Integrowanie usługi OneLake z usługą Azure Synapse Analytics
Azure Synapse to pozbawiona ograniczeń usługa analityczna łącząca funkcje magazynowania danych przedsiębiorstwa i analiz danych big data. W tym samouczku pokazano, jak nawiązać połączenie z usługą OneLake przy użyciu usługi Azure Synapse Analytics.
Zapisywanie danych z usługi Synapse przy użyciu platformy Apache Spark
Wykonaj następujące kroki, aby użyć platformy Apache Spark do zapisania przykładowych danych w usłudze OneLake z usługi Azure Synapse Analytics.
Otwórz obszar roboczy usługi Synapse i utwórz pulę platformy Apache Spark z preferowanymi parametrami.
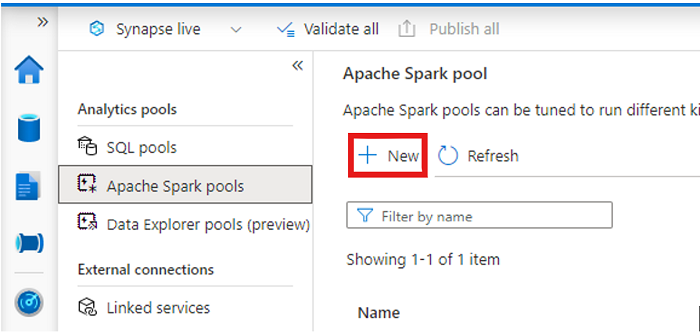
Utwórz nowy notes platformy Apache Spark.
Otwórz notes, ustaw język na PySpark (Python) i połącz go z nowo utworzoną pulą Spark.
Na osobnej karcie przejdź do magazynu lakehouse usługi Microsoft Fabric i znajdź folder Tabele najwyższego poziomu.
Kliknij prawym przyciskiem myszy folder Tables i wybierz polecenie Właściwości.
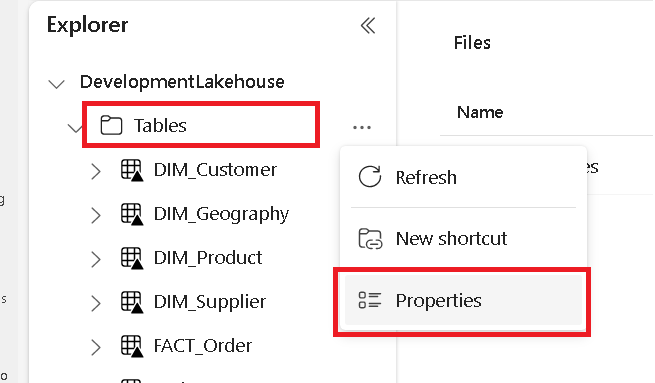
Skopiuj ścieżkę ABFS z okienka właściwości.
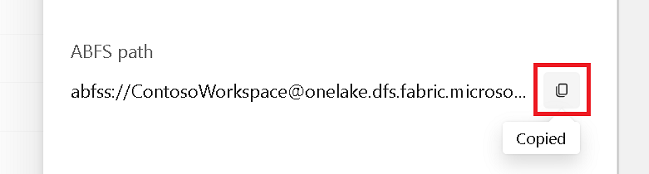
W notesie usługi Azure Synapse w pierwszej nowej komórce kodu podaj ścieżkę lakehouse. To lakehouse to miejsce, w którym dane są zapisywane później. Uruchom komórkę.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'W nowej komórce kodu załaduj dane z otwartego zestawu danych platformy Azure do ramki danych. Ten zestaw danych jest ładowany do magazynu lakehouse. Uruchom komórkę.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))W nowej komórce kodu, filtruj, przekształć lub przygotuj dane. W tym scenariuszu możesz przyciąć zestaw danych w celu szybszego ładowania, dołączania do innych zestawów danych lub filtrowania do określonych wyników. Uruchom komórkę.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))W nowej komórce kodu przy użyciu ścieżki OneLake zapisz przefiltrowaną ramkę danych w nowej tabeli Delta-Parquet w usłudze Fabric lakehouse. Uruchom komórkę.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Na koniec w nowej komórce kodu przetestuj, czy dane zostały pomyślnie zapisane, odczytując nowo załadowany plik z usługi OneLake. Uruchom komórkę.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Gratulacje. Teraz możesz odczytywać i zapisywać dane w usłudze OneLake przy użyciu platformy Apache Spark w usłudze Azure Synapse Analytics.
Odczytywanie danych z usługi Synapse przy użyciu języka SQL
Wykonaj następujące kroki, aby używać usługi SQL Serverless do odczytywania danych z usługi OneLake z usługi Azure Synapse Analytics.
Otwórz usługę Fabric lakehouse i zidentyfikuj tabelę, którą chcesz wykonać w zapytaniu z usługi Synapse.
Kliknij prawym przyciskiem myszy tabelę i wybierz polecenie Właściwości.
Skopiuj ścieżkę ABFS dla tabeli.
Otwórz obszar roboczy usługi Synapse w programie Synapse Studio.
Utwórz nowy skrypt SQL.
W edytorze zapytań SQL wprowadź następujące zapytanie, zastępując
ABFS_PATH_HEREciąg ścieżką skopiowaną wcześniej.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Uruchom zapytanie, aby wyświetlić 10 pierwszych wierszy tabeli.
Gratulacje. Teraz możesz odczytywać dane z usługi OneLake przy użyciu usługi SQL Serverless w usłudze Azure Synapse Analytics.
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla