Trenowanie modelu przetwarzania dokumentów ze strukturą lub dowolną formą w Microsoft Syntex
Postępuj zgodnie z instrukcjami w temacie Tworzenie modelu w programie Syntex , aby utworzyć model przetwarzania dokumentów o strukturze lub dowolnej strukturze w centrum zawartości. Możesz też wykonać instrukcje opisane w temacie Tworzenie modelu w lokalnej witrynie programu SharePoint , aby utworzyć model w witrynie lokalnej. Następnie użyj tego artykułu, aby wytrenować model.

Aby wytrenować model przetwarzania dokumentów o strukturze lub dowolnej strukturze, wykonaj następujące kroki:
- Krok 1. Dodawanie i analizowanie dokumentów
- Krok 2. Tagowanie pól i tabel
- Krok 3. Trenowanie i publikowanie modelu
- Krok 4. Korzystanie z modelu
Krok 1. Dodawanie i analizowanie dokumentów
Po utworzeniu modelu przetwarzania dokumentów ze strukturą lub dowolną formą zostanie otwarta strona Wybieranie informacji do wyodrębnienia . W tym miejscu wyświetlisz listę wszystkich informacji, które model AI ma wyodrębnić z dokumentów, takich jak Nazwa, Adres lub Kwota.
Uwaga
Jeśli szukasz przykładowych plików do użycia, zobacz wymagania dotyczące dokumentów wejściowych modelu przetwarzania dokumentów i porady dotyczące optymalizacji.
Najpierw zdefiniuj pola i tabele, które chcesz nauczyć model wyodrębniać na stronie Wybieranie informacji do wyodrębnienia . Aby uzyskać szczegółowe kroki, zobacz Definiowanie pól i tabel do wyodrębnienia.
Możesz utworzyć dowolną liczbę kolekcji układów dokumentów, które chcesz przetworzyć w modelu. Aby uzyskać szczegółowe instrukcje, zobacz Grupowanie dokumentów według kolekcji.
Po utworzeniu kolekcji i dodaniu co najmniej pięciu przykładowych plików dla każdego narzędzia AI Builder w aplikacji Syntex przeanalizujesz przekazane dokumenty w celu wykrycia pól i tabel. Ten proces zwykle trwa kilka sekund. Po zakończeniu analizy możesz kontynuować tagowanie dokumentów.
Krok 2. Tagowanie pól i tabel
Musisz otagować dokumenty, aby nauczyć model rozumieć pola i dane tabeli, które chcesz wyodrębnić. Aby uzyskać szczegółowe instrukcje, zobacz Tagowanie dokumentów.
Krok 3. Trenowanie i publikowanie modelu
Po utworzeniu i wytrenowania modelu możesz go opublikować i użyć w programie SharePoint. Aby opublikować model, wybierz pozycję Publikuj. Aby uzyskać szczegółowe instrukcje, zobacz Train and publish your document processing model (Trenowanie i publikowanie modelu przetwarzania dokumentów).
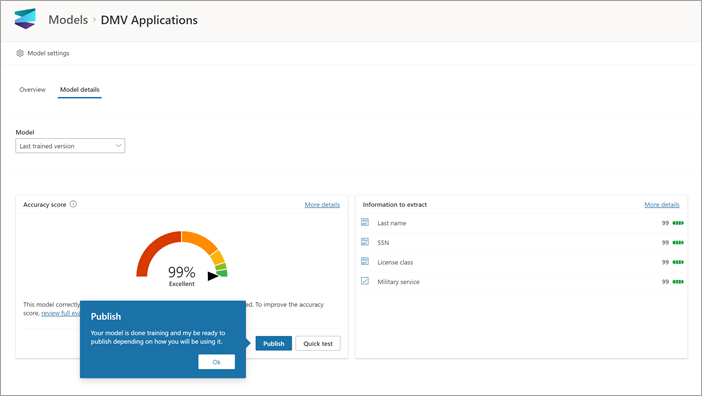
Po opublikowaniu modelu przejdziesz do strony głównej modelu. Następnie będziesz mieć możliwość zastosowania modelu do biblioteki dokumentów.
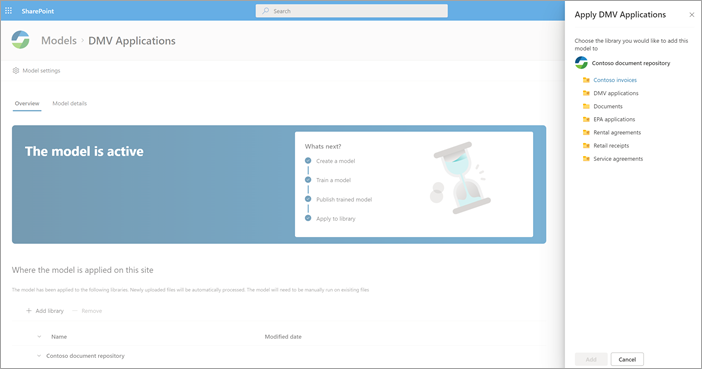
Krok 4. Korzystanie z modelu
W widoku modelu biblioteki dokumentów zwróć uwagę, że wybrane pola są teraz wyświetlane jako kolumny.
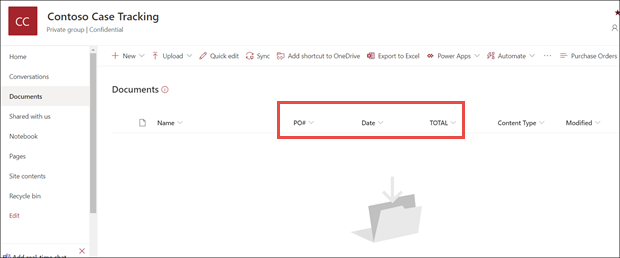
Zwróć uwagę, że link informacyjny obok pozycji Dokumenty zauważa, że model przetwarzania formularzy jest stosowany do tej biblioteki dokumentów.
Przekaż pliki do biblioteki dokumentów. Wszystkie pliki, które model identyfikuje jako typ zawartości, wyświetlają pliki w widoku i wyświetlają wyodrębnione dane w kolumnach.
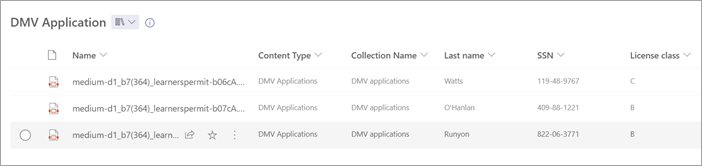
Uwaga
Jeśli model przetwarzania dokumentów ze strukturą lub dowolną strukturą i model przetwarzania dokumentów bez struktury są stosowane do tej samej biblioteki, plik jest klasyfikowany przy użyciu modelu przetwarzania dokumentów bez struktury i wszystkich wytrenowanych wyodrębniaczy dla tego modelu. Jeśli istnieją puste kolumny zgodne z modelem przetwarzania dokumentów, kolumny zostaną wypełnione przy użyciu wyodrębnionych wartości.
Pole Data klasyfikacji
Gdy dowolny model niestandardowy zostanie zastosowany do biblioteki dokumentów, pole Data klasyfikacji zostanie uwzględnione w schemacie biblioteki. Domyślnie to pole jest puste. Jednak gdy dokumenty są przetwarzane i klasyfikowane przez model, to pole jest aktualizowane za pomocą sygnatury daty i godziny ukończenia.
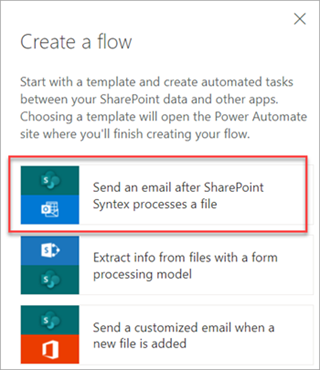
Gdy model jest ostemplowany datą klasyfikacji, możesz użyć polecenia Wyślij wiadomość e-mail po przetworzeniu przepływu pliku przez program Syntex , aby powiadomić użytkowników, że nowy plik został przetworzony i sklasyfikowany przez model w bibliotece dokumentów programu SharePoint.
Aby uruchomić przepływ:
Wybierz plik, a następnie wybierz pozycję Integruj>usługę Power Automate>Utwórz przepływ.
W panelu Tworzenie przepływu wybierz pozycję Wyślij wiadomość e-mail po przetworzeniu pliku przez program Syntex.
Wyodrębnianie informacji przy użyciu przepływów
Ważna
Informacje w tej sekcji nie mają zastosowania do najnowszej wersji aplikacji Syntex. Pozostanie ono odwołaniem tylko do modeli przetwarzania formularzy, które zostały utworzone w poprzednich wersjach. W najnowszej wersji nie trzeba już konfigurować przepływów do przetwarzania istniejących plików.
Dostępne są dwa przepływy do przetwarzania wybranego pliku lub partii plików w bibliotece, w której zastosowano model przetwarzania dokumentów o strukturze lub dowolnej strukturze.
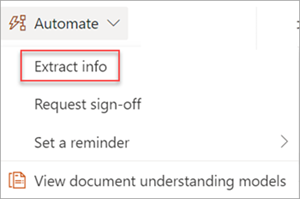
Wyodrębnianie informacji z obrazu lub pliku PDF przy użyciu modelu przetwarzania dokumentów — umożliwia wyodrębnienie tekstu z wybranego obrazu lub pliku PDF przez uruchomienie modelu przetwarzania dokumentów. Obsługuje pojedynczy wybrany plik jednocześnie i obsługuje tylko pliki PDF i pliki obrazów (.png, .jpg i jpeg). Aby uruchomić przepływ, wybierz plik, a następnie wybierz pozycję Automatyzuj>wyodrębnianie informacji.
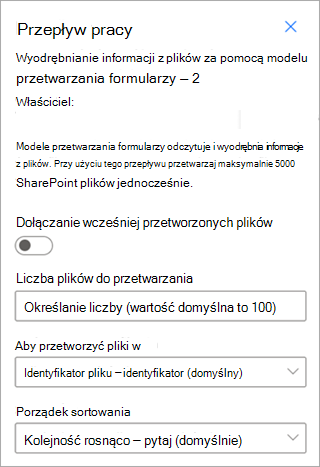
Wyodrębnij informacje z plików za pomocą modelu przetwarzania dokumentów — użyj z modelami przetwarzania dokumentów, aby odczytywać i wyodrębniać informacje z partii plików. Przetwarza do 5000 plików programu SharePoint jednocześnie. Po uruchomieniu tego przepływu można ustawić pewne parametry. Można:
- Określ, czy dołączyć wcześniej przetworzone pliki (domyślnie nie należy uwzględniać wcześniej przetworzonych plików).
- Wybierz liczbę plików do przetworzenia (wartość domyślna to 100 plików).
- Określ kolejność przetwarzania plików (opcje są określane według identyfikatora pliku, nazwy pliku, czasu utworzenia pliku lub czasu ostatniej modyfikacji).
- Określ, jak ma być sortowane zamówienie (kolejność rosnąca lub malejąca).
Uwaga
Przepływ wyodrębniania informacji z obrazu lub pliku PDF z przepływem modelu przetwarzania dokumentów jest automatycznie dostępny dla biblioteki ze skojarzonym modelem przetwarzania dokumentów. Przepływ wyodrębniania informacji z plików z modelem przetwarzania dokumentów to szablon, który w razie potrzeby musi zostać dodany do biblioteki.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla