Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:✅ Inżynieria danych i nauka o danych w usłudze Microsoft Fabric
Dowiedz się, jak przesyłać zadania sesji Spark przy użyciu interfejsu API usługi Livy dla Fabric Data Engineering.
Ważne
Ta funkcja jest dostępna w wersji zapoznawczej.
Wymagania wstępne
Pojemność Premium lub pojemność próbna z Lakehouse
Klient zdalny, taki jak Visual Studio Code z Jupyter Notebooks, PySpark i biblioteką Microsoft Authentication Library (MSAL) dla Python
Albo token aplikacji Entra firmy Microsoft. Rejestrowanie aplikacji za pomocą platformy tożsamości firmy Microsoft
Lub token spN firmy Microsoft Entra. Dodawanie poświadczeń aplikacji i zarządzanie nimi w usłudze Microsoft Entra
Niektóre dane w lakehouse, w tym przykładzie użyto pliku Parquet green_tripdata_2022_08 z NYC Taxi & Limousine Commission, załadowanego do lakehouse.
Interfejs API usługi Livy definiuje ujednolicony punkt końcowy dla operacji. Zastąp symbole zastępcze {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID}, {Fabric_LakehouseID} i {Entra_ClientSecret} odpowiednimi wartościami, korzystając z przykładów w tym artykule.
Konfigurowanie programu Visual Studio Code dla sesji interfejsu API usługi Livy
Wybierz Ustawienia Lakehouse w usłudze Fabric Lakehouse.

Przejdź do sekcji Livy endpoint.
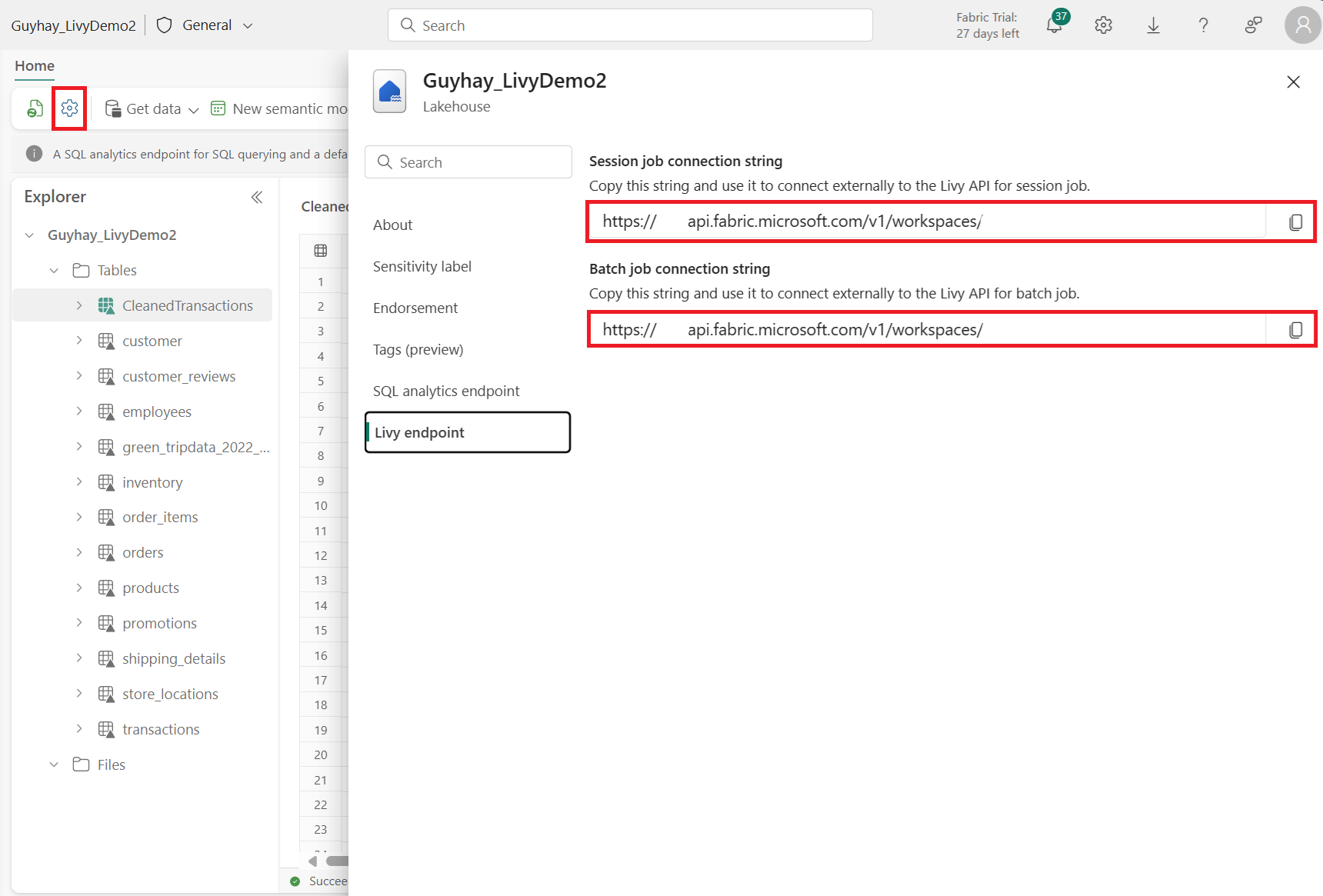
Skopiuj ciąg połączenia zadania sesji (pierwsze czerwone pole na obrazie) do swojego kodu.
