Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:✅ Inżynieria danych i nauka o danych w Fabric
Dowiedz się, jak przesyłać zadania partii Spark przy użyciu interfejsu API Livy dla Fabric Data Engineering. Interfejs API usługi Livy obecnie nie obsługuje Azure Service Principal (SPN).
Wymagania wstępne
Fabric Premium lub Trial capacity z funkcją Lakehouse.
Klient zdalny, taki jak Visual Studio Code z Jupyter Notebooks, PySpark oraz Microsoft Authentication Library (MSAL) dla Python.
Aby uzyskać dostęp do interfejsu API REST Fabric, wymagany jest token aplikacji Microsoft Entra. Registerowanie aplikacji z Platforma tożsamości Microsoft.
Niektóre dane w lakehouse; w tym przykładzie użyto
NYC Taxi & Limousine Commission green_tripdata_2022_08 jako pliku parquet załadowanego do lakehouse.
Interfejs API usługi Livy definiuje ujednolicony punkt końcowy dla operacji. Zastąp symbole zastępcze {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} i {Fabric_LakehouseID} odpowiednimi wartościami, korzystając z przykładów w tym artykule.
Konfigurowanie Visual Studio Code dla usługi Livy API Batch
Wybierz pozycję Lakehouse Settings w Fabric Lakehouse.

Przejdź do sekcji Livy endpoint.
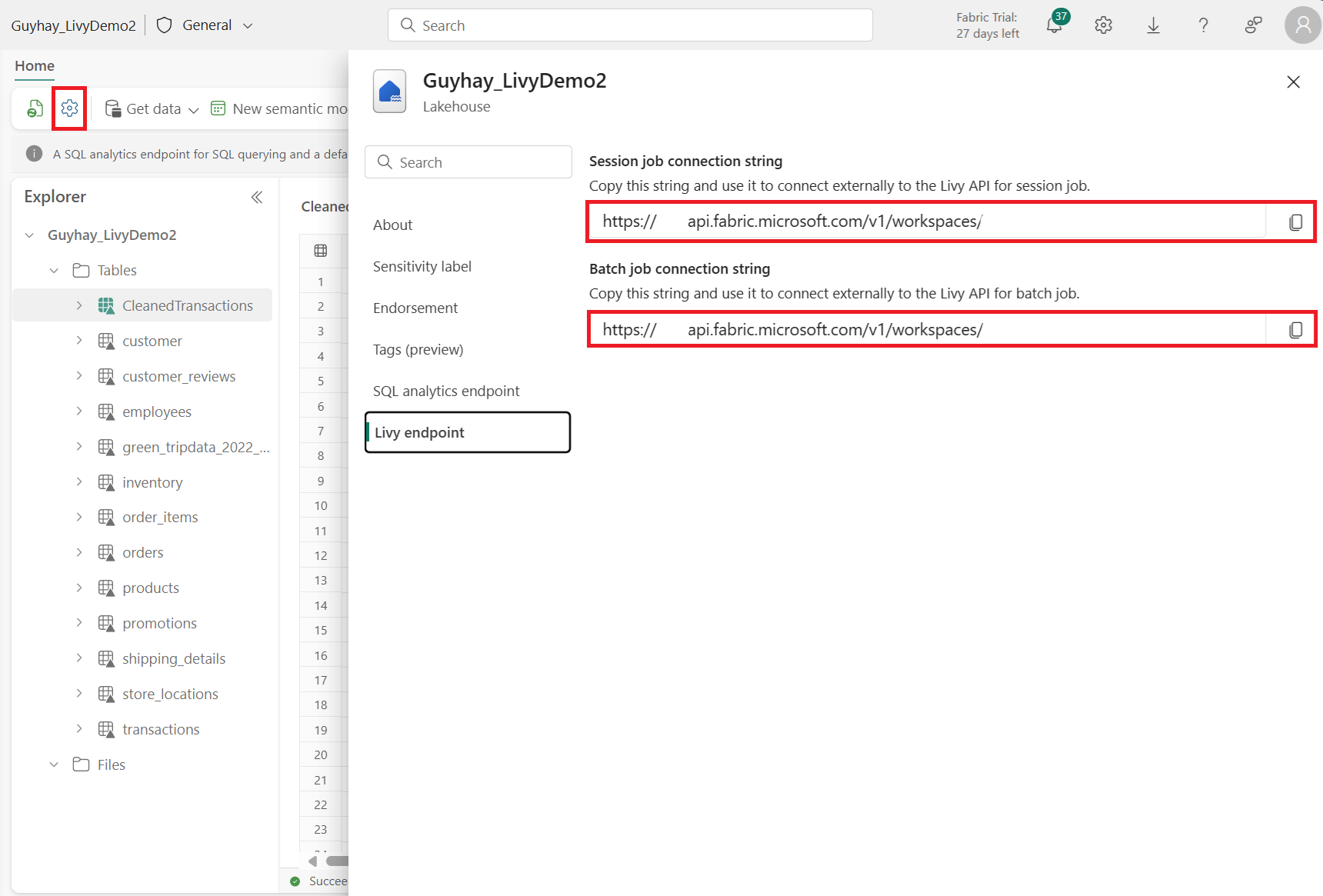
Skopiuj ciąg połączenia zadania Batch (drugie czerwone pole na obrazie) do swojego kodu.
