Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Rozszerzenie Visual Studio (VS) Code dla inżynierii danych Fabric w pełni obsługuje operacje tworzenia, odczytu, aktualizacji i usuwania (CRUD) definicji zadań Spark w Fabric. Po utworzeniu definicji zadania Spark możesz przekazać więcej bibliotek referencyjnych, przesłać żądanie uruchomienia definicji zadania Spark i sprawdzić historię realizacji.
Tworzenie definicji zadania platformy Spark
Aby utworzyć nową definicję zadania platformy Spark:
W Eksploratorze programu VS Code wybierz opcję Utwórz definicję zadania Spark.

Wprowadź początkowe wymagane pola: name, referenced lakehouse i default lakehouse.
Procesy żądania i nazwa nowo utworzonej definicji zadania Spark są wyświetlane w węźle głównym definicji zadania Spark w Eksploratorze programu VS Code. W węźle z nazwą definicji zadania Spark, znajdują się trzy podwęzły:
- Pliki: Lista głównego pliku definicji i innych bibliotek referencyjnych. Możesz załadować nowe pliki z tej listy.
-
Lakehouse: lista wszystkich jezior, do których odwołuje się ta definicja zadania platformy Spark. Domyślny lakehouse jest wskazany na liście i można uzyskać do niego dostęp za pomocą ścieżki względnej
Files/…, Tables/…. - Uruchom: lista uruchomienia tej definicji zadania Spark i stan zadania każdego uruchomienia.

Prześlij główny plik definicji do biblioteki odniesień
Aby przekazać lub zastąpić główny plik definicji, wybierz opcję Dodaj główny plik.

Aby przekazać plik biblioteki, do którego odwołuje się główny plik definicji, wybierz opcję Dodaj plik Lib.

Po przesłaniu pliku możesz go zastąpić, klikając opcję Aktualizuj plik i przesyłając nowy plik, lub możesz usunąć plik za pomocą opcji Usuń.

Przesyłanie żądania uruchomienia
Aby przesłać żądanie uruchomienia definicji zadania platformy Spark z programu VS Code:
Z opcji po prawej stronie nazwy definicji zadania platformy Spark, którą chcesz uruchomić, wybierz opcję Uruchom zadanie platformy Spark.

Po przesłaniu żądania nowa aplikacja Apache Spark zostanie wyświetlona w węźle Wykonywania na liście Eksplorator. Uruchomione zadanie można anulować, wybierając opcję Anuluj zadanie platformy Spark.
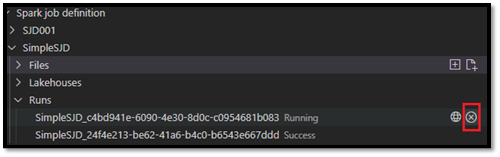


Otwórz definicję zadania Spark w portalu Fabric
Możesz otworzyć stronę tworzenia definicji zadań platformy Spark w portalu sieci szkieletowej, wybierając opcję Otwórz w przeglądarce .
Możesz również wybrać pozycję Otwórz w przeglądarce obok zakończonego procesu, aby wyświetlić szczegółową stronę monitorowania tego procesu.

Debugowanie kodu źródłowego definicji zadania platformy Spark (Python)
Jeśli definicja zadania platformy Spark jest tworzona przy użyciu narzędzia PySpark (Python), możesz pobrać skrypt .py głównego pliku definicji i pliku definicji, do którego się odwołujesz, oraz debugować skrypt źródłowy w programie VS Code.
Aby pobrać kod źródłowy, wybierz po prawej stronie definicji zadania Spark opcję Debugowanie definicji zadania Spark.

