Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wartości klastrów automatycznie tworzą grupy o podobnych wartościach przy użyciu algorytmu dopasowywania rozmytego, a następnie mapują wartość każdej kolumny na najlepiej dopasowaną grupę. Ta transformacja jest przydatna podczas pracy z danymi, które mają wiele różnych odmian tej samej wartości i trzeba połączyć wartości w spójne grupy.
Rozważ przykładową tabelę z kolumną id zawierającą zestaw identyfikatorów i kolumnę Person zawierającą zestaw różnych pisowni i wielkich wersji nazw Miguel, Mike, William i Bill.
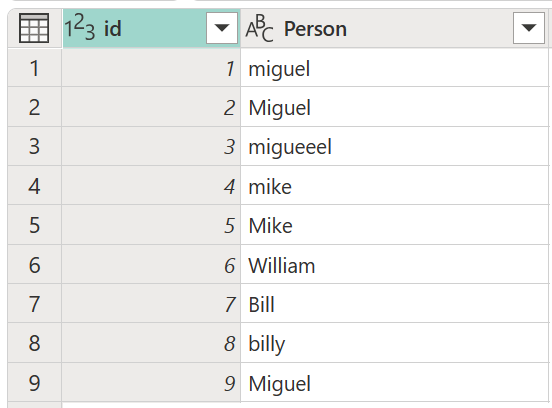
W tym przykładzie wynik, którego szukasz, to tabela z nową kolumną, która pokazuje odpowiednie grupy wartości z kolumny Person , a nie wszystkie różne odmiany tych samych słów.
Uwaga / Notatka
Funkcja Wartości klastra jest dostępna tylko dla dodatku Power Query Online.
Utwórz kolumnę klastra
Aby wybrać wartości klastra, najpierw wybierz kolumnę Osoba , przejdź do karty Dodaj kolumnę na wstążce, a następnie wybierz opcję Wartości klastra .
![]()
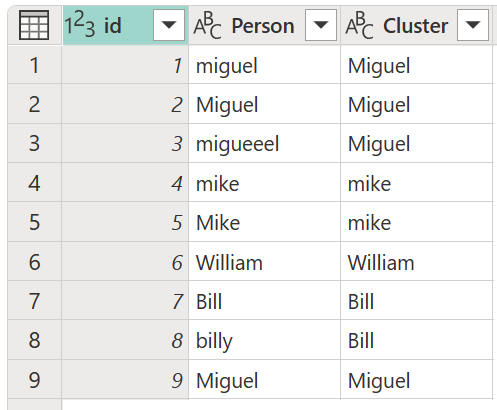
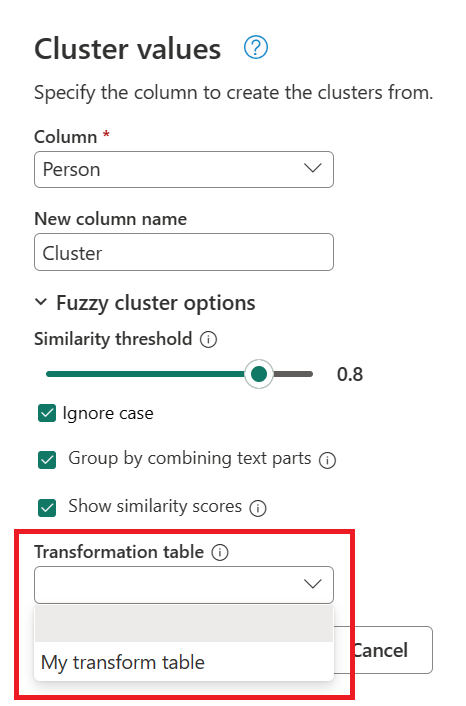
W oknie dialogowym Wartości klastra potwierdź kolumnę, z której chcesz utworzyć klastry, i wprowadź nową nazwę kolumny. W tym przypadku nadaj tej nowej kolumnie nazwę Klaster.
Wynik tej operacji przedstawiono na poniższej ilustracji.
Uwaga / Notatka
Dla każdego klastra wartości dodatek Power Query wybiera najczęstsze wystąpienie z wybranej kolumny jako wystąpienie "kanoniczne". Jeśli wystąpi wiele wystąpień z tą samą częstotliwością, dodatek Power Query wybierze pierwszy z nich.
Korzystanie z opcji klastra rozmytego
Następujące opcje są dostępne dla wartości klastrowania w nowej kolumnie:
- Próg podobieństwa (opcjonalnie): Ta opcja wskazuje, jak podobne dwie wartości muszą być zgrupowane razem. Ustawienie minimalnej wartości zero (0) powoduje zgrupowanie wszystkich wartości. Ustawienie maksymalne 1 umożliwia grupowanie wartości, które dokładnie pasują do siebie. Wartość domyślna to 0,8.
- Ignoruj wielkość liter: w przypadku porównywania ciągów tekstowych wielkość liter jest ignorowana. Ta opcja jest domyślnie włączona.
- Grupuj, łącząc części tekstowe: algorytm próbuje połączyć części tekstowe (jak w przykładzie z łączeniem "Micro" i "soft" w "Microsoft") w celu grupowania wartości.
- Pokaż wyniki podobieństwa: pokazuje wyniki podobieństwa między wartościami wejściowymi i obliczonymi wartościami reprezentatywnymi po klastrowaniu rozmyte.