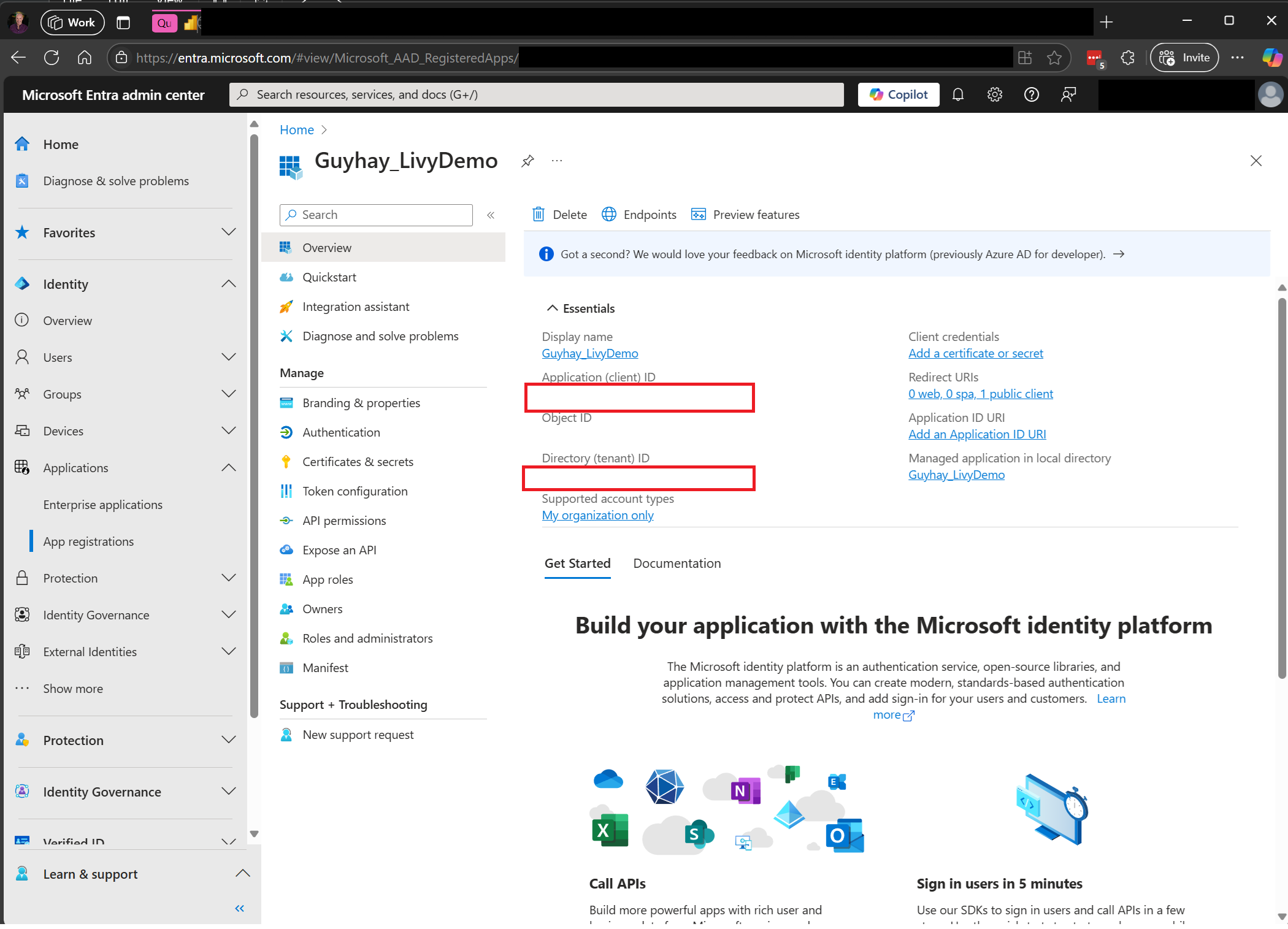
Przejdź do Microsoft Entra centrum administracyjne i skopiuj identyfikator aplikacji (klienta) oraz identyfikator katalogu (dzierżawcy) do swojego kodu.



Utwórz kod Spark Batch i wgraj go do swojego Lakehouse.
Utwórz notes
.ipynbw Visual Studio Code i wstaw następujący kodimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("batch_demo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") tableName = spark_context.getConf().get("spark.targetTable") if tableName is not None: print("tableName: " + str(tableName)) else: print("tableName is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM green_tripdata_2022 where total_amount > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("lpep_pickup_datetime").substr(1, 4)) deltaTablePath = f"Tables/{tableName}CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Zapisz plik Python lokalnie. Ten kod Python zawiera dwie instrukcje Spark, które działają na danych w systemie Lakehouse i muszą zostać wgrane do Lakehouse. Potrzebujesz ścieżki ABFS (Azure Blob File System) danych, aby odwołać się w zadaniu wsadowym API Livy w Visual Studio Code oraz nazwę tabeli Lakehouse w instrukcji SQL
SELECT.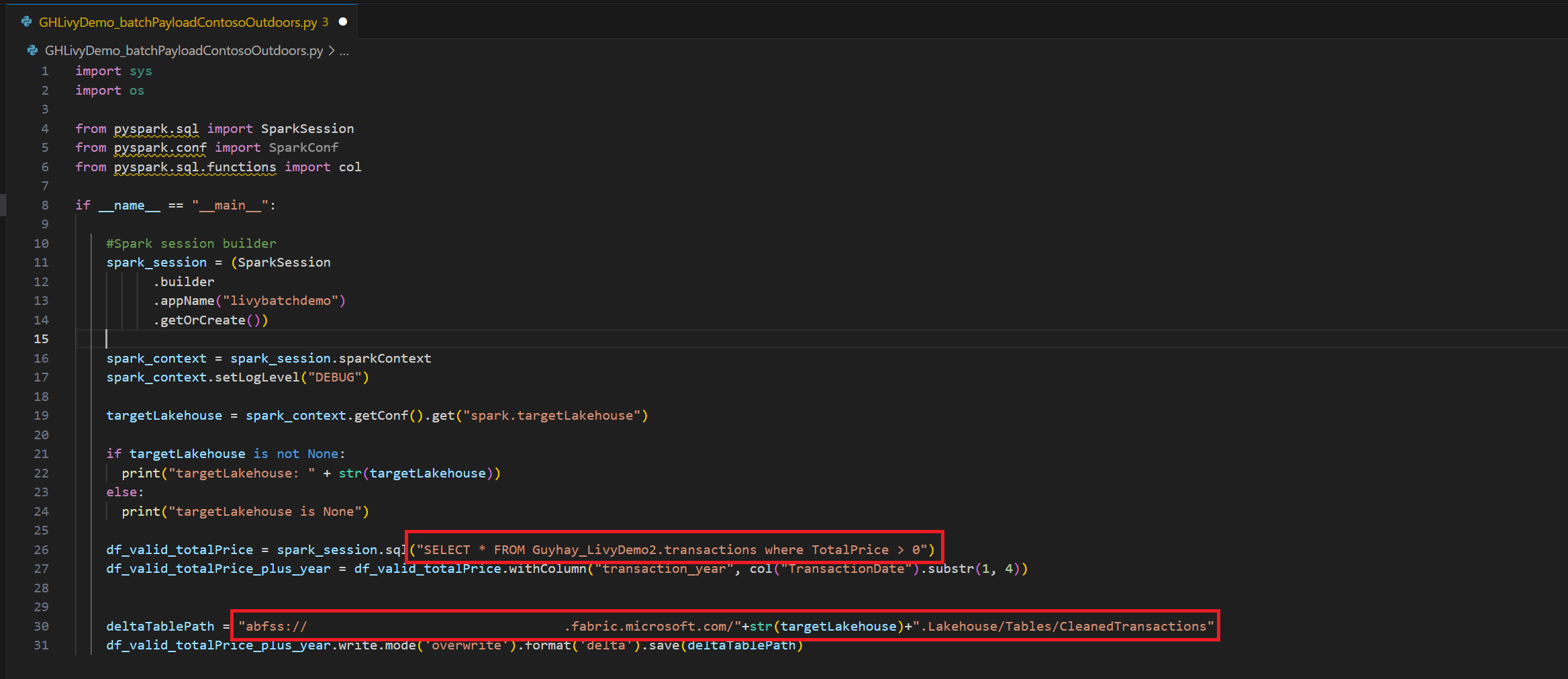
Prześlij skrypt Python do sekcji plików w Lakehouse. W eksploratorze usługi Lakehouse wybierz pozycję Pliki. Następnie wybierz pozycję >Pobierz dane>Przekaż pliki. Wybierz pliki za pośrednictwem selektora plików.
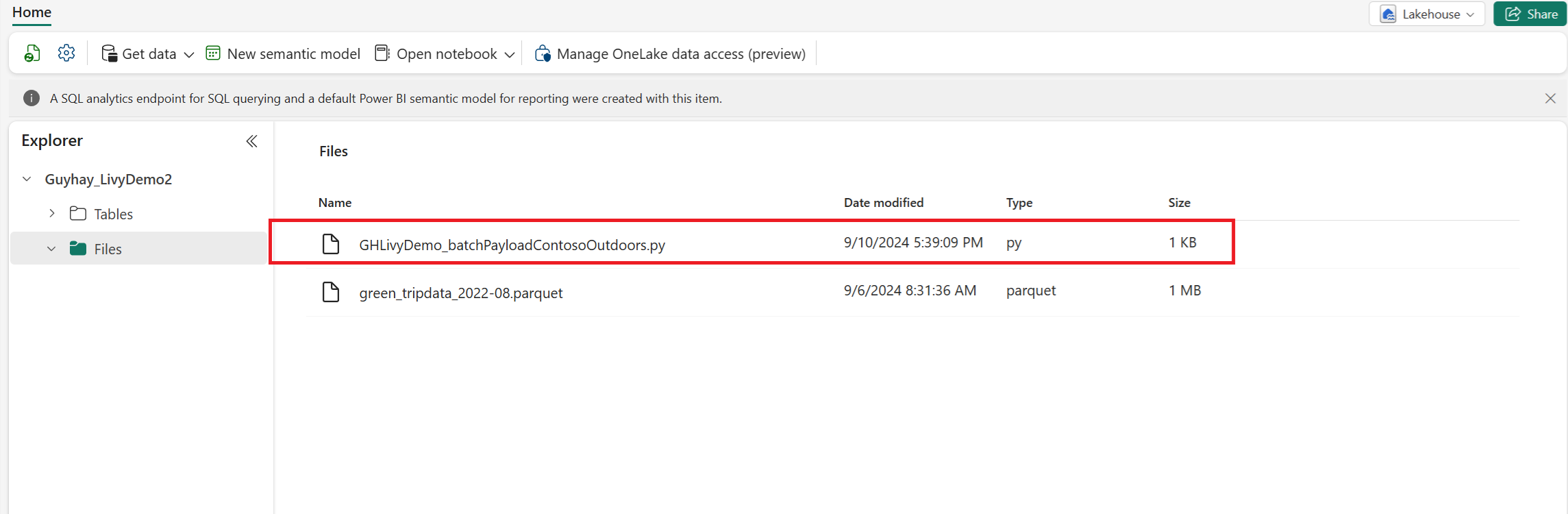
Gdy plik znajduje się w sekcji Pliki usługi Lakehouse, wybierz trzy kropki (wielokropek) po prawej stronie nazwy pliku ładunku i wybierz pozycję Właściwości.