Przejdź do Centrum administracyjne Microsoft Entra i skopiuj identyfikator aplikacji (klienta) i identyfikator katalogu (dzierżawcy) do swojego kodu.
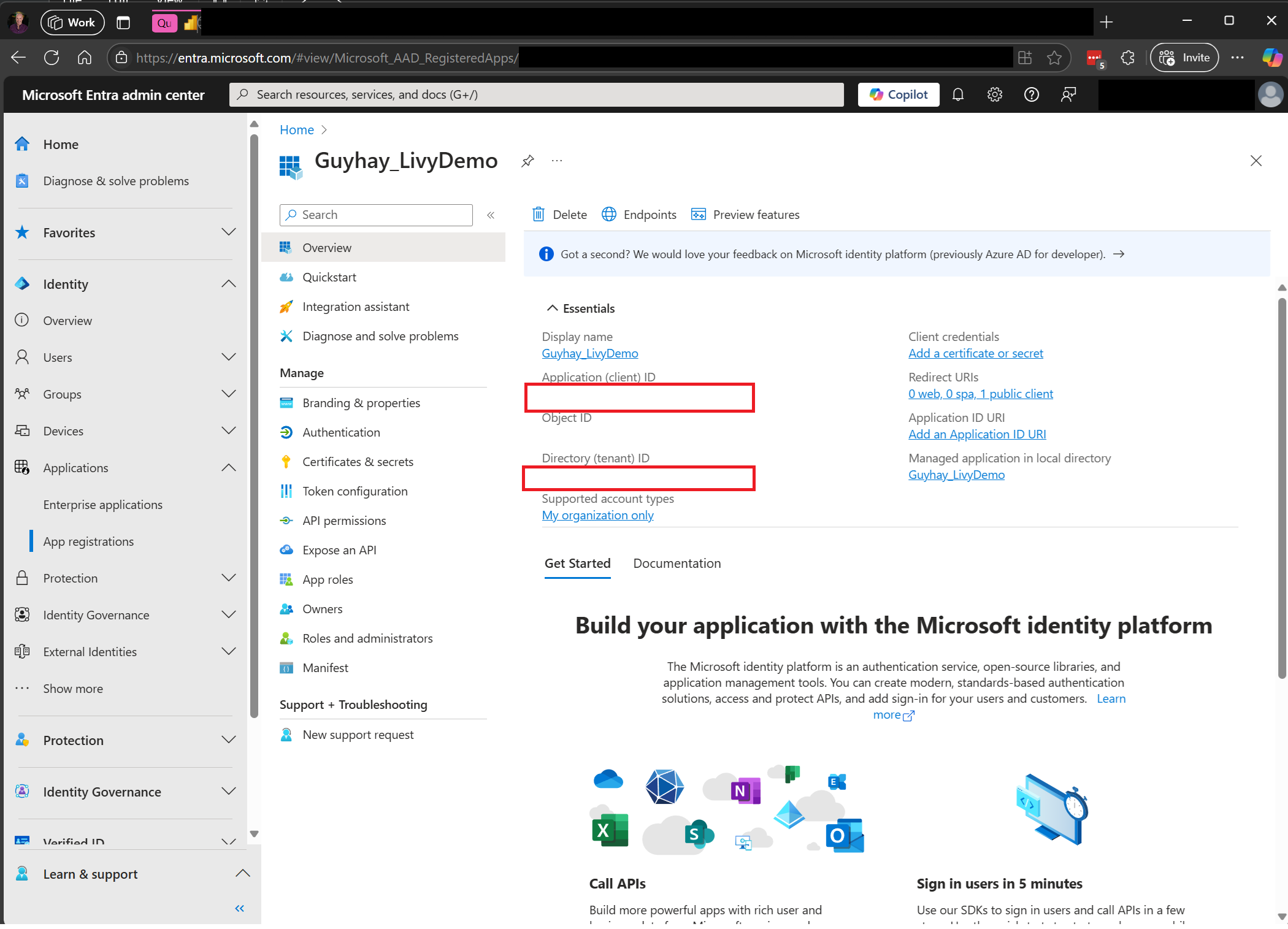



Uwierzytelnij sesję Livy API Spark za pomocą tokenu użytkownika Entra lub tokenu SPN Entra.
