Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:![]() program Power BI Desktop
program Power BI Desktop ![]() usługa Power BI
usługa Power BI
Wizualizacja kluczowych elementów mających wpływ pomaga zrozumieć czynniki, które napędzają metrykę, która Cię interesuje. Analizuje dane, klasyfikuje istotne czynniki i wyświetla je jako kluczowe elementy mające wpływ. Załóżmy na przykład, że chcesz dowiedzieć się, co wpływa na rotację pracowników, co jest również nazywane churnem. Jednym z czynników może być długość umowy o pracę, a inny czynnik może być czasem dojazdów.
Ten artykuł zawiera szczegółowy samouczek dotyczący używania wizualizacji kluczowych elementów mających wpływ w usłudze Power BI. Wyjaśniono w nim, jak skonfigurować wizualizację, interpretować jej wyniki i rozwiązywać typowe problemy. Jeśli chcesz zrozumieć, jakie czynniki wpływają na konkretne wyniki w danych — takie jak opinie klientów, sprzedaż lub inne metryki — ten przewodnik pomoże Ci uzyskać szczegółowe informacje umożliwiające podejmowanie działań przy użyciu narzędzi do analizy opartej na sztucznej inteligencji w usłudze Power BI.
Kiedy należy używać kluczowych elementów mających wpływ
Wizualizacja kluczowych elementów mających wpływ jest doskonałym wyborem, jeśli chcesz:
- Zobacz, które czynniki wpływają na analizowane metryki.
- Porównaj względne znaczenie tych czynników. Czy kontrakty krótkoterminowe wpływają na rotację bardziej niż kontrakty długoterminowe?
Funkcje wizualizacji kluczowych influencerów
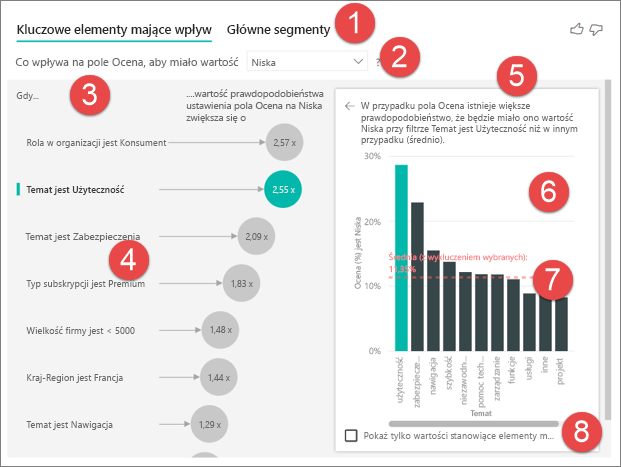
Karty: wybierz kartę i przełączaj się między widokami. Główne osoby wpływające pokazują najważniejszych kontrybutorów do wybranej wartości metryki. Najważniejsze segmenty pokazują najważniejsze segmenty , które przyczyniają się do wybranej wartości metryki. Segment składa się z kombinacji wartości. Na przykład jednym z segmentów mogą być konsumenci, którzy są długoterminowymi klientami i mieszkają w regionie zachodnim.
Pole listy rozwijanej: wartość metryki badanej. W tym przykładzie przyjrzyj się metryce Ocena. Wybrana wartość to Niska.
Restatement: ułatwia interpretowanie wizualizacji w okienku po lewej stronie.
Okienko po lewej stronie: okienko po lewej stronie zawiera jedną wizualizację. W tym przypadku w okienku po lewej stronie zostanie wyświetlona lista najważniejszych kluczowych elementów mających wpływ.
Restatement: Ułatwia interpretowanie grafiki w okienku po prawej stronie.
Okienko po prawej stronie: okienko po prawej stronie zawiera jedną wizualizację. W tym przypadku wykres kolumnowy wyświetla wszystkie wartości kluczowego motywu mającego wpływ, który został wybrany w okienku po lewej stronie. Konkretna wartość użyteczności w okienku po lewej stronie jest wyświetlana na zielono. Wszystkie pozostałe wartości motywu są wyświetlane na czarno.
Linia średnia: średnia jest obliczana dla wszystkich możliwych wartości motywu z wyjątkiem użyteczności (która jest wybranym elementem mającym wpływ). Dlatego obliczenie ma zastosowanie do wszystkich wartości w kolorze czarnym. Informuje o tym, jaki procent innych motywów miał niską ocenę. W tym przypadku 11,35% miało niską ocenę (pokazaną przez linię kropkowaną).
Pole wyboru: filtruje wizualizację w okienku po prawej stronie, aby wyświetlić tylko wartości mające wpływ dla tego pola.
Analizowanie metryki podzielonej na kategorie
- Menedżer produktu chce ustalić, które czynniki prowadzą klientów do pozostawienia negatywnych opinii na temat usługi w chmurze. Aby wykonać czynności opisane w programie Power BI Desktop, otwórz plik Opinii o Klientach PBIX.
Uwaga
Zestaw danych opinii klientów jest oparty na [Moro et al., 2014] S. Moro, P. Cortez i P. Rita. "Podejście oparte na danych do przewidywania sukcesu telemarketingu bankowego". Decision Support Systems, Elsevier, 62:22-31, czerwiec 2014.
W obszarze Kompiluj wizualizację w okienku Wizualizacje wybierz ikonę Kluczowe elementy mające wpływ .
Przenieś metrykę, którą chcesz zbadać, do pola Analizuj. Aby zobaczyć, co wpływa na niską ocenę usługi przez klientów, wybierz Tabelę klientów>Ocena.
Przenieś pola, które według Ciebie mogą mieć wpływ na ocenę w polu Wyjaśnij według . Możesz przenieść dowolną liczbę pól. W takim przypadku zacznij od:
- Kraj–region
- Rola w organizacji
- Typ subskrypcji
- Rozmiar firmy
- Motyw
Pole Rozwiń według pozostaw puste. To pole jest używane tylko podczas analizowania miary lub pola podsumowanego.
Aby skoncentrować się na ocenach negatywnych, wybierz pozycję Niski w polu listy rozwijanej Co wpływa na ocenę .
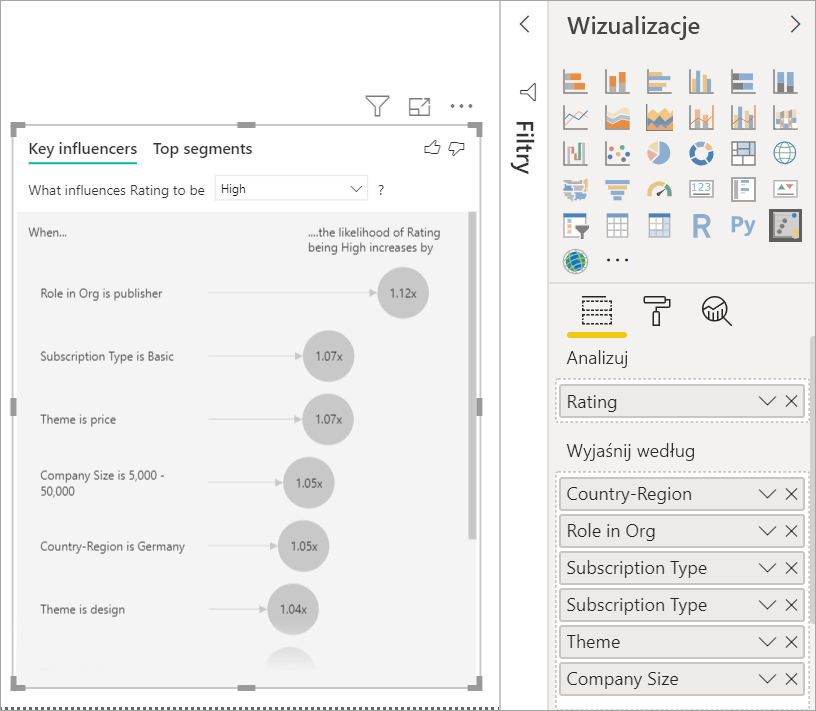
Analiza jest uruchamiana na poziomie tabeli analizowanego pola. W tym przypadku to metryka Ocena. Ta metryka jest definiowana na poziomie klienta. Każdy klient otrzymuje wysoką ocenę lub niską ocenę. Wszystkie czynniki objaśniające muszą być zdefiniowane na poziomie klienta, aby wizualizacja korzystała z nich.
W poprzednim przykładzie wszystkie czynniki objaśniające mają relację jeden do jednego lub wiele do jednego z metryką. W takim przypadku każdy klient przypisał do oceny pojedynczy motyw. Podobnie klienci pochodzą z jednego kraju lub regionu, mają jeden typ członkostwa i posiadają jedną rolę w swojej organizacji. Czynniki objaśniające są już atrybutami klienta i nie są potrzebne żadne przekształcenia. Grafika może z nich korzystać natychmiast.
W dalszej części samouczka przyjrzysz się bardziej złożonym przykładom, które mają relacje jeden do wielu. W takich przypadkach kolumny muszą zostać najpierw zagregowane w dół do poziomu klienta, zanim będzie można uruchomić analizę.
Miary oraz agregaty używane jako czynniki objaśniające podlegają również ocenie na poziomie tabeli metryki Analizuj. Niektóre przykłady przedstawiono w dalszej części tego artykułu.
Interpretowanie kluczowych elementów mających wpływ na kategorie
Przyjrzyjmy się kluczowym elementom mającym wpływ dla niskich ocen.
Najważniejszy pojedynczy czynnik wpływający na prawdopodobieństwo niskiej oceny
Klient w tym przykładzie może mieć jedną z trzech ról: konsumenta, administratora lub wydawcy. Bycie konsumentem jest głównym czynnikiem, który przyczynia się do niskiej oceny.
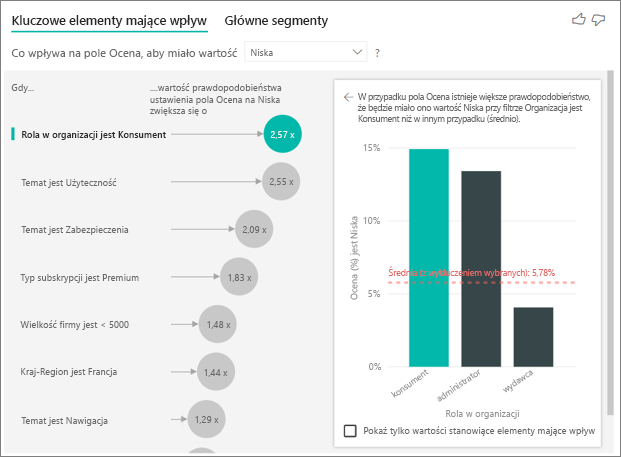
Dokładniej mówiąc, użytkownicy są 2,57 razy bardziej skłonni do nadania usłudze negatywnego wyniku. Wykres kluczowych elementów mających wpływ wymienia rolę konsumenta w organizacji jako pierwszą na liście po lewej stronie. Wybierając pozycję Rola w organizacji to konsument, usługa Power BI wyświetla więcej szczegółów w okienku po prawej stronie. Pokazano porównawczy wpływ każdej roli na prawdopodobieństwo niskiej oceny.
- 14,93% konsumentów daje niski wynik.
- Średnio wszystkie inne role w 5,78% przypadków dają niską ocenę.
- Konsumenci są 2,57 razy bardziej skłonni do wystawienia niskiej oceny w porównaniu do wszystkich innych ról. Ten wynik można określić, dzieląc zielony pasek przez czerwoną linię kropkowaną.
Drugi pojedynczy czynnik, który wpływa na prawdopodobieństwo niskiej oceny
Wizualizacja kluczowych elementów mających wpływ porównuje i klasyfikuje czynniki z wielu różnych zmiennych. Drugi wpływowy czynnik nie ma nic wspólnego z rolą w organizacji. Wybierz drugi wpływowy czynnik na liście, czyli temat to użyteczność.
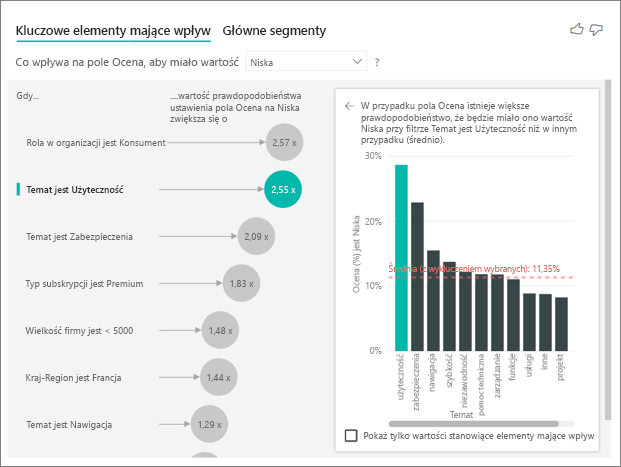
Drugim najważniejszym czynnikiem jest czynnik dotyczący tematu opinii klienta. Klienci, którzy skomentowali użyteczność produktu, byli 2,55 razy bardziej skłonni do uzyskania niskiej oceny w porównaniu do klientów, którzy skomentowali inne tematy, takie jak niezawodność, projektowanie lub szybkość.
Między wizualizacjami średnia, która jest wyświetlana przez czerwoną linię kropkowaną, zmieniła się z 5,78% na 11,35%. Średnia jest dynamiczna, ponieważ jest oparta na średniej wszystkich innych wartości. Dla pierwszego elementu mającego wpływ średnia wykluczyła rolę klienta. W przypadku drugiego influencera pominięto motyw użyteczności.
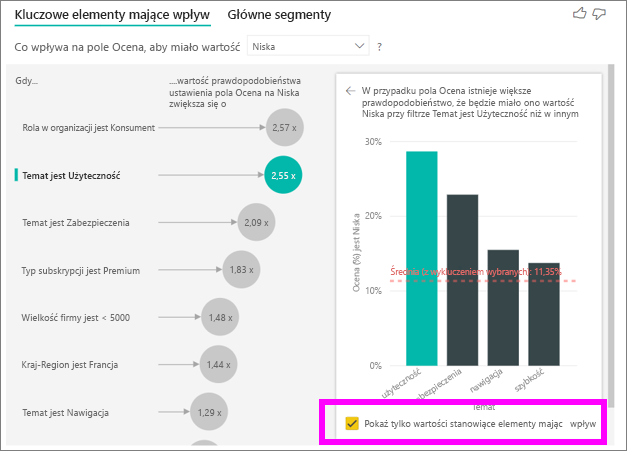
Zaznacz pole wyboru Pokaż tylko wartości, które mają wpływ, aby filtrować dane tylko przy użyciu wartości wpływowych. W takim przypadku są to role, które prowadzą do niskiego wyniku. 12 motywów jest zredukowanych do czterech, które usługa Power BI zidentyfikowała jako motywy, które napędzają niskie oceny.
Interakcja z innymi wizualizacjami
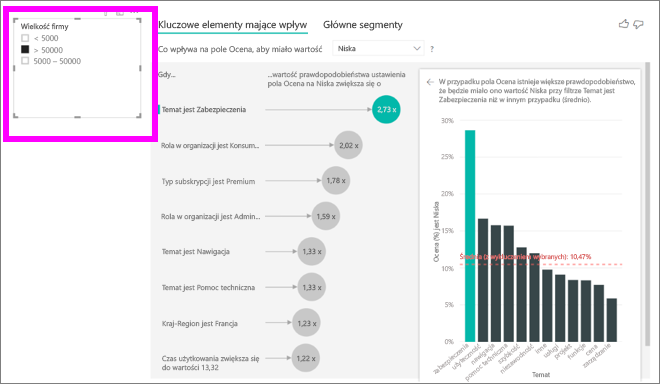
Za każdym razem, gdy wybierzesz fragmentator, filtr lub inną wizualizację na kanwie, wizualizacja kluczowych elementów mających wpływ ponownie uruchomi analizę nowej części danych. Możesz na przykład przenieść wielkość firmy do raportu i użyć go jako filtr. Użyj go, aby sprawdzić, czy kluczowe elementy mające wpływ dla klientów korporacyjnych różnią się od ogólnej populacji. Wielkość przedsiębiorstwa jest większa niż 50 000 pracowników.
Wybierz >50 000 , aby ponownie uruchomić analizę i zobaczysz, że elementy mające wpływ uległy zmianie. W przypadku dużych klientów korporacyjnych głównym elementem mającym wpływ na niską ocenę jest temat związany z zabezpieczeniami. Warto rozważyć dokładniejsze zbadanie, czy istnieją konkretne funkcje zabezpieczeń, z których niezadowoleni są Wasi duzi klienci.
Interpretacja nieustannych kluczowych czynników wpływowych
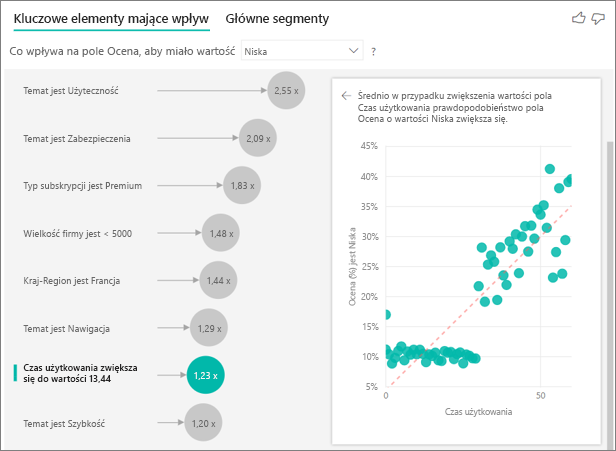
Do tej pory pokazano, jak za pomocą wizualizacji dowiedzieć się, jak różne pola podzielone na kategorie wpływają na niskie oceny. Istnieje również możliwość posiadania ciągłych czynników, takich jak wiek, wzrost i cena w polu Wyjaśnij według . Przyjrzyjmy się, co się stanie, gdy staż pracy zostanie przeniesiony z Tabeli Klientów do obszaru Wyjaśnij według. Czas użytkowania przedstawia, jak długo klient korzysta z usługi.
W miarę zwiększania się czasu użytkowania prawdopodobieństwo otrzymania niższej oceny również wzrasta. Ten trend sugeruje, że długoterminowi klienci są bardziej skłonni do uzyskania negatywnego wyniku. Ta analiza jest interesująca i warto kontynuować później.
Wizualizacja pokazuje, że za każdym razem, gdy czas użytkowania wzrasta o 13,44 miesięcy, średnio prawdopodobieństwo niskiej oceny zwiększa się o 1,23 razy. W tym przypadku 13,44 miesięcy przedstawia odchylenie standardowe kadencji. Dokładna analiza, którą otrzymujesz, bada, jak zwiększenie stażu pracy o standardową wartość, która jest odchyleniem standardowym stażu, wpływa na prawdopodobieństwo otrzymania niskiej oceny.
Wykres punktowy w okienku po prawej stronie przedstawia średni procent niskich ocen dla każdej wartości stażu pracy. Podkreśla nachylenie za pomocą linii trendu.
Zgrupowane ciągłe główne czynniki wpływające
W niektórych przypadkach może się okazać, że czynniki ciągłe zostały automatycznie przekształcone w kategorie. Jeśli relacja między zmiennymi nie jest liniowa, nie możemy opisać relacji jako po prostu rosnącej lub malejącej (tak jak w poprzednim przykładzie).
Uruchamiamy testy korelacji, aby określić, jak liniowy element mający wpływ jest porównywany z elementem docelowym. Jeśli element docelowy jest ciągły, uruchamiamy korelację Pearson; jeśli element docelowy jest podzielony na kategorie, uruchamiamy testy korelacji punktów biserycznych. Jeśli wykryjemy, że relacja nie jest wystarczająco liniowa, przeprowadzamy nadzorowane kwantowanie i generujemy maksymalnie pięć pojemników. Aby dowiedzieć się, które pojemniki mają najwięcej sensu, użyjemy nadzorowanej metody kwantowania. Nadzorowana metoda kwantowania analizuje relację między czynnikiem objaśniającym a analizowanym elementem docelowym.
