Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku przedstawiono sposób interakcji z usługą Power BI z notesu Jupyter i wykrywania relacji między tabelami za pomocą biblioteki SemPy.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
- Discover relationships in a semantic model (Power BI dataset), using semantic link's Python library (SemPy).
- Użyj składników biblioteki SemPy, które obsługują integrację z usługą Power BI i pomagają zautomatyzować analizę jakości danych. Te składniki obejmują:
- FabricDataFrame — struktura podobna do struktury pandas, rozszerzona o dodatkowe informacje semantyczne.
- Funkcje służące do ściągania modeli semantycznych z obszaru roboczego usługi Fabric do notesu.
- Funkcje automatyzujące ocenę hipotez dotyczących zależności funkcjonalnych i identyfikujące naruszenia relacji w modelach semantycznych.
Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Sign in to Microsoft Fabric.
Use the experience switcher on the bottom left side of your home page to switch to Fabric.

Wybierz pozycję Obszary robocze w okienku nawigacji po lewej stronie, aby znaleźć i wybrać obszar roboczy. Ten obszar roboczy staje się twoim aktualnym obszarem roboczym.
Download the Customer Profitability Sample.pbix and Customer Profitability Sample (auto).pbix semantic models from the fabric-samples GitHub repository and upload them to your workspace.
Follow along in the notebook
The powerbi_relationships_tutorial.ipynb notebook accompanies this tutorial.
Aby otworzyć towarzyszący temu samouczkowi notatnik, postępuj zgodnie z instrukcjami w Prepare your system for data science tutorials, aby zaimportować notatnik do swojego obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Be sure to attach a lakehouse to the notebook before you start running code.
Set up the notebook
W tej sekcji skonfigurujesz środowisko notesu z niezbędnymi modułami i danymi.
Install
SemPyfrom PyPI using the%pipin-line installation capability within the notebook:%pip install semantic-linkWykonaj niezbędne importy modułów SemPy, które będą potrzebne później:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsZaimportuj bibliotekę pandas do wymuszania opcji konfiguracji, która ułatwia formatowanie danych wyjściowych:
import pandas as pd pd.set_option('display.max_colwidth', None)
Eksplorowanie modeli semantycznych
This tutorial uses a standard sample semantic model Customer Profitability Sample.pbix. Aby zapoznać się z opisem modelu semantycznego, zobacz Przykład Customer Profitability dla usługi Power BI.
Użyj funkcji
list_datasetsSemPy, aby eksplorować modele semantyczne w bieżącym obszarze roboczym:fabric.list_datasets()
For the rest of this notebook you use two versions of the Customer Profitability Sample semantic model:
- Customer Profitability Sample: the semantic model as it comes from Power BI samples with predefined table relationships
- Przykład Rentowności Klienta (automatyczny): te same dane, ale relacje są ograniczone do tych, które Power BI wykrywa za pomocą autodetekcji.
Wyodrębnij model semantyczny przykładowy wraz z jego wstępnie zdefiniowanym modelem semantycznym
Załaduj relacje, które są wstępnie zdefiniowane i przechowywane w modelu semantycznym Customer Profitability Sample przy użyciu funkcji
list_relationshipsSemPy. Ta funkcja wyświetla listę z tabelarycznego modelu obiektów:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsWizualizowanie ramki danych
relationshipsjako grafu przy użyciu funkcjiplot_relationship_metadataSemPy:plot_relationship_metadata(relationships)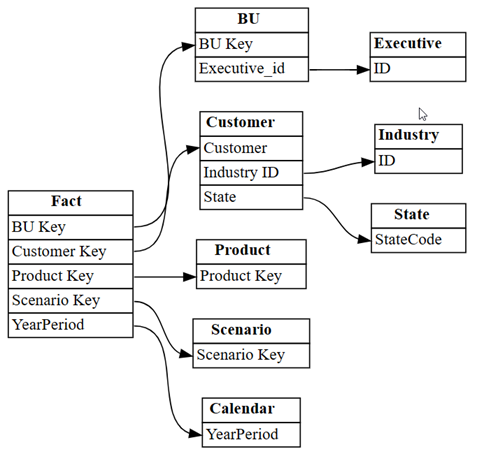

Ten wykres przedstawia "podstawy prawdy" dla relacji między tabelami w tym modelu semantycznym, ponieważ odzwierciedla sposób ich definiowania w usłudze Power BI przez eksperta w tej dziedzinie.
Odkrywanie relacji komplementarnych
Jeśli zaczniesz od relacji automatycznie wykrywanych przez usługę Power BI, masz mniejszy zestaw.