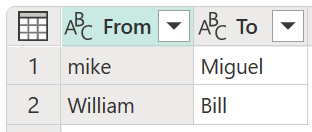
- Tabela przekształceń (opcjonalnie): możesz wybrać tabelę przekształceń, która mapuje wartości (takie jak mapowanie MSFT na Microsoft) aby je pogrupować.
W tym przykładzie nowa tabela przekształceń o nazwie Moja tabela przekształcania służy do zademonstrowania sposobu mapowania wartości. Ta tabela przekształceń ma dwie kolumny:
- Od: ciąg tekstowy, którego należy szukać w Twojej tabeli.
- Do: ciąg tekstowy do użycia w celu zastąpienia ciągu tekstowego w kolumnie Od .
Ważne
Ważne jest, aby tabela przekształceń miała takie same kolumny i nazwy kolumn, jak pokazano na poprzedniej ilustracji (muszą mieć nazwy "Od" i "Do"), w przeciwnym razie dodatek Power Query nie rozpozna tej tabeli jako tabeli transformacji, a żadne przekształcenie nie zostanie wykonane.
Używając wcześniej utworzonego zapytania, kliknij dwukrotnie krok Wartości klastrowane, a następnie w oknie dialogowym Klaster wartości rozwiń pozycję Opcje rozmytego klastrowania. W obszarze Opcje rozmyte klastra włącz opcję Pokaż wyniki podobieństwa . W polu Tabela przekształceń (opcjonalnie) wybierz zapytanie zawierające tabelę przekształcania.
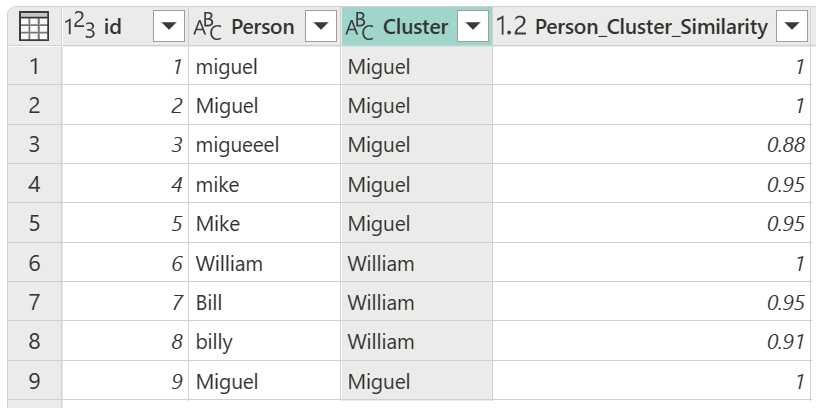
Po wybraniu tabeli przekształceń i włączeniu opcji Pokaż wyniki podobieństwa wybierz przycisk OK. Wynikiem tej operacji jest tabela zawierająca ten sam identyfikator i kolumny Person co oryginalna tabela, ale także dwie nowe kolumny o nazwie Cluster i Person_Cluster_Similarity. Kolumna Cluster (Klaster ) zawiera poprawnie napisane i wielkie wersje nazw Miguela dla wersji Miguela i Mike'a oraz Williama dla wersji Billa, Billy'ego i Williama. Kolumna Person_Cluster_Similarity zawiera wyniki podobieństwa dla każdej z nazw.
Zasady dotyczące tabeli przekształceń
Możesz zauważyć, że tabela transformacji w poprzedniej sekcji wskazuje, że przypadki imienia "Mike" są zmieniane na "Miguel", a przypadki imienia "William" są zmieniane na "Bill". Jednak w tabeli wynikowej przypadki "Bill" i "billy" zostały zmienione na "William." W tabeli transformacji, zamiast być bezpośrednią ścieżką od From do To, tabela jest symetryczna podczas klastrowania, co oznacza, że "mike" jest równoważny z "Miguel" i na odwrót. Wynik odpowiedników podanych w tabeli przekształceń zależy od następujących reguł:
- Jeśli istnieje większość identycznych wartości, te wartości mają pierwszeństwo przed wartościami nieidentycznymi.
- Jeśli nie ma większości wartości, wartość, która jest wyświetlana jako pierwsza, ma pierwszeństwo.
Na przykład w oryginalnej tabeli używanej w tym artykule, wersje imienia Miguel (zarówno 'miguel', jak i 'Miguel') w kolumnie Person stanowią większość wystąpień nazw Miguel i Mike. Ponadto imię Miguel pisane wielką literą stanowi większość nazwy Miguel. Dlatego skojarzenie Miguela i jego pochodnych oraz Mike'a i jego pochodnych w tabeli przekształcania powoduje, że nazwa Miguel jest używana w kolumnie Klaster .
Jednak dla nazw William, Bill i "billy" nie ma większości wartości, ponieważ wszystkie trzy są unikatowe. Ponieważ William pojawia się jako pierwszy, jego imię jest używane w kolumnie Klaster. Jeśli "billy" pojawiłby się najpierw w tabeli, to zostałby użyty w kolumnie Klaster. Ponadto, ponieważ nie przeważają pewne wartości, używany jest przypadek używany w poszczególnych nazwach. Oznacza to, że jeśli William jest pierwszy, William z wielkimi literami "W" jest używany jako wartość wynikowa; jeśli "billy" jest pierwszy, "billy" z małymi literami "b" jest używany.