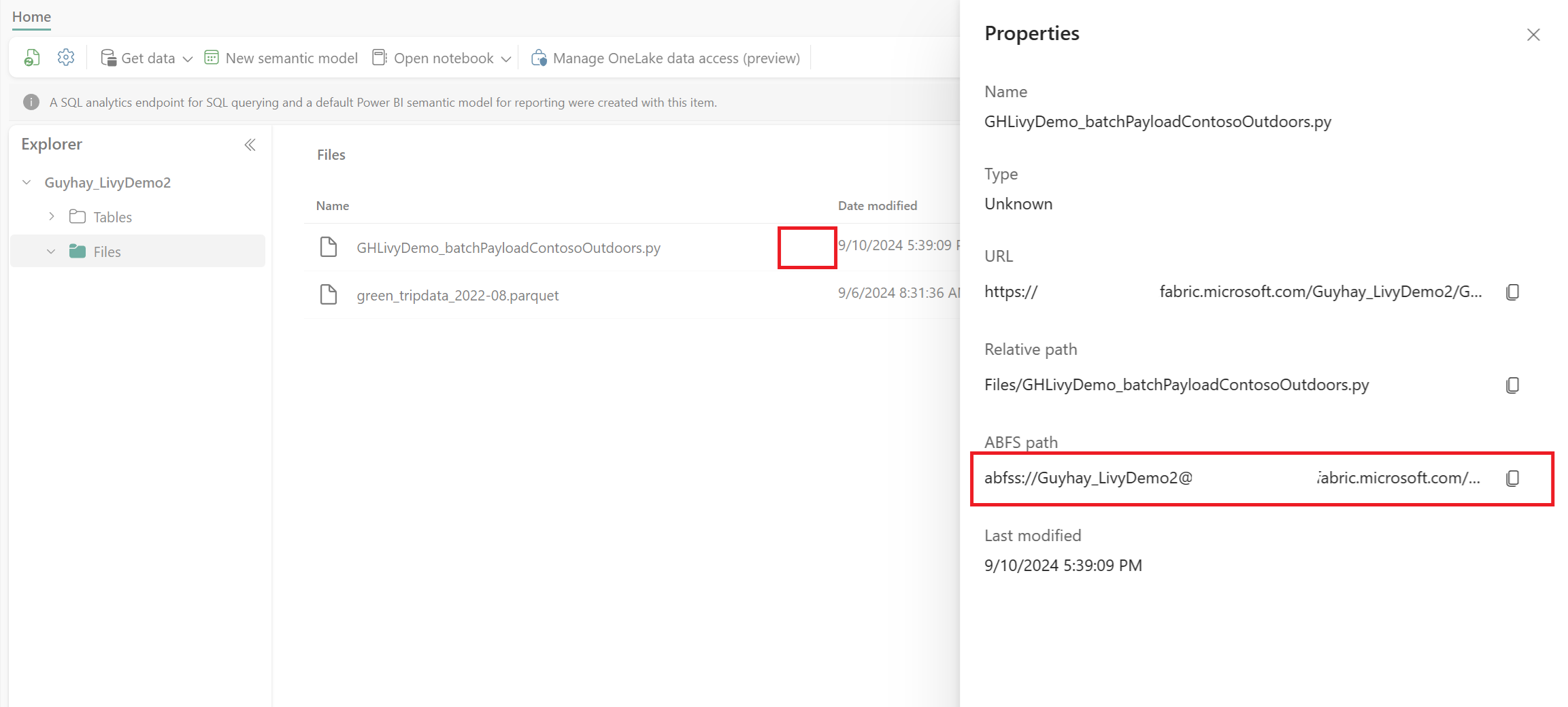
Skopiuj tę ścieżkę ABFS do komórki notesu w kroku 1.



Uwierzytelnij sesję wsadową Livy API Spark przy użyciu tokenu użytkownika Microsoft Entra lub tokenu SPN Microsoft Entra
Uwierzytelnij sesję wsadową interfejsu API Spark w usłudze Livy przy użyciu tokenu SPN Microsoft Entra
Utwórz notes
.ipynbw Visual Studio Code i wstaw następujący kod.import sys from msal import ConfidentialClientApplication # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Service Principal Application ID # Certificate paths - Update these paths to your certificate files certificate_path = "PATH_TO_YOUR_CERTIFICATE.pem" # Public certificate file private_key_path = "PATH_TO_YOUR_PRIVATE_KEY.pem" # Private key file certificate_thumbprint = "YOUR_CERTIFICATE_THUMBPRINT" # Certificate thumbprint # OAuth settings audience = "https://analysis.windows.net/powerbi/api/.default" authority = f"https://login.windows.net/{tenant_id}" def get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint=None): """ Get an app-only access token for a Service Principal using OAuth 2.0 client credentials flow. This function uses certificate-based authentication which is more secure than client secrets. Args: client_id (str): The Service Principal's client ID audience (str): The audience for the token (resource scope) authority (str): The OAuth authority URL certificate_path (str): Path to the certificate file (.pem format) private_key_path (str): Path to the private key file (.pem format) certificate_thumbprint (str): Certificate thumbprint (optional but recommended) Returns: str: The access token for API authentication Raises: Exception: If token acquisition fails """ try: # Read the certificate from PEM file with open(certificate_path, "r", encoding="utf-8") as f: certificate_pem = f.read() # Read the private key from PEM file with open(private_key_path, "r", encoding="utf-8") as f: private_key_pem = f.read() # Create the confidential client application app = ConfidentialClientApplication( client_id=client_id, authority=authority, client_credential={ "private_key": private_key_pem, "thumbprint": certificate_thumbprint, "certificate": certificate_pem } ) # Acquire token using client credentials flow token_response = app.acquire_token_for_client(scopes=[audience]) if "access_token" in token_response: print("Successfully acquired access token") return token_response["access_token"] else: raise Exception(f"Failed to retrieve token: {token_response.get('error_description', 'Unknown error')}") except FileNotFoundError as e: print(f"Certificate file not found: {e}") sys.exit(1) except Exception as e: print(f"Error retrieving token: {e}", file=sys.stderr) sys.exit(1) # Get the access token token = get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint)Uruchom komórkę notesu, powinien zostać zwrócony token Microsoft Entra.


