Tworzenie zasobów danych i zarządzanie nimi
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
W tym artykule pokazano, jak tworzyć zasoby danych i zarządzać nimi w usłudze Azure Machine Learning.
Zasoby danych mogą pomóc w razie potrzeby:
- Przechowywanie wersji: zasoby danych obsługują przechowywanie wersji danych.
- Powtarzalność: po utworzeniu wersji zasobu danych jest ona niezmienna. Nie można go modyfikować ani usuwać. W związku z tym zadania szkoleniowe lub potoki, które używają zasobu danych, można odtworzyć.
- Inspekcja: ponieważ wersja zasobu danych jest niezmienna, można śledzić wersje zasobów, które zaktualizowały wersję i kiedy wystąpiły aktualizacje wersji.
- Pochodzenie: w przypadku dowolnego zasobu danych można wyświetlić, które zadania lub potoki zużywają dane.
- Łatwość użycia: zasób danych usługi Azure Machine Learning przypomina zakładki przeglądarki internetowej (ulubione). Zamiast pamiętać długie ścieżki magazynowania odwołujące się do często używanych danych w usłudze Azure Storage, możesz utworzyć wersję zasobu danych, a następnie uzyskać dostęp do tej wersji zasobu z przyjazną nazwą (na przykład:
azureml:<my_data_asset_name>:<version>).
Napiwek
Aby uzyskać dostęp do danych w sesji interaktywnej (na przykład notesu) lub zadania, nie musisz najpierw tworzyć zasobu danych. Aby uzyskać dostęp do danych, możesz użyć identyfikatorów URI magazynu danych. Identyfikatory URI magazynu danych oferują prosty sposób uzyskiwania dostępu do danych w celu rozpoczęcia pracy z usługą Azure Machine Learning.
Wymagania wstępne
Aby utworzyć zasoby danych i pracować z nimi, potrzebne są następujące elementy:
Subskrypcja Azure. Jeśli nie masz subskrypcji, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Obszar roboczy usługi Azure Machine Learning. Tworzenie zasobów obszaru roboczego.
Zainstalowany interfejs wiersza polecenia/zestaw SDK usługi Azure Machine Learning.
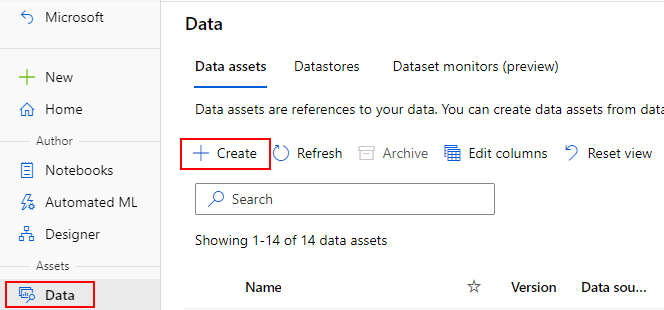
Tworzenie zasobów danych
Podczas tworzenia zasobu danych należy ustawić typ zasobu danych. Usługa Azure Machine Learning obsługuje trzy typy zasobów danych:
| Typ | interfejs API | Scenariusze kanoniczne |
|---|---|---|
| Plik Odwołanie do pojedynczego pliku |
uri_file |
Odczyt pojedynczego pliku w usłudze Azure Storage (plik może mieć dowolny format). |
| Folder Odwołuje się do folderu |
uri_folder |
Odczytaj folder plików parquet/CSV do biblioteki Pandas/Spark. Odczytywanie danych bez struktury (obrazów, tekstu, dźwięku itp.) znajdujących się w folderze. |
| Tabela Odwołanie do tabeli danych |
mltable |
Masz złożony schemat, który podlega częstym zmianom lub potrzebujesz podzbioru dużych danych tabelarycznych. AutoML z tabelami. Odczytywanie danych bez struktury (obrazów, tekstu, dźwięku itp.) danych rozmieszczonych w wielu lokalizacjach przechowywania. |
Uwaga
Użyj tylko osadzonych linii w plikach CSV, jeśli zarejestrujesz dane jako tabelę MLTable. Osadzone linie nowego wiersza w plikach CSV mogą powodować nieprawidłowe wartości pól podczas odczytywania danych. Tabela MLTable ma support_multi_line parametr dostępny w transformacji read_delimited , aby interpretować cudzysłów wierszy jako jeden rekord.
Gdy używasz zasobu danych w zadaniu usługi Azure Machine Learning, możesz zainstalować lub pobrać zasób do węzłów obliczeniowych. Aby uzyskać więcej informacji, odwiedź stronę Tryby.
Ponadto należy określić parametr wskazujący lokalizację path zasobu danych. Obsługiwane ścieżki obejmują:
| Lokalizacja | Przykłady |
|---|---|
| Ścieżka na komputerze lokalnym | ./home/username/data/my_data |
| Ścieżka w magazynie danych | azureml://datastores/<data_store_name>/paths/<path> |
| Ścieżka na publicznym serwerze HTTP | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Ścieżka w usłudze Azure Storage | (Obiekt blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS Gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS Gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Uwaga
Podczas tworzenia zasobu danych na podstawie ścieżki lokalnej zostanie on automatycznie przekazany do domyślnego magazynu danych w chmurze usługi Azure Machine Learning.
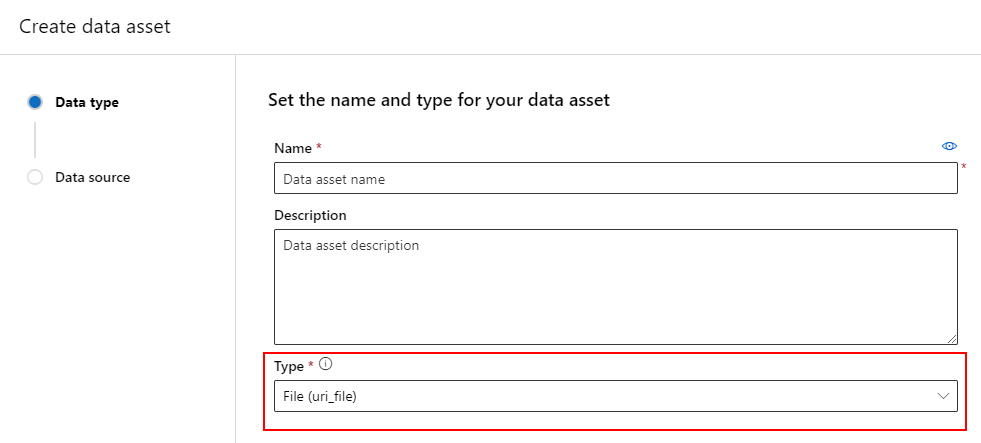
Tworzenie zasobu danych: typ pliku
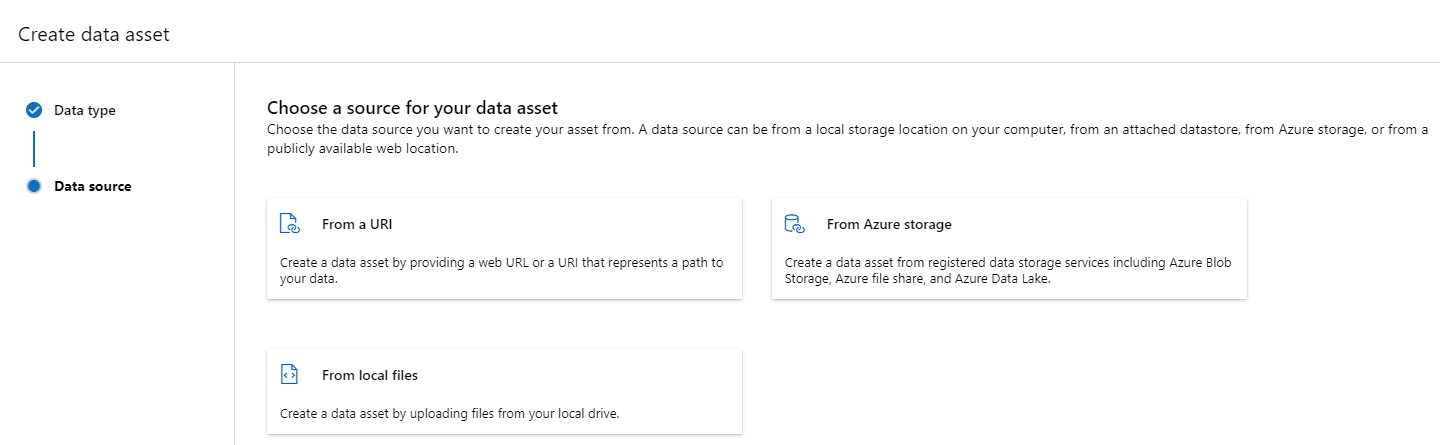
Zasób danych typu Plik (uri_file) wskazuje pojedynczy plik w magazynie (na przykład plik CSV). Zasób danych wpisanych w pliku można utworzyć za pomocą:
Utwórz plik YAML i skopiuj i wklej poniższy fragment kodu. Pamiętaj, aby zaktualizować <> symbole zastępcze za pomocą elementu
- nazwa zasobu danych
- wersja
- opis
- ścieżka do pojedynczego pliku w obsługiwanej lokalizacji
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Następnie wykonaj następujące polecenie w interfejsie wiersza polecenia. Pamiętaj, aby zaktualizować <filename> symbol zastępczy do nazwy pliku YAML.
