Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym szybkim przewodniku wyjaśniono, jak utworzyć definicję zadania platformy Spark zawierającą kod języka Python z użyciem Spark Structured Streaming, aby umieścić dane w systemie lakehouse, a następnie udostępnić je za pośrednictwem punktu końcowego SQL analytics. Po ukończeniu tego krótkiego przewodnika będziesz mieć definicję zadania Spark, która działa w sposób ciągły, a punkt końcowy analityki SQL może przeglądać dane przychodzące.
Tworzenie skryptu w języku Python
Użyj następującego skryptu języka Python, aby utworzyć tabelę Delta przesyłania strumieniowego w usłudze Lakehouse przy użyciu platformy Apache Spark. Skrypt odczytuje strumień wygenerowanych danych (jeden wiersz na sekundę) i zapisuje go w trybie dołączania do tabeli delty o nazwie streamingtable. Przechowuje dane i informacje o punkcie kontrolnym w określonym jeziorze.
Użyj następującego kodu w języku Python, który używa ustrukturyzowanego przesyłania strumieniowego Spark do pobierania danych w tabeli w lakehouse.
from pyspark.sql import SparkSession if __name__ == "__main__": # Start Spark session spark = SparkSession.builder \ .appName("RateStreamToDelta") \ .getOrCreate() # Table name used for logging tableName = "streamingtable" # Define Delta Lake storage path deltaTablePath = f"Tables/{tableName}" # Create a streaming DataFrame using the rate source df = spark.readStream \ .format("rate") \ .option("rowsPerSecond", 1) \ .load() # Write the streaming data to Delta query = df.writeStream \ .format("delta") \ .outputMode("append") \ .option("path", deltaTablePath) \ .option("checkpointLocation", f"{deltaTablePath}/_checkpoint") \ .start() # Keep the stream running query.awaitTermination()Zapisz skrypt jako plik języka Python (.py) na komputerze lokalnym.
Tworzenie jeziora
Aby utworzyć jezioro, wykonaj następujące czynności:
Zaloguj się do portalu Microsoft Fabric.
W razie potrzeby przejdź do żądanego obszaru roboczego lub utwórz nowy.
Aby utworzyć lakehouse, wybierz Nowy element z obszaru roboczego, a następnie wybierz Lakehouse w panelu, który się otworzy.
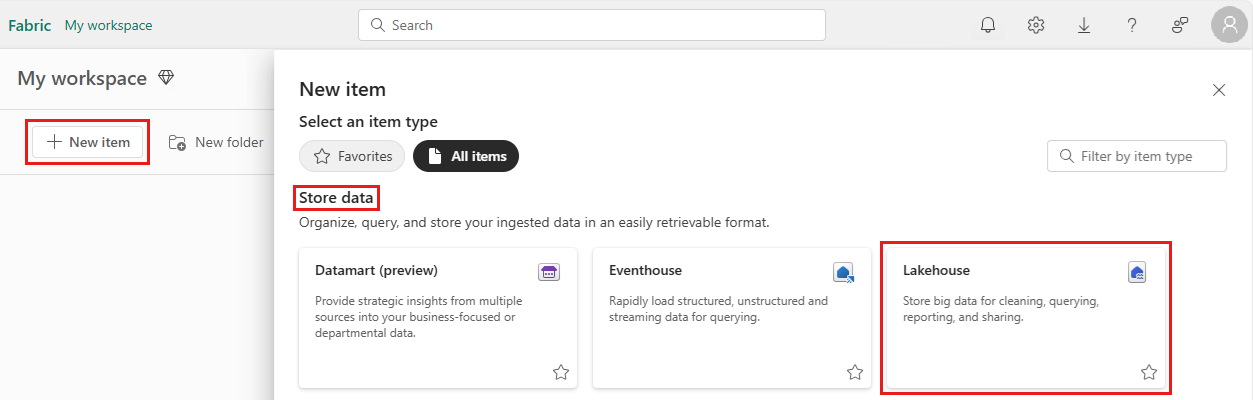
Wprowadź nazwę swojego domu nad jeziorem i wybierz Utwórz.

Tworzenie definicji zadania platformy Spark
Aby utworzyć definicję zadania platformy Spark, wykonaj następujące czynności:
W tym samym obszarze roboczym, w którym utworzono lakehouse, wybierz Nowy element.
W wyświetlonym panelu w obszarze Pobieranie danych wybierz pozycję Definicja zadania platformy Spark.
Wprowadź nazwę definicji zadania platformy Spark i wybierz pozycję Utwórz.
Wybierz pozycję Przekaż i wybierz plik języka Python utworzony w poprzednim kroku.
W obszarze Dokumentacja usługi Lakehouse wybierz utworzoną usługę Lakehouse.
Ustawianie zasad ponawiania dla definicji zadania platformy Spark
Wykonaj następujące kroki, aby ustawić zasady ponawiania dla definicji zadania platformy Spark:
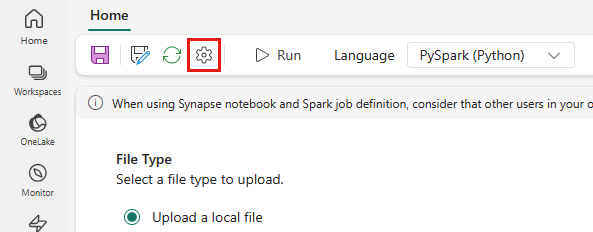
W górnym menu wybierz ikonę Ustawienie .
Otwórz kartę Optymalizacja i ustaw Zasady ponawiania prób na wyzwalacz Włączony.
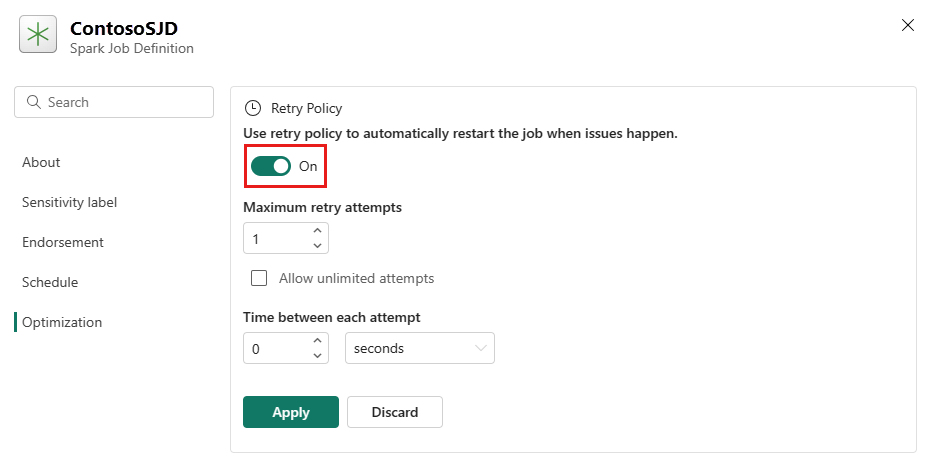
Zdefiniuj maksymalną liczbę ponownych prób lub zaznacz opcję Zezwalaj na nieograniczone próby.
Określ czas między każdą ponowną próbą i wybierz pozycję Zastosuj.


Uwaga
Obowiązuje limit 90 dni na ustawienie zasad ponawiania. Po włączeniu zasad ponawiania zadania zostaną uruchomione ponownie zgodnie z zasadami w ciągu 90 dni. Po upływie tego okresu zasady ponawiania będą automatycznie przestać działać, a zadanie zostanie zakończone. Następnie użytkownicy będą musieli ręcznie ponownie uruchomić zadanie, co spowoduje ponowne aktywowanie polityki ponawiania prób.
Wykonywanie i monitorowanie definicji zadania platformy Spark
W górnym menu wybierz ikonę Uruchom .
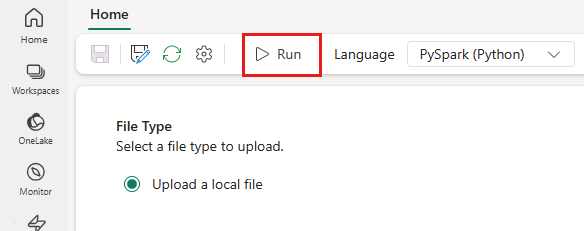
Sprawdź, czy definicja zadania Spark została pomyślnie przesłana i uruchomiona.

Wyświetlanie danych przy użyciu punktu końcowego analizy SQL
Po uruchomieniu skryptu w lakehouse zostanie utworzona tabela o nazwie streamingtable z kolumną timestamp i kolumną value. Dane można wyświetlić przy użyciu punktu końcowego analizy SQL:
W obszarze roboczym otwórz usługę Lakehouse.
Wybierz punkt końcowy analizy SQL z prawego górnego rogu.
W okienku nawigacji po lewej stronie rozwiń pozycję Schematy > dbo >Tables, wybierz pozycję streamingtable, aby wyświetlić podgląd danych.