Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Interfejs API usługi Microsoft Fabric dla języka GraphQL oferuje zaawansowany sposób wydajnego wykonywania zapytań o dane, ale optymalizacja wydajności jest kluczem do zapewnienia bezproblemowej i skalowalnej wydajności. Niezależnie od tego, czy obsługujesz złożone zapytania, czy optymalizujesz czasy odpowiedzi, poniższe najlepsze rozwiązania pomagają uzyskać najlepszą wydajność implementacji graphQL i zmaksymalizować wydajność interfejsu API w usłudze Fabric.
Kto potrzebuje optymalizacji wydajności
Optymalizacja wydajności ma kluczowe znaczenie dla:
- Deweloperzy aplikacji tworzący aplikacje o dużym natężeniu ruchu, które wysyłają zapytania do lakehouse'ów i magazynów usługi Fabric
- Inżynierowie danych optymalizują wzorce dostępu do danych w architekturze Fabric dla aplikacji analitycznych na dużą skalę i procesów ETL
- Administratorzy obszaru roboczego Fabric zarządzają przydziałem pojemności i zapewniają efektywne wykorzystanie zasobów.
- BI deweloperzy poprawiają czas odpowiedzi dla niestandardowych aplikacji analitycznych opartych na danych Fabric
- Zespoły DevOps rozwiązują problemy z opóźnieniami w aplikacjach produkcyjnych korzystających z Fabric APIs
Skorzystaj z tych najlepszych rozwiązań, gdy interfejs API GraphQL musi wydajnie obsługiwać obciążenia produkcyjne lub gdy występują problemy z wydajnością.
Wyrównanie regionu
Wywołania interfejsu API między regionami są częstą przyczyną dużego opóźnienia. Aby uzyskać optymalną wydajność, upewnij się, że aplikacje klienckie, dzierżawa Fabric, pojemność i źródła danych znajdują się w tym samym regionie Azure.
Sprawdzanie regionu dzierżawy
Aby zlokalizować region dzierżawcy Fabric:
- Zaloguj się do portalu usługi Microsoft Fabric przy użyciu konta administratora
- Wybierz ikonę Pomoc (?) w prawym górnym rogu
- W dolnej części okienka Pomoc wybierz pozycję Informacje o Fabric
- Zanotuj region wyświetlany w szczegółach dzierżawy
Sprawdzanie regionu pojemności
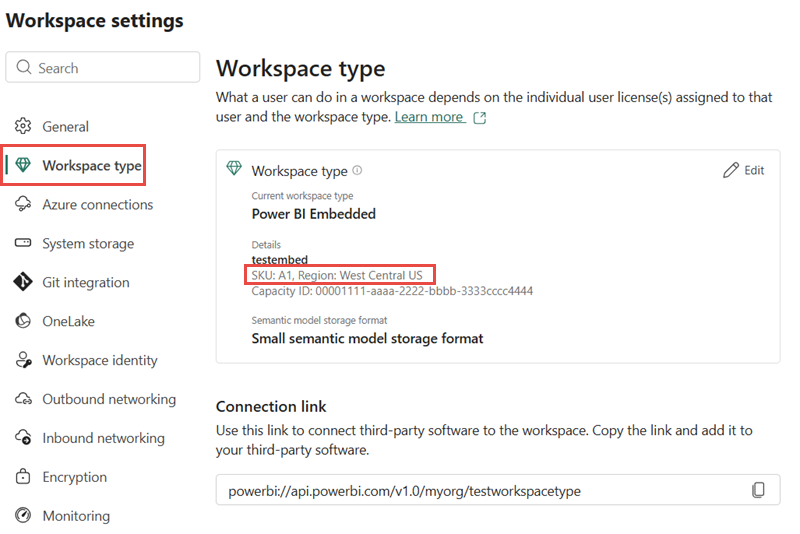
Twój interfejs API dla GraphQL działa w ramach określonej wydajności. Aby znaleźć obszar pojemności:
Otwórz obszar roboczy hostujący interfejs API dla GraphQL
Przejdź do Ustawienia przestrzeni roboczej>typ przestrzeni roboczej
Znajdź region w obszarze Pojemność licencji

Sprawdzanie regionu źródła danych
Lokalizacja źródeł danych ma również wpływ na wydajność:
- Źródła danych Fabric (Lakehouse, Data Warehouse, SQL Database): używają tego samego regionu co pojemność obszaru roboczego
- Zewnętrzne źródła danych (usługa Azure SQL Database itp.): Sprawdź lokalizację zasobu w witrynie Azure Portal
Najlepsze rozwiązanie: Wdróż aplikacje klienckie w tym samym regionie co pojemność sieci szkieletowej i źródła danych, aby zminimalizować opóźnienie sieci.
Najlepsze rozwiązania dotyczące testowania wydajnościowego
Podczas oceniania wydajności interfejsu API postępuj zgodnie z tymi wytycznymi, aby uzyskać niezawodne i spójne wyniki.
