Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Z tego przewodnika szybkiego startu dowiesz się, jak przepływy danych i potoki współpracują, aby utworzyć potężne rozwiązanie Data Factory. Dane zostaną oczyszczone za pomocą przepływów danych i przeniesione za pomocą potoków.
Warunki wstępne
Przed rozpoczęciem potrzebne są następujące elementy:
- Konto najemcy z aktywną subskrypcją. Utwórz bezpłatne konto.
- Obszar roboczy z włączoną usługą Microsoft Fabric: skonfiguruj obszar roboczy , który nie jest domyślnym obszarem Mój obszar roboczy.
- Baza danych Azure SQL Database z danymi tabeli.
- konto usługi Blob Storage.
Porównanie przepływów danych i potoków
Przepływ danych Gen2 udostępnia interfejs o niskim kodzie z 300+ danymi i przekształceniami opartymi na sztucznej inteligencji. Dzięki elastyczności można łatwo czyścić, przygotowywać i przekształcać dane. Pipeliny oferują zaawansowane możliwości orkiestracji danych, umożliwiające tworzenie elastycznych przepływów danych spełniające potrzeby Twojego przedsiębiorstwa.
W potoku można tworzyć logiczne grupowania działań, które wykonują zadanie. Może to obejmować wywołanie przepływu danych w celu oczyszczenia i przygotowania danych. Chociaż istnieją pewne funkcje, które się pokrywają, wybór zależy od tego, czy potrzebujesz pełnych możliwości potoków, czy też można korzystać z prostszych możliwości przepływów danych. Aby uzyskać więcej informacji, zobacz Przewodnik po decyzjach dotyczących Fabric.
Przekształcanie danych za pomocą przepływów danych
Wykonaj następujące kroki, aby skonfigurować przepływ danych.
Utwórz przepływ danych
Wybierz obszar roboczy z funkcją Fabric, a następnie Nowy i wybierz Przepływ danych Gen2.
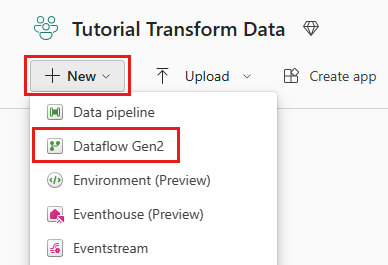
W edytorze przepływu danych wybierz pozycję Importuj z programu SQL Server.
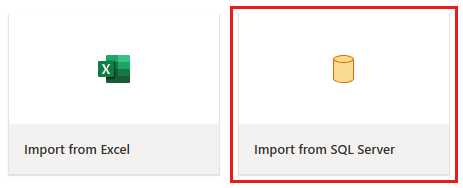


Pobierz dane
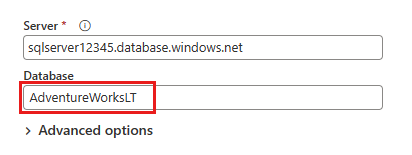
W oknie dialogowym Łączenie ze źródłem danych wprowadź szczegóły bazy danych Azure SQL Database i wybierz pozycję Dalej. Użyj przykładowej bazy danych AdventureWorksLT z wymagań wstępnych.
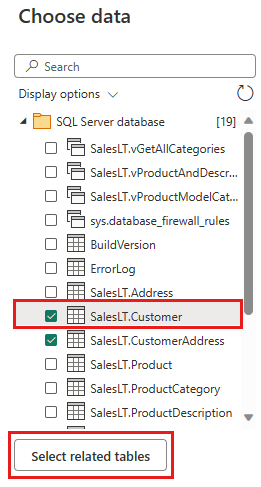
Wybierz dane do przekształcenia, takie jak SalesLT.Customer, i użyj pozycji Wybierz powiązane tabele , aby uwzględnić powiązane tabele. Następnie wybierz Utwórz.


Przekształcanie danych
Wybierz pozycję Widok diagramu z paska stanu lub menu Widok w edytorze Power Query.
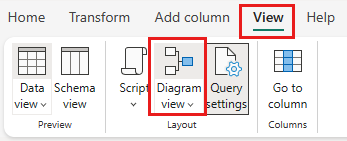
Wybierz prawym przyciskiem myszy zapytanie SalesLT Customer lub wybierz wielokropek pionowy po prawej stronie zapytania, a następnie wybierz pozycję Scal zapytania.
