Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku użyjesz notesów ze środowiskiem uruchomieniowym platformy Spark, aby przekształcić i przygotować nieprzetworzone dane w usłudze LakeHouse.
Wymagania wstępne
Jeśli nie masz magazynu lakehouse zawierającego dane, musisz:
Przygotowywanie danych
W poprzednich krokach samouczka mamy nieprzetworzone dane pozyskane ze źródła do sekcji Pliki w lakehouse. Teraz możesz przekształcić te dane i przygotować je do tworzenia tabel delty.
Pobierz notesy z folderu Kod źródłowy samouczka usługi Lakehouse.
Otwórz obszar roboczy, wybierz pozycję Importuj>notes>z tego komputera.
Wybierz pozycję Importuj notes z sekcji Nowy w górnej części strony docelowej.
Wybierz pozycję Przekaż w okienku Stan importu, który zostanie otwarty po prawej stronie ekranu.
Wybierz wszystkie notesy pobrane w pierwszym kroku tej sekcji.
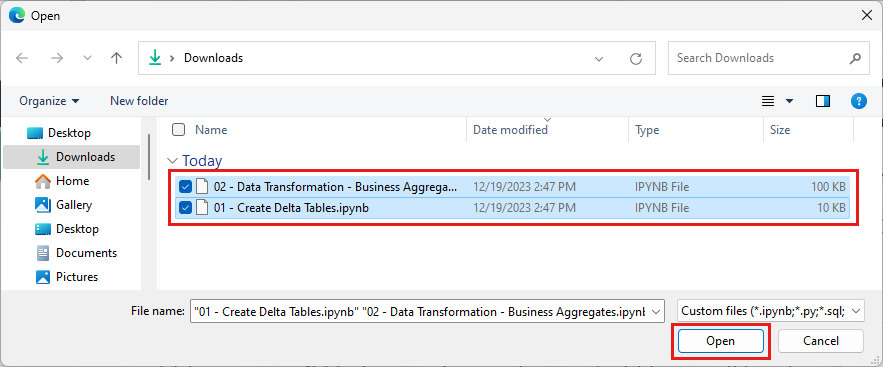
Wybierz Otwórz. W prawym górnym rogu okna przeglądarki zostanie wyświetlone powiadomienie wskazujące stan importu.
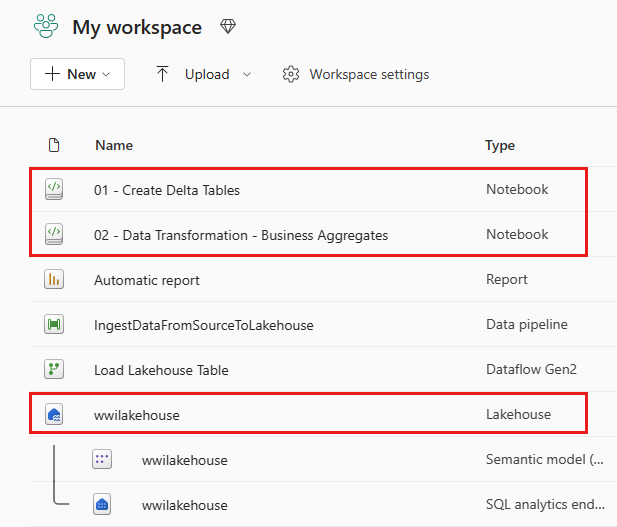
Po pomyślnym zaimportowaniu przejdź do widoku elementów obszaru roboczego i zobacz nowo zaimportowane notesy. Wybierz pozycję wwilakehouse lakehouse , aby go otworzyć.
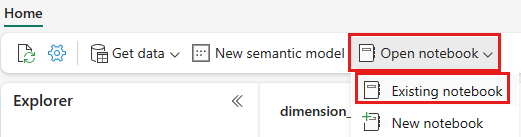
Po otwarciu usługi Lakehouse wwilakehouse wybierz pozycję Otwórz notes Istniejący notes> z górnego menu nawigacji.
Z listy istniejących notesów wybierz notes 01 — Utwórz tabele delty i wybierz pozycję Otwórz.
W otwartym notesie w eksploratorze lakehouse zobaczysz, że notes jest już połączony z otwartą usługą lakehouse.
Uwaga
Sieć szkieletowa zapewnia możliwość zamawiania maszyn wirtualnych do zapisywania zoptymalizowanych plików usługi Delta Lake. Kolejność maszyn wirtualnych często poprawia kompresję o trzy do czterech razy, a do 10 razy przyspiesza wydajność plików usługi Delta Lake, które nie są zoptymalizowane. Platforma Spark w sieci szkieletowej dynamicznie optymalizuje partycje podczas generowania plików o domyślnym rozmiarze 128 MB. Rozmiar pliku docelowego można zmienić na wymagania dotyczące obciążenia przy użyciu konfiguracji.
Dzięki możliwości optymalizacji zapisu aparat platformy Apache Spark zmniejsza liczbę zapisanych plików i ma na celu zwiększenie indywidualnego rozmiaru zapisanych danych.
Przed zapisem danych jako tabelami usługi Delta Lake w sekcji Tabele usługi Lakehouse należy użyć dwóch funkcji sieci szkieletowej (kolejność V i Optymalizowanie zapisu) w celu zoptymalizowanego zapisywania danych i zwiększenia wydajności odczytu. Aby włączyć te funkcje w sesji, ustaw te konfiguracje w pierwszej komórce notesu.
Aby uruchomić notes i wykonać wszystkie komórki w sekwencji, wybierz pozycję Uruchom wszystko na górnej wstążce (w obszarze Narzędzia główne). Lub, aby wykonać kod tylko z określonej komórki, wybierz ikonę Uruchom , która jest wyświetlana po lewej stronie komórki po umieszczeniu kursora, lub naciśnij SHIFT + ENTER na klawiaturze, gdy kontrolka znajduje się w komórce.
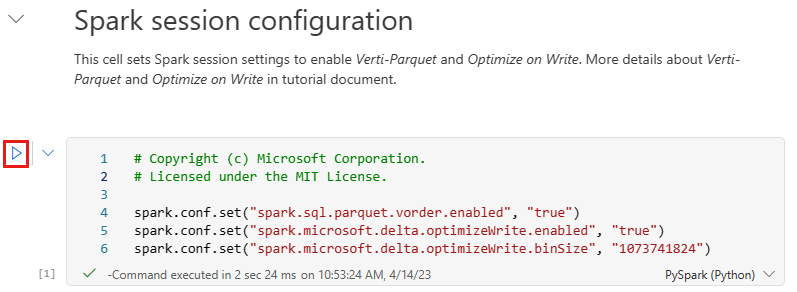
Podczas uruchamiania komórki nie trzeba było określać bazowej puli spark ani szczegółów klastra, ponieważ sieć szkieletowa udostępnia je za pośrednictwem puli na żywo. Każdy obszar roboczy sieci Szkieletowej zawiera domyślną pulę platformy Spark o nazwie Live Pool. Oznacza to, że podczas tworzenia notesów nie musisz martwić się o określanie żadnych konfiguracji platformy Spark ani szczegółów klastra. Po wykonaniu pierwszego polecenia notesu pula na żywo jest uruchomiona w ciągu kilku sekund. A sesja platformy Spark zostanie ustanowiona i rozpocznie wykonywanie kodu. Kolejne wykonywanie kodu jest niemal natychmiastowe w tym notesie, gdy sesja platformy Spark jest aktywna.
Następnie odczytujesz nieprzetworzone dane z sekcji Pliki lakehouse i dodasz więcej kolumn dla różnych części daty w ramach transformacji. Na koniec użyjesz partycji według interfejsu API platformy Spark do partycjonowania danych przed zapisaniem ich jako formatu tabeli delta na podstawie nowo utworzonych kolumn części danych (Rok i Kwartał).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Po załadowaniu tabel faktów można przejść do ładowania danych dla pozostałych wymiarów. Poniższa komórka tworzy funkcję służącą do odczytywania danych pierwotnych z sekcji Pliki magazynu lakehouse dla każdej z nazw tabel przekazanych jako parametr. Następnie tworzy listę tabel wymiarów. Na koniec przechodzi przez listę tabel i tworzy tabelę różnicową dla każdej nazwy tabeli odczytanej z parametru wejściowego. Zwróć uwagę, że skrypt odrzuca kolumnę o nazwie
Photow tym przykładzie, ponieważ kolumna nie jest używana.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Aby zweryfikować utworzone tabele, kliknij prawym przyciskiem myszy i wybierz pozycję Odśwież w lakehouse wwilakehouse . Pojawią się tabele.
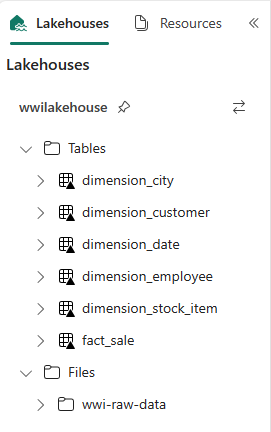
Ponownie przejdź do widoku elementów obszaru roboczego i wybierz obiekt lakehouse wwilakehouse , aby go otworzyć.
Teraz otwórz drugi notes. W widoku lakehouse wybierz pozycję Otwórz notes Istniejący notes> na wstążce.
Z listy istniejących notesów wybierz notes 02 — Przekształcanie danych — Business , aby go otworzyć.
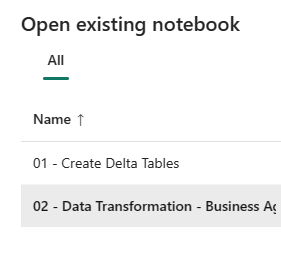
W otwartym notesie w eksploratorze lakehouse zobaczysz, że notes jest już połączony z otwartą usługą lakehouse.
Organizacja może mieć inżynierów danych pracujących z językiem Scala/Python i innymi inżynierami danych pracującymi z językiem SQL (Spark SQL lub T-SQL), którzy pracują nad tą samą kopią danych. Sieć szkieletowa umożliwia pracę i współpracę dla tych różnych grup, ze zróżnicowanym doświadczeniem i preferencjami. Dwa różne podejścia przekształcają i generują agregacje biznesowe. Możesz wybrać ten odpowiedni dla Ciebie lub wymieszać i dopasować te podejścia na podstawie preferencji bez naruszania wydajności:
Podejście nr 1 — użyj narzędzia PySpark do łączenia i agregowania danych do generowania agregacji biznesowych. Takie podejście jest preferowane dla kogoś, kto ma doświadczenie w programowaniu (Python lub PySpark).
Podejście nr 2 — używanie usługi Spark SQL do łączenia i agregowania danych na potrzeby generowania agregacji biznesowych. To podejście jest preferowane dla osoby z doświadczeniem SQL, przechodząc do platformy Spark.
Podejście nr 1 (sale_by_date_city) — użyj narzędzia PySpark do łączenia i agregowania danych do generowania agregacji biznesowych. W poniższym kodzie utworzysz trzy różne ramki danych platformy Spark, z których każda odwołuje się do istniejącej tabeli delty. Następnie połączysz te tabele przy użyciu ramek danych, pogrupuj według, aby wygenerować agregację, zmienić nazwę kilku kolumn, a na koniec zapisać ją jako tabelę delty w sekcji Tabele usługi Lakehouse, aby zachować dane.
W tej komórce utworzysz trzy różne ramki danych platformy Spark, z których każda odwołuje się do istniejącej tabeli delty.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Dodaj następujący kod do tej samej komórki, aby połączyć te tabele przy użyciu utworzonych wcześniej ramek danych. Grupuj według, aby wygenerować agregację, zmienić nazwę kilku kolumn, a na koniec zapisać ją jako tabelę delty w sekcji Tabele w lakehouse.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Podejście nr 2 (sale_by_date_employee) — użyj usługi Spark SQL do łączenia i agregowania danych w celu generowania agregacji biznesowych. W poniższym kodzie utworzysz tymczasowy widok platformy Spark, łącząc trzy tabele, grupuj według, aby wygenerować agregację i zmienić nazwę kilku kolumn. Na koniec odczytujesz z tymczasowego widoku platformy Spark i na koniec zapiszesz ją jako tabelę delta w sekcji Tabele magazynu lakehouse, aby zachować dane.
W tej komórce utworzysz tymczasowy widok platformy Spark, łącząc trzy tabele, grupuj według, aby wygenerować agregację i zmienić nazwę kilku kolumn.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCW tej komórce odczytujesz z tymczasowego widoku platformy Spark utworzonego w poprzedniej komórce i na koniec zapiszesz ją jako tabelę delty w sekcji Tabele lakehouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Aby zweryfikować utworzone tabele, kliknij prawym przyciskiem myszy i wybierz polecenie Odśwież w lakehouse wwilakehouse . Pojawią się tabele agregacji.
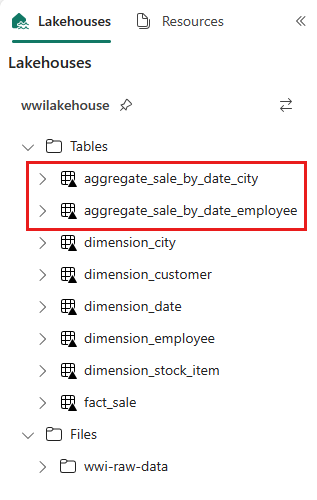







Te dwa podejścia generują podobny wynik. Aby zminimalizować potrzebę uczenia się nowej technologii lub naruszenia zabezpieczeń wydajności, wybierz podejście, które najlepiej odpowiada twoim potrzebom i preferencjom.
Możesz zauważyć, że zapisujesz dane jako pliki usługi Delta Lake. Funkcja automatycznego odnajdywania i rejestrowania tabel w usłudze Fabric pobiera je i rejestruje w magazynie metadanych. Nie trzeba jawnie wywoływać CREATE TABLE instrukcji w celu utworzenia tabel do użycia z językiem SQL.