do struktury aplikacji nietrygalnych monolitycznych.
W przypadku aplikacji monolitycznych projekty Application Core, Infrastructure i UI są uruchamiane jako pojedyncza aplikacja. Architektura aplikacji środowiska uruchomieniowego może wyglądać podobnie do rysunku 5–12.
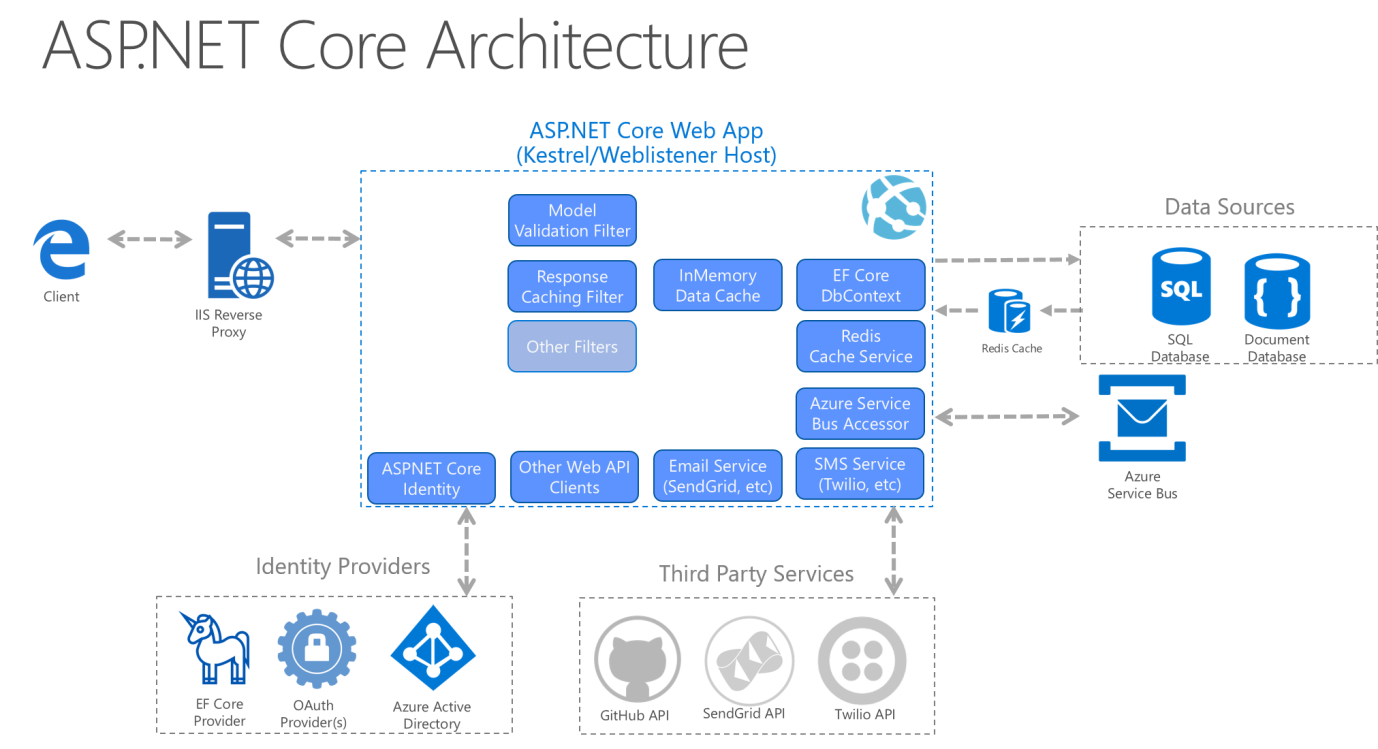
Rysunek 5–12. Przykładowa architektura środowiska uruchomieniowego aplikacji ASP.NET Core.