az ml data create -f <filename>.yml
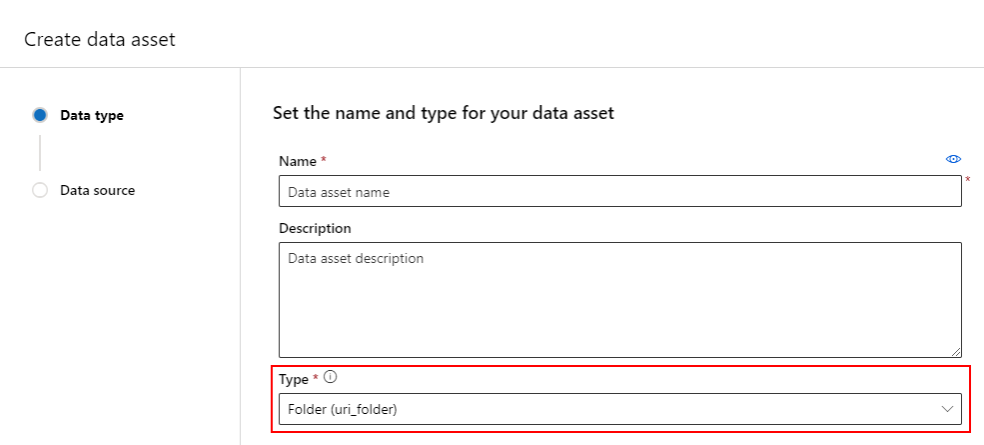
Tworzenie zasobu danych: typ folderu
Folder (uri_folder) typ zasobu danych wskazuje folder w zasobie magazynu — na przykład folder zawierający kilka podfolderów obrazów. Zasób danych wpisanych w folderze można utworzyć za pomocą:
Skopiuj i wklej następujący kod do nowego pliku YAML. Pamiętaj, aby zaktualizować <> symbole zastępcze za pomocą elementu
- Nazwa zasobu danych
- Wersja
- opis
- Ścieżka do folderu w obsługiwanej lokalizacji
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Następnie wykonaj następujące polecenie w interfejsie wiersza polecenia. Pamiętaj, aby zaktualizować <filename> symbol zastępczy do nazwy pliku YAML.
az ml data create -f <filename>.yml
Tworzenie zasobu danych: typ tabeli
Tabele usługi Azure Machine Learning (MLTable) mają zaawansowane funkcje opisane w temacie Praca z tabelami w usłudze Azure Machine Learning. Zamiast powtarzać tę dokumentację w tym miejscu, przeczytaj ten przykład, który opisuje sposób tworzenia zasobu danych typu Tabela z danymi Titanic znajdującymi się na publicznie dostępnym koncie usługi Azure Blob Storage.
