operator make-series
Dotyczy: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Utwórz serię określonych zagregowanych wartości wzdłuż określonej osi.
Składnia
T | make-series [MakeSeriesParameters] [Kolumna =] Agregacja [ default = DefaultValue] [, ...] on OśKolumn [from początek] [ to koniec] step krok [by [Kolumna = ] GroupExpression [, ...]]
Dowiedz się więcej na temat konwencji składni.
Parametry
| Nazwisko | Type | Wymagania | opis |
|---|---|---|---|
| Kolumna | string |
Nazwa kolumny wyników. Domyślnie nazwa pochodzi z wyrażenia . | |
| DefaultValue | skalar | Wartość domyślna, która ma być używana zamiast braków wartości. Jeśli nie ma wiersza z określonymi wartościami kolumn AxisColumn i GroupExpression, odpowiedni element tablicy zostanie przypisany do wartości DefaultValue. Wartość domyślna to 0. | |
| Agregacja | string |
✔️ | Wywołanie funkcji agregacji, takiej jak count() lub avg(), z nazwami kolumn jako argumentami. Zobacz listę funkcji agregacji. Operator może używać make-series tylko funkcji agregacji, które zwracają wyniki liczbowe. |
| Kolumna osi | string |
✔️ | Kolumna, według której będzie uporządkowana seria. Zazwyczaj wartości kolumn będą typu datetime lub timespan wszystkie typy liczbowe są akceptowane. |
| start | skalar | ✔️ | Niska wartość granicy kolumny AxisColumn dla każdej serii do skompilowania. Jeśli uruchomienie nie zostanie określone, będzie to pierwszy pojemnik lub krok zawierający dane w każdej serii. |
| koniec | skalar | ✔️ | Wysoka niezwiązana wartość inkluzywna kolumny AxisColumn. Ostatni indeks szeregów czasowych jest mniejszy niż ta wartość i zostanie uruchomiony plus liczba całkowita wielokrotność kroku , która jest mniejsza niż koniec. Jeśli koniec nie zostanie określony, będzie górną granicą ostatniego pojemnika lub kroku zawierającego dane dla każdej serii. |
| krok | skalar | ✔️ | Różnica lub rozmiar pojemnika między dwoma kolejnymi elementami tablicy AxisColumn . Aby uzyskać listę możliwych interwałów czasu, zobacz przedział czasu. |
| GroupExpression | Wyrażenie w kolumnach, które zawiera zestaw unikatowych wartości. Zazwyczaj jest to nazwa kolumny, która zawiera już ograniczony zestaw wartości. | ||
| MakeSeriesParameters | Zero lub więcej parametrów rozdzielonych spacjami w postaci wartości nazwy = , która kontroluje zachowanie. Zobacz obsługiwane parametry serii. |
Uwaga
Parametry rozpoczęcia, zakończenia i kroku służą do tworzenia tablicy wartości AxisColumn. Tablica składa się z wartości między rozpoczęciem a końcem, a wartością kroku reprezentującą różnicę między jednym elementem tablicy a następnym. Wszystkie wartości agregacji są uporządkowane odpowiednio dla tej tablicy.
Obsługiwane parametry serii
| Nazwa/nazwisko | opis |
|---|---|
kind |
Tworzy wynik domyślny, gdy dane wejściowe operatora serii make-series są puste. Wartość: nonempty |
hint.shufflekey=<key> |
Zapytanie shufflekey współudzieli obciążenie zapytania w węzłach klastra przy użyciu klucza do partycjonowania danych. Zobacz zapytanie mieszania |
Uwaga
Tablice generowane przez serię make są ograniczone do 1048576 wartości (2^20). Próba wygenerowania większej tablicy z serią make-series spowoduje błąd lub obciętą tablicę.
Składnia alternatywna
T | make-series [Kolumna = ] Agregacja [ default = DefaultValue] [, ...] on inrange(Krok) zatrzymania ,rozpoczęcia, osi [ [byKolumna =] GroupExpression [, ...]]
Wygenerowana seria z alternatywnej składni różni się od głównej składni w dwóch aspektach:
- Wartość zatrzymania jest inkluzywna.
- Łączenie osi indeksu jest generowane z wartością bin() i nie bin_at(), co oznacza, że rozpoczęcie może nie być uwzględnione w wygenerowanej serii.
Zaleca się używanie głównej składni make-series, a nie alternatywnej składni.
Zwraca
Wiersze wejściowe są rozmieszczane w grupach o tych samych wartościach by wyrażeń i wyrażeniu początkowymbin_at() kroku,AxisColumn., Następnie określone funkcje agregacji są obliczane dla każdej grupy, tworząc wiersz dla każdej grupy. Wynik zawiera by kolumny, kolumnę AxisColumn , a także co najmniej jedną kolumnę dla każdej obliczonej agregacji. (Agregacje w wielu kolumnach lub nieliczbowych wynikach nie są obsługiwane).
Ten wynik pośredni zawiera tyle wierszy, ile istnieje odrębnych kombinacji wartości początkowych by) kroku,AxisColumn ibin_at( AxisColumn.,
Na koniec wiersze z wyniku pośredniego rozmieszczone w grupach o tych samych wartościach by wyrażeń i wszystkie zagregowane wartości są rozmieszczane w tablice (wartości dynamic typu). Dla każdej agregacji istnieje jedna kolumna zawierająca jej tablicę o tej samej nazwie. Ostatnia kolumna to tablica zawierająca wartości kolumny AxisColumn binned zgodnie z określonym krokiem.
Uwaga
Mimo że można podać dowolne wyrażenia zarówno dla wyrażeń agregacji, jak i grupowania, bardziej wydajne jest używanie prostych nazw kolumn.
Lista funkcji agregacji
| Function | opis |
|---|---|
| avg() | Zwraca średnią wartość w grupie |
| avgif() | Zwraca średnią z predykatem grupy |
| count() | Zwraca liczbę grup |
| countif() | Zwraca liczbę z predykatem grupy |
| dcount() | Zwraca przybliżoną liczbę unikatowych elementów grupy |
| dcountif() | Zwraca przybliżoną liczbę unikatowych wartości z predykatem grupy |
| max() | Zwraca maksymalną wartość w grupie |
| maxif() | Zwraca wartość maksymalną z predykatem grupy |
| min() | Zwraca minimalną wartość w grupie |
| minif() | Zwraca wartość minimalną z predykatem grupy |
| percentyl() | Zwraca wartość percentyla w grupie |
| take_any() | Zwraca losową wartość niepustą dla grupy |
| stdev() | Zwraca odchylenie standardowe w grupie |
| sum() | Zwraca sumę elementów w grupie |
| sumif() | Zwraca sumę elementów z predykatem grupy |
| wariancja() | Zwraca wariancję w grupie |
Lista funkcji analizy serii
| Function | opis |
|---|---|
| series_fir() | Stosuje filtr skończonej odpowiedzi impulsowej |
| series_iir() | Stosuje filtr Nieskończona odpowiedź impulsowa |
| series_fit_line() | Znajduje linię prostą, która jest najlepszym przybliżeniem danych wejściowych |
| series_fit_line_dynamic() | Znajduje wiersz, który jest najlepszym przybliżeniem danych wejściowych, zwracając obiekt dynamiczny |
| series_fit_2lines() | Znajduje dwa wiersze, które są najlepszym przybliżeniem danych wejściowych |
| series_fit_2lines_dynamic() | Znajduje dwa wiersze, które są najlepszym przybliżeniem danych wejściowych, zwracając obiekt dynamiczny |
| series_outliers() | Ocenia punkty anomalii w serii |
| series_periods_detect() | Znajduje najbardziej znaczące okresy, które istnieją w szeregach czasowych |
| series_periods_validate() | Sprawdza, czy szereg czasowy zawiera okresowe wzorce danej długości |
| series_stats_dynamic() | Zwracanie wielu kolumn ze wspólnymi statystykami (minimalna/maksymalna/wariancja/stdev/average) |
| series_stats() | Generuje wartość dynamiczną z typowymi statystykami (minimalna/maksymalna/wariancja/stdev/average) |
Aby uzyskać pełną listę funkcji analizy serii, zobacz: Funkcje przetwarzania serii
Lista funkcji interpolacji serii
| Function | opis |
|---|---|
| series_fill_backward() | Wykonuje interpolację wsteczną brakujących wartości w serii |
| series_fill_const() | Zamienia brakujące wartości w serii na określoną wartość stałą |
| series_fill_forward() | Wykonuje interpolację wypełnienia do przodu z brakującymi wartościami w serii |
| series_fill_linear() | Wykonuje interpolację liniową brakujących wartości w serii |
- Uwaga: Funkcje interpolacji domyślnie zakładają
null, że jest to brakująca wartość. W związku z tym określdefault=wartośćmake-seriesdouble(null), jeśli zamierzasz używać funkcji interpolacji dla serii.
