Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Z tego artykułu dowiesz się, jak wykonywać eksploracyjne analizy danych przy użyciu zestawów danych Platformy Azure Open i platformy Apache Spark. W tym artykule przedstawiono analizę zestawu danych taksówek w Nowym Jorku. Dane są dostępne za pośrednictwem usługi Azure Open Datasets. Ten podzestaw zestawu danych zawiera informacje o żółtych przejazdach taksówkami: informacje o każdej podróży, godzinie rozpoczęcia i zakończenia oraz lokalizacjach, kosztach i innych interesujących atrybutach.
W tym artykule opisano następujące zagadnienia:
- Pobieranie i przygotowywanie danych
- Analizowanie danych
- Wizualizowanie danych
Wymagania wstępne
Uzyskaj subskrypcję usługi Microsoft Fabric. Możesz też utworzyć konto bezpłatnej wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Przełącz się na Fabric, używając przełącznika nawigacji w lewej dolnej części strony głównej.

Pobieranie i przygotowywanie danych
Aby rozpocząć, pobierz zestaw danych New York City (NYC) Taxi i przygotuj dane.
Utwórz notes przy użyciu narzędzia PySpark. Aby uzyskać instrukcje, zobacz Tworzenie notesu.
Uwaga
Ze względu na jądro PySpark nie trzeba jawnie tworzyć żadnych kontekstów. Kontekst platformy Spark jest automatycznie tworzony podczas uruchamiania pierwszej komórki kodu.
W tym artykule użyjesz kilku różnych bibliotek, aby ułatwić wizualizowanie zestawu danych. Aby wykonać tę analizę, zaimportuj następujące biblioteki:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdPonieważ dane pierwotne są w formacie Parquet, możesz użyć kontekstu platformy Spark, aby bezpośrednio ściągnąć plik do pamięci jako ramkę danych. Użyj interfejsu API Otwórz zestawy danych, aby pobrać dane i utworzyć ramkę danych platformy Spark. Aby wywnioskować typy danych i schemat, użyj schematu ramki danych Spark we właściwościach odczytu .
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Po odczytaniu danych wykonaj wstępne filtrowanie, aby wyczyścić zestaw danych. Możesz usunąć niepotrzebne kolumny i dodać kolumny, które wyodrębnią ważne informacje. Ponadto można odfiltrować anomalie w zestawie danych.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analizowanie danych
Jako analityk danych masz szeroką gamę narzędzi, które ułatwiają wyodrębnianie szczegółowych informacji z danych. W tej części artykułu dowiesz się więcej o kilku przydatnych narzędziach dostępnych w notesach usługi Microsoft Fabric. W tej analizie chcesz zrozumieć czynniki, które dają wyższe porady dotyczące taksówek dla wybranego okresu.
Apache Spark SQL Magic
Najpierw wykonaj eksploracyjne analizy danych przy użyciu języka Apache Spark SQL i poleceń magic z notesem usługi Microsoft Fabric. Po wykonaniu zapytania zwizualizuj wyniki przy użyciu wbudowanej chart options funkcji.
W notesie utwórz nową komórkę i skopiuj następujący kod. Korzystając z tego zapytania, możesz zrozumieć, jak zmieniają się średnie kwoty porad w wybranym okresie. To zapytanie pomaga również zidentyfikować inne przydatne szczegółowe informacje, w tym minimalną/maksymalną kwotę porad dziennie i średnią kwotę taryfy.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCPo zakończeniu działania zapytania możesz zwizualizować wyniki, przełączając się do widoku wykresu. W tym przykładzie tworzony jest wykres liniowy, określając
day_of_monthpole jako klucz iavgTipAmountjako wartość. Po wybraniu zaznaczenia wybierz pozycję Zastosuj , aby odświeżyć wykres.
Wizualizowanie danych
Oprócz wbudowanych opcji tworzenia wykresów notesów można tworzyć własne wizualizacje przy użyciu popularnych bibliotek typu open source. W poniższych przykładach użyj bibliotek Seaborn i Matplotlib, które są często używane biblioteki języka Python do wizualizacji danych.
