Użyj modeli opartych na usłudze Azure Machine Learning
Zunifikowane dane w Dynamics 365 Customer Insights - Data są źródłem budowania modeli uczenia maszynowego, które mogą generować dodatkowe informacje o firmie. Customer Insights - Data integruje się z usługą Azure Machine Learning w celu używania własnych modeli niestandardowych.
Wymagania wstępne
- Dostęp do usługi Customer Insights - Data
- Aktywna subskrypcja Azure Enterprise
- Ujednolicone profile klientów
- Skonfigurowany eksport tabel do usługi Azure Blob Storage
Skonfiguruj obszar roboczy Azure Machine Learning
Zobacz Tworzenie obszaru roboczego Azure Machine Learning, aby poznać różne opcje tworzenia obszaru roboczego. Aby uzyskać najlepszą wydajność, utwórz obszar roboczy w regionie świadczenia usługi Azure, który jest geograficznie najbliższy środowiska Customer Insights.
Uzyskiwanie dostępu do obszaru roboczego za pośrednictwem Azure Machine Learning Studio. Istnieje kilka sposobów interakcji z obszarem roboczym.
Praca z projektantem Azure Machine Learning
Projektant Azure Machine Learning dostarcza wizualną kanwę, na której możesz przeciągać i upuszczać zestawy danych i moduły. Potok partii utworzony przez projektanta można zintegrować Customer Insights - Data, jeśli zostaną odpowiednio skonfigurowane.
Praca z Azure Machine Learning SDK
Naukowcy zajmujący się danymi i programiści sztucznej inteligencji używają zestawu SDK usługi Azure Machine Learning do tworzenia przepływów pracy uczenia maszynowego. Obecnie modeli przeszkolonych przy użyciu zestawu SDK nie można zintegrować bezpośrednio. Potok interferencji wsadowy, który zużywa ten model i jest wymagany do integracji z Customer Insights - Data.
Wymagania dotyczące potoku wsadowego do integracji z Customer Insights - Data
Konfiguracja zestawu danych
Utwórz zestawy danych, aby używać danych tabel z Customer Insights dla potoku wnioskowania wsadowego. Zarejestruj te zestawy danych w obszarze roboczym. Obecnie są obsługiwane tylko zestawy danych tabelarycznych w formacie CSV. Parametryzuj zestawy danych odpowiadające danej tabel jako parametry potoku.
Parametry zestawu danych w projektancie
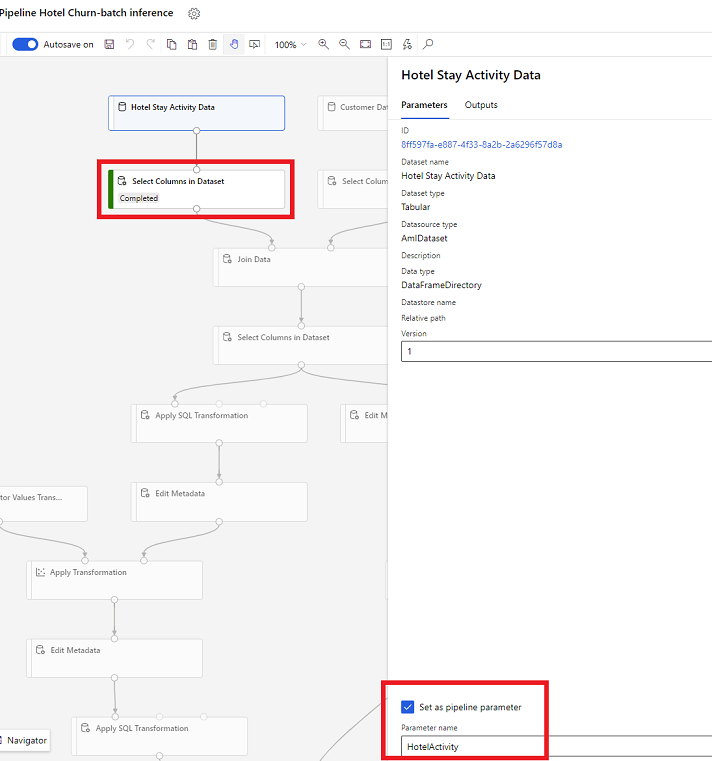
W projektancie otwórz Wybierz kolumny w zestawie danych i wybierz polecenie Ustaw jako parametr potoku, gdzie jest określona nazwa parametru.
Parametr zestawu danych w SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Potok wnioskowania wsadowego
W projektancie użyj potoku szkoleniowego do tworzenia lub aktualizowania potoku wnioskowania. Obecnie obsługiwane są tylko potoki wnioskowania wsadowego.
Za pomocą zestawu SDK opublikuj potok do punktu końcowego. Obecnie Customer Insights - Data integruje się z domyślną potokiem w potoku wsadowym, punkt końcowy w Obszar roboczy usługi Machine Learning.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Import danych potoku
Projektant dostarcza moduł eksportowania danych, który umożliwia wyeksportowanie danych wyjściowych z potoku do usługi Azure Storage. Obecnie moduł musi używać typu magazynu danych Azure Blob Storage i sparametryzować Magazyn danych i względną Ścieżkę. System zastępuje oba te parametry podczas wykonywania potoku magazynem danych i ścieżką dostępną dla aplikacji.
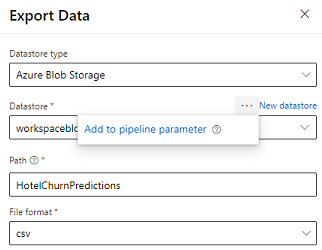
Przy tworzeniu danych wyjściowych dotyczących wnioskowania przy użyciu kodu można przekazać wyniki na ścieżkę z zarejestrowanego magazynu danych w obszarze roboczym. Jeśli ścieżka i datametra są parametryzowane w potoku, aplikacja Customer Insights może odczytać i zaimportować parametr wyjściowy inference. Obecnie obsługiwany jest tylko jeden format danych wyjściowych w formacie CSV. Ścieżka musi zawierać katalog i nazwę pliku.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name