Najpierw utwórz nowy katalog o nazwie data i utwórz plik o nazwie MLTable:
mkdir data
touch MLTable
Następnie skopiuj i wklej następujący kod YAML do pliku MLTable utworzonego w poprzednim kroku:
Uwaga
Nie zmieniaj nazwy pliku na MLTable.yaml MLTable lub MLTable.yml. Usługa Azure Machine Learning oczekuje MLTable pliku.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Wykonaj następujące polecenie w interfejsie wiersza polecenia. Pamiętaj, aby zaktualizować <> symbole zastępcze przy użyciu nazwy zasobu danych i wartości wersji.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Ważne
Powinien path to być folder zawierający prawidłowy MLTable plik.
Tworzenie zasobów danych na podstawie danych wyjściowych zadania
Zasób danych można utworzyć na podstawie zadania usługi Azure Machine Learning. W tym celu ustaw name parametr w danych wyjściowych. W tym przykładzie przesyłasz zadanie, które kopiuje dane z publicznego magazynu obiektów blob do domyślnego magazynu danych usługi Azure Machine Learning i tworzy zasób danych o nazwie job_output_titanic_asset.
Utwórz plik YAML specyfikacji zadania (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Następnie prześlij zadanie przy użyciu interfejsu wiersza polecenia:
az ml job create --file <file-name>.yml
Zarządzanie zasobami danych
Usuwanie zasobu danych
Ważne
Zgodnie z projektem usuwanie zasobów danych nie jest obsługiwane.
Jeśli usługa Azure Machine Learning zezwoliłaby na usunięcie zasobów danych, będzie to miało następujące niekorzystne i negatywne skutki:
- Zadania produkcyjne, które zużywają zasoby danych, które zostały później usunięte, zakończy się niepowodzeniem.
- Byłoby trudniej odtworzyć eksperyment ML.
- Pochodzenie zadania spowodowałoby przerwanie, ponieważ nie można wyświetlić usuniętej wersji zasobu danych.
- Nie można prawidłowo śledzić i przeprowadzać inspekcji , ponieważ mogą brakować wersji.
W związku z tym niezmienność zasobów danych zapewnia poziom ochrony podczas pracy w zespole tworzącym obciążenia produkcyjne.
W przypadku błędnie utworzonego zasobu danych — na przykład z nieprawidłową nazwą, typem lub ścieżką — usługa Azure Machine Learning oferuje rozwiązania do obsługi sytuacji bez negatywnych konsekwencji usunięcia:
| Chcę usunąć ten zasób danych, ponieważ... | Rozwiązanie |
|---|---|
| Nazwa jest nieprawidłowa | Archiwizowanie zasobu danych |
| Zespół nie korzysta już z zasobu danych | Archiwizowanie zasobu danych |
| Zaśmieca listę zasobów danych | Archiwizowanie zasobu danych |
| Ścieżka jest niepoprawna | Utwórz nową wersję zasobu danych (taką samą nazwę) z poprawną ścieżką. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie zasobów danych. |
| Ma niepoprawny typ | Obecnie usługa Azure Machine Learning nie zezwala na tworzenie nowej wersji z innym typem w porównaniu z początkową wersją. (1) Archiwizowanie zasobu danych (2) Utwórz nowy zasób danych pod inną nazwą z poprawnym typem. |
Archiwizowanie zasobu danych
Archiwizowanie zasobu danych domyślnie ukrywa je przed obydwoma zapytaniami listy (na przykład w interfejsie wiersza polecenia az ml data list) i listą elementów zawartości danych w interfejsie użytkownika programu Studio. Nadal możesz odwoływać się do zarchiwizowanego zasobu danych i używać go w przepływach pracy. Możesz zarchiwizować jedną z następujących czynności:
- Wszystkie wersje zasobu danych pod daną nazwą
lub
- Określona wersja zasobu danych
Archiwizowanie wszystkich wersji zasobu danych
Aby zarchiwizować wszystkie wersje zasobu danych pod daną nazwą, użyj:
Uruchom następujące polecenie. Pamiętaj, aby zaktualizować <> symbole zastępcze przy użyciu Twoich informacji.
