Raportowanie rozliczeń i wykorzystania platformy Apache Spark w usłudze Microsoft Fabric
Dotyczy: ![]() inżynierowie danych i Nauka o danych w usłudze Microsoft Fabric
inżynierowie danych i Nauka o danych w usłudze Microsoft Fabric
W tym artykule wyjaśniono wykorzystanie zasobów obliczeniowych i raportowanie dla platformy ApacheSpark, które obsługuje obciążenia usługi Synapse inżynierowie danych i nauki w usłudze Microsoft Fabric. Wykorzystanie zasobów obliczeniowych obejmuje operacje typu lakehouse, takie jak podgląd tabeli, ładowanie do różnicy, uruchamianie notesu z interfejsu, zaplanowane uruchomienia, uruchomienia wyzwalane przez kroki notesu w potokach i uruchomienia definicji zadań platformy Apache Spark.
Podobnie jak w przypadku innych środowisk w usłudze Microsoft Fabric, inżynierowie danych korzysta również z pojemności skojarzonej z obszarem roboczym, aby uruchomić to zadanie, a ogólne opłaty za pojemność są wyświetlane w witrynie Azure Portal w ramach subskrypcji usługi Microsoft Cost Management. Aby dowiedzieć się więcej na temat rozliczeń za sieć szkieletową, zobacz Omówienie rachunku za korzystanie z platformy Azure w pojemności sieci szkieletowej.
Pojemność sieci szkieletowej
Jako użytkownik możesz kupić pojemność sieci szkieletowej z platformy Azure, określając przy użyciu subskrypcji platformy Azure. Wielkość pojemności określa ilość dostępnej mocy obliczeniowej. W przypadku platformy Apache Spark for Fabric każda zakupiona aktualizacja zbiorcza przekłada się na 2 rdzenie wirtualne platformy Apache Spark. Jeśli na przykład zakupisz pojemność sieci szkieletowej F128, przekłada się to na 256 rdzeni SparkVCore. Pojemność sieci szkieletowej jest współdzielona we wszystkich dodanych do niego obszarach roboczych i w których dozwolone zasoby obliczeniowe platformy Apache Spark są współużytkowane we wszystkich zadaniach przesłanych ze wszystkich obszarów roboczych skojarzonych z pojemnością. Aby poznać różne jednostki SKU, alokację rdzeni i ograniczanie przepustowości na platformie Spark, zobacz Limity współbieżności i kolejkowanie na platformie Apache Spark dla usługi Microsoft Fabric.
Konfiguracja obliczeniowa platformy Spark i zakupiona pojemność
Obliczenia platformy Apache Spark dla sieci szkieletowej oferują dwie opcje, jeśli chodzi o konfigurację obliczeniową.
Pule początkowe: te pule domyślne są szybkie i łatwe w użyciu platformy Spark na platformie Microsoft Fabric w ciągu kilku sekund. Sesje platformy Spark można używać od razu, zamiast czekać na skonfigurowanie węzłów platformy Spark, co ułatwia wykonywanie większej ilości danych i szybsze uzyskiwanie szczegółowych informacji. Jeśli chodzi o rozliczenia i zużycie pojemności, opłaty są naliczane po rozpoczęciu wykonywania notesu lub definicji zadania platformy Spark lub operacji lakehouse. Opłaty nie są naliczane za czas bezczynności klastrów w puli.