Uwierzytelnij sesję Spark interfejsu API Livy przy użyciu tokenu Entra SPN.
.ipynbUtwórz notes w programie Visual Studio Code i wstaw następujący kod.from msal import ConfidentialClientApplication import requests import time tenant_id = "Entra_TenantID" client_id = "Entra_ClientID" client_secret = "Entra_ClientSecret" audience = "https://api.fabric.microsoft.com/.default" workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" # Get the app-only token def get_app_only_token(tenant_id, client_id, client_secret, audience): """ Get an app-only access token for a Service Principal using OAuth 2.0 client credentials flow. Args: tenant_id (str): The Azure Active Directory tenant ID. client_id (str): The Service Principal's client ID. client_secret (str): The Service Principal's client secret. audience (str): The audience for the token (e.g., resource-specific scope). Returns: str: The access token. """ try: # Define the authority URL for the tenant authority = f"https://login.microsoftonline.com/{tenant_id}" # Create a ConfidentialClientApplication instance app = ConfidentialClientApplication( client_id = client_id, client_credential = client_secret, authority = authority ) # Acquire a token using the client credentials flow result = app.acquire_token_for_client(scopes = [audience]) # Check if the token was successfully retrieved if "access_token" in result: return result["access_token"] else: raise Exception("Failed to retrieve token: {result.get('error_description', 'Unknown error')}") except Exception as e: print(f"Error retrieving token: {e}", fil = sys.stderr) sys.exit(1) token = get_app_only_token(tenant_id, client_id, client_secret, audience) api_base_url = 'https://api.fabric.microsoft.com/v1/' livy_base_url = api_base_url + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + token} print(token)W programie Visual Studio Code powinien zostać zwrócony token Entra firmy Microsoft.
 ```
```

Uwierzytelnij sesję Spark interfejsu API Livy przy użyciu tokenu użytkownika Entra.
.ipynbUtwórz notes w programie Visual Studio Code i wstaw następujący kod.from msal import PublicClientApplication import requests import time tenant_id = "Entra_TenantID" client_id = "Entra_ClientID" workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" app = PublicClientApplication( client_id, authority = "https://login.microsoftonline.com/"Entra_TenantID" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes = ["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item. ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url ='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/sessions" headers = {"Authorization": "Bearer " + access_token}W programie Visual Studio Code powinien zostać zwrócony token Entra firmy Microsoft.

Tworzenie sesji platformy Spark interfejsu API usługi Livy
Dodaj kolejną komórkę notesu i wstaw ten kod.
create_livy_session = requests.post(livy_base_url, headers = headers, json={}) print('The request to create the Livy session is submitted:' + str(create_livy_session.json())) livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers = headers) print(get_session_response.json())Uruchom komórkę notesu. Powinien zostać wyświetlony jeden wiersz wydrukowany podczas tworzenia sesji usługi Livy.

Możesz sprawdzić, czy sesja usługi Livy została utworzona, korzystając z opcji [Wyświetl swoje zadania w Centrum monitorowania](#View your jobs in the Monitoring hub).

