Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:✅ Magazyn w systemie Microsoft Fabric
W tym artykule przedstawiono funkcje i innowacje w architekturze usługi Fabric Data Warehouse, które zwiększają wydajność, skalowalność i efektywność kosztową.
Magazyn danych Fabric działa w architekturze gotowej na przyszłość w konwergentnej platformie danych. Dzięki otwartemu formatowi magazynowania Delta i integracji z usługą OneLake, dane w usłudze Fabric Data Warehouse są gotowe do analizy.
Architektura wysokiego poziomu

Magazyn danych Fabric jest przeznaczony do analizy na dużą skalę przy użyciu następujących bloków konstrukcyjnych:
| Blok konstrukcyjny | Opis |
|---|---|
| Ujednolicony optymalizator zapytań | Generuje optymalny plan wykonywania dla rozproszonych środowisk w chmurze, niezależnie od jakości zapytań SQL utworzonych przez użytkownika. |
| Przetwarzanie zapytań rozproszonych | Obsługuje równoległe wykonywanie zapytań na dużą skalę z szybko skalującą się infrastrukturą chmurową, natychmiast dostarczając potrzebne zasoby obliczeniowe do obsługi zapytań. Oddzielne obciążenia SELECT i DML używają odrębnych pul do wydajnego i izolowanego wykonywania. |
| Aparat wykonywania zapytań | Aparat oparty na języku SQL do wykonywania zapytań analitycznych na dużej ilości danych z szybką wydajnością i wysoką współbieżnością. |
| Zarządzanie metadanymi i transakcjami | Metadane znajdują się w frontendzie, backendzie oraz w lokalnej pamięci podręcznej SSD i zdalnym magazynie OneLake. Obsługuje współbieżne transakcje i zapewnia zgodność ACID. |
| Przechowywanie w OneLake | Tabele ze strukturą dziennika zaimplementowane przy użyciu otwartego formatu tabeli delta, modelu typu lakehouse z bezpiecznym otwartym magazynem. |
| Platforma fabric | Platforma sieci szkieletowej zapewnia ujednolicony model uwierzytelniania i zabezpieczeń, monitorowanie i inspekcję. Magazyn danych Fabric jest automatycznie dostępny dla innych usług platformy Fabric, aby zaspokoić potrzeby biznesowe, w tym Power BI, potoki danych w Data Factory, Real-Time Intelligence i nie tylko. |
Aparat ujednoliconego optymalizatora zapytań
Ujednolicony optymalizator zapytań w usłudze Fabric Data Warehouse to silnik, który decyduje o najmądrzejszy sposób uruchamiania zapytań SQL.
Podczas przesyłania zapytania ujednolicony optymalizator zapytań analizuje możliwe sposoby jego wykonania: jak łączyć tabele, gdzie przenosić dane i jak używać zasobów, takich jak procesor CPU, pamięć i sieć. Ujednolicony optymalizator zapytań nie wybiera tylko pierwszej opcji, wybiera najbardziej optymalny plan w czasie dozwolonym przez ocenę kosztów dla tych czynników oraz dostępnych metadanych i statystyk.
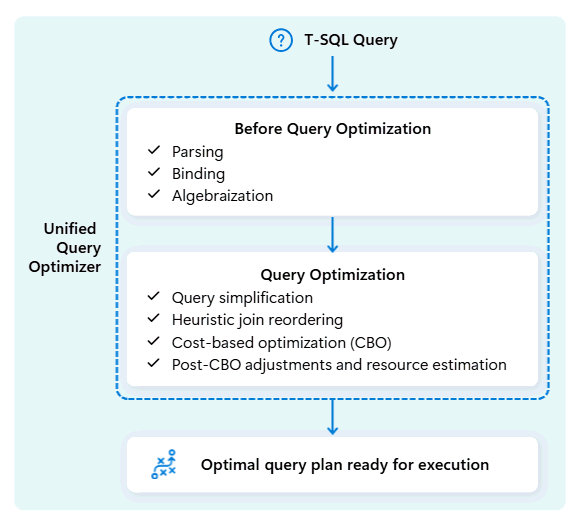
Podczas optymalizowania planu wykonywania zapytania ujednolicony optymalizator zapytań uwzględnia wszystko w jednym miejscu: kształt zapytania, rozkład danych tabel i koszt przenoszenia danych w porównaniu z przetwarzaniem lokalnym. Ujednolicony optymalizator zapytań może dokonywać inteligentnych kompromisów, takich jak decyzja, czy bardziej opłacalne jest rozsyłanie małej tabeli, czy tasowanie dużej. Oznacza to mniej niepotrzebnych przetasowania danych, lepsze wykorzystanie zasobów obliczeniowych i szybszą wydajność, nawet w przypadku złożonych lub słabo napisanych zapytań T-SQL.
Spójna wydajność nie wymaga, aby deweloperzy poświęcali czas na ręczne dostrajanie zapytań T-SQL. Na przykład nie trzeba ręcznie określać najlepszej JOIN kolejności zapytań. Jeśli twoje zapytanie SQL najpierw wymienia dużą tabelę, a następnie mniejszą, bardzo selektywną tabelę danych, optymalizator może automatycznie zmienić ich pozycje dla lepszej wydajności. Będzie ona używać mniejszej tabeli jako punktu wyjścia do dopasowywania wierszy (po stronie "budowania") i większej tabeli jako tej, która będzie przeszukiwana (strona "sondowania", sprawdzanego pod kątem dopasowań). Takie podejście minimalizuje użycie pamięci, zmniejsza przenoszenie danych i poprawia równoległość, jednocześnie zapewniając dokładne wyniki.
Ujednolicony optymalizator zapytań stale uczy się z poprzednich wykonań zapytań w miarę rozwoju obciążeń, uściśliając algorytm optymalizacji, aby zapewnić najlepszą możliwą wydajność. Użytkownicy korzystają z automatycznego szybkiego wykonywania zapytań, niezależnie od złożoności i bez konieczności interweniowania.
Aparat przetwarzania zapytań rozproszonych
W Fabric Data Warehouse silnik przetwarzania zapytań rozproszonych przydziela zasoby obliczeniowe do zadań w planach zapytań. Aparat przetwarzania zapytań rozproszonych może planować zadania między węzłami obliczeniowymi, dzięki czemu każdy węzeł uruchamia część planu zapytania, umożliwiając równoległe wykonywanie w celu zwiększenia wydajności. Złożone raporty dotyczące dużych zestawów danych mogą korzystać z rozproszonego przetwarzania zapytań.
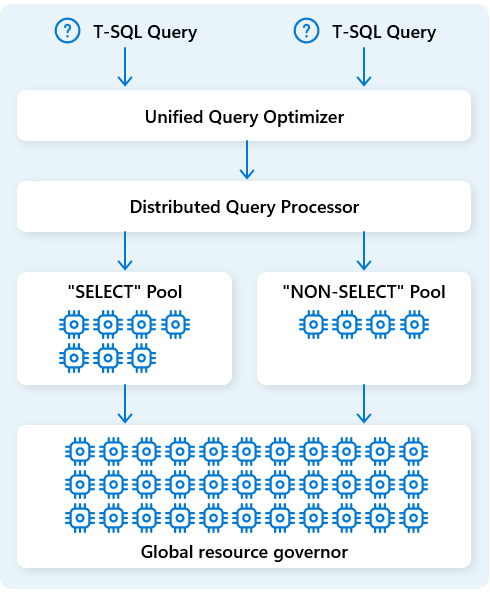
Aby jeszcze bardziej zoptymalizować zasoby, aparat przetwarzania zapytań rozproszonych oddziela zasoby obliczeniowe w dwie pule: dla SELECT zapytań i zadań pozyskiwania danych (NON-SELECT zapytań). Każde obciążenie otrzymuje dedykowane zasoby zgodnie z potrzebami. Oznacza to na przykład, że nocne zadania ETL nie opóźnią porannych pulpitów nawigacyjnych.
Dzięki szybkiej aprowizacji węzłów w chmurze aparat rozproszonego przetwarzania zapytań automatycznie skaluje zasoby obliczeniowe w górę lub w dół w odpowiedzi na zmiany w woluminie zapytań, rozmiarze danych i złożoności zapytań. Magazyn danych Fabric ma możliwości przetwarzania równoległego dla małych zestawów danych lub danych w skali wielu petabajtów.
Aparat wykonywania zapytań
Aparat wykonywania zapytań to proces, który uruchamia części rozproszonego planu wykonywania przypisanego do poszczególnych węzłów obliczeniowych. Silnik wykonywania zapytań jest oparty na tym samym silniku używanym przez SQL Server i Azure SQL Database do wykonywania w trybie wsadowym i formatów kolumnowych, w celu wydajnej analizy danych wielkich zbiorów przy optymalnym koszcie.
Aparat wykonywania zapytań odczytuje dane bezpośrednio z plików Delta Parquet przechowywanych w usłudze Fabric OneLake i korzysta z wielu warstw buforowania (pamięci i dysków SSD), aby przyspieszyć wydajność zapytań i zapewnić wykonywanie zapytań z optymalną szybkością. Aparat wykonywania zapytań przetwarza dane w pamięci, a w razie potrzeby pobiera dodatkowe dane z pamięci podręcznej SSD lub magazynu OneLake.
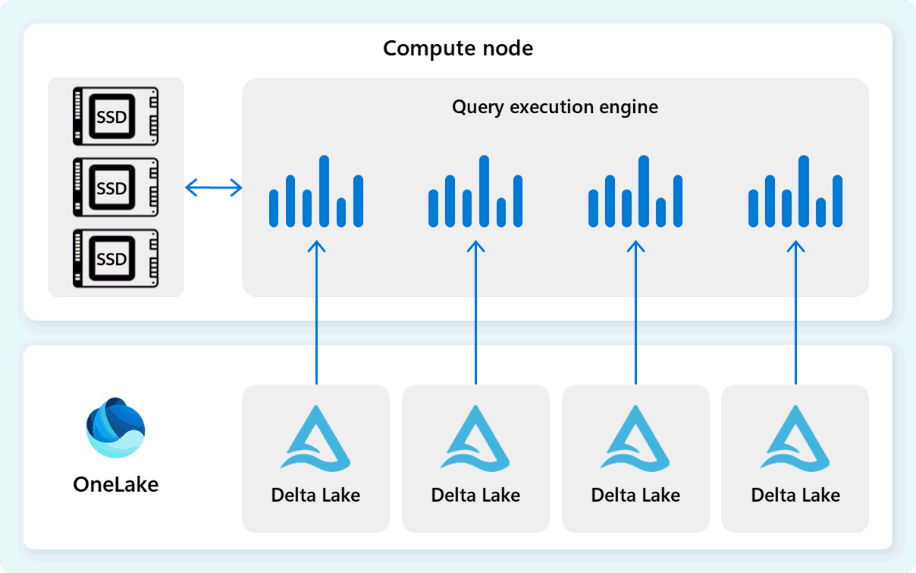
Podczas przetwarzania danych aparat wykonywania zapytań wykonuje eliminację kolumn i grup wierszy, aby pominąć segmenty, które nie są istotne dla zapytania. Ta optymalizacja zmniejsza ilość danych przeskanowanych z plików i pamięci podręcznej, co pomaga zminimalizować użycie zasobów i poprawić całkowity czas wykonywania.
Aparat wykonywania zapytań wyróżnia się filtrowaniem i agregowaniem miliardów wierszy, obsługując ogólne wzorce analityczne danych używane w nowoczesnych rozwiązaniach magazynu danych. Tryb wykonywania wsadowego korzysta z nowoczesnych możliwości procesorów do równoległego przetwarzania wielu wierszy, co znacznie zmniejsza obciążenie i sprawia, że zapytania mogą być wykonywane nawet setki razy szybciej w porównaniu z tradycyjnym wykonywaniem wiersz po wierszu.
Zarządzanie metadanymi i transakcjami
Aparat magazynu używa metadanych do opisywania schematu tabeli, organizacji plików, historii wersji i stanów transakcyjnych. Te metadane umożliwiają aparatowi magazynu wydajne zarządzanie danymi i wykonywanie zapytań o nie. Usługa Fabric Data Warehouse oferuje niezawodną i kompleksową architekturę zarządzania metadanymi i transakcjami, rozszerzając menedżera transakcji OLTP w celu organizowania wysoce współbieżnych operacji metadanych i zapewnienia zgodności ACID.