az ml data archive --name <NAME OF DATA ASSET>
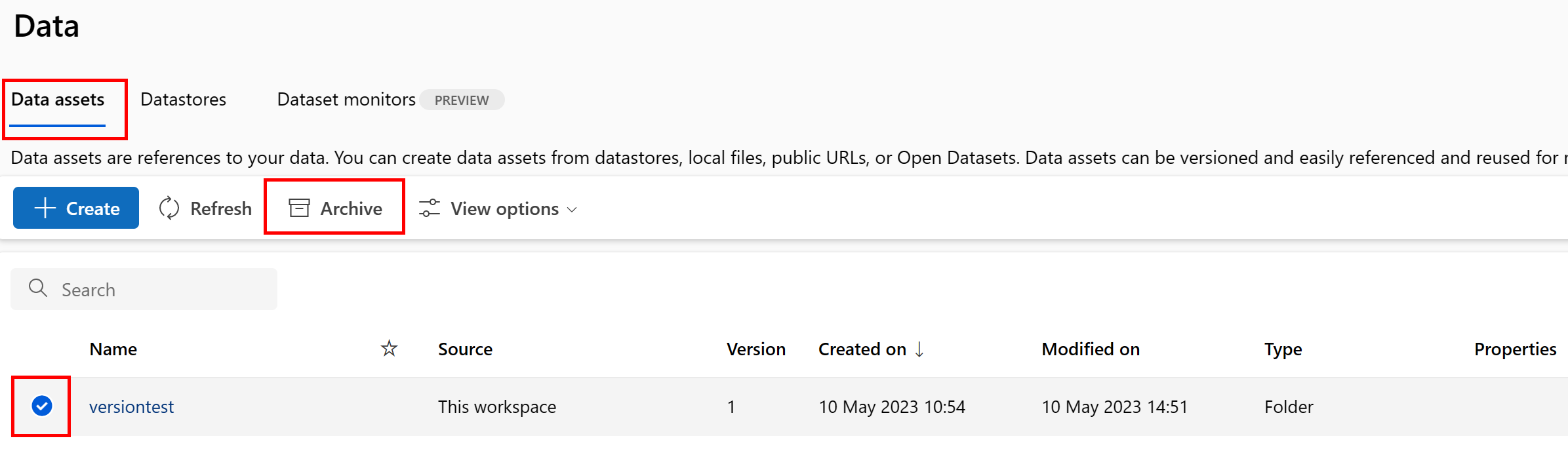
Archiwizowanie określonej wersji zasobu danych
Aby zarchiwizować określoną wersję zasobu danych, użyj:
Uruchom następujące polecenie. Pamiętaj, aby zaktualizować <> symbole zastępcze przy użyciu nazwy zasobu danych i wersji.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Przywracanie zarchiwizowanego zasobu danych
Możesz przywrócić zarchiwizowany zasób danych. Jeśli wszystkie wersje zasobu danych są archiwizowane, nie można przywrócić poszczególnych wersji zasobu danych — musisz przywrócić wszystkie wersje.
Przywracanie wszystkich wersji zasobu danych
Aby przywrócić wszystkie wersje zasobu danych pod daną nazwą, użyj:
Uruchom następujące polecenie. Pamiętaj, aby zaktualizować <> symbole zastępcze przy użyciu nazwy zasobu danych.