Interpretowanie miar i agregacji jako kluczowych elementów mających wpływ
Miary i agregacje można używać jako czynników objaśniających wewnątrz analizy. Na przykład jaki wpływ ma liczba wniosków do działu obsługi klienta na otrzymany wynik. Lub jaki wpływ ma średni czas trwania otwartego biletu na otrzymany wynik.
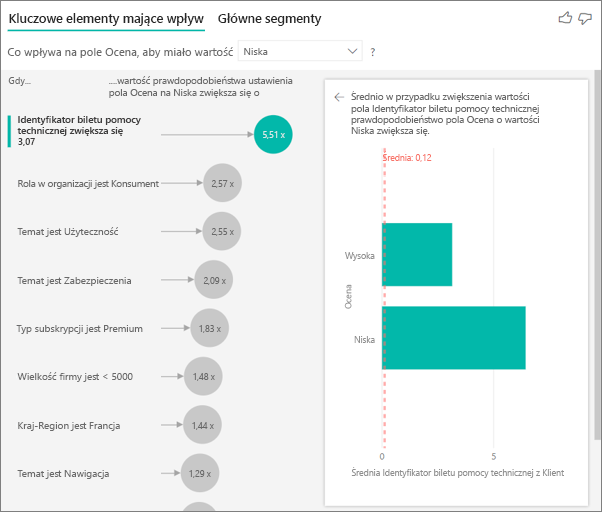
W tym przypadku chcesz sprawdzić, czy liczba biletów wsparcia technicznego, jaką ma klient, wpływa na ocenę, którą przyznaje. Teraz wprowadzasz ID zgłoszenia do pomocy technicznej z tabeli Zgłoszenia do pomocy technicznej. Ponieważ klient może mieć wiele zgłoszeń do wsparcia technicznego, należy zagregować ID na poziomie klienta. Agregacja jest ważna, ponieważ analiza jest uruchamiana na poziomie klienta, dlatego wszystkie sterowniki muszą być zdefiniowane na tym poziomie szczegółowości.
Przyjrzyjmy się liczbie identyfikatorów. W każdym wierszu klienta znajduje się skojarzona liczba zgłoszeń do działu wsparcia. W takim przypadku, w miarę wzrostu liczby biletów pomocy technicznej, prawdopodobieństwo niskiej oceny wzrasta o 4,08 razy. Zrzut ekranu przedstawia średnią liczbę zgłoszeń do pomocy technicznej według różnych wartości klasyfikacji ocenianych na poziomie klienta.
Interpretowanie wyników: najważniejsze segmenty
Możesz użyć karty Kluczowi influencerzy, aby ocenić każdy czynnik indywidualnie. Możesz również użyć karty Najważniejsze segmenty , aby zobaczyć, jak kombinacja czynników wpływa na analizną metrykę.
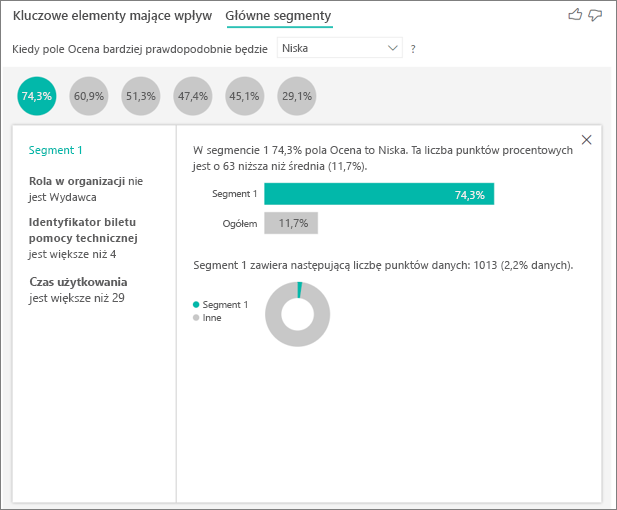
Pierwsze segmenty początkowo przedstawiają przegląd wszystkich segmentów odnalezionych przez usługę Power BI. W poniższym przykładzie pokazano, że znaleziono sześć segmentów. Procent niskich ocen w segmencie określa klasyfikację. Na przykład segment 1 ma 74,3% ocen klientów, które są niskie. Im wyższy bąbelek, tym wyższy odsetek niskich ocen. Rozmiar bąbelka reprezentuje liczbę klientów w segmencie.
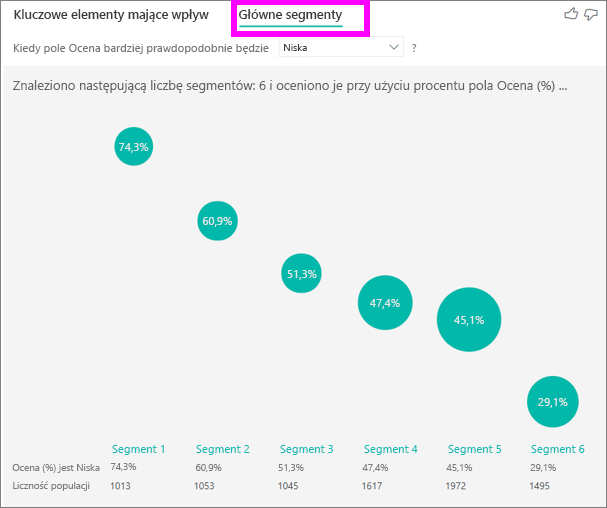
Wybranie bąbelka powoduje wyświetlenie szczegółów tego segmentu. Jeśli na przykład wybierzesz segment 1, okaże się, że reprezentuje on ustanowionych klientów. Byli klientami od ponad 29 miesięcy i mają więcej niż cztery zgłoszenia do pomocy technicznej. Na koniec nie są wydawcami, więc są konsumentami lub administratorami.
W tej grupie 74,3% klientów wystawiło niską ocenę. Średni klient wystawił niską ocenę 11,7% czasu, więc ten segment ma większy odsetek niskich ocen. Jest to 63 punkty procentowe wyższe. Segment 1 zawiera również około 2,2% danych, co oznacza, że reprezentuje adresowalną część populacji.
Dodawanie liczby
Czasami element mający wpływ może mieć znaczący wpływ, ale reprezentuje niewiele danych. Na przykład, w przypadku tematu, użyteczność jest trzecim największym czynnikiem wpływającym na niskie oceny. Jednak może istnieć tylko garstka klientów, którzy skarżyli się na użyteczność. Liczby mogą pomóc w określaniu priorytetów elementów mających wpływ, na których chcesz się skupić.
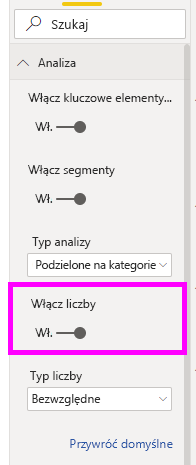
Licznik można włączyć za pomocą karty Analiza okienka widoku Format.
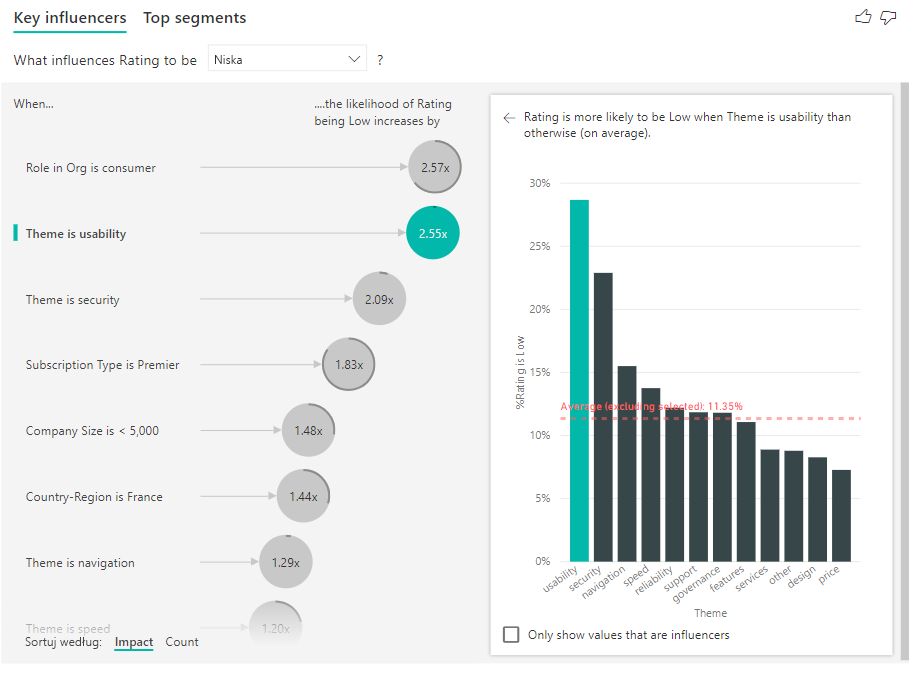
Po włączeniu liczników zobaczysz pierścień wokół bąbelka każdego influencera, który reprezentuje przybliżony procent danych, które zawiera influencer. Więcej bąbelków pierścienia, tym więcej danych zawiera. Widzimy, że temat użyteczność zawiera niewielką część danych.
Możesz również użyć przełącznika Sortuj według w lewym dolnym rogu wizualizacji, aby posortować bąbelki według liczby zamiast wpływu. Typ subskrypcji to Premier jest głównym elementem mającym wpływ na podstawie liczby.
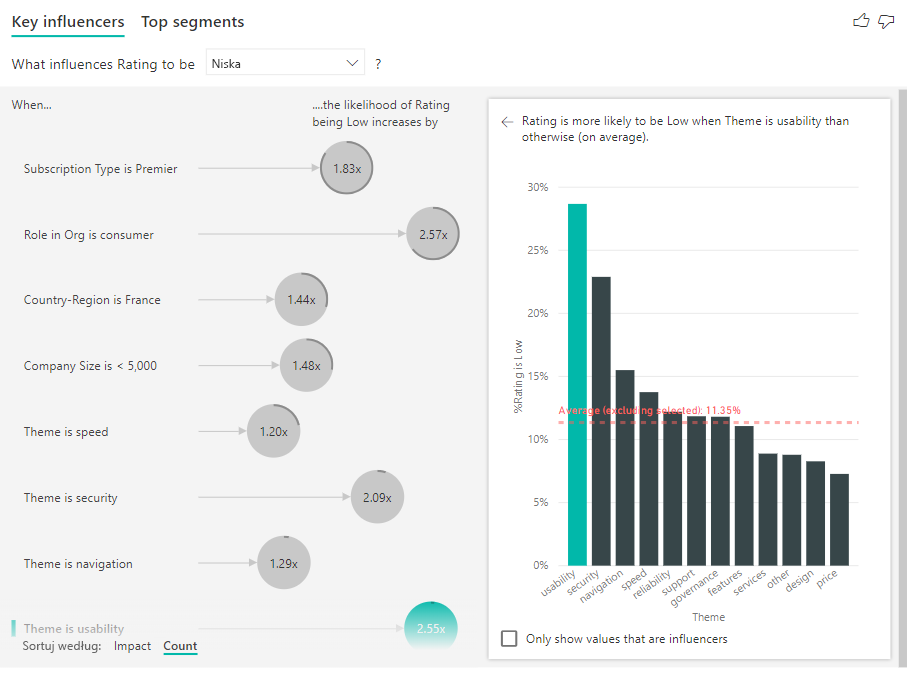
Posiadanie pełnego pierścienia wokół okręgu oznacza, że element mający wpływ zawiera 100% danych. Możesz zmienić typ licznika na względny względem maksymalnego wpływu, korzystając z listy rozwijanej Typ licznika na Karcie analizy okienka wizualizacji Format. Teraz influencer z największą ilością danych jest reprezentowany przez pełny pierścień, a wszystkie inne liczby są względem niego porównywane.
Analizowanie metryki, która jest liczbowa
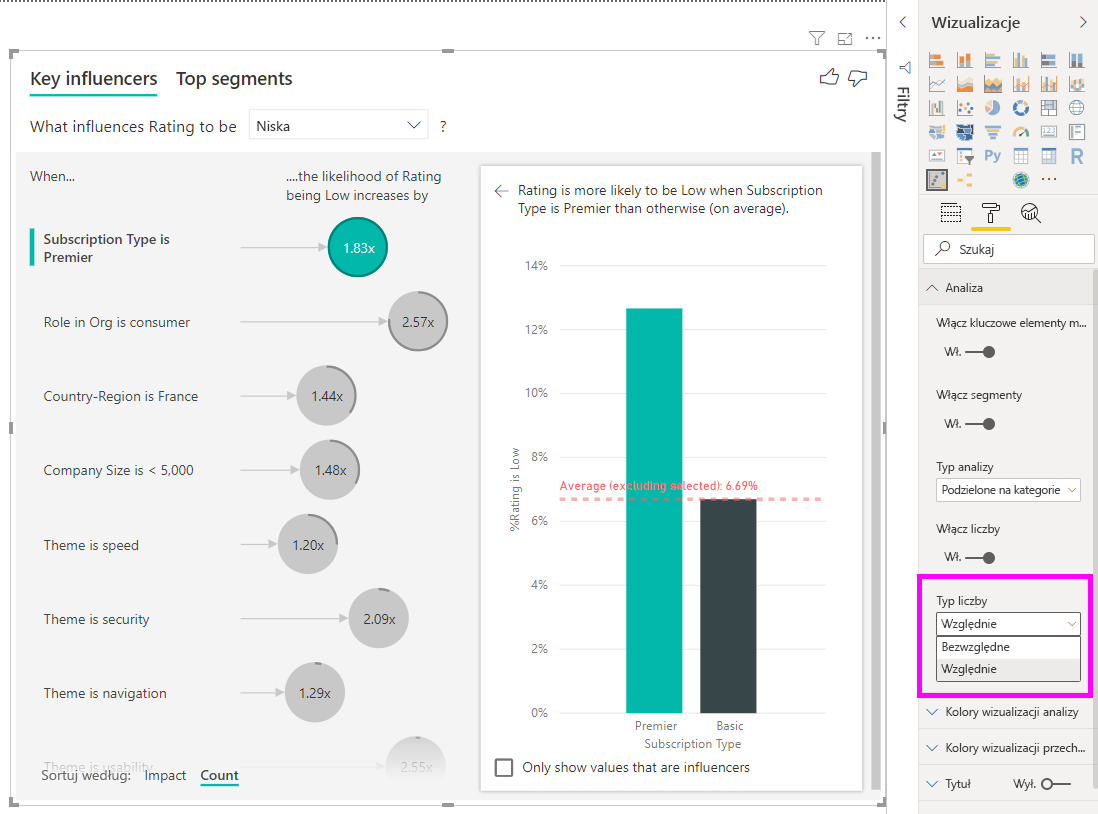
Jeśli przeniesiesz niesumaryzowane pole liczbowe do pola Analizuj , możesz wybrać sposób obsługi tego scenariusza. Zachowanie wizualizacji można zmienić, przechodząc do okienka Wizualizacja Format i przełączając się między typem analizy kategorialnej a typem analizy ciągłej.
Typ analizy podzielonej na kategorie został opisany wcześniej w tym artykule. Na przykład jeśli spojrzysz na wyniki ankiety z zakresu od 1 do 10, możesz zapytać "Co wpływa na wyniki ankiety 1?"
Typ analizy ciągłej zmienia pytanie na ciągłe. W poprzednim przykładzie naszym nowym pytaniem jest "Co wpływa na to, że wyniki ankiety rosną/maleją?"
To rozróżnienie jest przydatne, gdy masz wiele unikatowych wartości w analizowym polu. W następnym przykładzie przyjrzymy się cenom domów. Nie ma sensu pytać "Co wpływa na cenę domu wynoszącą 156,214?", ponieważ jest to specyficzne i prawdopodobnie nie mamy wystarczających danych, aby wywnioskować wzorzec.
Zamiast tego możemy chcieć zapytać: "Co wpływa na wzrost ceny domu", co pozwala nam traktować ceny domów jako zakres, a nie odrębne wartości.
Interpretowanie wyników: Kluczowe elementy mające wpływ
Uwaga
Przykłady w tej sekcji korzystają z danych dotyczących cen domu w domenie publicznej. Jeśli chcesz kontynuować, możesz pobrać przykładowy zestaw danych .
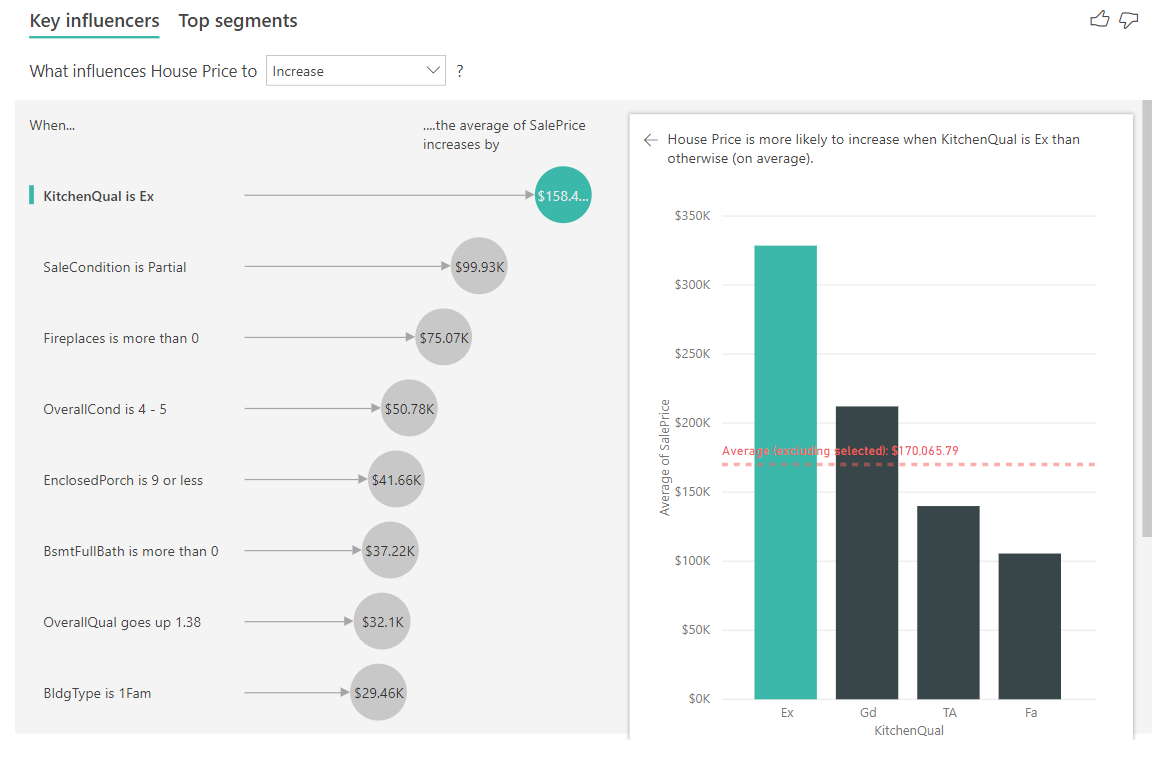
W tym scenariuszu przyjrzymy się "Co wpływa na wzrost ceny domu". Wiele czynników objaśniających może mieć wpływ na cenę domu, takich jak Year Built (rok, w której został zbudowany dom), KitchenQual (jakość kuchni) i YearRemodAdd (rok, w których dom został przebudowany).
W poniższym przykładzie przyjrzymy się naszemu głównemu elementowi wpływu, którym jest doskonała jakość kuchni. Wyniki są podobne do tych, które widzieliśmy podczas analizowania metryk kategorii z kilkoma ważnymi różnicami:
- Wykres kolumnowy po prawej stronie analizuje średnie, a nie wartości procentowe. Dlatego pokazuje nam, jaka jest średnia cena domu z doskonałą kuchnią (zielony pasek) w porównaniu do średniej ceny domu bez doskonałej kuchni (linia przerywana).
- Liczba w bąbelku jest nadal różnicą między czerwoną linią kropkowaną a zielonym paskiem, ale jest wyrażona jako liczba (\$158,49K), a nie prawdopodobieństwo (1,93x). Więc średnio domy z doskonałymi kuchniami są prawie \$160K droższe niż domy bez doskonałych kuchni.
W następnym przykładzie przyjrzymy się wpływowi ciągłego czynnika, jakim jest rok przebudowy domu, na cenę domu. Różnice w porównaniu z analizą ciągłych elementów mających wpływ dla metryk kategorii są następujące:
- Wykres punktowy w okienku po prawej stronie wykreśla średnią cenę domu dla każdego indywidualnego roku przebudowy.
- Wartość w bąbelku pokazuje, o ile wzrasta średnia cena domu (w tym przypadku 2,87 tys. USD), kiedy rok przebudowy domu zwiększa się o jedno odchylenie standardowe (w tym przypadku 20 lat).
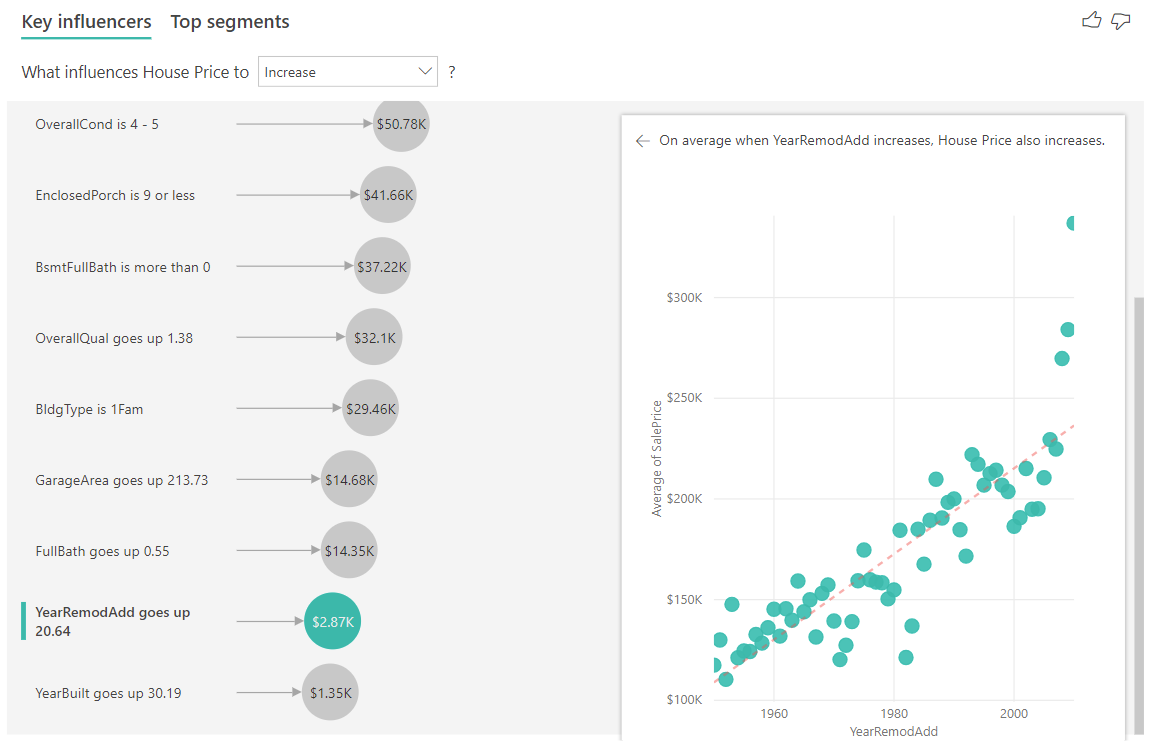
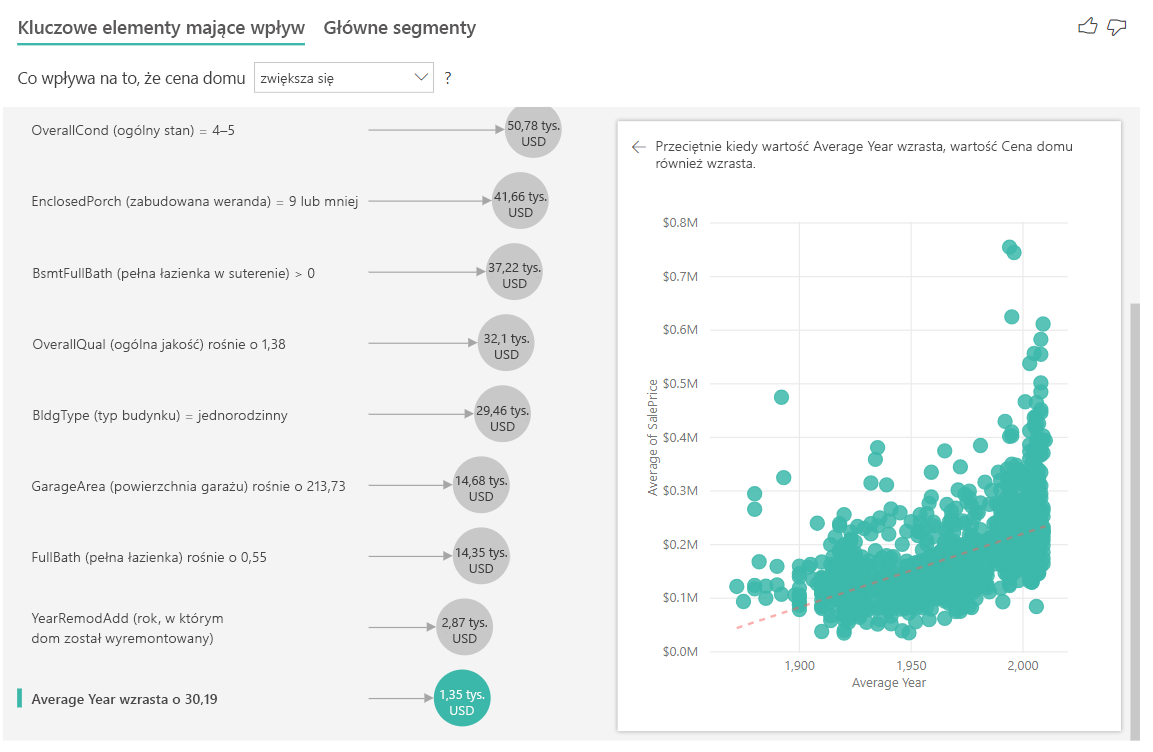
Na koniec, w przypadku miar, patrzymy na średni rok budowy domu. Analiza jest następująca:
- Wykres punktowy w okienku po prawej stronie kreśli średnią cenę domu dla każdej odrębnej wartości w tabeli.
- Wartość w bąbelku pokazuje, o ile wzrasta średnia cena domu (w tym przypadku 1,35 tys. zł), gdy średnia liczba lat wzrasta o jej odchylenie standardowe (w tym przypadku 30 lat).
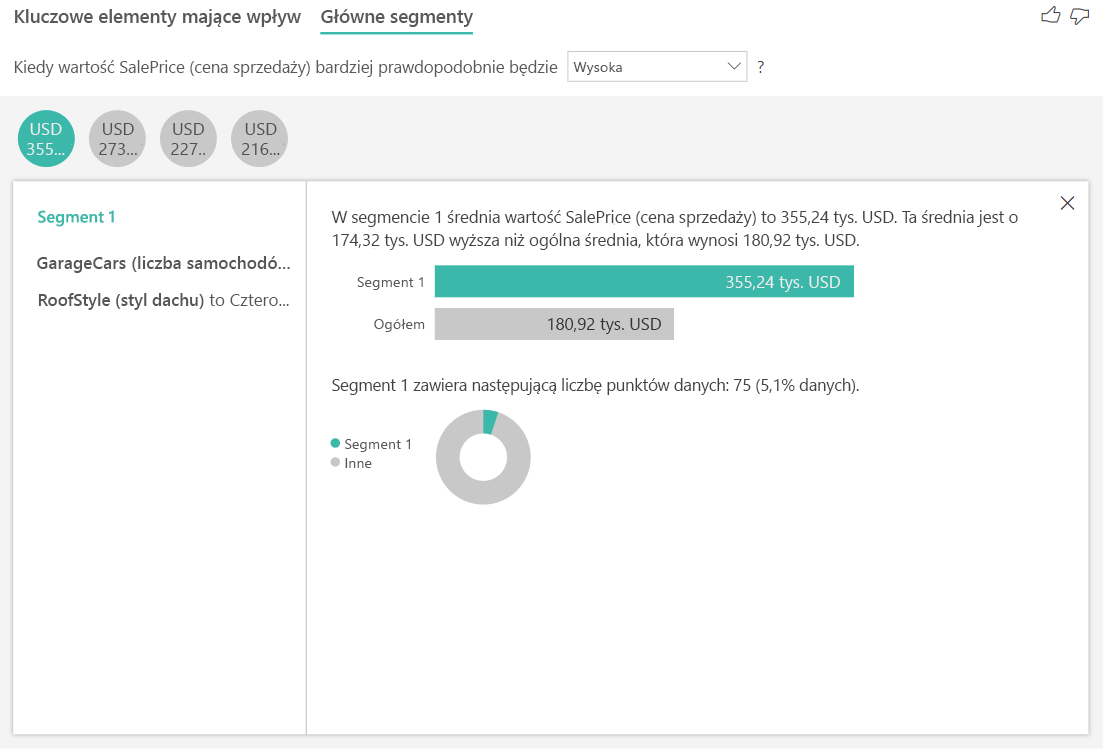
Interpretowanie wyników przy użyciu najważniejszych segmentów
Najważniejsze segmenty dla celów liczbowych pokazują grupy, w których średnie ceny domów są wyższe niż w ogólnym zestawie danych. Na przykład poniżej widać, że segment 1 składa się z domów, w których GarażCars (liczba samochodów, które może zmieścić się w garażu) jest większa niż 2, a RoofStyle to Hip. Domy o tych cechach mają średnią cenę \$355K w porównaniu do ogólnej średniej w danych, czyli \$180K.