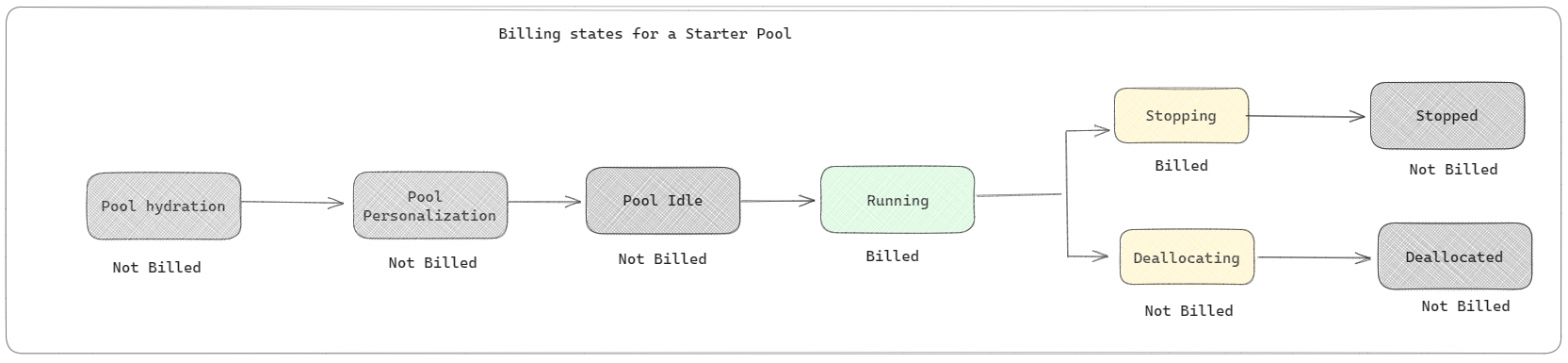
Jeśli na przykład przesyłasz zadanie notesu do puli startowej, opłaty są naliczane tylko za okres, w którym sesja notesu jest aktywna. Rozliczany czas nie obejmuje czasu bezczynności ani czasu potrzebnego do spersonalizowania sesji z kontekstem platformy Spark. Aby dowiedzieć się więcej na temat konfigurowania pul starter na podstawie zakupionej jednostki SKU pojemności sieci szkieletowej, odwiedź stronę Konfigurowanie pul startowych na podstawie pojemności sieci szkieletowej
Pule platformy Spark: są to pule niestandardowe, w których można dostosować rozmiar zasobów potrzebnych do zadań analizy danych. Możesz nadać puli Spark nazwę i wybrać liczbę i liczbę węzłów (maszyny, które wykonują pracę). Możesz również poinformować platformę Spark, jak dostosować liczbę węzłów w zależności od ilości pracy. Tworzenie puli platformy Spark jest bezpłatne; Płacisz tylko wtedy, gdy uruchamiasz zadanie spark w puli, a następnie platforma Spark konfiguruje węzły.
- Rozmiar i liczba węzłów, które można mieć w niestandardowej puli platformy Spark, zależy od pojemności usługi Microsoft Fabric. Za pomocą tych rdzeni wirtualnych platformy Spark można tworzyć węzły o różnych rozmiarach dla niestandardowej puli Spark, o ile łączna liczba rdzeni wirtualnych platformy Spark nie przekracza 128.
- Pule platformy Spark są rozliczane jak pule początkowe; Nie płacisz za utworzone niestandardowe pule platformy Spark, chyba że masz aktywną sesję platformy Spark utworzoną na potrzeby uruchamiania notesu lub definicji zadania platformy Spark. Opłaty są naliczane tylko za czas trwania przebiegów zadania. Po zakończeniu zadania nie są naliczane opłaty za etapy, takie jak tworzenie klastra i cofanie przydziału.
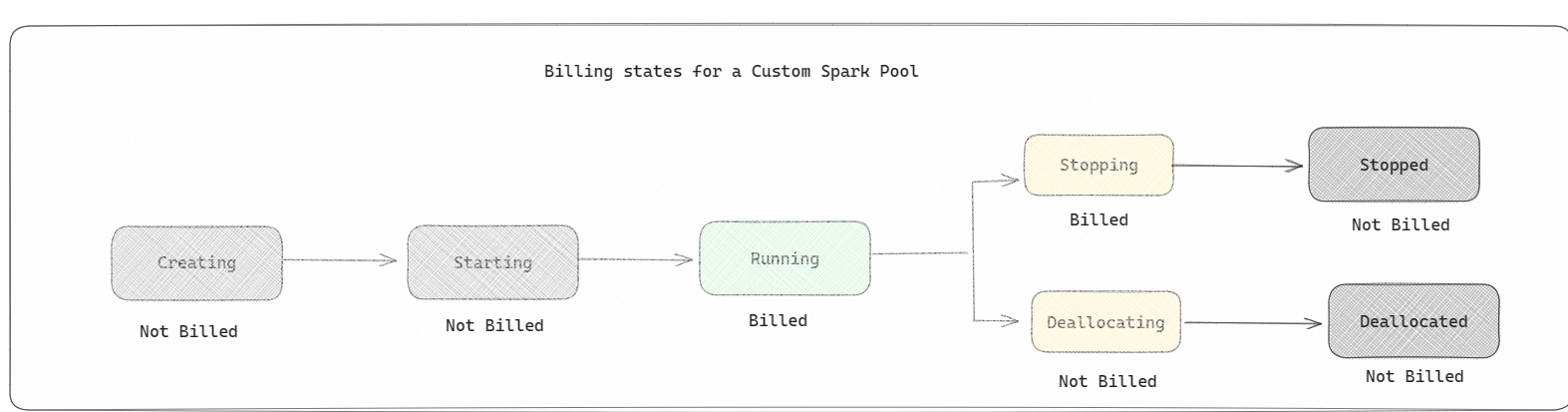
Jeśli na przykład przesyłasz zadanie notesu do niestandardowej puli Spark, opłaty są naliczane tylko za okres, w którym sesja jest aktywna. Rozliczenia dla tej sesji notesu są zatrzymywane po zatrzymaniu lub wygaśnięciu sesji platformy Spark. Nie są naliczane opłaty za czas potrzebny na uzyskanie wystąpień klastra z chmury ani na czas potrzebny na zainicjowanie kontekstu platformy Spark. Aby dowiedzieć się więcej na temat konfigurowania pul platformy Spark na podstawie zakupionej jednostki SKU pojemności sieci szkieletowej, odwiedź stronę Konfigurowanie pul na podstawie pojemności sieci szkieletowej


Uwaga
Domyślny okres wygaśnięcia sesji dla utworzonych pul startowych i pul platformy Spark wynosi 20 minut. Jeśli nie używasz puli Spark przez 2 minuty po wygaśnięciu sesji, pula platformy Spark zostanie cofnięto przydział. Aby zatrzymać sesję i rozliczenia po zakończeniu wykonywania notesu przed upływem czasu wygaśnięcia sesji, możesz kliknąć przycisk Zatrzymaj sesję w menu głównym notesów lub przejść do strony centrum monitorowania i zatrzymać tam sesję.