az ml data restore --name <NAME OF DATA ASSET>

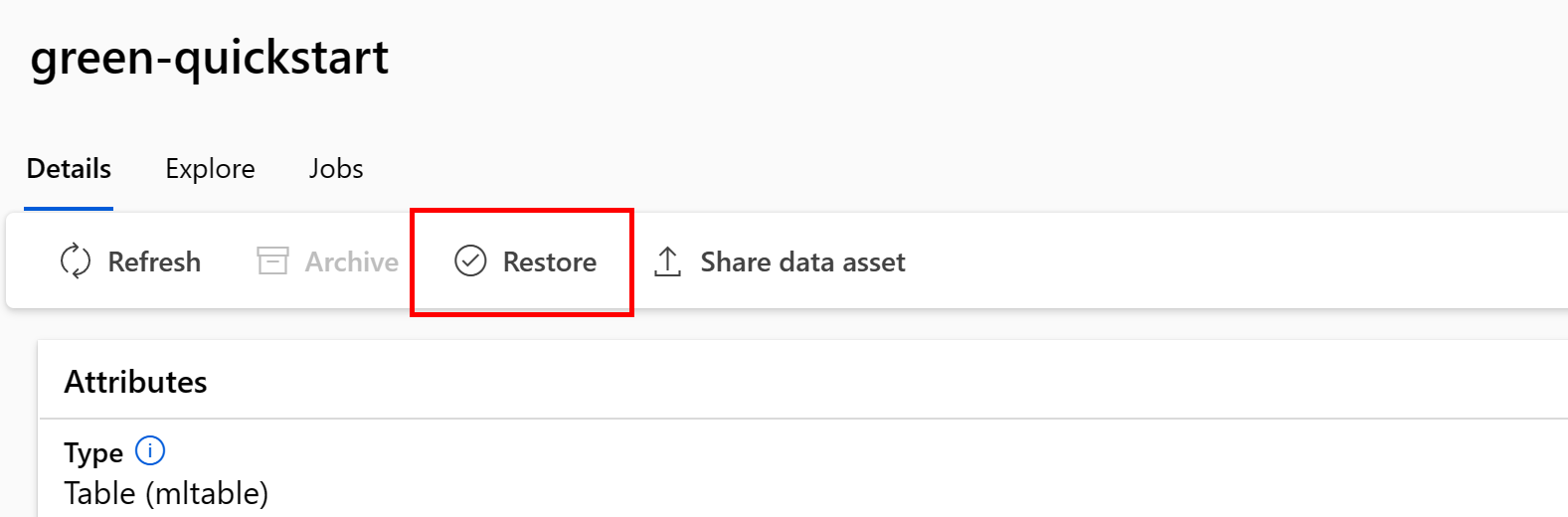
Przywracanie określonej wersji zasobu danych
Ważne
Jeśli wszystkie wersje zasobów danych zostały zarchiwizowane, nie można przywrócić poszczególnych wersji zasobu danych — musisz przywrócić wszystkie wersje.
Aby przywrócić określoną wersję zasobu danych, użyj:
Uruchom następujące polecenie. Pamiętaj, aby zaktualizować <> symbole zastępcze przy użyciu nazwy zasobu danych i wersji.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Pochodzenie danych
Pochodzenie danych jest powszechnie zrozumiałe jako cykl życia obejmujący źródło danych i miejsce, w którym przenosi się wraz z upływem czasu w magazynie. Używane są różne rodzaje scenariuszy wstecznych, na przykład
- Rozwiązywanie problemów
- Śledzenie głównych przyczyn w potokach uczenia maszynowego
- Debugowanie
Scenariusze analizy jakości danych, zgodności i "analizy warunkowej" również używają pochodzenia danych. Pochodzenie jest reprezentowane wizualnie w celu wyświetlania danych przenoszonych ze źródła do miejsca docelowego i dodatkowo obejmuje przekształcenia danych. Biorąc pod uwagę złożoność większości środowisk danych przedsiębiorstwa, te widoki mogą stać się trudne do zrozumienia bez konsolidacji lub maskowania peryferyjnych punktów danych.