Uwierzytelnij sesję interfejsu API Livy platformy Spark przy użyciu tokenu użytkownika Microsoft Entra
Utwórz notes
.ipynbw Visual Studio Code i wstaw następujący kod.from msal import PublicClientApplication import requests import time # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Application ID (can be the same as above or different) # Required scopes for Livy API access scopes = [ "https://api.fabric.microsoft.com/Lakehouse.Execute.All", # Required — execute operations in lakehouses "https://api.fabric.microsoft.com/Lakehouse.Read.All", # Required — read lakehouse metadata "https://api.fabric.microsoft.com/Code.AccessFabric.All", # Required — general Fabric API access from Spark Runtime "https://api.fabric.microsoft.com/Code.AccessStorage.All", # Required — access OneLake and Azure storage from Spark Runtime ] # Optional scopes — add these only if your Spark jobs need access to the corresponding services: # "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All" # Optional — access Azure Key Vault from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All" # Optional — access Azure Data Lake Storage Gen1 from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All" # Optional — access Azure Data Explorer from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessSQL.All" # Optional — access Azure SQL audience tokens from Spark Runtime def get_access_token(tenant_id, client_id, scopes): """ Get an access token using interactive authentication. This method will open a browser window for user authentication. Args: tenant_id (str): The Azure Active Directory tenant ID client_id (str): The application client ID scopes (list): List of required permission scopes Returns: str: The access token, or None if authentication fails """ app = PublicClientApplication( client_id, authority=f"https://login.microsoftonline.com/{tenant_id}" ) print("Opening browser for interactive authentication...") token_response = app.acquire_token_interactive(scopes=scopes) if "access_token" in token_response: print("Successfully authenticated") return token_response["access_token"] else: print(f"Authentication failed: {token_response.get('error_description', 'Unknown error')}") return None # Uncomment the lines below to use interactive authentication token = get_access_token(tenant_id, client_id, scopes) print("Access token acquired via interactive login")Uruchom komórkę notebooka, w przeglądarce powinno pojawić się okienko umożliwiające wybór tożsamości do zalogowania się.
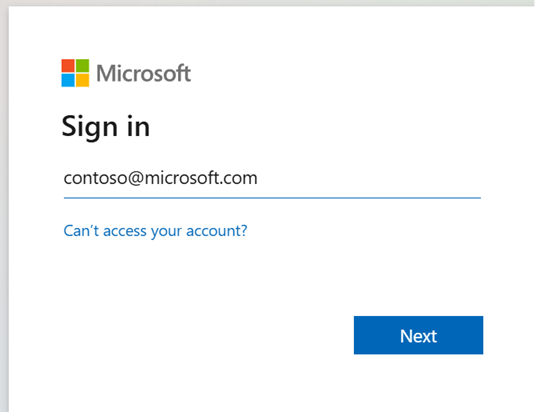
Po wybraniu tożsamości do logowania należy zatwierdzić uprawnienia interfejsu API rejestracji aplikacji Microsoft Entra.
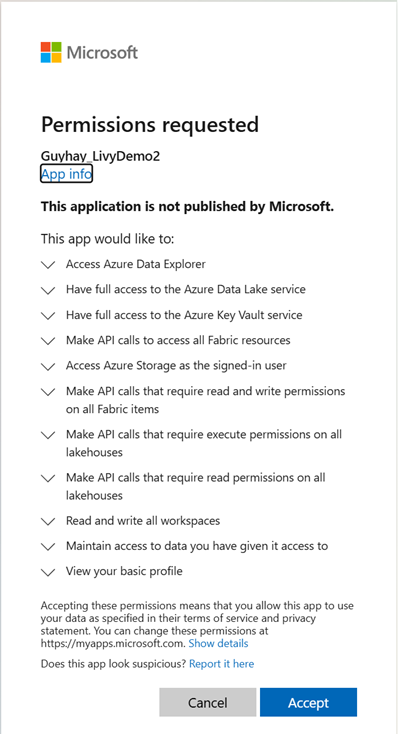
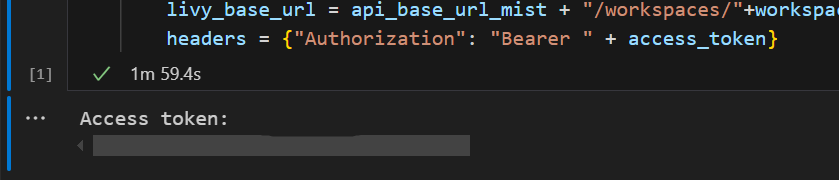
Zamknij okno przeglądarki po zakończeniu uwierzytelniania.

W programie Visual Studio Code powinien zostać wyświetlony zwrócony token Microsoft Entra.




Zrozumienie zakresów Code.* dla API Livy
Gdy zadania platformy Spark są uruchamiane za pośrednictwem interfejsu API usługi Livy, zakresy kontrolują, Code.* do jakich usług zewnętrznych środowisko uruchomieniowe platformy Spark może uzyskiwać dostęp w imieniu uwierzytelnionego użytkownika. Dwa są wymagane; pozostałe są opcjonalne w zależności od obciążenia.