Analizowanie metryki, która jest miarą lub kolumną podsumowaną
W przypadku miary lub kolumny podsumowanej analiza jest domyślnie ustawiona na typ analizy ciągłej opisany wcześniej w tym artykule. Nie można tego zmienić. Największą różnicą między analizowaniem kolumny miary/podsumowania a niesumaryzowaną kolumną liczbową jest poziom, na którym jest uruchamiana analiza.
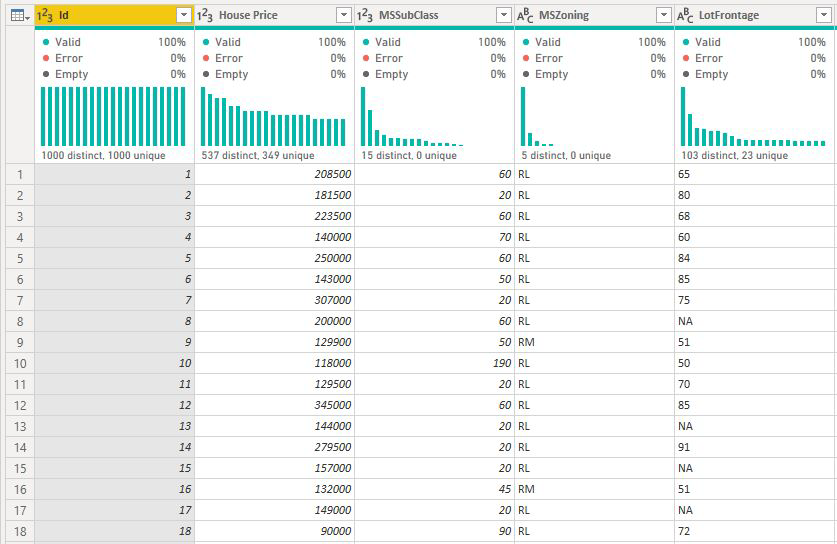
W przypadku kolumn niesumowanych analiza zawsze odbywa się na poziomie tabeli. W przykładzie ceny domu przeanalizowaliśmy metrykę ceny domu, aby zobaczyć, co wpływa na wzrost/spadek ceny domu. Analiza jest uruchamiana automatycznie na poziomie tabeli. Nasza tabela ma unikatowy identyfikator dla każdego domu, więc analiza jest uruchamiana na poziomie domu.
W przypadku miar i podsumowanych kolumn nie wiemy od razu, na jakim poziomie należy je analizować. Jeśli cena domu została podsumowana jako średnia, musimy rozważyć, jaki poziom chcielibyśmy obliczyć tę średnią cenę domu. Czy jest to średnia cena domu na poziomie sąsiedztwa? A może na poziomie regionalnym?
Miary i kolumny podsumowane są automatycznie analizowane na poziomie używanego pola Wyjaśnij według . Wyobraź sobie, że chcemy zbadać trzy pola w obszarze Wyjaśnij według: Jakość kuchni, Typ budynku i Klimatyzacja. Średnia cena domu zostanie obliczona dla każdej unikatowej kombinacji tych trzech pól. Często warto przełączyć się do widoku tabeli, aby zobaczyć, jak wyglądają oceniane dane.
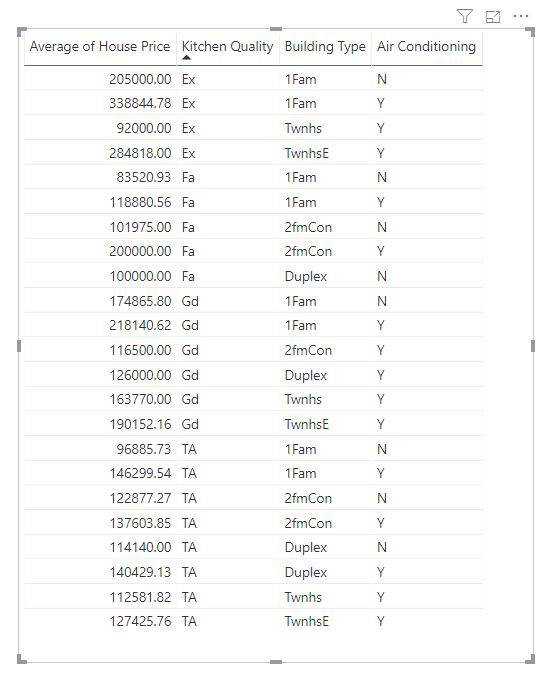
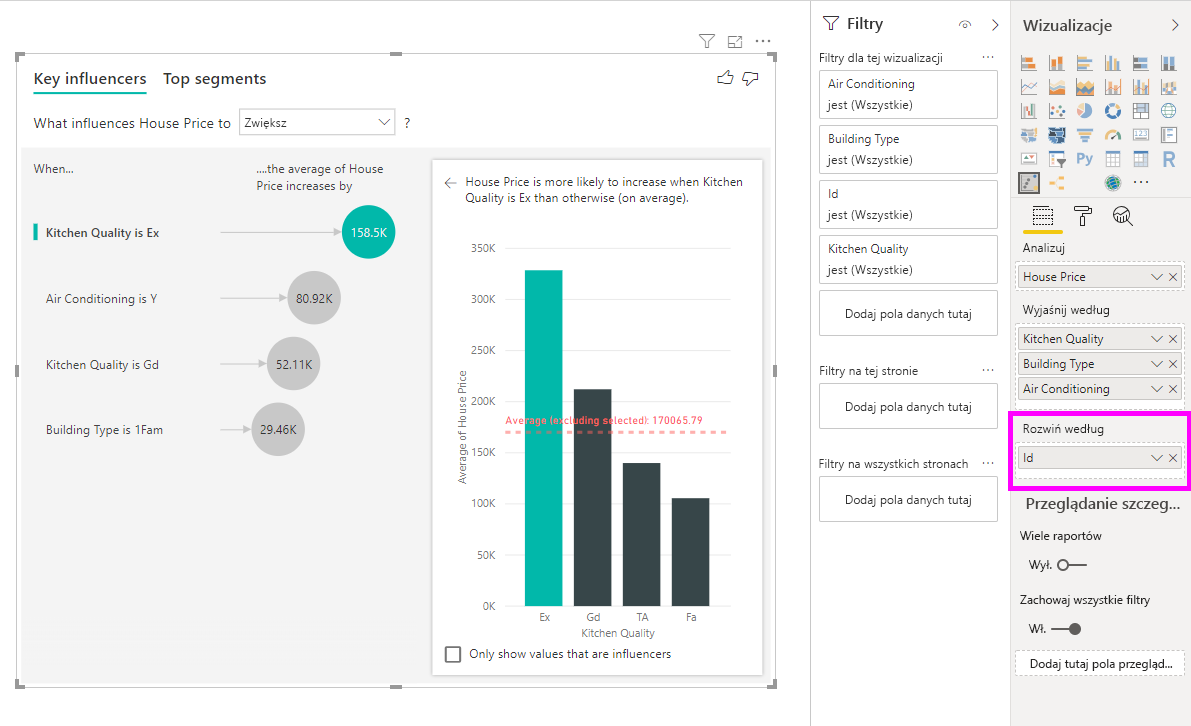
Analiza ta jest bardzo skrótowa, więc modelowi regresji może być trudno znaleźć jakiekolwiek wzorce w danych, z których mógłby się uczyć. Powinniśmy uruchomić analizę na bardziej szczegółowym poziomie, aby uzyskać lepsze wyniki. Jeśli chcielibyśmy przeanalizować cenę na poziomie domu, musielibyśmy jawnie dodać pole ID do analizy. Niemniej jednak nie chcemy, aby identyfikator domu był traktowany jako element mający wpływ. Nie przynosi korzyści wiedzieć, że kiedy identyfikator nieruchomości rośnie, cena domu wzrasta. Opcja Rozwiń według pola przydaje się tutaj. Możesz użyć polecenia Rozwiń według , aby dodać pola, których chcesz użyć do ustawiania poziomu analizy bez wyszukiwania nowych elementów mających wpływ.
Zobacz, jak wygląda wizualizacja, gdy dodamy ID do Rozwiń według. Po zdefiniowaniu poziomu, na którym miara ma zostać obliczona, interpretacja elementów mających wpływ jest dokładnie taka sama jak w przypadku kolumn liczbowych bez zasumowania.
Aby dowiedzieć się, jak usługa Power BI używa ML.NET za kulisami do wnioskowania o danych i uzyskiwaniu wglądu w szczegółowe dane w naturalny sposób, zobacz Usługa Power BI identyfikuje kluczowe elementy mające wpływ przy użyciu ML.NET.
Zagadnienia i rozwiązywanie problemów
Jakie są ograniczenia dotyczące wizualizacji?
Wizualizacja kluczowych elementów mających wpływ ma pewne ograniczenia:
- Zapytanie bezpośrednie nie jest obsługiwane.
- Połączenie na żywo z usługami Azure Analysis Services i SQL Server Analysis Services nie jest obsługiwane.
- Publikowanie w internecie nie jest obsługiwane.
- Wymagany jest program .NET Framework 4.6 lub nowszy.
- Osadzanie w usłudze SharePoint Online nie jest obsługiwane.
- Analizowanie metryki, która jest kategoryczna, nie jest obsługiwane, jeśli dla modelu danych ustawiono Nie wspieraj miar niejawnych na true (na przykład, gdy w modelu danych zdefiniowane są grupy obliczeniowe).
Widzę błąd, że nie znaleziono żadnych influencerów ani segmentów. Dlaczego?