Korzystanie z realistycznych narzędzi do testowania
Przetestuj za pomocą narzędzi, które są ściśle zgodne ze środowiskiem produkcyjnym:
- Skrypty lub aplikacje: użyj skryptów python, Node.jslub .NET, które symulują rzeczywiste zachowanie klienta
- Buforowanie połączeń HTTP: ponowne używanie połączeń HTTP w celu zmniejszenia opóźnienia, szczególnie ważne w scenariuszach obejmujących wiele regionów
- Zarządzanie sesjami: obsługa sesji między żądaniami w celu dokładnego odzwierciedlenia rzeczywistego użycia
Przykładowe zasoby:
- Przykładowy skrypt testu wydajności (notebook Pythona)
- Obiekty sesji HTTP w języku Python
- Wskazówki dotyczące klienta HttpClient dla platformy .NET
Zbieranie znaczących metryk
Aby uzyskać dokładną ocenę wydajności:
- Automatyzowanie testowania: używanie skryptów lub narzędzi do testowania wydajnościowego w celu spójnego uruchamiania testów w określonym okresie
- Rozgrzej interfejs API: wykonaj kilka zapytań testowych przed pomiarem wydajności (zobacz Wymagania dotyczące rozgrzewki)
- Analizowanie dystrybucji: użyj metryk opartych na percentylu (P50, P95, P99), a nie tylko średnich, aby zrozumieć wzorce opóźnień
- Testowanie pod obciążeniem: Mierzenie wydajności przy użyciu realistycznych woluminów żądań współbieżnych
- Warunki dokumentu: rejestruj czas dnia, wykorzystanie pojemności i wszystkie współbieżne obciążenia podczas testowania
Typowe problemy z wydajnością
Zrozumienie tych typowych problemów ułatwia efektywne diagnozowanie i rozwiązywanie problemów z wydajnością.
Wymagania dotyczące rozgrzewki
Problem: Pierwsze żądanie interfejsu API trwa znacznie dłużej niż kolejne żądania.
Dlaczego tak się dzieje:
- Inicjowanie interfejsu API: w przypadku bezczynności środowisko interfejsu API musi zainicjować podczas pierwszego wywołania, dodając kilka sekund opóźnienia
- Rozgrzewka źródła danych: wiele źródeł danych (zwłaszcza punkty końcowe SQL Analytics i magazyny danych) przechodzi fazę rozgrzewki, gdy zostaną uruchomione po okresie bezczynności
- Inicjowanie połączone: jeśli zarówno interfejs API, jak i źródło danych pozostają bezczynne, czasy inicjowania kumulują się
Rozwiązanie:
- Wykonywanie 2–3 zapytań testowych przed pomiarem wydajności
- W przypadku aplikacji produkcyjnych zaimplementuj punkty końcowe kontroli kondycji, które utrzymują interfejs API w gotowości.
- Rozważ użycie zaplanowanych zapytań lub narzędzi do monitorowania, aby zachować aktywny stan w godzinach pracy
Niezgodność regionalna
Problem: Stale duże opóźnienie we wszystkich żądaniach.
Dlaczego tak się dzieje: Wywołania sieciowe obejmujące wiele regionów dodają znaczne opóźnienie, zwłaszcza gdy klient, interfejs API i źródła danych znajdują się w różnych regionach świadczenia usługi Azure.
Rozwiązanie:
- Sprawdź, czy aplikacja kliencka, pojemność Fabric i źródła danych znajdują się w tym samym regionie
- Jeśli dostęp między regionami jest nieunikniony, zaimplementuj agresywne strategie buforowania
- Rozważ wdrożenie regionalnych replik interfejsu API dla aplikacji globalnych
Wydajność źródła danych
Problem: Żądania API działają wolno nawet gdy API jest gotowe do pracy, a regiony są zestawione.
Dlaczego tak się dzieje: Interfejs API dla języka GraphQL działa jako interfejs zapytania dla źródeł danych. Jeśli bazowe źródło danych ma problemy z wydajnością — takie jak brakujące indeksy, złożone zapytania lub ograniczenia zasobów — interfejs API dziedziczy te ograniczenia.
Rozwiązanie:
- Testowanie bezpośrednio: wykonywanie zapytań względem źródła danych bezpośrednio (przy użyciu języka SQL lub innych narzędzi natywnych) w celu ustalenia wydajności punktu odniesienia
-
Zoptymalizuj źródło danych:
- Dodawanie odpowiednich indeksów dla często odpytywanych kolumn
- Rozważ odpowiedni magazyn danych dla Państwa przypadku użycia: Przewodnik po decyzjach dotyczących wyboru magazynu danych
- Przeglądanie planów wykonywania zapytań pod kątem możliwości optymalizacji
- Odpowiednia pojemność: Upewnij się, że jednostka SKU pojemności Fabric zapewnia wystarczające zasoby obliczeniowe. Zobacz Pojęcia dotyczące usługi Microsoft Fabric, aby uzyskać wskazówki dotyczące doboru odpowiedniej pojemności.
Projekt zapytania
Problem: Niektóre zapytania działają dobrze, gdy inne działają wolno.
Dlaczego tak się dzieje:
- Nadmierne pobieranie: żądanie większej liczby pól niż jest to konieczne zwiększa czas przetwarzania
- Głębokie zagnieżdżanie: zapytania z wieloma poziomami zagnieżdżonych relacji wymagają wielu wykonań rozwiązywania
- Brakujące filtry: Zapytania bez odpowiednich filtrów mogą zwracać nadmierne dane
Rozwiązanie:
- Wyszukaj tylko potrzebne pola w zapytaniu GraphQL
- Ogranicz głębokość zagnieżdżonych relacji, jeśli jest to możliwe
- Używanie odpowiednich filtrów i stronicowania w zapytaniach
- Rozważ podzielenie złożonych zapytań na wiele prostszych zapytań, jeśli jest to konieczne