Integracja ze środowiskami Fabric
Domyślnie ta sesja interfejsu API usługi Livy działa na domyślnej puli początkowej dla obszaru roboczego. Alternatywnie możesz użyć środowisk Fabric Tworzenie, konfigurowanie i używanie środowiska w usłudze Microsoft Fabric, aby dostosować pulę Spark, z której sesja interfejsu API Livy korzysta do tych zadań Spark. Aby użyć Fabric Environment, po prostu zaktualizuj poprzednią komórkę notatnika z tym ładunkiem JSON.
create_livy_session = requests.post(livy_base_url, headers = headers, json = {
"conf" : {
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID""}"}
}
)
Przesyłanie instrukcji spark.sql przy użyciu sesji usługi Livy API Spark
Dodaj kolejną komórkę notesu i wstaw ten kod.
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers = headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers = headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where fare_amount = 60\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers = headers, json = payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url + "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers = headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers = headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)Uruchom komórkę notesu. Powinno zostać wyświetlonych kilka wierszy przyrostowych wydrukowanych podczas przesyłania zadania i zwracanych wyników.
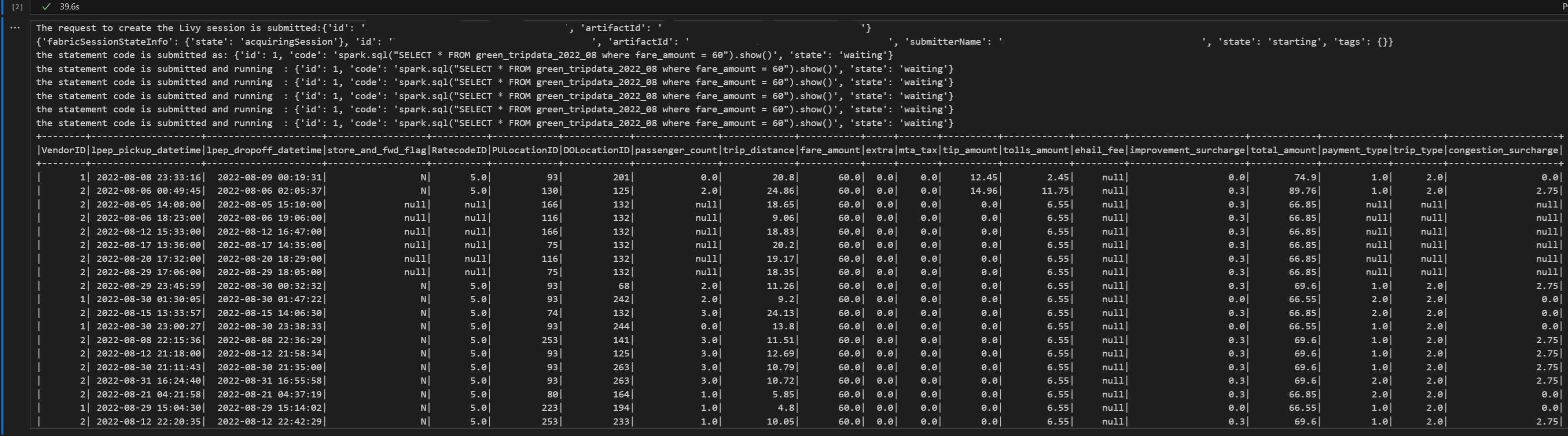

Prześlij drugą instrukcję spark.sql przy użyciu sesji usługi Livy API Spark
Dodaj kolejną komórkę notesu i wstaw ten kod.
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers = headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers = headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where tip_amount = 10\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers = headers, json = payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url + "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers = headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers = headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)Uruchom komórkę notesu. Powinno zostać wyświetlonych kilka wierszy przyrostowych wydrukowanych podczas przesyłania zadania i zwracanych wyników.