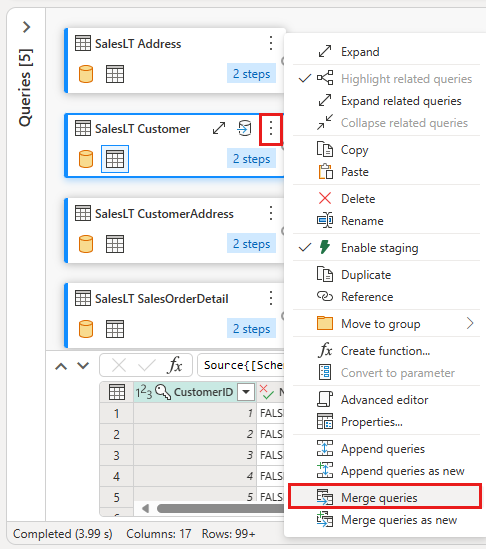
Skonfiguruj scalanie z SalesLTOrderHeader jako prawą tabelą, CustomerID jako kolumną sprzężenia i lewe zewnętrzne sprzężenie jako typem sprzężenia. Kliknij przycisk OK.
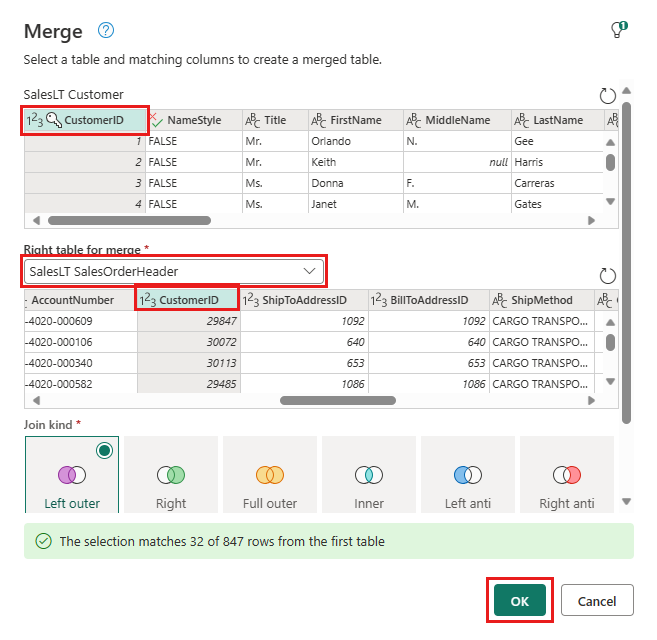
Dodaj miejsce docelowe danych, wybierając symbol bazy danych ze strzałką. Wybierz pozycję Azure SQL Database jako typ docelowy.
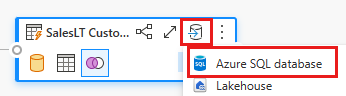
Podaj szczegóły połączenia usługi Azure SQL Database, w którym ma zostać opublikowane zapytanie scalania. W tym przykładzie używamy bazy danych AdventureWorksLT , która również była źródłem danych dla miejsca docelowego.
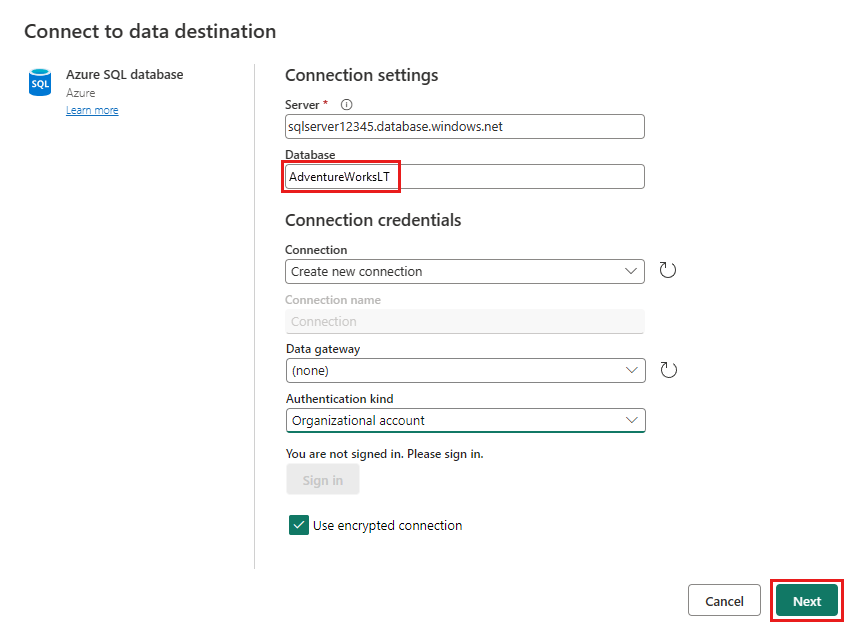
Wybierz bazę danych do przechowywania danych i podaj nazwę tabeli, a następnie wybierz pozycję Dalej.