Po zakończeniu pobierania zostanie automatycznie otwarty folder kodu źródłowego.
Gdy pojawi się monit, wybierz opcję Ufaj autorom. (Ta opcja jest wyświetlana tylko przy pierwszym otwarciu folderu. Jeśli nie wybierzesz tej opcji, nie możesz debugować ani uruchamiać skryptu źródłowego. Aby uzyskać więcej informacji, zobacz Zabezpieczenia zaufania obszaru roboczego programu Visual Studio Code).
Jeśli wcześniej pobrano kod źródłowy, zostanie wyświetlony monit o potwierdzenie, że chcesz zastąpić lokalną wersję przy użyciu nowego pobierania.
Uwaga
W folderze głównym skryptu źródłowego system tworzy podfolder o nazwie conf. W tym folderze plik o nazwie lighter-config.json zawiera pewne metadane systemowe potrzebne do zdalnego uruchamiania. Nie wprowadzaj w nim żadnych zmian.
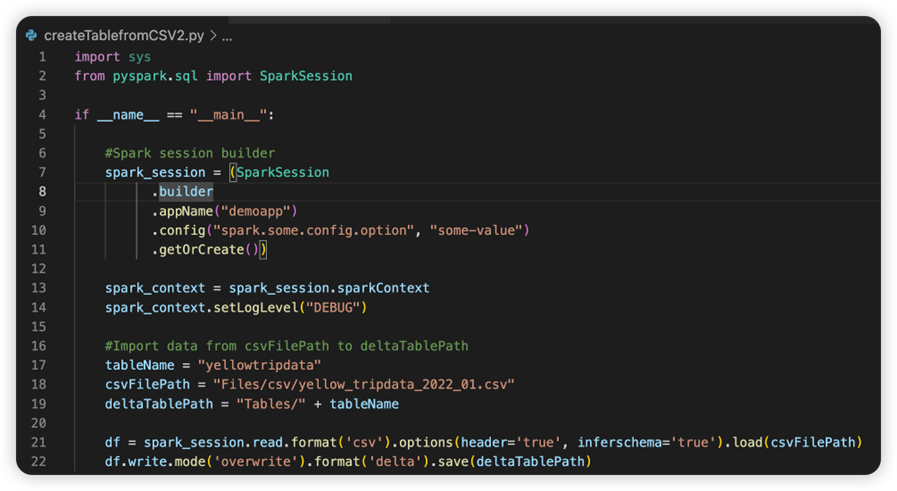
Plik o nazwie sparkconf.py zawiera fragment kodu, który należy dodać, aby skonfigurować obiekt SparkConf . Aby włączyć debugowanie zdalne, upewnij się, że obiekt SparkConf jest poprawnie skonfigurowany. Na poniższej ilustracji przedstawiono oryginalną wersję kodu źródłowego.
Następny obraz to zaktualizowany kod źródłowy po skopiowaniu i wklejeniu fragmentu kodu.
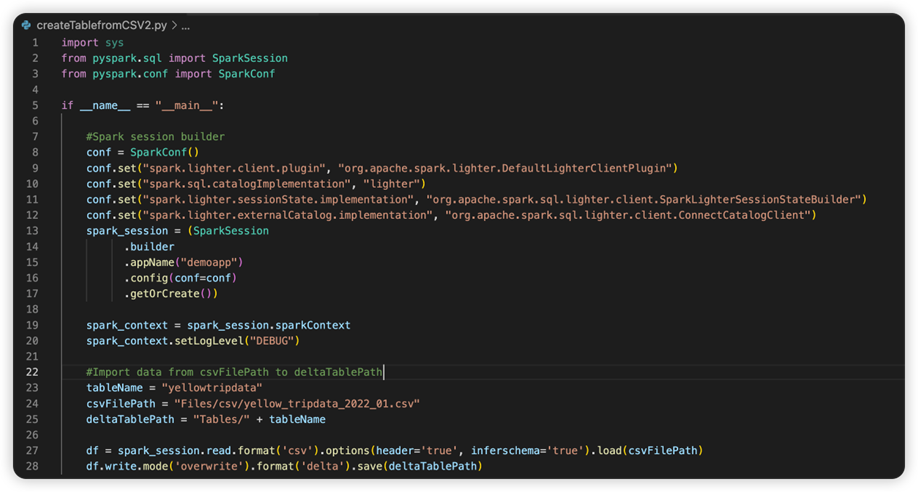
Po aktualizacji kodu źródłowego przy użyciu niezbędnej konfiguracji, musisz wybrać właściwy interpreter języka Python. Upewnij się, że wybrano ten zainstalowany ze środowiska conda synapse-spark-kernel.



Edytowanie właściwości definicji zadania platformy Spark
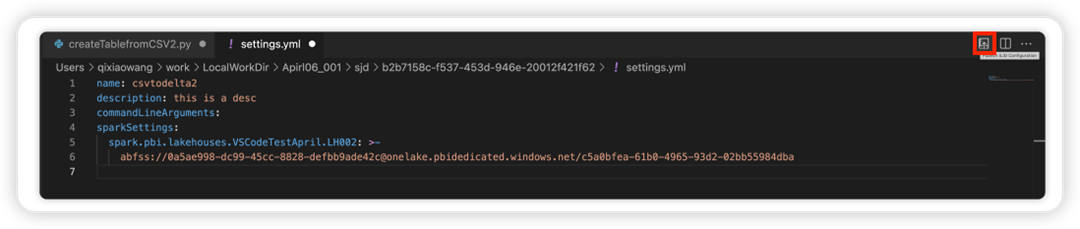
Możesz edytować szczegółowe właściwości definicji zadań platformy Spark, takich jak argumenty wiersza polecenia.
Wybierz opcję Aktualizuj konfigurację SJD, aby otworzyć plik settings.yml. Istniejące właściwości wypełniają zawartość tego pliku.
Zaktualizuj i zapisz plik .yml.
Wybierz opcję Publikuj właściwość SJD w prawym górnym rogu, aby zsynchronizować zmianę z powrotem do zdalnego obszaru roboczego.