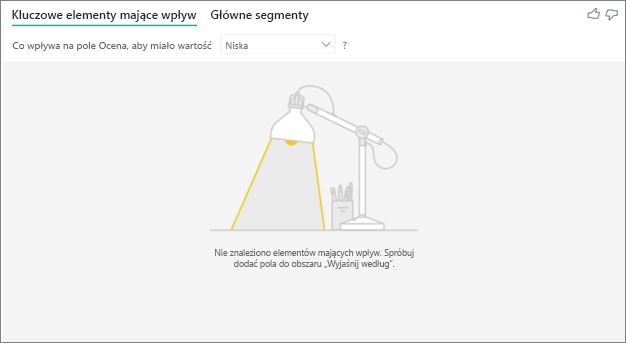
Ten błąd występuje, gdy uwzględniono pola w Wyjaśnij według, ale nie znaleziono żadnych wpływowych elementów. Sprawdź, czy któryś z następujących problemów może mieć zastosowanie.
- Metryka, którą analizowano, została uwzględniona zarówno w obszarze Analizuj, jak i Wyjaśnij według. Usuń to z Explain by.
- Pola objaśniające mają zbyt wiele kategorii, które mają tylko kilka obserwacji. Ta sytuacja utrudnia wizualizacji ustalenie, które czynniki mają wpływ. Trudno uogólnić tylko kilka obserwacji. Jeśli analizujesz pole liczbowe, możesz przełączyć się z analizy kategorialnej na analizę ciągłą w okienku wizualizacji Format na karcie Analiza.
- Czynniki objaśniające mają wystarczającą liczbę obserwacji do uogólnienia, ale wizualizacja nie znalazła żadnych istotnych korelacji do raportowania.
Widzę błąd, że metryka, którą analizuję, nie ma wystarczającej ilości danych, aby przeprowadzić analizę. Dlaczego?

Wizualizacja działa, przeglądając wzorce w danych dla jednej grupy w porównaniu z innymi grupami. Na przykład szuka klientów, którzy wystawili niskie oceny w porównaniu z klientami, którzy wystawili wysokie oceny. Jeśli dane w modelu mają tylko kilka obserwacji, wzorce są trudne do znalezienia. Jeśli wizualizacja nie ma wystarczającej ilości danych do znalezienia znaczących elementów mających wpływ, oznacza to, że do uruchomienia analizy jest potrzebnych więcej danych.
Zalecamy wykonanie co najmniej 100 obserwacji dla wybranego stanu. W tym przypadku stanem są klienci, którzy odchodzą. Potrzebujesz również co najmniej 10 obserwacji dla stanów używanych do porównania. W tym przypadku stan porównania to klienci, którzy nie rezygnują z usług.
Jeśli analizujesz pole liczbowe, możesz przełączyć się z analizy kategorialnej na analizę ciągłą w okienku wizualizacji Format na karcie Analiza.
Zauważyłem błąd, że gdy "Analiza" nie jest podsumowana, analiza zawsze odbywa się na poziomie wiersza tabeli nadrzędnej. Zmiana tego poziomu za pomocą pól "Rozwiń według" jest niedozwolona. Dlaczego?
Podczas analizowania kolumny liczbowej lub podzielonej na kategorie analiza zawsze jest uruchamiana na poziomie tabeli. Jeśli na przykład analizujesz ceny domów, a tabela zawiera kolumnę ID, analiza jest uruchamiana automatycznie na poziomie identyfikatora domu.
Podczas analizowania miary lub kolumny podsumowanej musisz jawnie stwierdzić, na jakim poziomie chcesz, aby analiza została uruchomiona. Możesz użyć polecenia Rozwiń według aby zmienić poziom analizy miar i podsumowanych kolumn bez dodawania nowych wpływających czynników. Jeśli Cena domu została zdefiniowana jako miara, możesz dodać kolumnę identyfikatora domu w sekcji Rozwiń wg, aby zmienić poziom analizy.
Widzę błąd, że pole w Explain by nie jest jednoznacznie powiązane z tabelą zawierającą analizowaną metrykę. Dlaczego?
Analiza jest uruchamiana na poziomie tabeli analizowanego pola. Na przykład w przypadku analizowania opinii klientów dotyczących usługi może istnieć tabela, która informuje, czy klient wystawił wysoką ocenę, czy niską ocenę. W takim przypadku analiza jest przeprowadzana na poziomie tabeli klientów.
Jeśli masz powiązaną tabelę zdefiniowaną na bardziej szczegółowym poziomie niż tabela zawierająca metrykę, zostanie wyświetlony ten błąd. Oto przykład:
- Analizujesz, co wpływa na to, że klienci mają niskie oceny usługi.
- Chcesz sprawdzić, czy urządzenie, na którym klient korzysta z twojej usługi, wpływa na podane recenzje.
- Klient może korzystać z usługi na wiele różnych sposobów.
- W poniższym przykładzie klient 10000000 używa przeglądarki i tabletu do interakcji z usługą.
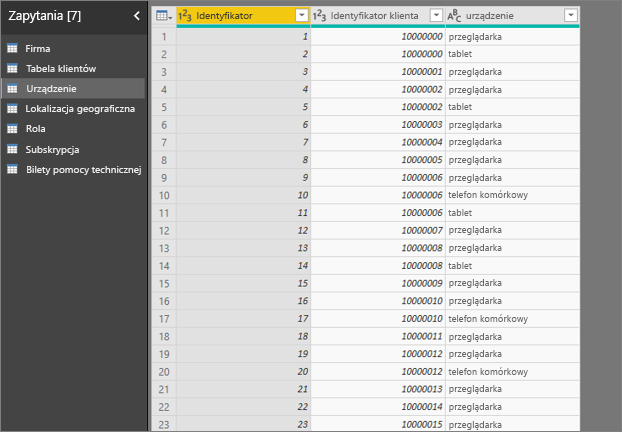
Jeśli spróbujesz użyć kolumny urządzenia jako czynnik objaśniający, zostanie wyświetlony następujący błąd:

Ten błąd pojawia się, ponieważ urządzenie nie jest zdefiniowane na poziomie klienta. Jeden klient może korzystać z usługi na wielu urządzeniach. Aby wizualizacja znalazła wzorce, urządzenie musi być atrybutem klienta. Istnieje kilka rozwiązań, które zależą od zrozumienia firmy:
- Możesz zmienić podsumowanie urządzeń na ich zliczanie. Na przykład użyj liczby, jeśli liczba urządzeń może mieć wpływ na ocenę, którą podaje klient.
- Możesz przestawić kolumnę urządzenia, aby sprawdzić, czy korzystanie z usługi na określonym urządzeniu wpływa na ocenę klienta.
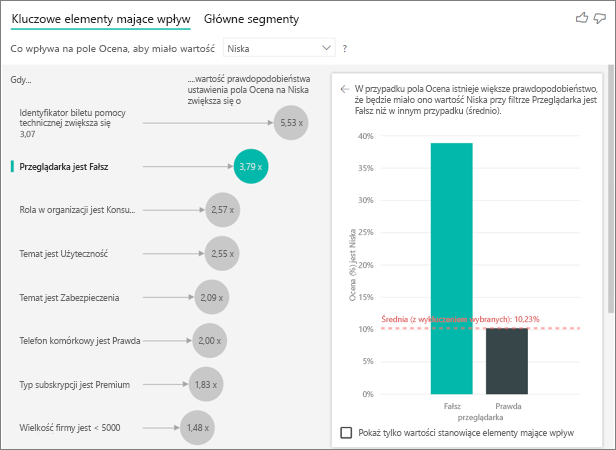
W tym przykładzie dane zostały przestawione w celu utworzenia nowych kolumn dla przeglądarki, urządzenia przenośnego i tabletów (upewnij się, że usuniesz i ponownie utworzysz relacje w widoku modelowania po przestawieniu danych). Teraz możesz używać tych konkretnych urządzeń w Explain by. Wszystkie urządzenia okazują się elementami mającymi wpływ, a przeglądarka ma największy wpływ na ocenę klienta.
Dokładniej mówiąc, klienci, którzy nie korzystają z przeglądarki do korzystania z usługi, są 3,79 razy bardziej skłonni do uzyskania niskiej oceny niż klienci, którzy to robią. W dolnej części listy odwrotność jest prawdziwa dla urządzeń przenośnych. Klienci korzystający z aplikacji mobilnej są bardziej skłonni do uzyskania niskiej oceny niż klienci, którzy tego nie robią.
Widzę ostrzeżenie, że miary nie zostały uwzględnione w mojej analizie. Dlaczego?
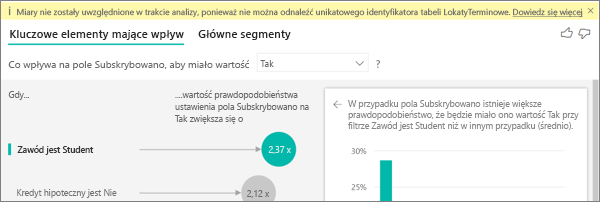
Analiza jest uruchamiana na poziomie tabeli analizowanego pola. Jeśli analizujesz rezygnację klientów, możesz mieć tabelę, która informuje o tym, czy klient zrezygnował, czy nie. W takim przypadku analiza jest uruchamiana na poziomie tabeli klienta.
Domyślnie miary i agregacje są domyślnie analizowane na poziomie tabeli. Gdyby istniała miara średnich miesięcznych wydatków, byłaby analizowana na poziomie tabeli klientów.
Jeśli tabela klienta nie ma unikatowego identyfikatora, nie możesz ocenić miary i jest ona ignorowana przez analizę. Aby uniknąć tej sytuacji, upewnij się, że tabela z metryką ma unikatowy identyfikator. W takim przypadku jest to tabela klienta, a unikatowy identyfikator to ID klienta. Można również łatwo dodać kolumnę indeksu przy użyciu dodatku Power Query.
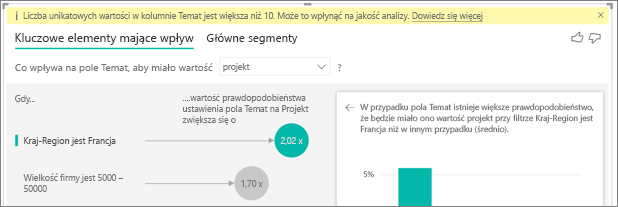
Widzę ostrzeżenie, że analizna metryka ma więcej niż 10 unikatowych wartości i że ta kwota może mieć wpływ na jakość mojej analizy. Dlaczego?