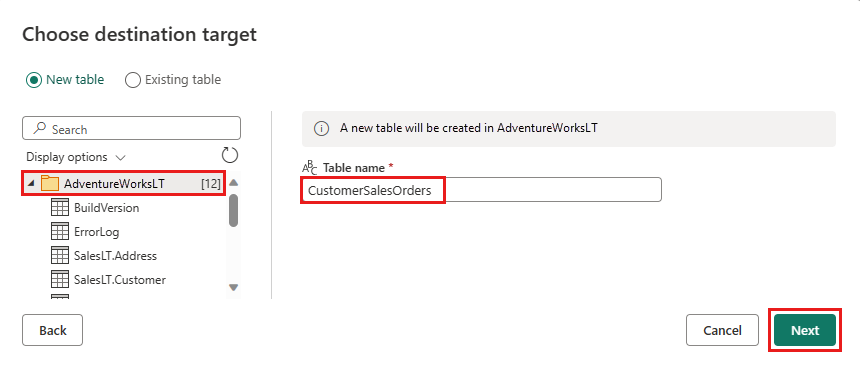
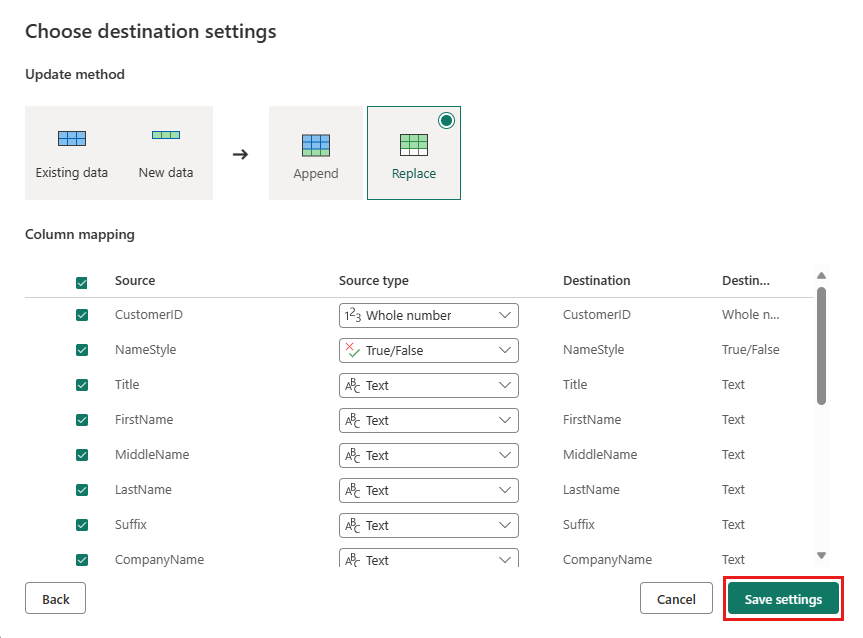
Zaakceptuj ustawienia domyślne w oknie dialogowym Wybieranie ustawień docelowych i wybierz pozycję Zapisz ustawienia.
Wybierz pozycję Publikuj w edytorze przepływu danych, aby opublikować przepływ danych.



Przenoszenie danych za pomocą potoków
Po utworzeniu przepływu danych Gen2, możesz nim operować w potoku. W tym przykładzie skopiujesz dane wygenerowane z przepływu danych do formatu tekstowego na koncie usługi Azure Blob Storage.
Tworzenie nowego potoku
W obszarze roboczym wybierz Nowy, a następnie Potok.
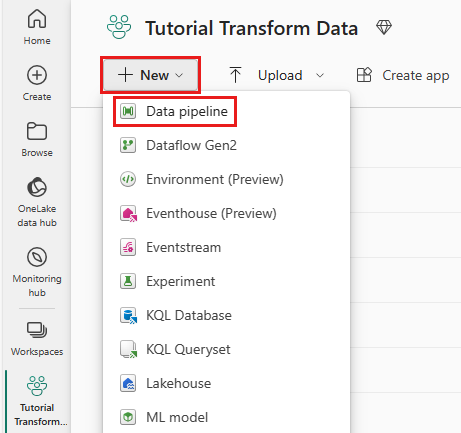
Nadaj potokowi nazwę i wybierz pozycję Utwórz.