Organizowanie kodu w czystej architekturze
W rozwiązaniu Czystej architektury każdy projekt ma jasne obowiązki. W związku z tym niektóre typy należą do każdego projektu i często znajdziesz foldery odpowiadające tym typom w odpowiednim projekcie.
Application Core
Aplikacja Core przechowuje model biznesowy, który obejmuje jednostki, usługi i interfejsy. Te interfejsy obejmują abstrakcje operacji, które będą wykonywane przy użyciu infrastruktury, takich jak dostęp do danych, dostęp do systemu plików, wywołania sieciowe itp. Czasami usługi lub interfejsy zdefiniowane w tej warstwie muszą współpracować z typami innych niż jednostki, które nie mają zależności od interfejsu użytkownika lub infrastruktury. Można je zdefiniować jako proste obiekty transferu danych (DTO).
Typy rdzeni aplikacji
- Jednostki (klasy modelu biznesowego, które są utrwalane)
- Agregacje (grupy jednostek)
- Interfejsy
- Domain Services
- Specyfikacje
- Wyjątki niestandardowe i klauzule Guard
- Zdarzenia domeny i programy obsługi
Infrastruktura
Projekt Infrastruktura zwykle obejmuje implementacje dostępu do danych. W typowej aplikacji internetowej platformy ASP.NET Core implementacje te obejmują obiekty Programu Entity Framework (EF) DbContext, wszystkie zdefiniowane obiekty programu EF Core Migration i klasy implementacji dostępu do danych. Najczęstszym sposobem abstrakcyjnego kodu implementacji dostępu do danych jest użycie wzorca projektowego repozytorium.
Oprócz implementacji dostępu do danych projekt Infrastruktura powinien zawierać implementacje usług, które muszą współdziałać z kwestie związane z infrastrukturą. Te usługi powinny implementować interfejsy zdefiniowane w elemencie Application Core, dlatego infrastruktura powinna mieć odwołanie do projektu Application Core.
Typy infrastruktury
- Typy programu EF Core (
DbContext,Migration) - Typy implementacji dostępu do danych (repozytoria)
- Usługi specyficzne dla infrastruktury (na przykład
FileLoggerlubSmtpNotifier)
Warstwa interfejsu użytkownika
Warstwa interfejsu użytkownika w aplikacji ASP.NET Core MVC jest punktem wejścia dla aplikacji. Ten projekt powinien odwoływać się do projektu Application Core, a jego typy powinny ściśle korzystać z infrastruktury za pośrednictwem interfejsów zdefiniowanych w aplikacji Core. W warstwie interfejsu użytkownika nie powinny być dozwolone żadne bezpośrednie wystąpienia ani wywołania statyczne typów warstw infrastruktury.
Typy warstw interfejsu użytkownika
- Kontrolery
- Filtry niestandardowe
- Niestandardowe oprogramowanie pośredniczące
- Widoki
- Modele widoków
- Uruchamianie
Plik Startup klasy lub Program.cs jest odpowiedzialny za konfigurowanie aplikacji oraz podłączanie typów implementacji do interfejsów. Miejsce, w którym jest wykonywana ta logika, jest nazywane katalogiem głównym kompozycji aplikacji i umożliwia prawidłowe działanie wstrzykiwania zależności w czasie wykonywania.
Uwaga
Aby połączyć iniekcję zależności podczas uruchamiania aplikacji, projekt warstwy interfejsu użytkownika może wymagać odwołania się do projektu Infrastruktura. Tę zależność można wyeliminować z łatwością przy użyciu niestandardowego kontenera di, który ma wbudowaną obsługę ładowania typów z zestawów. Na potrzeby tego przykładu najprostszym podejściem jest umożliwienie projektowi interfejsu użytkownika odwołowania się do projektu infrastruktury (ale deweloperzy powinni ograniczyć rzeczywiste odwołania do typów w projekcie Infrastruktura do katalogu głównego kompozycji aplikacji).
Aplikacje monolityczne i kontenery
Możesz utworzyć pojedynczą i monolityczną aplikację internetową lub usługę opartą na monolitycznym wdrożeniu i wdrożyć ją jako kontener. W aplikacji może nie być monolityczna, ale zorganizowana w kilka bibliotek, składników lub warstw. Zewnętrznie jest to pojedynczy kontener z pojedynczym procesem, pojedynczą aplikacją internetową lub pojedynczą usługą.
Aby zarządzać tym modelem, należy wdrożyć pojedynczy kontener reprezentujący aplikację. Aby przeprowadzić skalowanie, wystarczy dodać dodatkowe kopie z modułem równoważenia obciążenia z przodu. Prostota pochodzi z zarządzania pojedynczym wdrożeniem w jednym kontenerze lub maszynie wirtualnej.
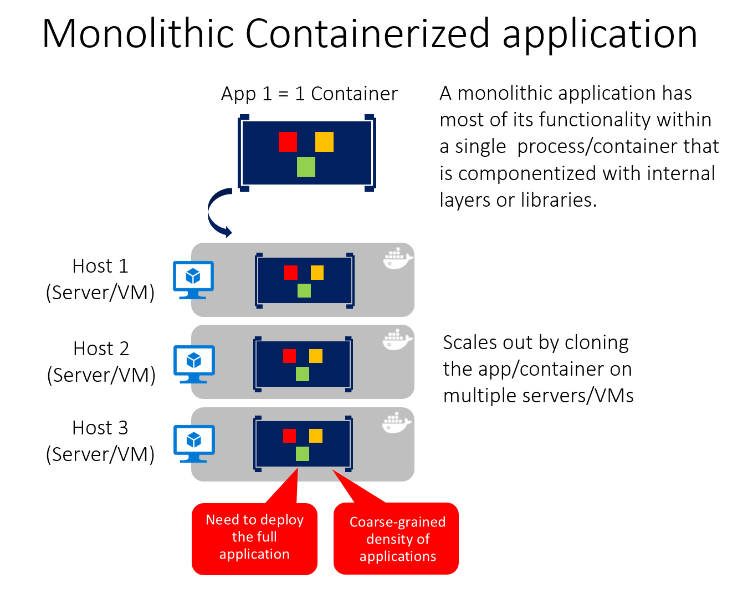
W każdym kontenerze można uwzględnić wiele składników/bibliotek lub warstw wewnętrznych, jak pokazano na rysunku 5–13. Jednak zgodnie z zasadą kontenera "kontener wykonuje jedną rzecz i robi to w jednym procesie", wzorzec monolityczny może być konfliktem.
Wadą tego podejścia jest to, czy i kiedy aplikacja rośnie, wymagając jej skalowania. Jeśli cała aplikacja jest skalowana, nie jest to naprawdę problem. Jednak w większości przypadków kilka części aplikacji jest punktami dławiania wymagającymi skalowania, podczas gdy inne składniki są używane mniej.
Korzystając z typowego przykładu handlu elektronicznego, prawdopodobnie konieczne jest skalowanie składnika informacji o produkcie. Wielu innych klientów przegląda produkty niż je kupuje. Więcej klientów korzysta z koszyka niż używa potoku płatności. Mniej klientów dodaje komentarze lub wyświetla historię zakupów. Prawdopodobnie masz tylko kilku pracowników w jednym regionie, które muszą zarządzać kampaniami marketingowymi i treściami. Skalując projekt monolityczny, cały kod jest wdrażany wiele razy.
Oprócz problemu "skalowanie wszystkiego" zmiany w jednym składniku wymagają całkowitego ponownego testowania całej aplikacji i całkowitego ponownego wdrożenia wszystkich wystąpień.