Przykłady
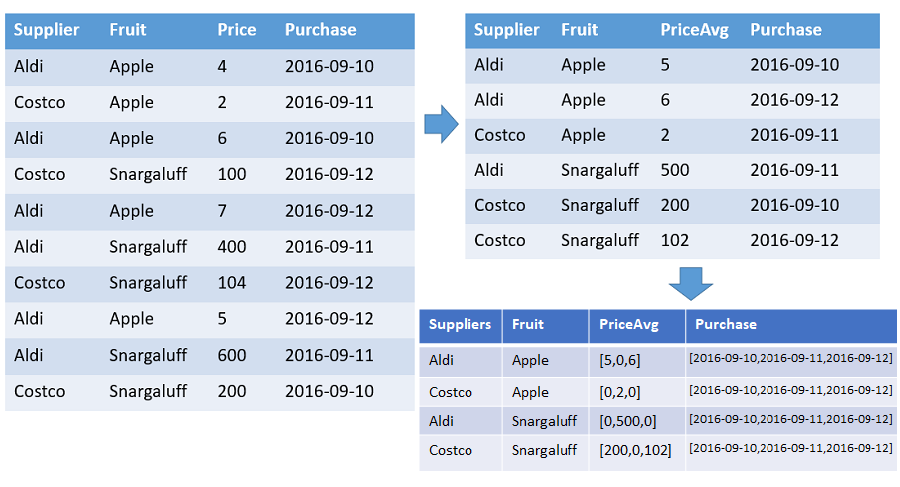
Tabela przedstawiająca tablice liczb i średnich cen każdego owocu od każdego dostawcy uporządkowanego według znacznika czasu z określonym zakresem. W danych wyjściowych znajduje się wiersz dla każdej odrębnej kombinacji owoców i dostawcy. W kolumnach wyjściowych są wyświetlane owoce, dostawca i tablice: liczba, średnia i cała oś czasu (od 2016-01-01 do 2016-01-10). Wszystkie tablice są sortowane według odpowiedniego znacznika czasu, a wszystkie luki są wypełniane wartościami domyślnymi (0 w tym przykładzie). Wszystkie inne kolumny wejściowe są ignorowane.
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | timestamp |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
Gdy dane wejściowe są make-series puste, domyślne zachowanie elementu powoduje wygenerowanie pustego make-series wyniku.
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
Wyjście
| Count |
|---|
| 0 |
Użycie kind=nonempty w make-series metodzie spowoduje wygenerowanie niepustego wyniku wartości domyślnych:
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
Wyjście
| avg_metric | timestamp |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ "2017-01-01T00:00:00.000000Z", "2017-01-02T00:00:00.000000Z", "2017-01-03T00:00:00.000000Z", "2017-01-04T00:00:00.000000Z", "2017-01-05T00:00:00.000000Z", "2017-01-06T00:00:00.000000Z", "2017-01-07T00:00:00.000000Z", "2017-01-08T00:00:00.000000Z", "2017-01-09T00:00:00.000000Z" ] |