Aby ułatwić tworzenie i obniżanie kosztów tworzenia, należy obniżyć poziom próbkowania zestawu danych. Użyj wbudowanej funkcji próbkowania platformy Apache Spark. Ponadto zarówno biblioteki Seaborn, jak i Matplotlib wymagają tablicy Pandas DataFrame lub NumPy. Aby uzyskać ramkę danych biblioteki Pandas, użyj
toPandas()polecenia , aby przekonwertować ramkę danych.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Możesz zrozumieć dystrybucję porad w zestawie danych. Użyj biblioteki Matplotlib, aby utworzyć histogram pokazujący rozkład ilości i liczby porad. Na podstawie rozkładu można zobaczyć, że wskazówki są niesymetryczne w stosunku do kwot mniejszych lub równych 10 USD.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()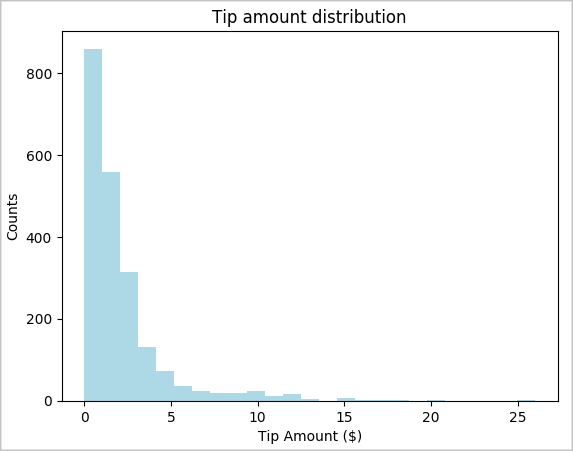
Następnie spróbuj zrozumieć relację między poradami dotyczącymi danej podróży a dniem tygodnia. Użyj platformy Seaborn, aby utworzyć wykres skrzynkowy, który podsumowuje trendy dla każdego dnia tygodnia.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()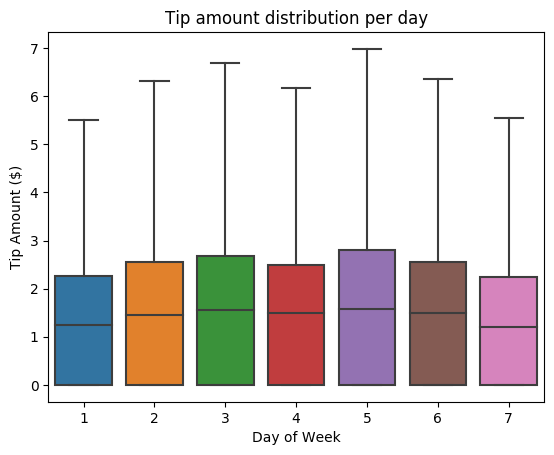
Inną hipotezą może być to, że istnieje pozytywny związek między liczbą pasażerów a całkowitą kwotą porad taksówki. Aby zweryfikować tę relację, uruchom następujący kod, aby wygenerować wykres skrzynkowy ilustrujący rozkład wskazówek dla każdej liczby pasażerów.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()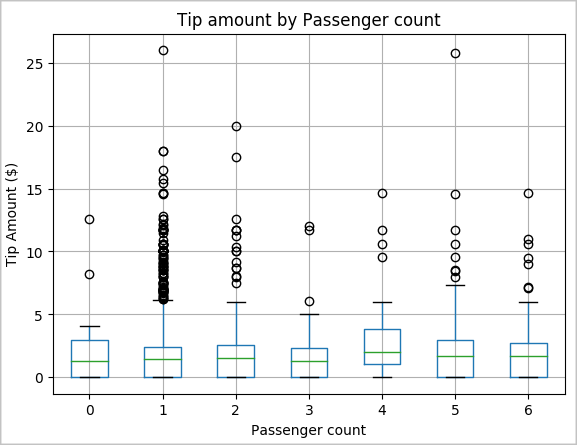
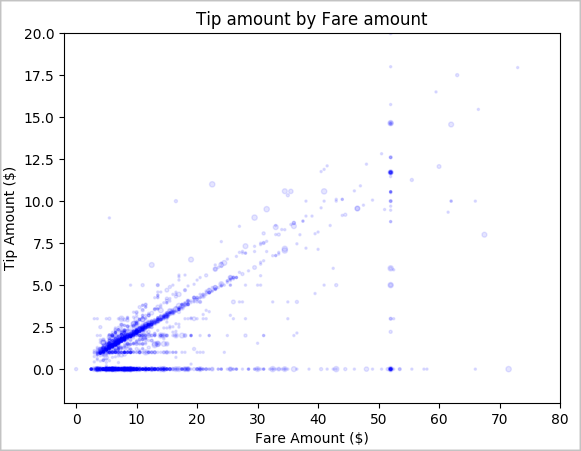
Na koniec zapoznaj się z relacją między kwotą taryfy a kwotą porad. Na podstawie wyników widać, że istnieje kilka obserwacji, w których ludzie nie przechylają się. Jednak istnieje pozytywna relacja między ogólną taryfą a kwotami porad.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()