Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:✅ Magazyn w Microsoft Fabric
Potoki danych oferują alternatywę dla używania polecenia COPY za pomocą graficznego interfejsu użytkownika. Potok danych to logiczne grupowanie działań, które razem wykonują zadanie pozyskiwania danych. Rurociągi umożliwiają zarządzanie działaniami wyodrębniania, przekształcania i ładowania (ETL) zamiast zarządzania każdym z osobna.
W tym samouczku utworzysz nowy potok, który ładuje przykładowe dane do hurtowni danych w usłudze Microsoft Fabric.
Uwaga
Niektóre funkcje usługi Azure Data Factory nie są dostępne w usłudze Microsoft Fabric, ale koncepcje są zamienne. Więcej informacji na temat usługi Azure Data Factory i potoków można uzyskać w temacie Pipelines and activities in Azure Data Factory and Azure Synapse Analytics (Potoki i działania w usługach Azure Data Factory i Azure Synapse Analytics). Aby zapoznać się z przewodnikiem Szybki start, odwiedź stronę Szybki start: tworzenie pierwszego potoku w celu skopiowania danych.
Tworzenie potoku danych
Aby utworzyć nowy potok, przejdź do obszaru roboczego, wybierz przycisk +Nowy i wybierz pozycję Potok danych.
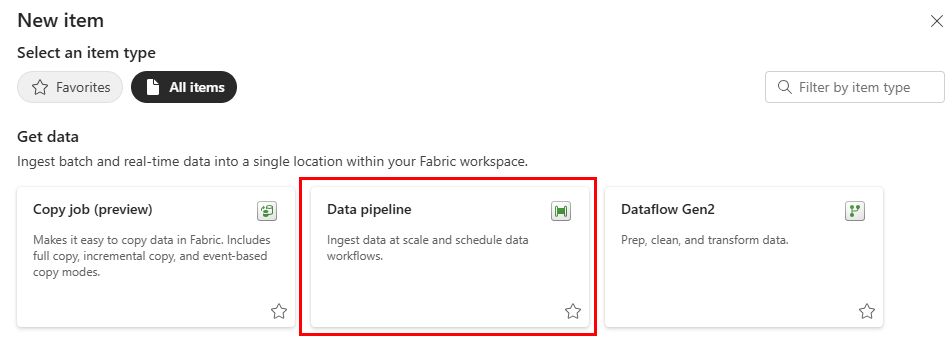
Aby utworzyć nowy potok, przejdź do obszaru roboczego, wybierz przycisk + Nowy element i wybierz pozycję Potok danych.
- W obszarze roboczym wybierz pozycję + Nowy element i poszukaj karty Potok danych w sekcji Pobieranie danych .
- Możesz też wybrać pozycję Utwórz w okienku nawigacji. Poszukaj karty Potok danych w sekcji Data Factory .
W oknie dialogowym Nowy potok podaj nazwę nowego potoku i wybierz pozycję Utwórz.
Nastąpi przekierowanie do obszaru kanwy potoku, w którym zobaczysz opcje rozpoczęcia pracy.
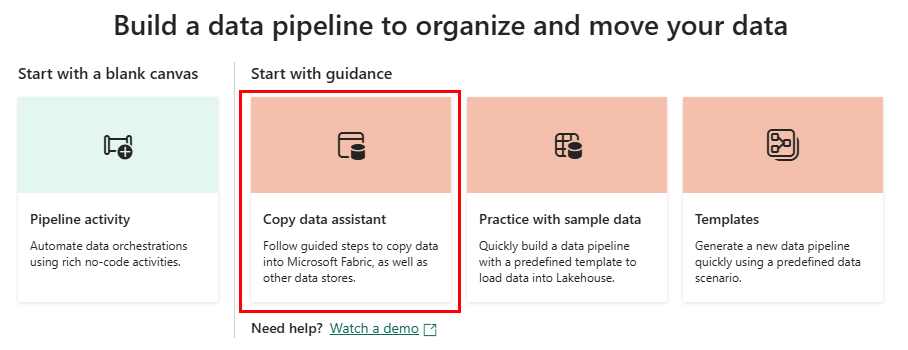
Wybierz opcję Asystent kopiowania danych, aby uruchomić Asystent kopiowania.
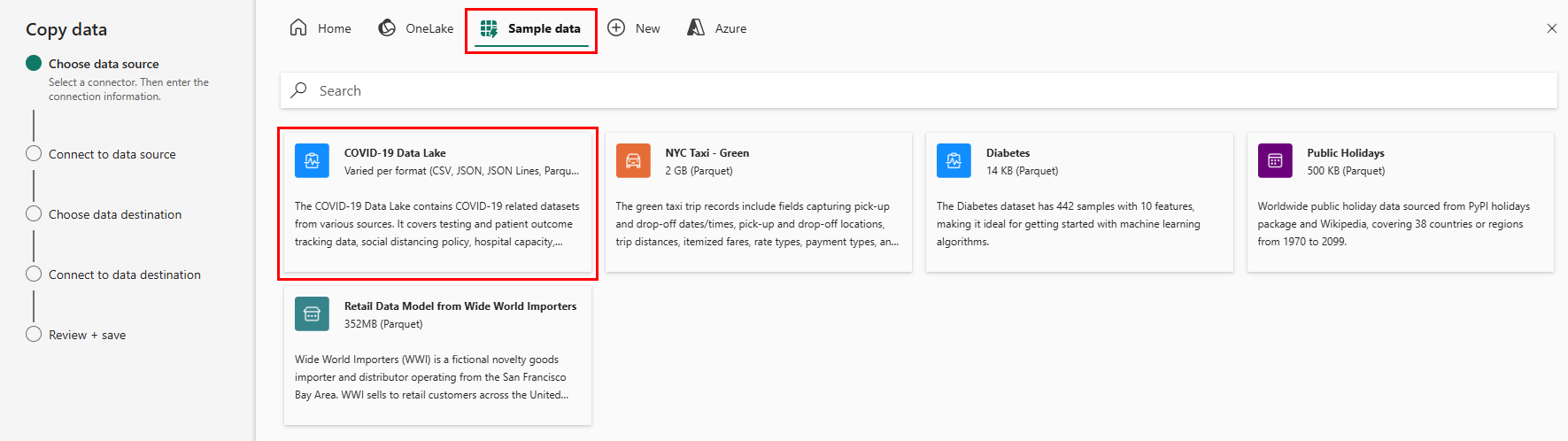
Pierwsza strona asystenta kopiowania danych pomaga wybrać własne dane z różnych źródeł danych lub wybrać jedną z podanych przykładów, aby rozpocząć pracę. Wybierz pozycję Przykładowe dane na pasku menu na tej stronie. Na potrzeby tego samouczka użyjemy przykładu COVID-19 Data Lake . Wybierz tę opcję i wybierz przycisk Dalej.
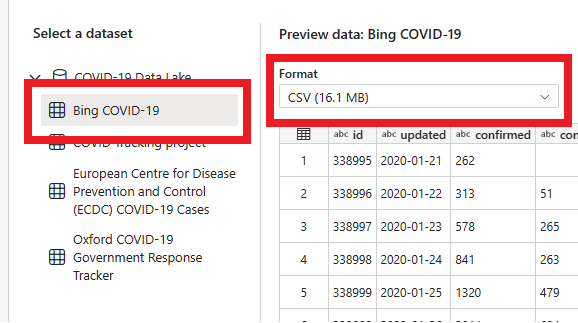
Na następnej stronie możesz wybrać zestaw danych, format pliku źródłowego i wyświetlić podgląd wybranego zestawu danych. Wybierz pozycję Bing COVID-19, format CSV i wybierz przycisk Dalej.
Następna strona, Miejsca docelowe danych, umożliwia skonfigurowanie typu docelowego obszaru roboczego. Załadujemy dane do magazynu w naszym obszarze roboczym. Wybierz żądany magazyn z listy rozwijanej i wybierz pozycję Dalej.
Ostatnim krokiem do skonfigurowania miejsca docelowego jest podanie nazwy tabeli docelowej i skonfigurowanie mapowań kolumn. W tym miejscu możesz załadować dane do nowej tabeli lub istniejącej, podać schemat i nazwy tabel, zmienić nazwy kolumn, usunąć kolumny lub zmienić ich mapowania. Możesz zaakceptować wartości domyślne lub dostosować ustawienia do swoich preferencji.
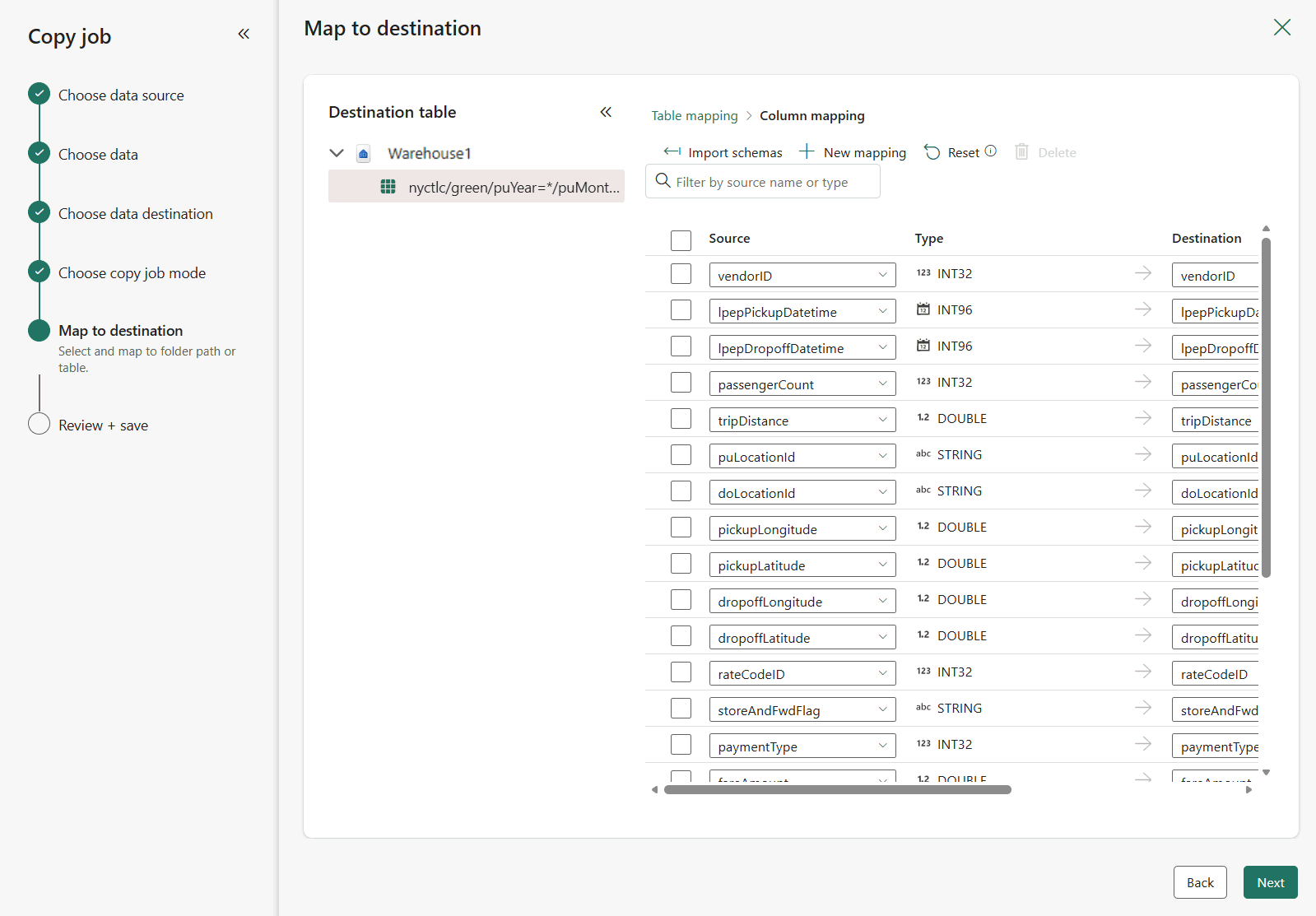
Po zakończeniu przeglądania opcji wybierz pozycję Dalej.
Następna strona daje możliwość użycia etapowania lub oferuje zaawansowane opcje do operacji kopiowania danych (która używa polecenia T-SQL COPY). Przejrzyj opcje bez ich zmiany, a następnie wybierz przycisk Dalej.
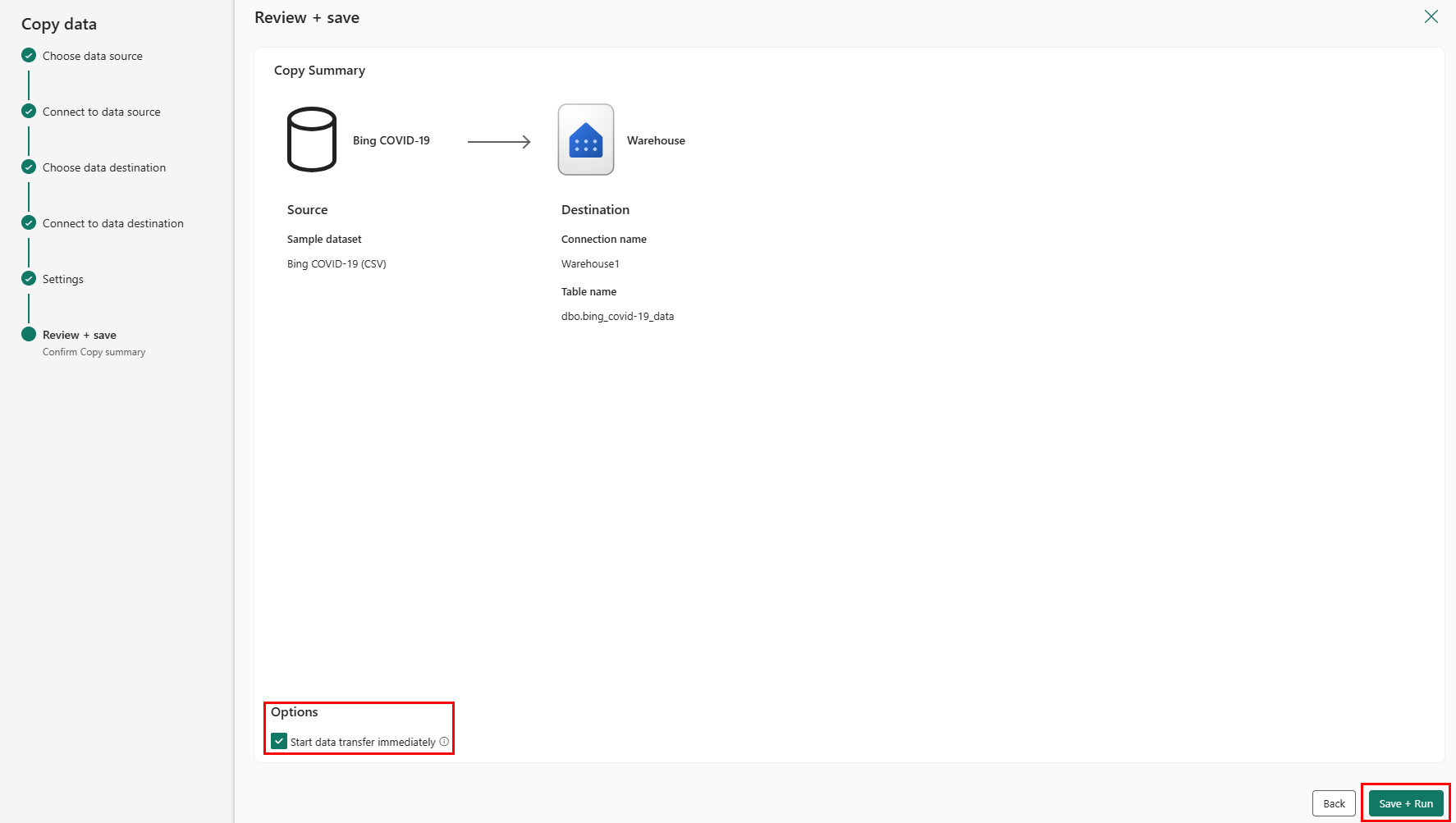
Ostatnia strona asystenta zawiera podsumowanie działania kopiowania. Wybierz opcję Rozpocznij transfer danych natychmiast , a następnie wybierz pozycję Zapisz i uruchom.