Wizualizuj relacje automatycznie wykrywane przez usługę Power BI w modelu semantycznym:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)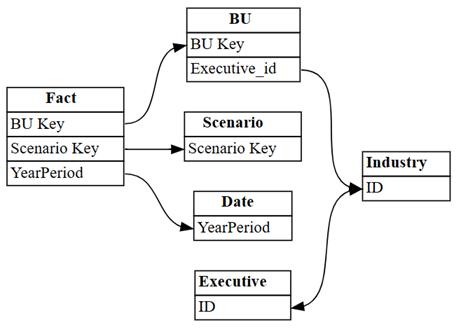
Power BI's autodetection missed many relationships. Co więcej, dwie relacje automatycznie wykrywane są semantycznie niepoprawne:
-
Executive[ID]—>Industry[ID] -
BU[Executive_id]—>Industry[ID]
-
Wydrukuj relacje jako tabelę:
autodetectedNiepoprawne relacje z tabelą
Industrysą wyświetlane w wierszach z indeksem 3 i 4. Użyj tych informacji, aby usunąć te wiersze.Odrzuć nieprawidłowo zidentyfikowane relacje.
autodetected.drop(index=[3,4], inplace=True) autodetectedTeraz masz poprawne, ale niekompletne relacje.
Zwizualizuj te niekompletne relacje przy użyciu
plot_relationship_metadata:plot_relationship_metadata(autodetected)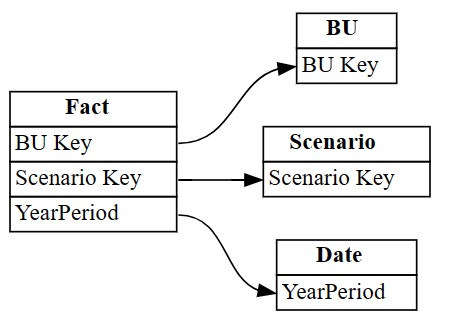
Załaduj wszystkie tabele z modelu semantycznego przy użyciu funkcji
list_tablesiread_tableSemPy:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Znajdź relacje między tabelami przy użyciu
find_relationshipsi przejrzyj dane wyjściowe dziennika, aby uzyskać szczegółowe informacje na temat działania tej funkcji:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Wizualizowanie nowo odnalezionych relacji:
plot_relationship_metadata(suggested_relationships_all)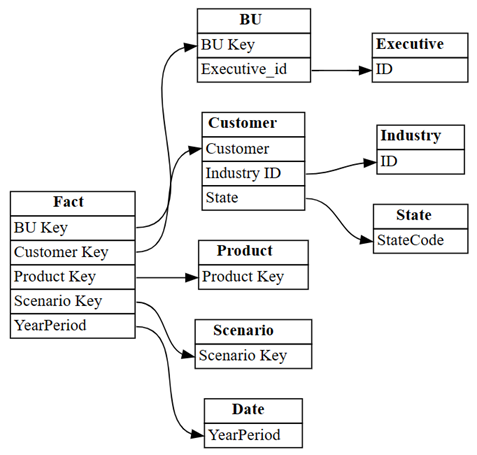
Oprogramowanie SemPy było w stanie wykryć wszystkie relacje.
Użyj parametru
exclude, aby ograniczyć wyszukiwanie do dodatkowych relacji, które nie zostały wcześniej zidentyfikowane:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Weryfikowanie relacji
Najpierw załaduj dane z modelu semantycznego Customer Profitability Sample:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Sprawdź nakładanie się wartości klucza podstawowego i obcego przy użyciu funkcji
list_relationship_violations. Podaj dane wyjściowe funkcjilist_relationshipsjako dane wejściowe dolist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Naruszenia związków dostarczają kilku interesujących wniosków. Na przykład jedna z siedmiu wartości w
Fact[Product Key]jest nieobecna wProduct[Product Key], a brakujący klucz to50.
Eksploracyjna analiza danych to ekscytujący proces, a także czyszczenie danych. Zawsze jest coś, co ukrywa dane, w zależności od tego, jak patrzysz na to, co chcesz zapytać itd. Link semantyczny dostarcza nowe narzędzia, które można użyć, aby osiągnąć więcej dzięki swoim danym.
Powiązana zawartość
Zapoznaj się z innymi samouczkami dotyczącymi linku semantycznego /SemPy:
- samouczek : czyszczenie danych z zależnościami funkcjonalnymi
- Samouczek: analizowanie zależności funkcjonalnych w przykładowym modelu semantycznym
- Samouczek : wyodrębnianie i obliczanie miar Power BI z notebooka Jupyter
- Tutorial: Discover relationships in the Synthea dataset, using semantic link
- Tutorial: Validate data using SemPy and Great Expectations (GX)