W potoku usługi Azure Machine Learning zasoby danych pokazują pochodzenie danych i sposób przetwarzania danych, na przykład:
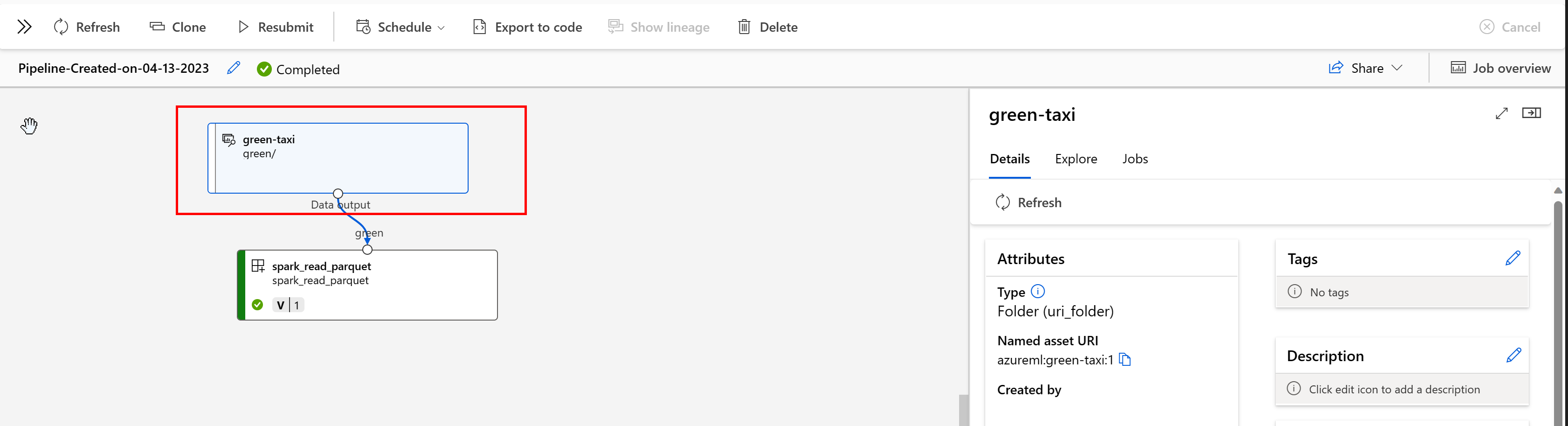
Zadania wykorzystujące zasób danych można wyświetlić w interfejsie użytkownika programu Studio. Najpierw wybierz pozycję Dane z menu po lewej stronie, a następnie wybierz nazwę zasobu danych. Zwróć uwagę na zadania zużywające zasób danych:
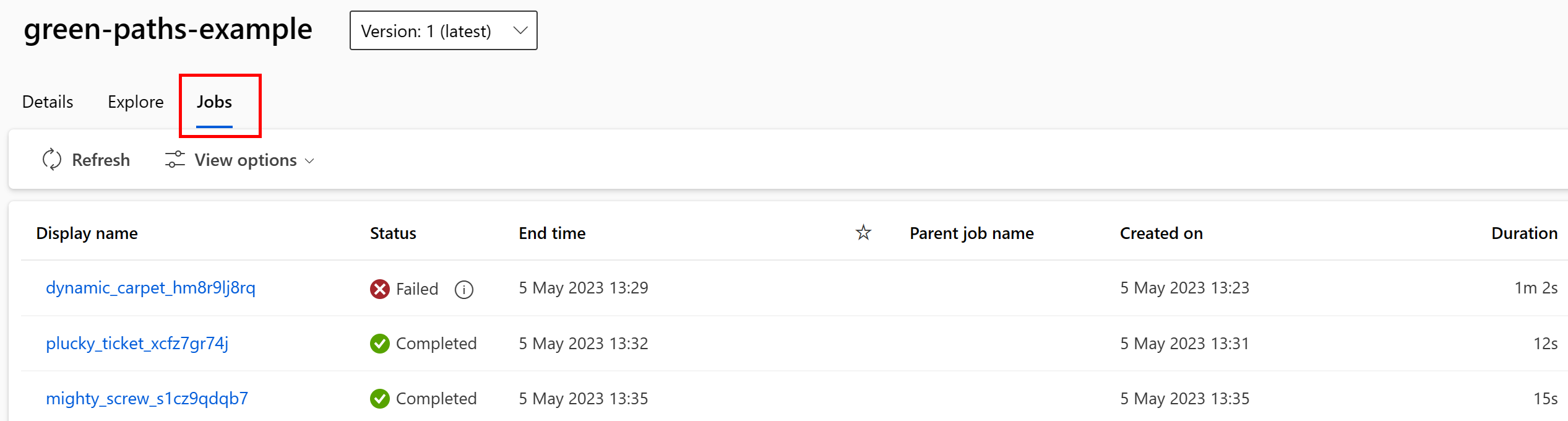
Widok zadań w zasobach danych ułatwia znajdowanie błędów zadań i analizowanie głównych przyczyn w potokach uczenia maszynowego i debugowaniu.