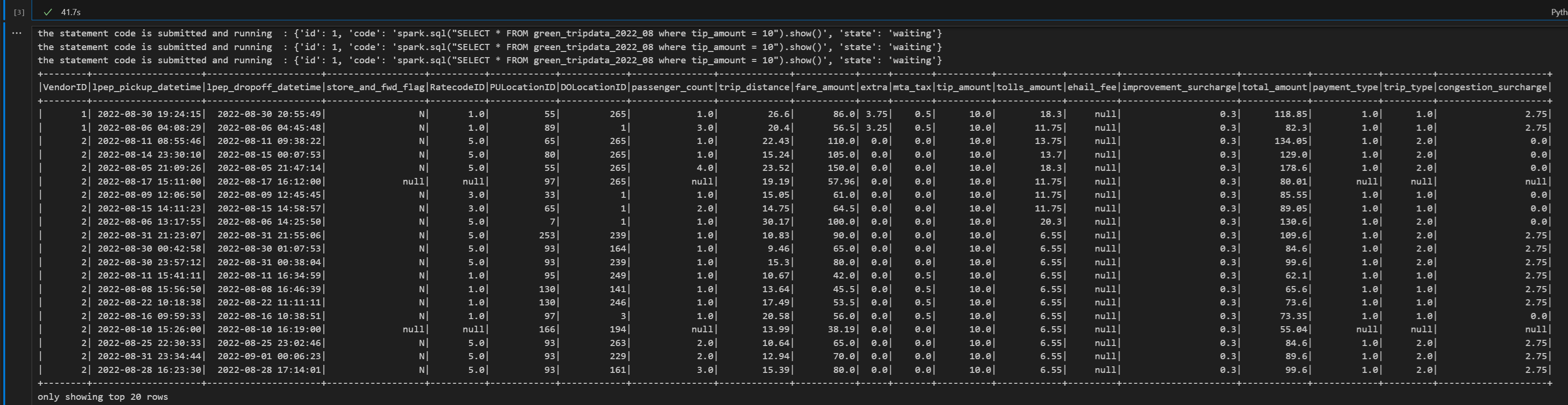

Zamknij sesję usługi Livy za pomocą trzeciej instrukcji
Dodaj kolejną komórkę notesu i wstaw ten kod.
# call get session API with a delete session statement get_session_response = requests.get(livy_session_url, header = headers) print('Livy statement URL ' + livy_session_url) response = requests.delete(livy_session_url, headers = headers) print (response)
Wyświetl swoje zadania w centrum monitorowania