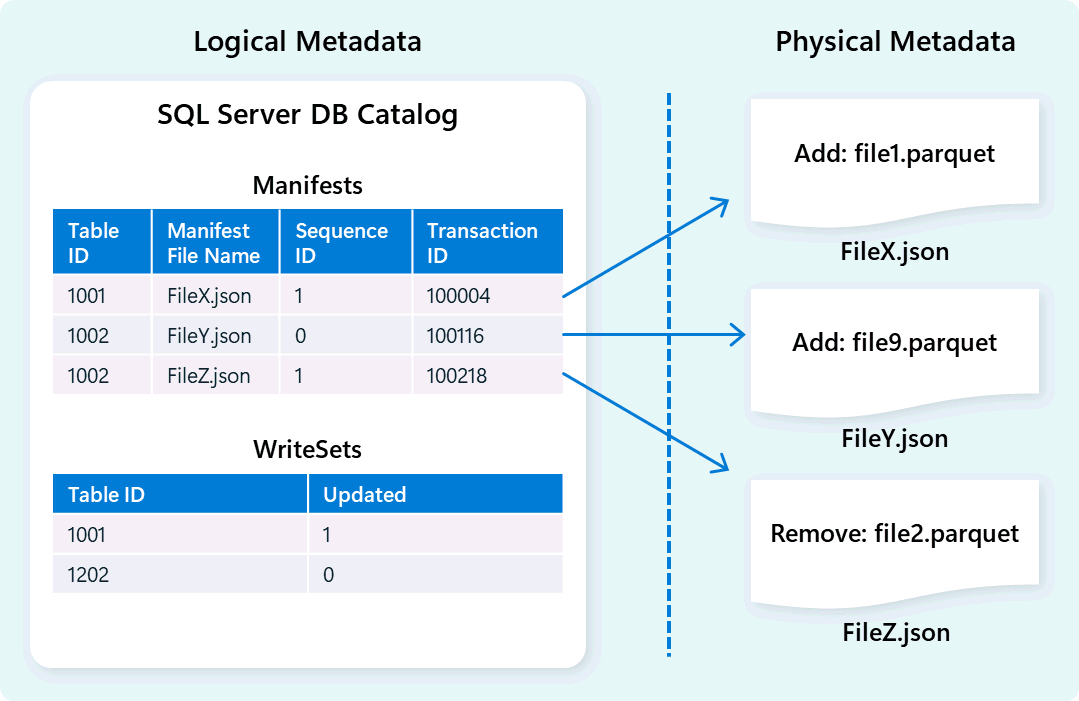
Ten projekt umożliwia szybką, niezawodną nawigację po stanach transakcyjnych, obsługującą obciążenia z dużą współbieżnością przy jednoczesnym zapewnieniu spójności.
Przechowywanie i ładowanie danych
Usługa Fabric Data Warehouse używa architektury typu lakehouse z formatem delta typu open source do skalowalnego, bezpiecznego magazynu o wysokiej wydajności. Format tabeli delta obsługuje przechowywanie wersji danych, umożliwiając natychmiastowy dostęp do historycznych migawek za pośrednictwem podróży w czasie i klonowania bez kopiowania na potrzeby bezpiecznych operacji testowania i wycofywania. Dane użytkownika są przechowywane w usłudze OneLake, co umożliwia wszystkim silnikom Fabric efektywny dostęp do współdzielonych danych bez nadmiarowości.
Bazując na tej podstawie, usługa Fabric Data Warehouse została zaprojektowana tak, aby zapewnić optymalną wydajność pozyskiwania danych, koncentrując się na prostotzie i elastyczności. Silnik efektywnie zarządza przechowywaniem danych tabel za pomocą automatycznego kompaktowania danych, którym konsoliduje pofragmentowane pliki w tle w celu zmniejszenia niepotrzebnego skanowania danych. Jego inteligentna metoda dystrybucji danych dzieli i organizuje dane w mikrodzielone komórki w celu zwiększenia przetwarzania równoległego i ulepszenia wyników zapytań. Te możliwości działają autonomicznie, bez konieczności ręcznego dostosowywania.