Tagowanie zasobów danych
Zasoby danych obsługują tagowanie, czyli dodatkowe metadane stosowane do zasobu danych jako parę klucz-wartość. Tagowanie danych zapewnia wiele korzyści:
- Opis jakości danych. Jeśli na przykład organizacja używa architektury lakehouse medallion, możesz tagować zasoby za pomocą
medallion:bronze(nieprzetworzonych),medallion:silver(zweryfikowanych) imedallion:gold(wzbogaconych). - Wydajne wyszukiwanie i filtrowanie danych w celu ułatwienia odnajdywania danych.
- Identyfikacja poufnych danych osobowych w celu prawidłowego zarządzania dostępem do danych i zarządzania nimi. Na przykład
sensitivity:PII/sensitivity:nonPII. - Określenie, czy dane są zatwierdzane przez inspekcję odpowiedzialnej sztucznej inteligencji (RAI). Na przykład
RAI_audit:approved/RAI_audit:todo.
Tagi można dodawać do zasobów danych w ramach przepływu tworzenia lub dodawać tagi do istniejących zasobów danych. W tej sekcji przedstawiono oba te elementy:
Dodawanie tagów w ramach przepływu tworzenia zasobu danych
Utwórz plik YAML i skopiuj i wklej następujący kod do tego pliku YAML. Pamiętaj, aby zaktualizować <> symbole zastępcze za pomocą elementu
- nazwa zasobu danych
- wersja
- opis
- tagi (pary klucz-wartość)
- ścieżka do pojedynczego pliku w obsługiwanej lokalizacji
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Wykonaj następujące polecenie w interfejsie wiersza polecenia. Pamiętaj, aby zaktualizować <filename> symbol zastępczy do nazwy pliku YAML.
az ml data create -f <filename>.yml
Dodawanie tagów do istniejącego zasobu danych
Wykonaj następujące polecenie w interfejsie wiersza polecenia platformy Azure. Pamiętaj, aby zaktualizować <> symbole zastępcze za pomocą elementu
- Nazwa zasobu danych
- Wersja
- Para klucz-wartość dla tagu
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Najlepsze rozwiązania dotyczące przechowywania wersji
Zazwyczaj procesy ETL organizują strukturę folderów w usłudze Azure Storage według czasu, na przykład:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
Kombinacja folderów strukturalnych czasu/wersji i tabel usługi Azure Machine Learning (MLTable) umożliwia konstruowanie zestawów danych w wersji. Hipotetyczny przykład przedstawia sposób uzyskiwania danych w wersji za pomocą tabel usługi Azure Machine Learning. Załóżmy, że masz proces, który co tydzień przekazuje obrazy aparatu do usługi Azure Blob Storage, w tej strukturze:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Uwaga
Chociaż pokazujemy, jak wersję danych obrazu (jpeg), to samo podejście działa dla dowolnego typu pliku (na przykład Parquet, CSV).
Za pomocą tabel usługi Azure Machine Learning (mltable) skonstruuj tabelę ścieżek, które zawierają dane do końca pierwszego tygodnia w 2023 roku. Następnie utwórz zasób danych:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Pod koniec następnego tygodnia proces ETL zaktualizował dane w celu uwzględnienia większej liczby danych:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Pierwsza wersja (20230108) nadal instaluje/pobiera pliki tylko z year=2022/week=52 pliku i year=2023/week=1 dlatego, że ścieżki są deklarowane MLTable w pliku. Zapewnia to powtarzalność eksperymentów. Aby utworzyć nową wersję zasobu danych zawierającego year=2023/week2element , użyj polecenia:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Masz teraz dwie wersje danych, w których nazwa wersji odpowiada dacie przekazania obrazów do magazynu:
- 20230108: Obrazy do 2023-Jan-08.
- 20230115: Obrazy do 2023-Jan-15.
W obu przypadkach tabela MLTable tworzy tabelę ścieżek, które zawierają tylko obrazy do tych dat.
W zadaniu usługi Azure Machine Learning możesz zainstalować lub pobrać te ścieżki w wersji tabeli MLTable do docelowego obiektu obliczeniowego przy użyciu eval_download trybów lub eval_mount :
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Uwaga
Tryby eval_mount i eval_download są unikatowe dla tabeli MLTable. W tym przypadku funkcja środowiska uruchomieniowego danych AzureML ocenia MLTable plik i instaluje ścieżki na docelowym obiekcie obliczeniowym.