Wymagane zakresy kodu.*
| Scope | Opis |
|---|---|
Code.AccessFabric.All |
Umożliwia uzyskiwanie tokenów dostępu do Microsoft Fabric. Wymagane dla wszystkich operacji interfejsu API Livy. |
Code.AccessStorage.All |
Umożliwia uzyskiwanie tokenów dostępu do usługi OneLake i magazynu Azure. Wymagane do odczytywania i zapisywania danych w lakehouse'ach. |
Opcjonalne zakresy Code.*
Dodaj te zakresy tylko wtedy, gdy zadania platformy Spark muszą uzyskiwać dostęp do odpowiednich usług Azure w czasie wykonywania.
| Scope | Opis | Kiedy stosować |
|---|---|---|
Code.AccessAzureKeyvault.All |
Umożliwia uzyskiwanie tokenów dostępu do Azure Key Vault. | Kod Spark pobiera tajemnice, klucze lub certyfikaty z Azure Key Vault. |
Code.AccessAzureDataLake.All |
Umożliwia uzyskiwanie tokenów dostępu do Azure Data Lake Storage Gen1. | Kod Spark odczytuje dane z kont Azure Data Lake Storage Gen1 lub zapisuje je na tych kontach. |
Code.AccessAzureDataExplorer.All |
Umożliwia uzyskiwanie tokenów dostępu do Azure Data Explorer (Kusto). | Kod platformy Spark wykonuje zapytania lub pozyskuje dane do/z klastrów Azure Data Explorer. |
Code.AccessSQL.All |
Umożliwia uzyskiwanie tokenów dostępu do Azure SQL. | Kod platformy Spark musi łączyć się z bazami danych Azure SQL. |
Uwaga / Notatka
Zakresy Lakehouse.Execute.All i Lakehouse.Read.All są również wymagane, ale nie są częścią Code.* rodziny. Udzielają uprawnień do wykonywania operacji oraz odczytywania metadanych z Fabric lakehouses.
Prześlij usługę Livy Batch i monitoruj zadanie wsadowe.
Dodaj kolejną komórkę notesu i wstaw ten kod.
# submit payload to existing batch session import requests import time import json api_base_url = "https://api.fabric.microsoft.com/v1" # Base URL for Fabric APIs # Fabric Resource IDs - Replace with your workspace and lakehouse IDs workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" # Construct the Livy Batch API URL # URL pattern: {base_url}/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/livyApi/versions/{api_version}/batches livy_base_url = f"{api_base_url}/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/livyApi/versions/2023-12-01/batches" # Set up authentication headers headers = {"Authorization": f"Bearer {token}"} print(f"Livy Batch API URL: {livy_base_url}") new_table_name = "TABLE_NAME" # Name for the new table # Configure the batch job print("Configuring batch job parameters...") # Batch job configuration - Modify these values for your use case payload_data = { # Job name - will appear in the Fabric UI "name": f"livy_batch_demo_{new_table_name}", # Path to your Python file in the lakehouse "file": "<ABFSS_PATH_TO_YOUR_PYTHON_FILE>", # Replace with your Python file path # Optional: Spark configuration parameters "conf": { "spark.targetTable": new_table_name, # Custom configuration for your application }, } print("Batch Job Configuration:") print(json.dumps(payload_data, indent=2)) try: # Submit the batch job print("\nSubmitting batch job...") post_batch = requests.post(livy_base_url, headers=headers, json=payload_data) if post_batch.status_code == 202: batch_info = post_batch.json() print("Livy batch job submitted successfully!") print(f"Batch Job Info: {json.dumps(batch_info, indent=2)}") # Extract batch ID for monitoring batch_id = batch_info['id'] livy_batch_get_url = f"{livy_base_url}/{batch_id}" print(f"\nBatch Job ID: {batch_id}") print(f"Monitoring URL: {livy_batch_get_url}") else: print(f"Failed to submit batch job. Status code: {post_batch.status_code}") print(f"Response: {post_batch.text}") except requests.exceptions.RequestException as e: print(f"Network error occurred: {e}") except json.JSONDecodeError as e: print(f"JSON decode error: {e}") print(f"Response text: {post_batch.text}") except Exception as e: print(f"Unexpected error: {e}")Uruchom komórkę notesu. Po utworzeniu i uruchomieniu zadania usługi Livy Batch powinno zostać wyświetlonych kilka wierszy.

** Aby wyświetlić zmiany, przejdź z powrotem do Lakehouse.

Integracja ze środowiskami Fabric
Domyślnie ta sesja interfejsu API usługi Livy działa na domyślnej puli początkowej dla obszaru roboczego. Alternatywnie możesz użyć Fabric Environments Utwórz, skonfiguruj i użyj środowiska w Microsoft Fabric, aby dostosować pulę Spark używaną przez sesję interfejsu API usługi Livy dla tych zadań Spark. Aby użyć środowiska Fabric, zaktualizuj poprzednią komórkę notatnika, dokonując zmiany w tym wierszu.
payload_data = {
"name":"livybatchdemo_with"+ newlakehouseName,
"file":"abfss://YourABFSPathToYourPayload.py",
"conf": {
"spark.targetLakehouse": "Fabric_LakehouseID",
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID"\"}" # remove this line to use starter pools instead of an environment, replace "EnvironmentID" with your environment ID
}
}
Wyświetl swoje zadania w centrum monitorowania
Aby wyświetlić różne działania platformy Apache Spark, możesz uzyskać dostęp do centrum monitorowania, wybierając pozycję Monitoruj w linkach nawigacji po lewej stronie.
Gdy zadanie wsadowe osiągnie stan zakończenia, możesz wyświetlić stan sesji, przechodząc do zakładki Monitor.