Zostanie przekierowany do obszaru kanwy potoku, w którym skonfigurowano już nowe działanie Kopiowania danych. Potok zostanie uruchomiony automatycznie. Można monitorować status przepływu zadań w okienku Dane wyjściowe:
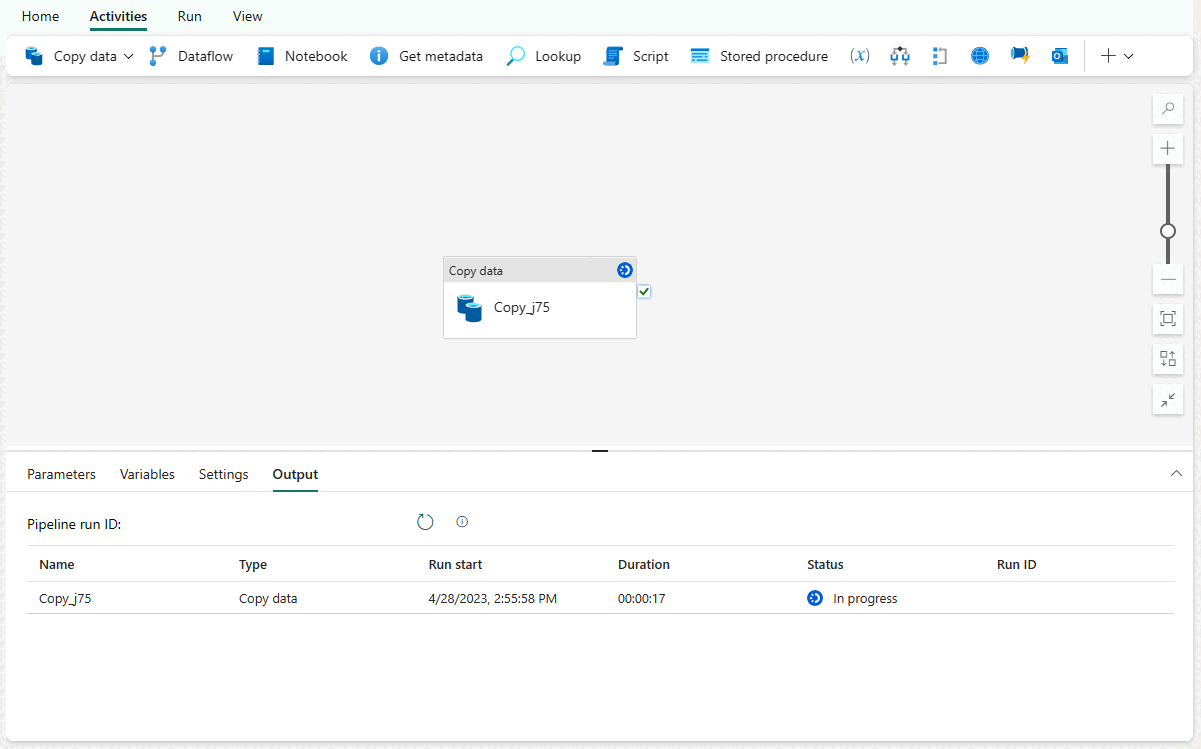
Po kilku sekundach potok zakończy się pomyślnie. Po powrocie do magazynu możesz wybrać tabelę, aby wyświetlić podgląd danych i potwierdzić zakończenie operacji kopiowania.




Aby uzyskać więcej informacji na temat importowania danych do magazynu w usłudze Microsoft Fabric, odwiedź:
- Pozyskiwanie danych do magazynu
- Pozyskiwanie danych do magazynu przy użyciu instrukcji COPY
- Pozyskiwanie danych do magazynu przy użyciu języka Transact-SQL