Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano sposób konfigurowania formatu Parquet w potoku danych usługi Data Factory w usłudze Microsoft Fabric.
Obsługiwane możliwości
Format Parquet jest obsługiwany w przypadku następujących działań i łączników jako źródła i miejsca docelowego.
| Kategoria | Łącznik/działanie |
|---|---|
| Obsługiwany łącznik | Amazon S3 |
| Zgodność z usługą Amazon S3 | |
| Azure Blob Storage | |
| Usługa Azure Data Lake Storage 1. generacji | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| System plików | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Pliki lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Obsługiwane działanie | działanie Kopiuj (źródło/miejsce docelowe) |
| Działanie Lookup | |
| Działanie GetMetadata | |
| Działanie usuwania |
Format Parquet w działaniu kopiowania
Aby skonfigurować format Parquet, wybierz połączenie w źródle lub miejscu docelowym działania kopiowania potoku danych, a następnie wybierz pozycję Parquet z listy rozwijanej Format pliku. Wybierz pozycję Ustawienia , aby uzyskać dalszą konfigurację tego formatu.
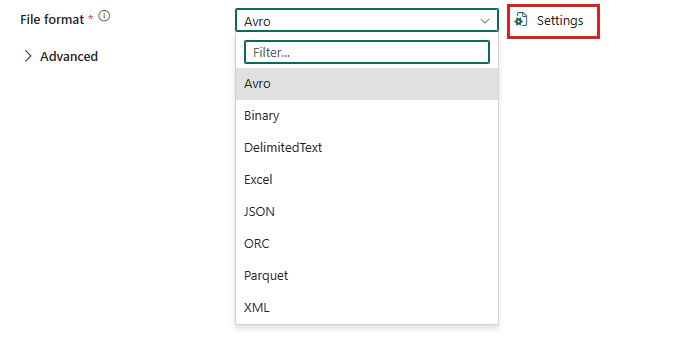
Format Parquet jako źródło
Po wybraniu pozycji Ustawienia w sekcji Format pliku w oknie dialogowym Ustawienia formatu pliku zostaną wyświetlone następujące właściwości.
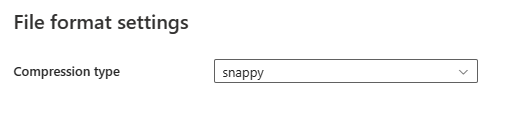
- Typ kompresji: wybierz koder-dekoder kompresji używany do odczytywania plików Parquet na liście rozwijanej. Możesz wybrać spośród opcji None, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2), lub lz4hadoop.
Format Parquet jako miejsce docelowe
Po wybraniu pozycji Ustawienia zostaną wyświetlone następujące właściwości w wyskakującym oknie dialogowym Ustawienia formatu pliku.
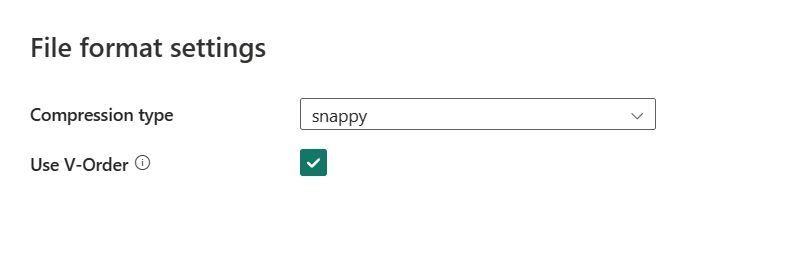
Typ kompresji: wybierz koder-dekoder kompresji używany do zapisywania plików Parquet na liście rozwijanej. Możesz wybrać spośród opcji None, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2), lub lz4hadoop.
Użyj opcji V-Order: włącz optymalizację czasu zapisu w formacie pliku parquet. Aby uzyskać więcej informacji, zobacz Delta Lake table optimization and V-Order (Optymalizacja tabel usługi Delta Lake) i V-Order (Kolejność maszyn wirtualnych). Jest ona domyślnie włączona.
W obszarze Ustawienia zaawansowane na karcie Miejsce docelowe zostaną wyświetlone następujące właściwości powiązane z formatem Parquet.
- Maksymalna liczba wierszy na plik: podczas zapisywania danych w folderze można zapisać w wielu plikach i określić maksymalną liczbę wierszy na plik. Określ maksymalną liczbę wierszy, które mają być zapisywane dla każdego pliku.
- Prefiks nazwy pliku: ma zastosowanie, gdy skonfigurowano maksymalną liczbę wierszy na plik . Określ prefiks nazwy pliku podczas zapisywania danych w wielu plikach, co spowodowało następujący wzorzec:
<fileNamePrefix>_00000.<fileExtension>. Jeśli nie zostanie określony, prefiks nazwy pliku jest generowany automatycznie. Ta właściwość nie ma zastosowania, gdy źródło jest magazynem opartym na plikach lub opcją partycji włączonego magazynu danych.
Podsumowanie tabeli
Parquet jako źródło
Poniższe właściwości są obsługiwane w sekcji Źródło działania kopiowania w przypadku korzystania z formatu Parquet.
| Nazwa/nazwisko | Opis | Wartość | Wymagania | Właściwość skryptu JSON |
|---|---|---|---|---|
| Format pliku | Format pliku, którego chcesz użyć. | Parkiet | Tak | type (w obszarze datasetSettings):Parquet |
| Typ kompresji | Koder koder kompresji używany do odczytywania plików Parquet. | Wybierz jedną z: Brak gzip (.gz) Żwawy lzo Brotli (br) Zstandard lz4 lz4frame bzip2 (bz2) lz4hadoop |
Nie. | compressionCodec: gzip Żwawy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet jako miejsce docelowe
Poniższe właściwości są obsługiwane w sekcji Miejsce docelowe działania kopiowania w przypadku korzystania z formatu Parquet.
| Nazwa/nazwisko | Opis | Wartość | Wymagania | Właściwość skryptu JSON |
|---|---|---|---|---|
| Format pliku | Format pliku, którego chcesz użyć. | Parkiet | Tak | type (w obszarze datasetSettings):Parquet |
| Użyj polecenia V-Order | Optymalizacja czasu zapisu w formacie pliku parquet. | zaznaczone lub niezaznaczone | Nie. | enableVertiParquet |
| Typ kompresji | Koder koder kompresji używany do pisania plików Parquet. | Wybierz jedną z: Brak gzip (.gz) Żwawy lzo Brotli (br) Zstandard lz4 lz4frame bzip2 (bz2) lz4hadoop |
Nie. | compressionCodec: gzip Żwawy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
| Maksymalna liczba wierszy na plik | Podczas zapisywania danych w folderze można zapisać w wielu plikach i określić maksymalną liczbę wierszy na plik. Określ maksymalną liczbę wierszy, które mają być zapisywane dla każdego pliku. | <maksymalna liczba wierszy na plik> | Nie. | maxRowsPerFile |
| Prefiks nazwy pliku | Ma zastosowanie w przypadku skonfigurowania maksymalnej liczby wierszy na plik . Określ prefiks nazwy pliku podczas zapisywania danych w wielu plikach, co spowodowało następujący wzorzec: <fileNamePrefix>_00000.<fileExtension>. Jeśli nie zostanie określony, prefiks nazwy pliku jest generowany automatycznie. Ta właściwość nie ma zastosowania, gdy źródło jest magazynem opartym na plikach lub opcją partycji włączonego magazynu danych. |
<prefiks nazwy pliku> | Nie. | fileNamePrefix |