Podejście monolityczne jest powszechne, a wiele organizacji opracowuje przy użyciu tego podejścia architektonicznego. Wiele z tych osób ma wystarczająco dobre wyniki, podczas gdy inni osiągają limity. Wiele z nich zaprojektowało swoje aplikacje w tym modelu, ponieważ narzędzia i infrastruktura były zbyt trudne do tworzenia architektur zorientowanych na usługi (SOA) i nie widziały potrzeby aż do wzrostu aplikacji. Jeśli okaże się, że osiągasz limity podejścia monolitycznego, podzielenie aplikacji w celu umożliwienia jej lepszego wykorzystania kontenerów i mikrousług może być następnym krokiem logicznym.
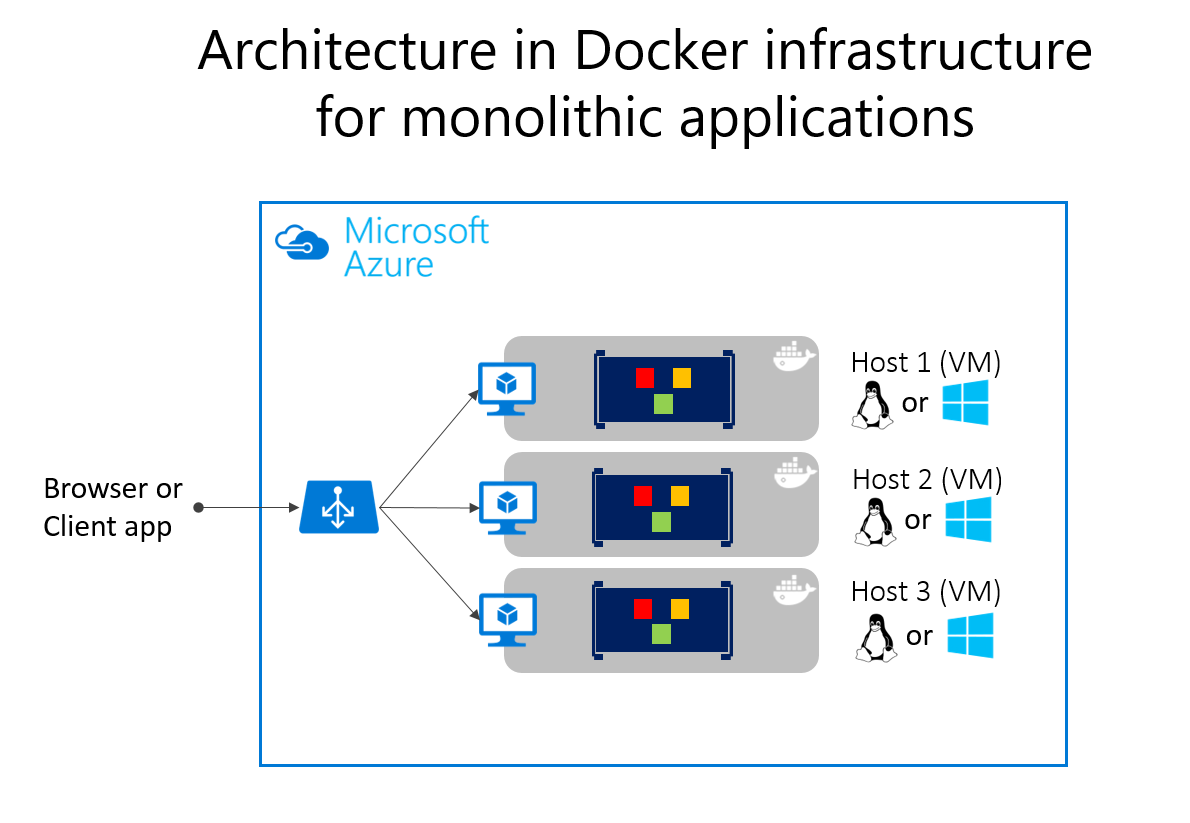
Wdrażanie aplikacji monolitycznych na platformie Microsoft Azure można osiągnąć przy użyciu dedykowanych maszyn wirtualnych dla każdego wystąpienia. Za pomocą usługi Azure Virtual Machine Scale Sets można łatwo skalować maszyny wirtualne. aplikacja systemu Azure Services mogą uruchamiać aplikacje monolityczne i łatwo skalować wystąpienia bez konieczności zarządzania maszynami wirtualnymi. aplikacja systemu Azure Services mogą również uruchamiać pojedyncze wystąpienia kontenerów platformy Docker, upraszczając wdrażanie. Za pomocą platformy Docker można wdrożyć pojedynczą maszynę wirtualną jako hosta platformy Docker i uruchomić wiele wystąpień. Korzystając z usługi Azure Balancer, jak pokazano na rysunku 5–14, możesz zarządzać skalowaniem.