Aby wyświetlić różne działania platformy Apache Spark, możesz uzyskać dostęp do centrum monitorowania, wybierając pozycję Monitoruj w linkach nawigacji po lewej stronie.
Gdy sesja jest w toku lub jest w stanie ukończonym, możesz wyświetlić stan sesji, przechodząc do pozycji Monitor.
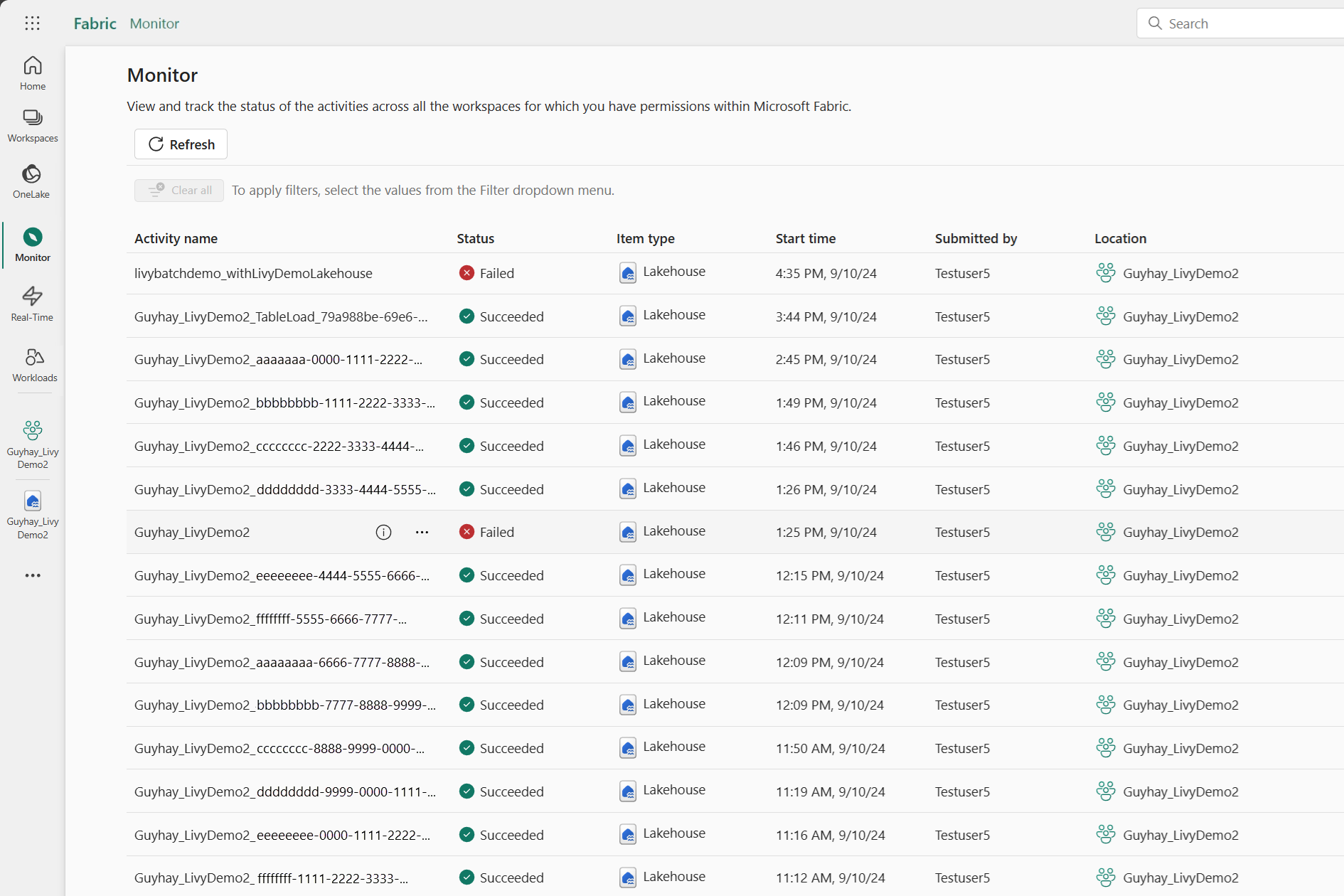
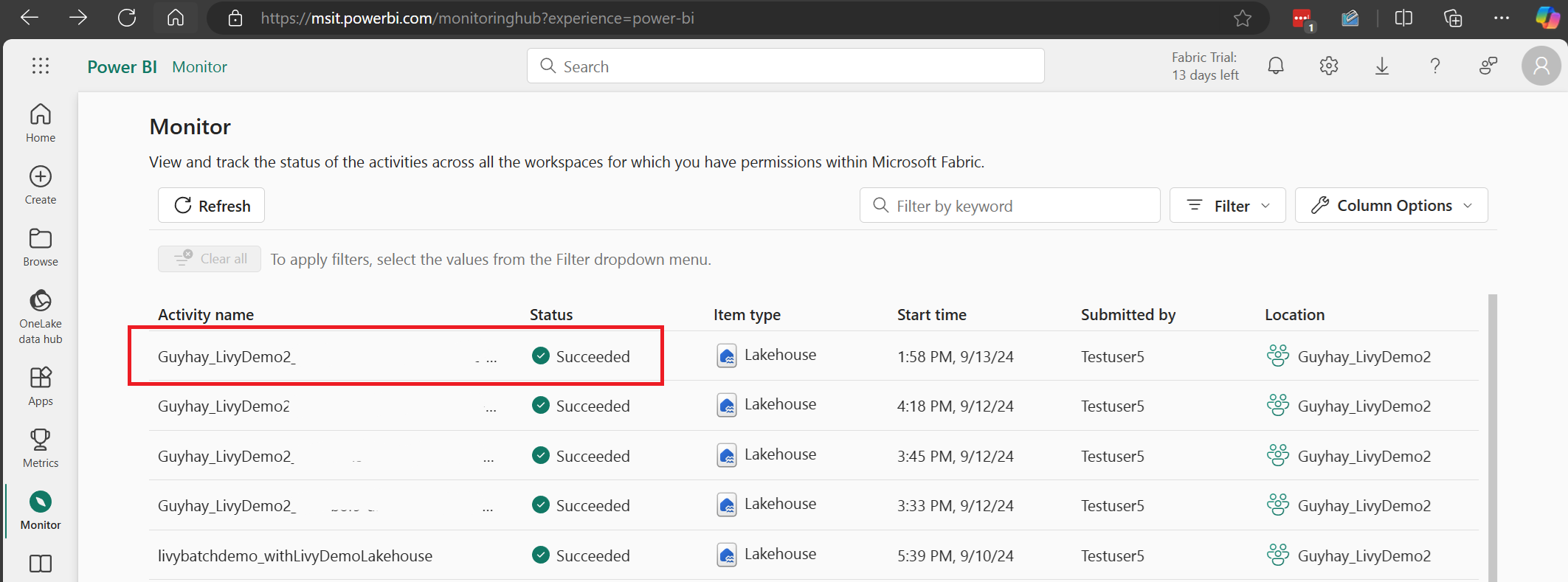
Wybierz i otwórz najnowszą nazwę działania.
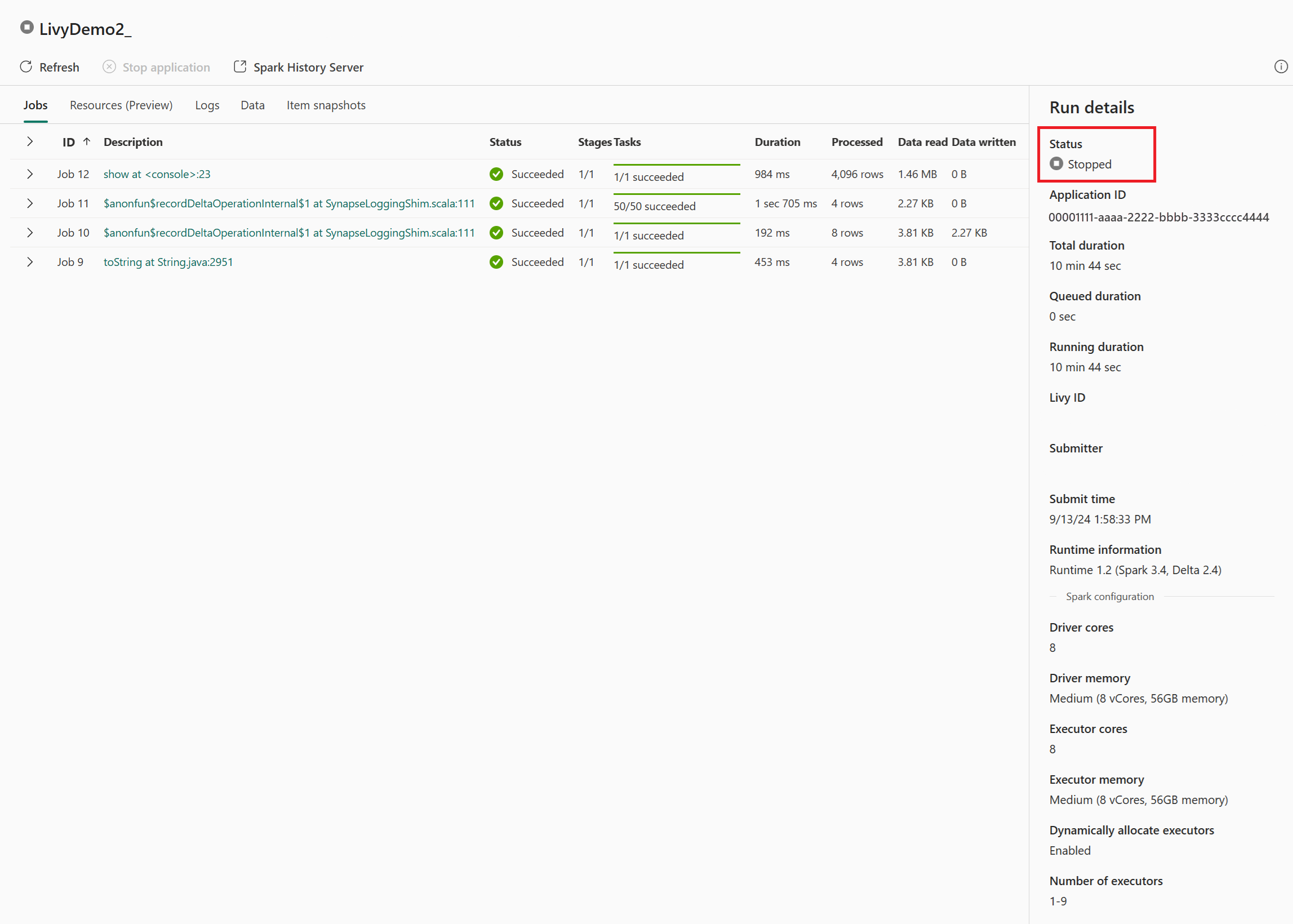
W tym przypadku sesji interfejsu API usługi Livy można wyświetlić poprzednie przesłania sesji, szczegóły uruchomienia, wersje platformy Spark i konfigurację. Zwróć uwagę na status zatrzymania w prawym górnym rogu.

Aby podsumować cały proces, potrzebny jest klient zdalny, taki jak Visual Studio Code, aplikacja/SPN Microsoft Entra, adres URL punktu końcowego interfejsu API Livy, uwierzytelnianie względem usługi Lakehouse, a na koniec interfejs API sesji Livy.