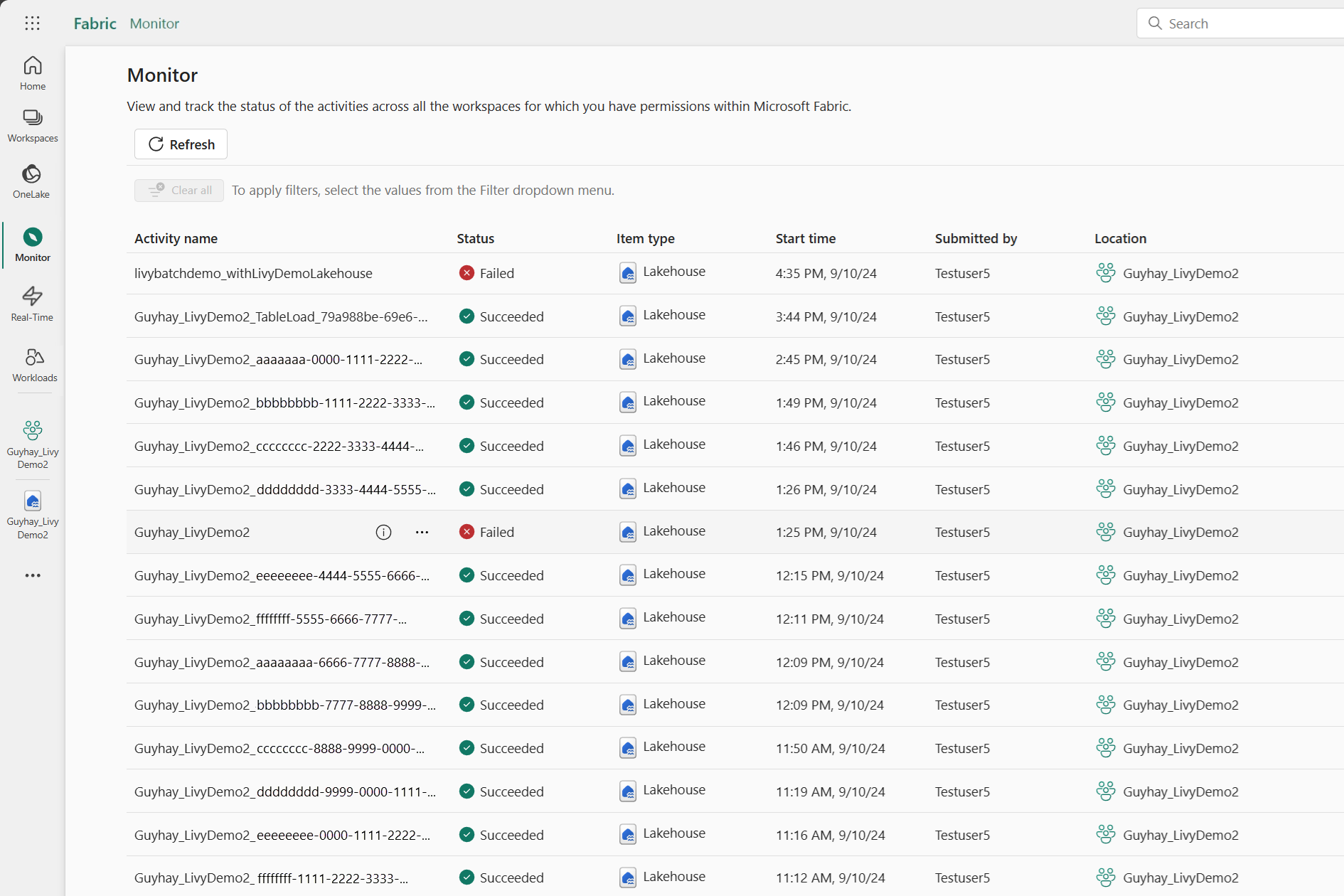
Wybierz i otwórz najnowszą nazwę działania.
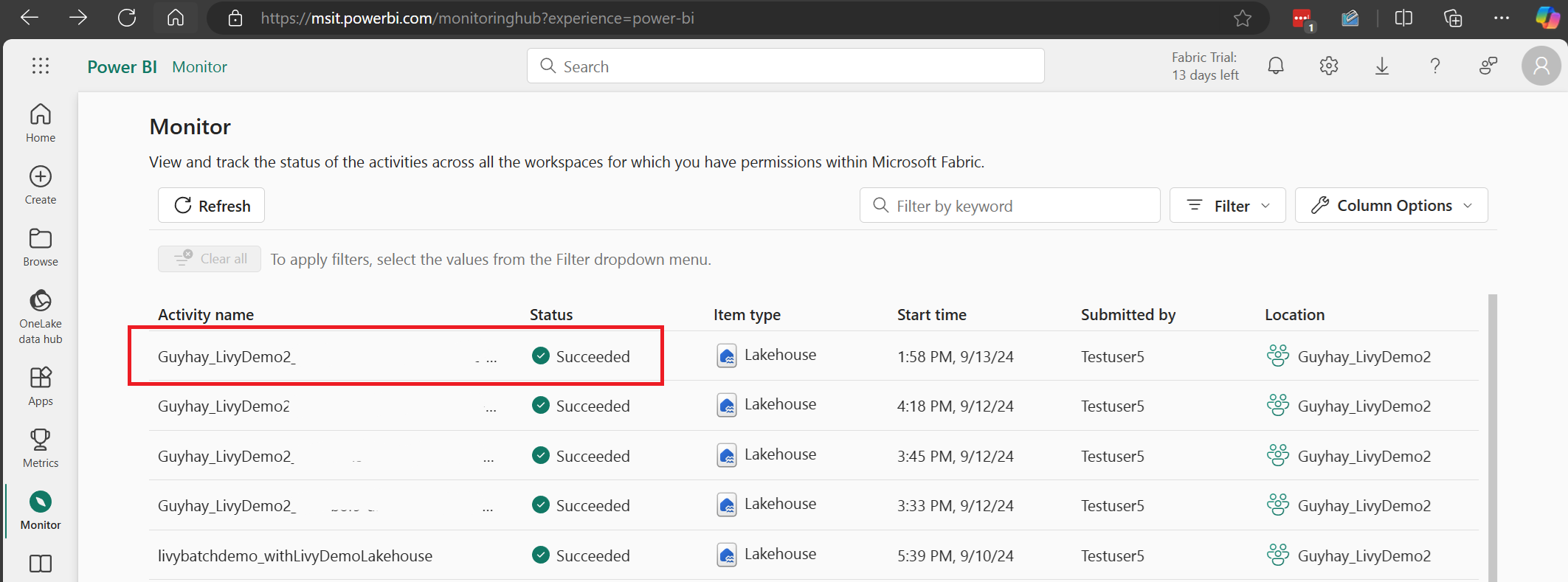
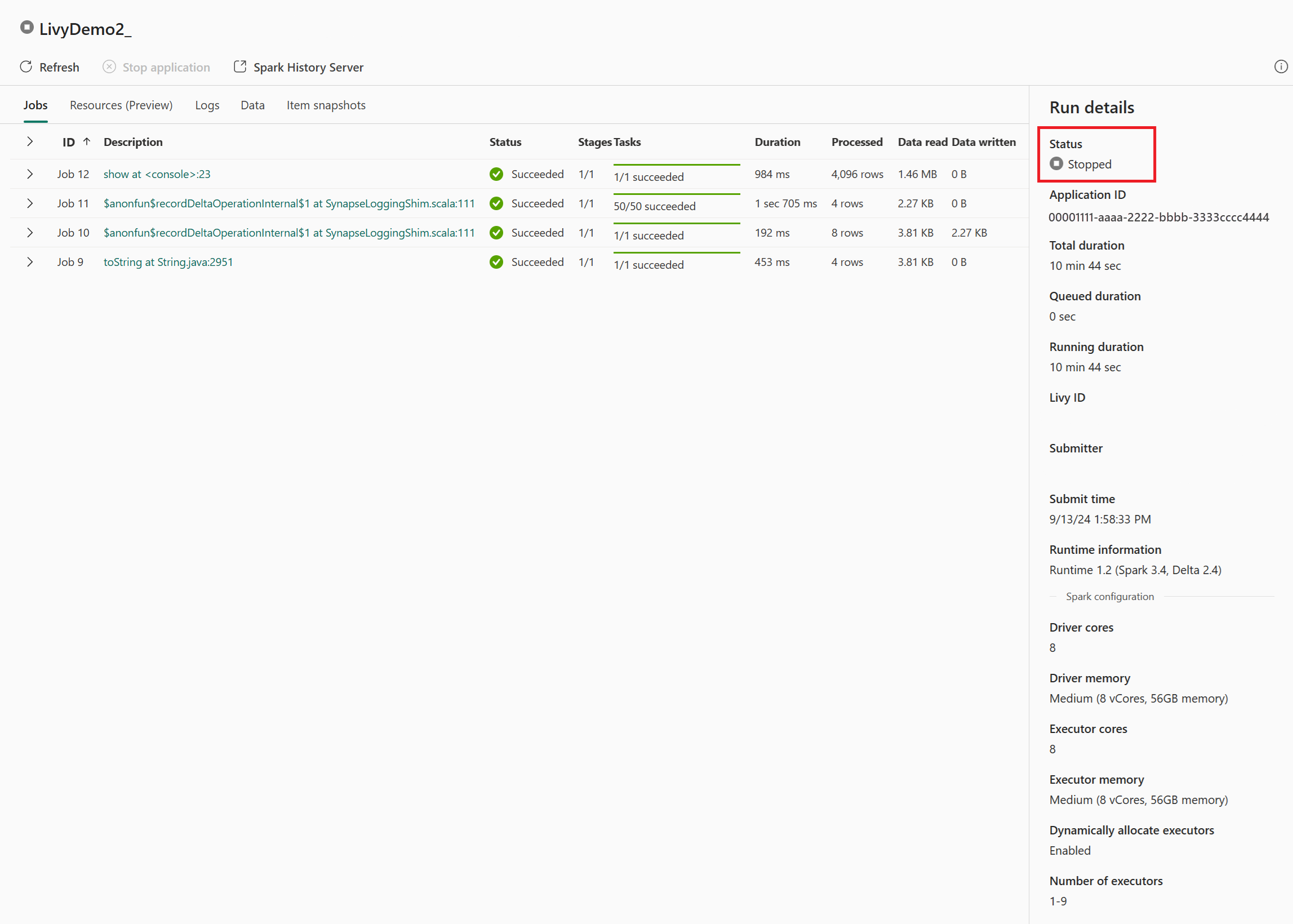
W tym przypadku sesji interfejsu API usługi Livy możesz zobaczyć poprzednie przesyłanie wsadowe, szczegóły uruchomienia, wersje platformy Spark i konfigurację. Zwróć uwagę na stan zatrzymania w prawym górnym rogu.



Aby podsumować cały proces, potrzebujesz zdalnego klienta, takiego jak Visual Studio Code, tokenu aplikacji Microsoft Entra, adresu URL punktu końcowego interfejsu API Livy, uwierzytelnienia do Lakehouse, zadania Spark w Lakehouse, oraz końcowo sesji wsadowej z interfejsem API Livy.