Wdrożenie na różnych hostach można zarządzać przy użyciu tradycyjnych technik wdrażania. Hosty platformy Docker można zarządzać za pomocą poleceń, takich jak uruchamianie platformy Docker wykonywane ręcznie, lub za pośrednictwem potoków automatyzacji, takich jak potoki ciągłego dostarczania (CD).
Aplikacja monolityczna wdrożona jako kontener
Istnieją korzyści wynikające z używania kontenerów do zarządzania wdrożeniami aplikacji monolitycznych. Skalowanie wystąpień kontenerów jest znacznie szybsze i łatwiejsze niż wdrażanie dodatkowych maszyn wirtualnych. Nawet w przypadku używania zestawów skalowania maszyn wirtualnych do skalowania maszyn wirtualnych tworzenie ich zajmuje trochę czasu. Po wdrożeniu jako wystąpienia aplikacji konfiguracja aplikacji jest zarządzana jako część maszyny wirtualnej.
Wdrażanie aktualizacji, ponieważ obrazy platformy Docker są znacznie szybsze i wydajne w sieci. Obrazy platformy Docker zwykle rozpoczynają się w sekundach, przyspieszając wprowadzanie. Usunięcie wystąpienia platformy Docker jest tak proste, jak wydawanie docker stop polecenia, zwykle kończy się w mniej niż sekundzie.
Ponieważ kontenery są z założenia niezmienne zgodnie z projektem, nigdy nie musisz martwić się o uszkodzone maszyny wirtualne, podczas gdy skrypty aktualizacji mogą zapomnieć o określonej konfiguracji lub pliku pozostawionego na dysku.
Kontenery platformy Docker umożliwiają monolityczne wdrażanie prostszych aplikacji internetowych. Takie podejście usprawnia ciągłą integrację i potoki ciągłego wdrażania i pomaga osiągnąć sukces wdrażania w środowisku produkcyjnym. Nie ma więcej "Działa na mojej maszynie, dlaczego nie działa w środowisku produkcyjnym?"
Architektura oparta na mikrousługach ma wiele korzyści, ale te korzyści kosztują większą złożoność. W niektórych przypadkach koszty przewyższają korzyści, więc aplikacja wdrożenia monolitycznego uruchomiona w jednym kontenerze lub w kilku kontenerach jest lepszym rozwiązaniem.
Aplikacja monolityczna może nie być łatwo rozłożona na dobrze oddzielone mikrousługi. Mikrousługi powinny działać niezależnie od siebie, aby zapewnić bardziej odporną aplikację. Jeśli nie możesz dostarczać niezależnych fragmentów funkcji aplikacji, oddzielenie jej tylko zwiększa złożoność.
Aplikacja może jeszcze nie wymagać niezależnego skalowania funkcji. Wiele aplikacji, gdy konieczne jest skalowanie poza pojedyncze wystąpienie, może to zrobić za pomocą stosunkowo prostego procesu klonowania tego całego wystąpienia. Dodatkowa praca w celu oddzielenia aplikacji od dyskretnych usług zapewnia minimalną korzyść, gdy skalowanie pełnych wystąpień aplikacji jest proste i ekonomiczne.
Na wczesnym etapie tworzenia aplikacji może nie być jasne, gdzie znajdują się naturalne granice funkcjonalne. W miarę rozwoju minimalnego opłacalnego produktu naturalne rozdzielenie mogło jeszcze nie pojawić się. Niektóre z tych warunków mogą być tymczasowe. Możesz zacząć od utworzenia aplikacji monolitycznej, a później oddzielić niektóre funkcje, które mają zostać opracowane i wdrożone jako mikrousługi. Inne warunki mogą być istotne dla przestrzeni problemowej aplikacji, co oznacza, że aplikacja nigdy nie może być podzielona na wiele mikrousług.
Rozdzielenie aplikacji na wiele odrębnych procesów powoduje również narzut. Istnieje większa złożoność oddzielania funkcji do różnych procesów. Protokoły komunikacyjne stają się bardziej złożone. Zamiast wywołań metod należy użyć asynchronicznej komunikacji między usługami. Podczas przechodzenia do architektury mikrousług należy dodać wiele bloków konstrukcyjnych zaimplementowanych w wersji mikrousług aplikacji eShopOnContainers: obsługa magistrali zdarzeń, odporność komunikatów i ponawianie prób, spójność ostateczna i nie tylko.
Znacznie prostsza aplikacja referencyjna eShopOnWeb obsługuje użycie kontenerów jednokontenerowych monolitycznych. Aplikacja zawiera jedną aplikację internetową, która zawiera tradycyjne widoki MVC, internetowe interfejsy API i strony Razor. Opcjonalnie możesz uruchomić składnik administracyjny oparty na platformie Blazor aplikacji, który wymaga również uruchomienia oddzielnego projektu interfejsu API.
Aplikację można uruchomić z poziomu katalogu głównego rozwiązania przy użyciu docker-compose build poleceń i docker-compose up . To polecenie konfiguruje kontener dla wystąpienia internetowego przy użyciu Dockerfile elementu znajdującego się w katalogu głównym projektu internetowego i uruchamia kontener na określonym porcie. Źródło tej aplikacji można pobrać z usługi GitHub i uruchomić ją lokalnie. Nawet ta monolityczna aplikacja korzysta z wdrażania w środowisku kontenera.
W przypadku jednego wdrożenie konteneryzowane oznacza, że każde wystąpienie aplikacji działa w tym samym środowisku. Takie podejście obejmuje środowisko deweloperskie, w którym odbywa się wczesne testowanie i programowanie. Zespół deweloperów może uruchomić aplikację w środowisku konteneryzowanym zgodnym ze środowiskiem produkcyjnym.
Ponadto konteneryzowane aplikacje są skalowane w poziomie przy niższych kosztach. Korzystanie ze środowiska kontenera umożliwia większe udostępnianie zasobów niż tradycyjne środowiska maszyn wirtualnych.
Na koniec konteneryzacja aplikacji wymusza rozdzielenie logiki biznesowej i serwera magazynu. W miarę skalowania aplikacji w poziomie wiele kontenerów będzie polegać na jednym nośniku magazynu fizycznego. Ten nośnik magazynu zazwyczaj jest serwerem o wysokiej dostępności z uruchomioną bazą danych programu SQL Server.
Obsługa platformy Docker
Projekt eShopOnWeb jest uruchamiany na platformie .NET. W związku z tym może działać w kontenerach opartych na systemie Linux lub Windows. Należy pamiętać, że w przypadku wdrożenia platformy Docker chcesz użyć tego samego typu hosta dla programu SQL Server. Kontenery oparte na systemie Linux umożliwiają mniejsze zużycie i są preferowane.
Możesz użyć programu Visual Studio 2017 lub nowszego, aby dodać obsługę platformy Docker do istniejącej aplikacji, klikając prawym przyciskiem myszy projekt w Eksplorator rozwiązań i wybierając polecenie Dodaj>obsługę platformy Docker. Ten krok powoduje dodanie wymaganych plików i zmodyfikowanie projektu w celu ich użycia. Bieżący eShopOnWeb przykład zawiera już te pliki.
Plik na poziomie docker-compose.yml rozwiązania zawiera informacje o obrazach do skompilowania i kontenerach do uruchomienia. Plik umożliwia uruchamianie wielu aplikacji w tym samym czasie za pomocą docker-compose polecenia . W takim przypadku uruchamia tylko projekt internetowy. Można go również użyć do konfigurowania zależności, takich jak oddzielny kontener bazy danych.
version: '3'
services:
eshopwebmvc:
image: eshopwebmvc
build:
context: .
dockerfile: src/Web/Dockerfile
environment:
- ASPNETCORE_ENVIRONMENT=Development
ports:
- "5106:5106"
networks:
default:
external:
name: nat
Plik docker-compose.yml odwołuje się do Dockerfile pliku w projekcie Web . Służy Dockerfile do określania, który kontener podstawowy będzie używany i jak aplikacja zostanie skonfigurowana. Element Web" : Dockerfile
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.sln .
COPY . .
WORKDIR /app/src/Web
RUN dotnet restore
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS runtime
WORKDIR /app
COPY --from=build /app/src/Web/out ./
ENTRYPOINT ["dotnet", "Web.dll"]
Rozwiązywanie problemów z platformą Docker
Po uruchomieniu konteneryzowanej aplikacji będzie ona nadal działać, dopóki nie zostanie zatrzymana. Możesz wyświetlić, które kontenery są uruchomione za docker ps pomocą polecenia . Możesz zatrzymać uruchomiony kontener przy użyciu docker stop polecenia i określić identyfikator kontenera.
Należy pamiętać, że uruchamianie kontenerów platformy Docker może być powiązane z portami, których można użyć w innym środowisku programistycznym. Jeśli spróbujesz uruchomić lub debugować aplikację przy użyciu tego samego portu co uruchomiony kontener platformy Docker, zostanie wyświetlony błąd informujący, że serwer nie może powiązać z tym portem. Po raz kolejny zatrzymanie kontenera powinno rozwiązać ten problem.
Jeśli chcesz dodać obsługę platformy Docker do aplikacji przy użyciu programu Visual Studio, upewnij się, że program Docker Desktop jest uruchomiony, gdy to zrobisz. Kreator nie zostanie uruchomiony poprawnie, jeśli program Docker Desktop nie jest uruchomiony podczas uruchamiania kreatora. Ponadto kreator sprawdza bieżący wybór kontenera, aby dodać poprawną obsługę platformy Docker. Jeśli chcesz dodać obsługę kontenerów systemu Windows, musisz uruchomić kreatora, gdy masz skonfigurowany program Docker Desktop z kontenerami systemu Windows. Jeśli chcesz dodać, obsługa kontenerów systemu Linux uruchom kreatora, gdy masz skonfigurowaną platformę Docker z kontenerami systemu Linux.
Inne style architektury aplikacji internetowej
- Web-Queue-Worker: podstawowe składniki tej architektury to fronton internetowy obsługujący żądania klientów oraz proces roboczy wykonujący zadania intensywnie korzystające z zasobów, długotrwałe przepływy pracy lub zadania wsadowe. Fronton internetowy komunikuje się z procesem roboczym za pośrednictwem kolejki komunikatów.
- N-warstwowa: Architektura N-warstwowa dzieli aplikację na warstwy logiczne i warstwy fizyczne.
- Mikrousługi: architektura mikrousług składa się z kolekcji małych, autonomicznych usług. Każda usługa jest samodzielna i powinna implementować pojedynczą funkcję biznesową w ograniczonym kontekście.
Odwołania — typowe architektury internetowe
- Czysta architektura
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html - Architektura cebuli
https://jeffreypalermo.com/blog/the-onion-architecture-part-1/ - Wzorzec repozytorium
https://deviq.com/repository-pattern/ - Szablon rozwiązania czystej architektury
https://github.com/ardalis/cleanarchitecture - Tworzenie architektury książek elektronicznych mikrousług
https://aka.ms/MicroservicesEbook - DDD (projekt oparty na domenie)
https://learn.microsoft.com/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla