Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
XML (Extensible Markup Language) to format tekstowy do wymiany danych strukturalnych. W tym artykule opisano sposób konfigurowania formatu XML jako źródła w potoku działania kopiowania w usłudze Data Factory w Microsoft Fabric.
Obsługiwane możliwości
Format XML jest obsługiwany dla następujących działań i łączników jako źródła.
| Kategoria | Łącznik/działanie |
|---|---|
| Obsługiwany łącznik | Amazon S3 |
| Zgodność z usługą Amazon S3 | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| System plików | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Pliki Lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Obsługiwane działanie | Kopiowanie (źródło/-) |
| Działanie Lookup | |
| Działanie GetMetadata | |
| Usuń aktywność |
Format XML w działaniu kopiowania
Aby skonfigurować format XML, wybierz połączenie w źródle działania kopiowania potoku, a następnie wybierz pozycję XML z listy rozwijanej Format pliku. Wybierz pozycję Ustawienia , aby uzyskać dalszą konfigurację tego formatu.
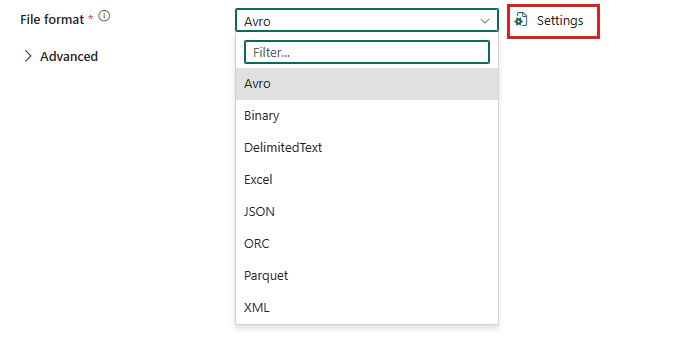
XML jako źródło
Po wybraniu pozycji Ustawienia w sekcji Format pliku w oknie dialogowym Ustawienia formatu pliku zostaną wyświetlone następujące właściwości.
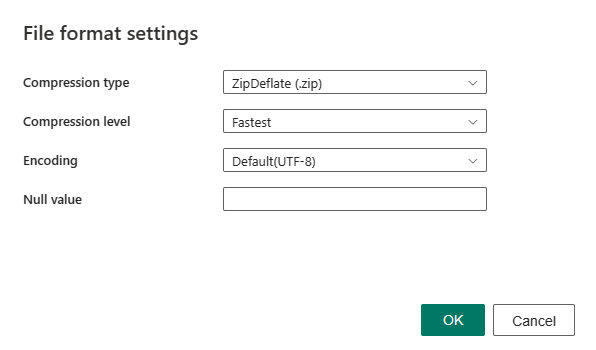
Typ kompresji: koder-dekoder kompresji używany do odczytywania plików XML. Możesz wybrać typ Brak, bzip2, gzip, deflate, ZipDeflate, TarGZip lub tar na liście rozwijanej.
Jeśli wybierzesz ZipDeflate jako typ kompresji, opcja Zachowaj nazwę pliku ZIP jako folder jest wyświetlana w Ustawieniach zaawansowanych na karcie Źródło.
-
Zachowaj nazwę pliku zip jako folder: wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów.
- Jeśli to pole jest zaznaczone (ustawienie domyślne), usługa zapisuje rozpakowane pliki na .
<specified file path>/<folder named as source zip file>/ - Jeśli to pole jest niezaznaczone, usługa zapisuje rozpakowane pliki bezpośrednio do
<specified file path>. Upewnij się, że nie masz zduplikowanych nazw plików w różnych źródłowych plikach zip, aby uniknąć wyścigów ani nieoczekiwanych zachowań.
- Jeśli to pole jest zaznaczone (ustawienie domyślne), usługa zapisuje rozpakowane pliki na .
W przypadku wybrania TarGZip/tar jako typu kompresji, opcja Zachowaj nazwę pliku kompresji jako folder jest wyświetlana w obszarze Ustawienia zaawansowane na karcie Źródło.
-
Zachowaj nazwę pliku kompresji jako folder: wskazuje, czy podczas kopiowania zachować nazwę skompresowanego pliku źródłowego jako strukturę folderów.
- Jeśli to pole jest zaznaczone (ustawienie domyślne), usługa zapisuje dekompresowane pliki do
<specified file path>/<folder named as source compressed file>/. - Jeśli to pole jest niezaznaczone, usługa zapisuje dekompresowane pliki bezpośrednio do
<specified file path>. Upewnij się, że nie masz zduplikowanych nazw plików w różnych plikach źródłowych, aby uniknąć wyścigów ani nieoczekiwanych zachowań.
- Jeśli to pole jest zaznaczone (ustawienie domyślne), usługa zapisuje dekompresowane pliki do
-
Zachowaj nazwę pliku zip jako folder: wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów.
Poziom kompresji: Określ stopień kompresji po wybraniu typu kompresji. Możesz wybrać opcję Najszybsze lub Optymalne.
- Najszybsza: operacja kompresji powinna zostać ukończona tak szybko, jak to możliwe, nawet jeśli wynikowy plik nie jest optymalnie skompresowany.
- Optymalna: operacja kompresji powinna być optymalnie skompresowana, nawet jeśli operacja trwa dłużej. Aby uzyskać więcej informacji, zobacz Temat Poziom kompresji.
Kodowanie: określ typ kodowania używany do odczytywania plików tekstowych. Wybierz jeden typ z listy rozwijanej. Wartość domyślna to UTF-8.
Wartość null: określa ciąg znaków reprezentujący wartość null. Wartość domyślna to pusty ciąg.
W obszarze Ustawienia zaawansowane na karcie Źródło zostaną wyświetlone następujące właściwości powiązane z formatem XML.
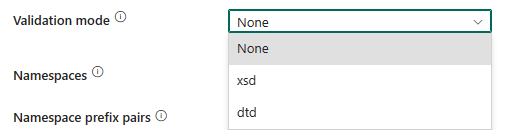
Tryb weryfikacji: określa, czy należy zweryfikować schemat XML. Wybierz jeden tryb z listy rozwijanej.
- Brak: wybierz tę opcję, aby nie używać trybu weryfikacji.
- xsd: wybierz tę opcję, aby zweryfikować schemat XML przy użyciu XSD.
- dtd: wybierz tę opcję, aby zweryfikować schemat XML przy użyciu dtD.
Przestrzeń nazw: określ, czy włączyć przestrzeń nazw podczas analizowania plików XML. Jest ona domyślnie zaznaczona.
Pary prefiksów przestrzeni nazw: Jeśli przestrzenie nazw są aktywowane, wybierz opcję + Nowy i określ adres URL oraz prefiks. Możesz dodać więcej par, wybierając pozycję + Nowy.
Identyfikator URI przestrzeni nazw do mapowania prefiksu służy do nazywania pól podczas analizowania pliku XML. Jeśli plik XML ma przestrzeń nazw, a przestrzeń nazw jest domyślnie włączona, nazwa pola jest taka sama jak w dokumencie XML. Jeśli w tej mapie istnieje element zdefiniowany dla identyfikatora URI przestrzeni nazw, to nazwa pola toprefix:fieldName.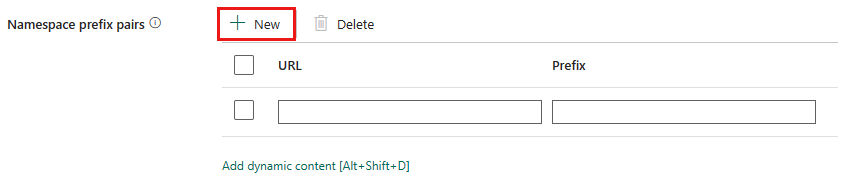
Wykrywanie typu danych: określ, czy mają być wykrywane typy danych liczb całkowitych, podwójnych i logicznych. Jest ona domyślnie zaznaczona.
Właściwości działania kopiowania XML
XML jako źródło
Poniższe właściwości są obsługiwane w sekcji Źródło zadania kopiowania podczas użycia formatu XML.
| Nazwa | Opis | Wartość | Wymagane | Właściwość skryptu JSON |
|---|---|---|---|---|
| Format pliku | Format pliku, którego chcesz użyć. | XML | Tak | type (w obszarze datasetSettings):XML |
| Typ kompresji | Kodek kompresji używany do odczytywania plików XML. |
Brak bzip2 gzip Deflate ZipDeflate TarGZip tar |
Nie. | wpisz (w obszarze compression): bzip2 gzip Deflate ZipDeflate TarGZip smoła |
| Poziom kompresji | Współczynnik kompresji. |
Najszybszy Optymalny |
Nie | poziom (w obszarze compression): Najszybszy Optymalny |
| Kodowanie | Typ kodowania używany do odczytywania plików tekstowych. | "UTF-8" (domyślnie),"UTF-8 bez BOM", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Nie | encodingName |
| Zachowaj nazwę pliku zip jako folder | Wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów. | Wybrane (domyślne) lub usuń zaznaczenie | Nie. | zachowajNazwęPlikuZipJakoFolder (w obszarze compressionProperties->type jako ZipDeflateReadSettings):true (wartość domyślna) lub fałsz |
| Zachowaj nazwę pliku kompresji jako folder | Wskazuje, czy podczas kopiowania zachować nazwę skompresowanego pliku źródłowego jako strukturę folderów. | Wybrane (domyślne) lub usuń zaznaczenie | Nie. | zachowajNazwęPlikuKompresjiJakoFolder (w obszarze compressionProperties->type jako TarGZipReadSettings lub TarReadSettings):true (wartość domyślna) lub fałsz |
| Wartość null | Ciąg reprezentujący wartość null. |
<Twoja wartość null> pusty ciąg (domyślnie) |
Nie | wartość null |
| Tryb weryfikacji | Czy należy zweryfikować schemat XML. |
Brak xsd Dtd |
Nie. | validationMode: xsd Dtd |
| Przestrzenie nazw | Czy włączyć przestrzeń nazw podczas analizowania plików XML. | Wybrane (domyślne) lub niezaznaczone | Nie. | przestrzenie nazw: true (wartość domyślna) lub fałsz |
| Pary prefiksów namespace | URI przestrzeni nazw do mapowania prefiksu, który służy do oznaczania pól nazewnictwem podczas analizowania pliku XML. Jeśli plik XML ma przestrzeń nazw, a przestrzeń nazw jest domyślnie włączona, nazwa pola jest taka sama jak w dokumencie XML. Jeśli w tej mapie istnieje element zdefiniowany dla identyfikatora URI przestrzeni nazw, to nazwa pola to prefix:fieldName. |
< url >:< prefiks > | Nie. | prefiksy przestrzeni nazw < url >:< prefiks > |
| Wykrywanie typu danych | Czy wykrywać typy danych liczb całkowitych, zmiennoprzecinkowych i logicznych. | Wybrane (domyślne) lub niezaznaczone | Nie. | detectDataType: true (wartość domyślna) lub fałsz |