Wizualizacja sztucznej inteligencji może analizować pola kategorii i pola liczbowe. W przypadku pól kategorii przykładem może być wartość Churn to Tak lub Nie, a zadowolenie klientów to Wysoka, Średnia lub Niska. Zwiększenie liczby kategorii do przeanalizowania oznacza, że liczba obserwacji na kategorię jest mniejsza. Taka sytuacja utrudnia wizualizacji znajdowanie wzorców w danych.
Podczas analizowania pól liczbowych możesz traktować pola liczbowe, takie jak tekst, w takim przypadku uruchamiasz tę samą analizę, co w przypadku danych kategorii (analiza kategorii). Jeśli masz wiele odrębnych wartości, zalecamy przełączenie analizy na analizę ciągłą, ponieważ oznacza to, że możemy wywnioskować wzorce, gdy liczby rosną lub zmniejszają, zamiast traktować je jako odrębne wartości. Możesz przełączyć się z analizy kategorii na analizę ciągłą w okienku wizualizacji Format na karcie Analiza .
Aby znaleźć silniejsze elementy mające wpływ, zalecamy grupowanie podobnych wartości w jedną jednostkę. Jeśli na przykład masz metrykę dla ceny, prawdopodobnie uzyskasz lepsze wyniki, grupując podobne ceny na kategorie Wysokie, Średnie i Niskie w porównaniu z użyciem poszczególnych punktów cenowych.
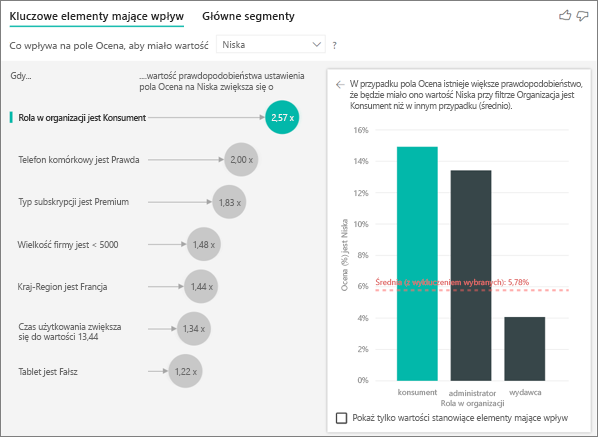
W moich danych istnieją czynniki, które wyglądają tak, jakby były kluczowymi elementami mającymi wpływ, ale tak nie są. Jak to się stanie?
W poniższym przykładzie klienci, którzy są konsumentami, mają niskie oceny, z 14,93% ocen, które są niskie. Rola administratora ma również wysoki odsetek niskich ocen na poziomie 13,42%, ale nie jest uważany za element mający wpływ.
Przyczyną tej determinacji jest to, że wizualizacja uwzględnia również liczbę punktów danych w przypadku znalezienia elementów mających wpływ. Poniższy przykład ma ponad 29 000 użytkowników i 10 razy mniej administratorów, około 2900. Tylko 390 z nich dało niską ocenę. Wizualizacja nie ma wystarczającej ilości danych, aby określić, czy znalazła zależność od ocen administratorów, czy jest to przypadkowe odkrycie.
Jakie są limity punktów danych dla kluczowych elementów mających wpływ?
Przeprowadzamy analizę na próbce 10 000 punktów danych. Bąbelki z jednej strony pokazują wszystkich znalezionych influencerów. Wykresy kolumnowe i wykresy punktowe po drugiej stronie są zgodne ze strategiami próbkowania dla tych podstawowych wizualizacji.
Jak obliczyć kluczowe elementy mające wpływ na potrzeby analizy kategorii?
W tle wizualizacja sztucznej inteligencji używa ML.NET do uruchamiania regresji logistycznej w celu obliczenia kluczowych elementów mających wpływ. Regresja logistyczna to model statystyczny, który porównuje ze sobą różne grupy.
Jeśli chcesz zobaczyć, co napędza niską ocenę, regresja logistyczna sprawdza, w jaki sposób klienci, którzy dali niską ocenę, różnią się od klientów, którzy wystawili wysoki wynik. Jeśli masz wiele kategorii, takich jak wysokie, neutralne i niskie wyniki, przyjrzyj się, jak klienci, którzy wystawili niską ocenę, różnią się od klientów, którzy nie wystawili niskiej oceny. W takim przypadku, jak klienci, którzy dali niską ocenę, różnią się od klientów, którzy wystawili wysoką ocenę lub neutralną ocenę?
Regresja logistyczna wyszukuje wzorce w danych i szuka, w jaki sposób klienci, którzy wystawili niską ocenę, mogą różnić się od klientów, którzy wystawili wysoką ocenę. Może się na przykład okazać, że klienci z większą liczbą biletów pomocy technicznej dają wyższy procent niskich ocen niż klienci z kilkoma biletami pomocy technicznej lub bez nich.
Regresja logistyczna uwzględnia również liczbę punktów danych. Jeśli na przykład klienci, którzy pełnią rolę administratora, dają proporcjonalnie więcej negatywnych wyników, ale istnieje tylko kilku administratorów, ten czynnik nie jest uważany za wpływowy. Ta determinacja jest dokonana, ponieważ nie ma wystarczającej liczby dostępnych punktów danych, aby wywnioskować wzorzec. Test statystyczny, znany jako test Wald, służy do określenia, czy czynnik jest uważany za element mający wpływ. Wizualizacja używa wartości p 0,05, aby określić próg.
Jak obliczyć kluczowe elementy mające wpływ na potrzeby analizy liczbowej?
W tle wizualizacja sztucznej inteligencji używa ML.NET do uruchamiania regresji liniowej w celu obliczenia kluczowych elementów mających wpływ. Regresja liniowa to model statystyczny, który bada, jak wynik w dziedzinie, którą analizujesz, zmienia się w zależności od czynników objaśniających.
Na przykład, jeśli analizujemy ceny domów, regresja liniowa przygląda się wpływowi, jaki posiadanie doskonałej kuchni ma na cenę domu. Czy domy z doskonałymi kuchniami zazwyczaj mają niższe lub wyższe ceny domów w porównaniu do domów bez doskonałych kuchni?
Regresja liniowa uwzględnia również liczbę punktów danych. Jeśli na przykład domy z kortami tenisowymi mają wyższe ceny, ale mamy kilka domów z kortem tenisowym, ten czynnik nie jest uważany za wpływowy. Ta determinacja jest dokonana, ponieważ nie ma wystarczającej liczby dostępnych punktów danych, aby wywnioskować wzorzec. Test statystyczny, znany jako test Wald, służy do określenia, czy czynnik jest uważany za element mający wpływ. Wizualizacja używa wartości p 0,05, aby określić próg.
Jak obliczasz segmenty?
W tle wizualizacja sztucznej inteligencji używa ML.NET do uruchamiania drzewa decyzyjnego w celu znalezienia interesujących podgrup. Celem drzewa decyzyjnego jest uzyskanie takiej podgrupy punktów danych, która cechuje się stosunkowo wysokimi wartościami w metryce, która cię interesuje. Może to być klienci o niskich ocenach lub domach o wysokich cenach.
Drzewo decyzyjne przyjmuje każdy czynnik objaśniający i próbuje uzasadnić, który czynnik daje mu najlepszy podział. Jeśli na przykład przefiltrujesz dane w celu uwzględnienia tylko dużych klientów korporacyjnych, czy to oddziela klientów, którzy wystawili wysoką ocenę w porównaniu z niską oceną? A może lepiej filtrować dane, aby uwzględnić tylko klientów, którzy skomentowali zabezpieczenia?
Po podzieleniu drzewa decyzyjnego, przyjmuje ono podgrupę danych i określa najlepszy kolejny podział dla tej podgrupy. W takim przypadku podgrupa to klienci, którzy komentowali zabezpieczenia. Po każdym podziale drzewo decyzyjne uwzględnia również, czy ma wystarczającą liczbę punktów danych dla tej grupy, aby była wystarczająco reprezentatywna, aby wywnioskować wzorzec. Jeśli nie, to jest to anomalia w danych, a nie rzeczywisty segment. Zastosowano kolejny test statystyczny w celu sprawdzenia istotności statystycznej warunku podziału z wartością p 0,05.
Gdy drzewo decyzyjne zakończy działanie, bierze wszystkie podziały, takie jak komentarze zabezpieczeń i duże przedsiębiorstwa, i tworzy filtry usługi Power BI. Ta kombinacja filtrów jest spakowana jako segment w wizualizacji.
Dlaczego niektóre czynniki stają się elementami mającymi wpływ lub przestają być elementami mającymi wpływ, gdy przenosim więcej pól do obszaru Wyjaśnij według?
Wizualizacja ocenia wszystkie czynniki objaśniające razem. Czynnik może być sam w sobie elementem mającym wpływ, ale jeśli jest brany pod uwagę z innymi czynnikami, może to nie być. Załóżmy, że chcesz przeanalizować, co napędza wysoką cenę domu, z sypialniami i rozmiarem domu jako czynniki objaśniające:
- Sama liczba dodatkowych sypialni może być czynnikiem wpływającym na wysokie ceny domów.
- Uwzględnienie wielkości domu w analizie oznacza, że teraz patrzysz na to, co dzieje się z sypialniami, podczas gdy rozmiar domu pozostaje stały.
- Jeśli rozmiar domu jest stały na 1500 stóp kwadratowych, jest mało prawdopodobne, że ciągły wzrost liczby sypialni znacznie zwiększa cenę domu.
- Sypialnie mogą nie być tak ważne, jak to było przed rozważenia wielkości domu.
Udostępnianie raportu współpracownikowi usługi Power BI wymaga posiadania indywidualnych licencji usługi Fabric lub Power BI Pro albo zapisania raportu w pojemności Premium. Zobacz udostępnianie raportów.