Raportowanie użycia zasobów obliczeniowych platformy Spark
Aplikacja Metryki pojemności usługi Microsoft Fabric zapewnia wgląd w użycie pojemności dla wszystkich obciążeń sieci szkieletowej w jednym miejscu. Jest ona używana przez administratorów pojemności do monitorowania wydajności obciążeń i ich użycia w porównaniu z zakupiona pojemnością.
Po zainstalowaniu aplikacji wybierz typ elementu Notebook,Lakehouse,Spark Job Definition (Definicja zadania platformy Spark) z listy rozwijanej Wybierz rodzaj elementu: . Wykres wstążkowy z wieloma metrykami można teraz dostosować do żądanego przedziału czasu, aby zrozumieć użycie ze wszystkich tych wybranych elementów.
Wszystkie operacje związane z platformą Spark są klasyfikowane jako operacje w tle. Użycie pojemności z platformy Spark jest wyświetlane w notesie, definicji zadania platformy Spark lub lakehouse i jest agregowane według nazwy operacji i elementu. Na przykład: Jeśli uruchamiasz zadanie notesu, możesz zobaczyć uruchomienie notesu, jednostki CU używane przez notes (łączna liczba rdzeni wirtualnych platformy Spark/2 jako 1 CU daje 2 rdzenie wirtualne platformy Spark), czas trwania zadania wykonanego w raporcie.
 Aby dowiedzieć się więcej na temat raportowania użycia pojemności platformy Spark, zobacz Monitorowanie zużycia pojemności platformy Apache Spark
Aby dowiedzieć się więcej na temat raportowania użycia pojemności platformy Spark, zobacz Monitorowanie zużycia pojemności platformy Apache Spark
Przykład rozliczeń
Rozważmy następujący scenariusz:
Istnieje pojemność C1, która hostuje obszar roboczy sieci szkieletowej W1, a ten obszar roboczy zawiera magazyn Lakehouse LH1 i Notes NB1.
- Każda operacja platformy Spark wykonywana przez notes (NB1) lub lakehouse(LH1) jest zgłaszana względem pojemności C1.
Rozszerzenie tego przykładu do scenariusza, w którym istnieje inna pojemność C2, która hostuje obszar roboczy sieci szkieletowej W2 i informuje, że ten obszar roboczy zawiera definicję zadania platformy Spark (SJD1) i Lakehouse (LH2).
- Jeśli definicja zadania platformy Spark (SDJ2) z obszaru roboczego (W2) odczytuje dane z usługi Lakehouse (LH1), użycie jest zgłaszane względem pojemności C2 skojarzonej z obszarem roboczym (W2) hostowanym elementem.
- Jeśli notes (NB1) wykonuje operację odczytu z usługi Lakehouse(LH2), zużycie pojemności jest zgłaszane względem pojemności C1, która obsługuje obszar roboczy W1 hostujący element notesu.
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla