Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Power Automate Process Mining umożliwia przechowywanie i odczytywanie danych dziennika zdarzeń bezpośrednio z usługi Azure Data Lake Storage Gen2. Ta funkcja upraszcza zarządzanie wyodrębnienia, przekształcenia, ładowania (ETL) przez połączenie bezpośrednio z kontem magazynu.
Ta funkcja obsługuje obecnie pozyskiwanie następujących elementów:
-
CSV
- Jeden plik CSV.
- Folder z wieloma plikami CSV o tej samej strukturze. Wszystkie pliki są pozyskiwane.
-
Parquet
- Jeden plik parquet.
- Folder z wieloma plikami parquet o tej samej strukturze. Wszystkie pliki są pozyskiwane.
-
Delta-parquet
- Folder zawierający strukturę Delta-parquet.
Wymagania wstępne
Konto Data Lake Storage musi być Gen2. Możesz to sprawdzić w Azure Portal. Konta magazynu Azure Data Lake Gen1 nie są obsługiwane.
Konto magazynu Azure Data Lake Storage musi mieć włączoną hierarchiczną przestrzeń nazw.
Rola Właściciel (na poziomie konta magazynu) musi być przypisana do użytkownika wykonującego wstępną konfigurację kontenera dla środowiska dla następujących użytkowników w tym samym środowisku. Ci użytkownicy łączący się z tym samym kontenerem muszą mieć następujące przypisania:
- Czytnik danych obiektu Blob magazynu lub Współautor obiektu blob magazynu — przypisana rola
- Przynajmniej przypisana rola Czytelnik do Azure Resource Manager.
Udostępnianie zasobów (CORS) – reguła do konta magazynu, której chcesz udostępnić w Power Automate Process Mining.
Dozwolone źródła muszą być ustawione na
https://make.powerautomate.comihttps://make.powerapps.com.Dozwolone metody muszą zawierać:
get,options,put,post.Dozwolone nagłówki powinny być jak najbardziej elastyczne. Zaleca się ich zdefiniowanie jako
*.Uwidocznione nagłówki powinny być jak najbardziej elastyczne. Zaleca się ich zdefiniowanie jako
*.Maksymalny okres życia powinien być jak najbardziej elastyczny. Zaleca się korzystanie z aplikacji
86400.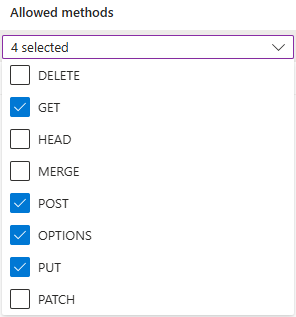
Dane CSV w Data Lake danych muszą spełniać następujące wymagania dotyczące formatu pliku CSV:
- Typ kompresji: brak
- Ogranicznik kolumny: Przecinek (,)
- Ogranicznik wiersza: kodowanie domyślne i kodowanie. Na przykład domyślnie (\r,\n lub \r\n)
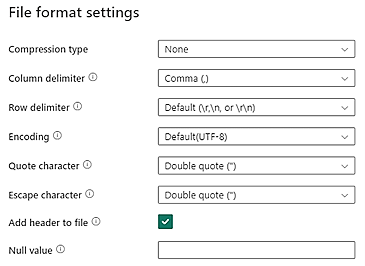
Wszystkie dane muszą mieć format dziennika zdarzeń końcowych i muszą spełniać wymagania określone w wymaganiach dotyczących danych. Dane powinny być gotowe do zamapowania na schemat badania procesów. Przekształcenie danych nie jest dostępne po ich pozyskaniu.
Rozmiar (szerokość) wiersza nagłówka jest obecnie ograniczony do 1 MB.
Ważne
Należy się upewnić, że sygnatura czasowa reprezentująca plik CSV ma standardowy format ISO 8601 (np. YYYY-MM-DD HH:MM:SS.sss lub YYYY-MM-DDTHH:MM:SS.sss).
Nawiązywanie połączenia z usługą Azure Data Lake Storage
W okienku nawigacji po lewej stronie wybierz pozycję Badanie procesów>Rozpocznij tutaj.
W polu Nazwa procesu wprowadź nazwę procesu.
W obszarze Źródło danych wybierz pozycję Importuj dane>Azure Data Lake>Kontynuuj.

Na ekranie Konfiguracja połączenia wybierz ID subskrypcji, Grupę zasobów, Konto magazynu i Kontener z menu rozwijanych.
Wybierz plik lub folder zawierający dane dziennika zdarzeń.
Można wybrać jeden plik lub folder z wieloma plikami. Wszystkie pliki muszą mieć te same nagłówki i formaty.
Wybierz Dalej.
Na ekranie Mapowanie danych zamapuj dane na wymagany schemat.
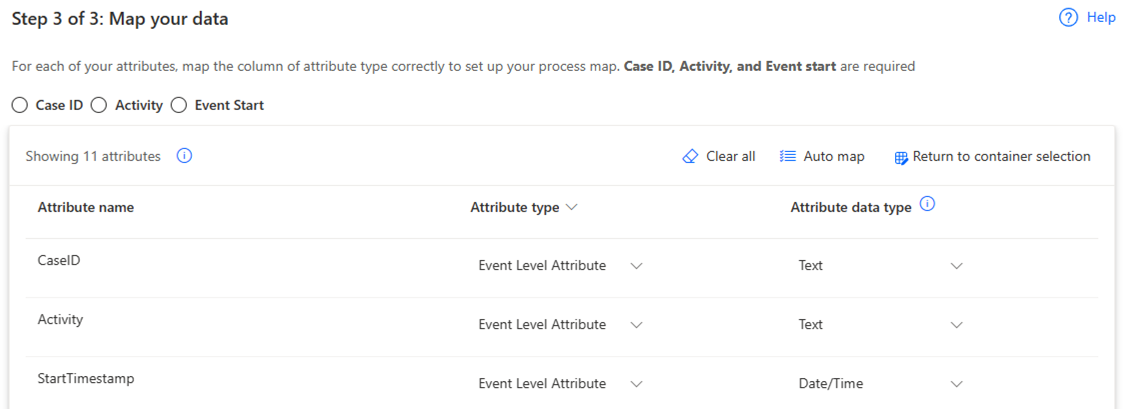
Zakończyć połączenie, wybierając przycisk Zapisz i przeanalizuj.
Określ ustawienia odświeżania przyrostowego danych
Proces z kopii danych Azure Data Lake można odświeżyć w harmonogramie, zarówno w trybie odświeżania pełnego, jak i przyrostowego. Mimo że nie istnieją zasady przechowywania, można pozykać dane, używając jednej z następujących metod:
Jeśli w poprzedniej sekcji wybrałeś pojedynczy plik, dołącz więcej danych do wybranego pliku.
Jeśli w poprzedniej sekcji wybrałeś folder, dodaj pliki przyrostowe do wybranego folderu.
Ważne
Podczas dodawania plików do wybranych folderów lub podfolderów należy upewnić się, że wskazuje się kolejność przyrostową, nazewnictwo plików nazwami takimi jak YYYMMDD.csv lub YYYYMMDDHHMMSS.csv.
Aby odświeżyć proces:
Przejdź do strony Szczegóły procesu.
Wybierz Ustawienia odświeżania.
Na ekranie Zaplanuj odświeżanie wykonaj następujące kroki:
- Włącz przełącznik Zachowuj dane na bieżąco.
- Z listy rozwijanej Odśwież dane co wybierz częstotliwość odświeżania.
- W polach Rozpocznij o wybierz datę i godzinę odświeżenia.
- Włącz przełącznik Odświeżanie przyrostowe.