Konfigurowanie przepływu danych
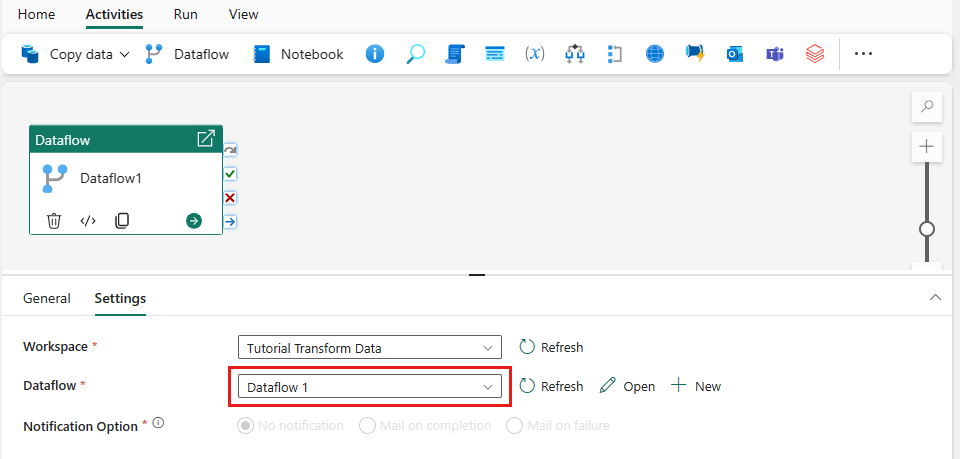
Dodaj działanie przepływu danych do potoku, wybierając Przepływ danych na karcie Działania.

Wybierz przepływ danych na kanwie potoku, przejdź do karty Ustawienia i wybierz utworzony wcześniej przepływ danych.
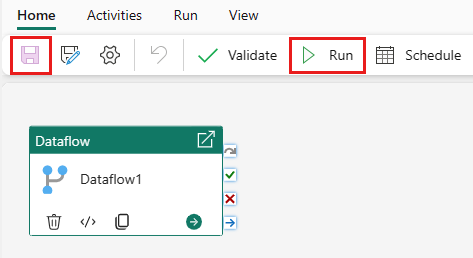
Wybierz pozycję Zapisz, a następnie uruchom , aby wypełnić scaloną tabelę zapytań.
Dodawanie działania kopiowania
Wybierz pozycję Kopiuj dane na kanwie lub użyj Asystenta kopiowania na karcie Działania .
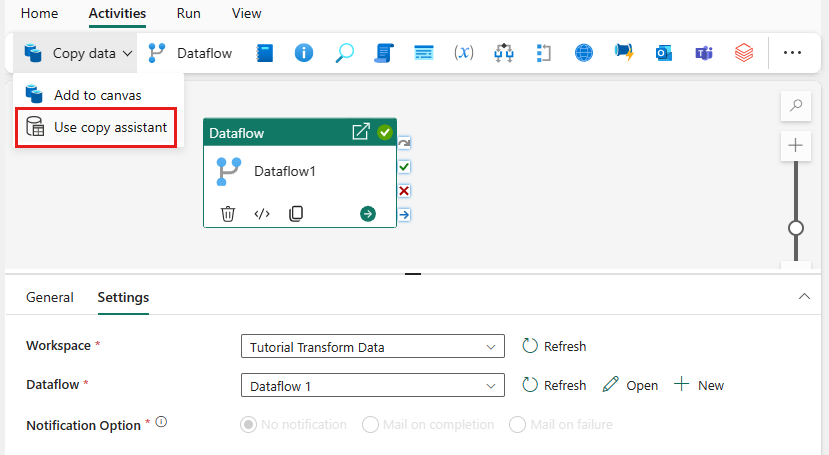
Wybierz pozycję Azure SQL Database jako źródło danych, a następnie wybierz pozycję Dalej.
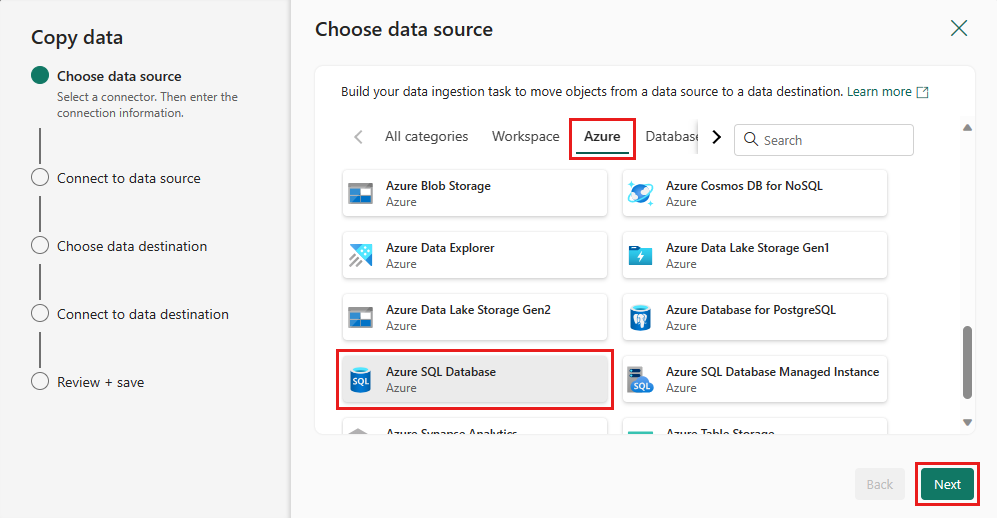
Utwórz połączenie ze źródłem danych, wybierając pozycję Utwórz nowe połączenie. Wypełnij wymagane informacje o połączeniu na panelu, a następnie wprowadź nazwę AdventureWorksLT jako nazwę bazy danych, w której wygenerowaliśmy zapytanie scalania w przepływie danych. Następnie wybierz pozycję Dalej.
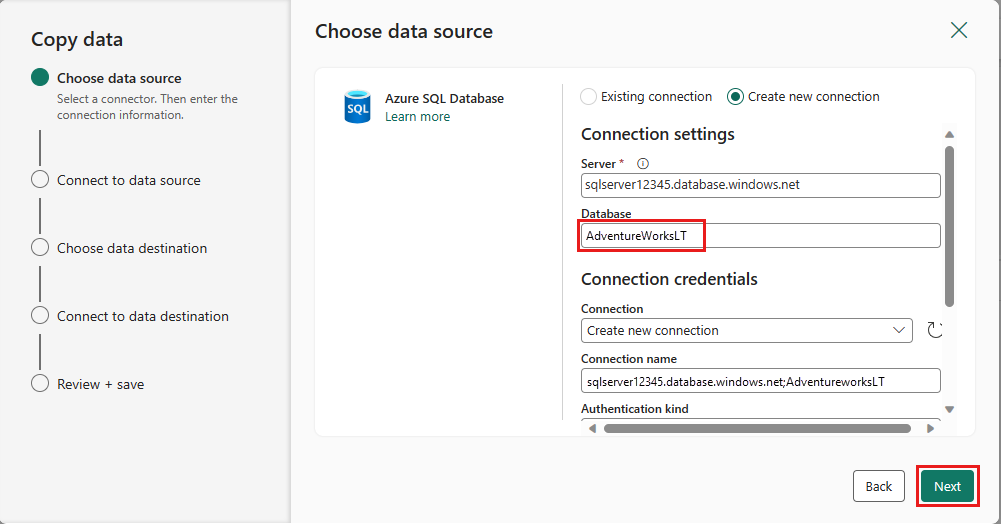
Wybierz tabelę wygenerowaną wcześniej w kroku przepływu danych, a następnie wybierz pozycję Dalej.
Jako miejsce docelowe wybierz Azure Blob Storage, a następnie Dalej.
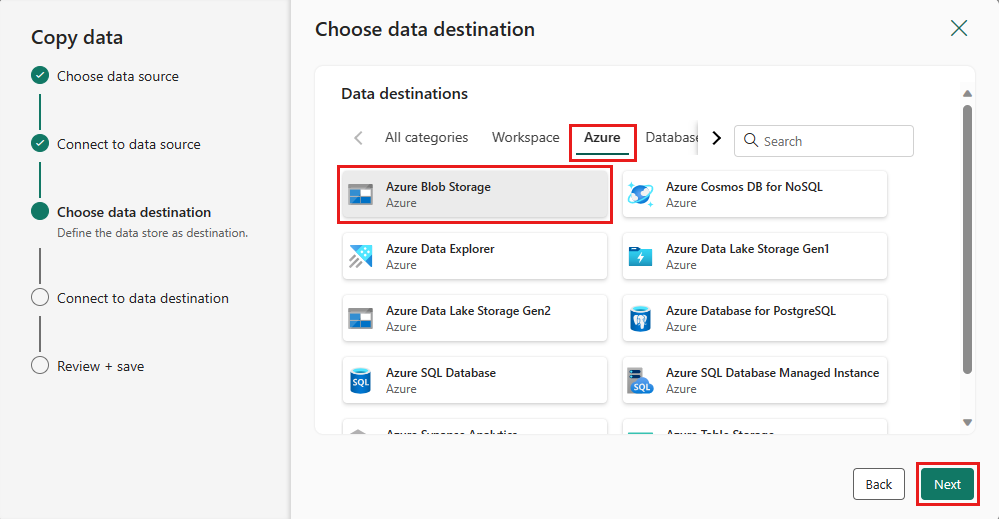
Utwórz połączenie z miejscem docelowym, wybierając pozycję Utwórz nowe połączenie. Podaj szczegóły połączenia, a następnie wybierz pozycję Dalej.
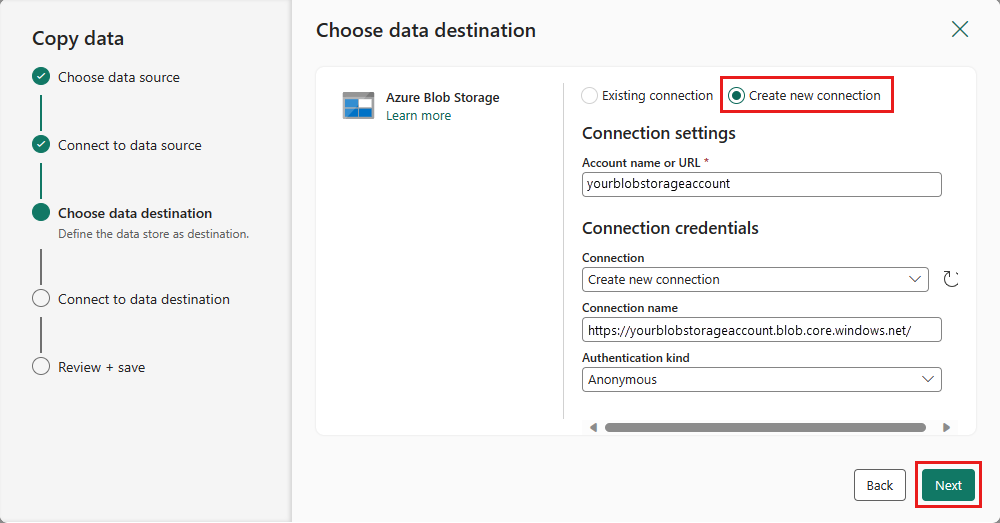
Wybierz ścieżkę folderu i podaj nazwę pliku , a następnie wybierz pozycję Dalej.
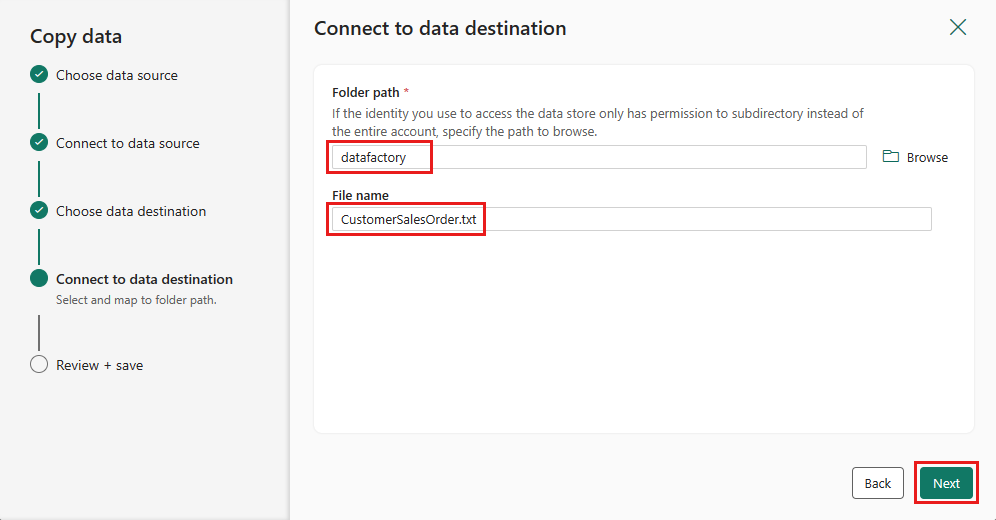
Ponownie wybierz przycisk Dalej , aby zaakceptować domyślny format pliku, ogranicznik kolumny, ogranicznik wierszy i typ kompresji, opcjonalnie w tym nagłówek.
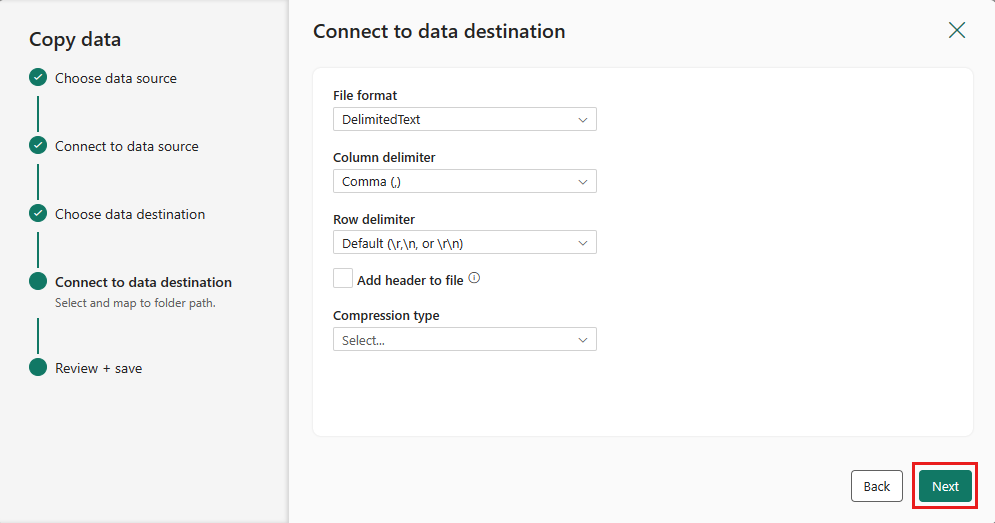
Finalizuj ustawienia. Następnie przejrzyj i wybierz pozycję Zapisz i uruchom, aby zakończyć proces.
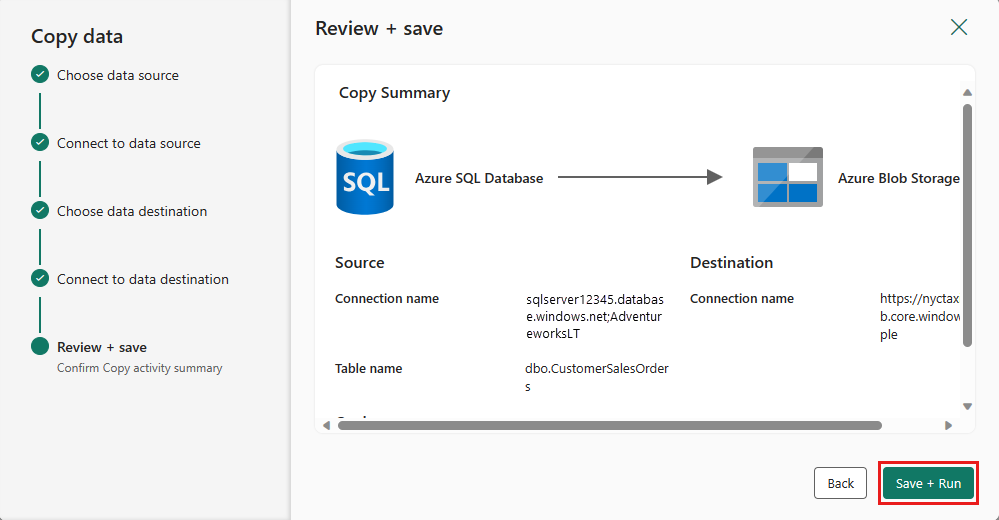
Zaprojektuj swój potok i zapisz, aby uruchomić i załadować dane.
Aby uruchomić działanie kopiowania po działaniu Przepływ danych, przeciągnij z fragmentu Powodzenie na działanie kopiowania w działaniu Przepływ danych. Działanie Kopiowanie jest uruchamiane tylko po pomyślnym zakończeniu działania Przepływ danych.

Wybierz Zapisz, aby zapisać potok. Następnie wybierz pozycję Uruchom, aby uruchomić pipeline i załadować dane.
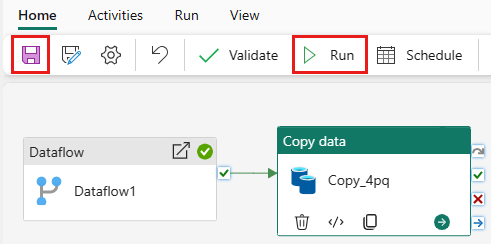
Harmonogram wykonywania potoku
Po zakończeniu tworzenia i testowania potoku możesz zaplanować jego automatyczne uruchamianie.
Na karcie Narzędzia główne okna edytora potoków wybierz pozycję Harmonogram.
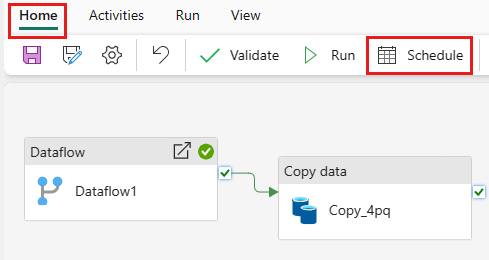
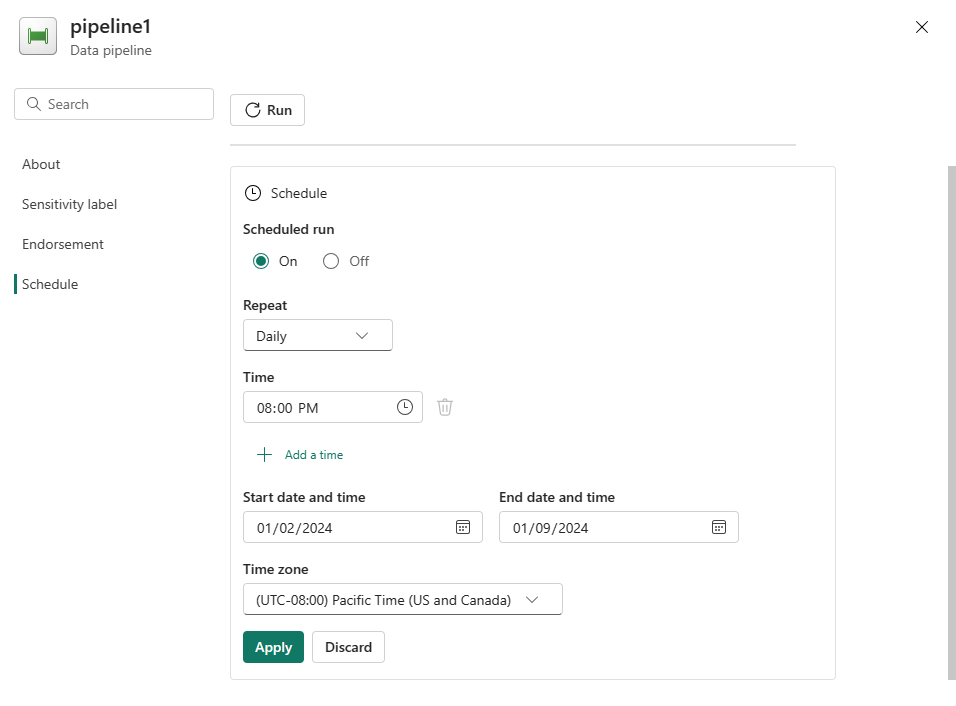
Skonfiguruj harmonogram zgodnie z wymaganiami. W tym przykładzie zaplanowano uruchamianie potoku codziennie o godzinie 18:00 do końca roku.
Powiązana zawartość
W tym przykładzie pokazano, jak utworzyć i skonfigurować przepływ danych Gen2 w celu utworzenia zapytania scalania i zapisania go w bazie danych Azure SQL Database, a następnie skopiować dane z bazy danych do pliku tekstowego w usłudze Azure Blob Storage. Wiesz już, jak wykonać następujące działania:
- Tworzenie przepływu danych.
- Przekształcanie danych za pomocą przepływu danych.
- Stwórz pipeline przy użyciu przepływu danych.
- Zleć wykonywanie kroków w potoku.
- Kopiowanie danych za pomocą Asystenta kopiowania.
- Uruchom i zaplanuj swój rurociąg.
Następnie kontynuuj, aby dowiedzieć się więcej na temat monitorowania przebiegów potoku.