Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Scalanie rozmyte to funkcja inteligentnego przygotowywania danych, której można użyć do stosowania algorytmów dopasowywania rozmytego podczas porównywania kolumn. Te algorytmy próbują znaleźć dopasowania w tabelach, które są scalane.
Dopasowanie rozmyte można włączyć w dolnej części okna dialogowego Scalanie , wybierając przycisk Użyj dopasowania rozmytego, aby wykonać opcję scalania . Więcej informacji: Omówienie operacji scalania
Uwaga
Dopasowywanie rozmyte jest obsługiwane tylko w przypadku operacji scalania w kolumnach tekstowych. Dodatek Power Query używa algorytmu podobieństwa Jaccard do mierzenia podobieństwa między parami wystąpień.
Przykładowy scenariusz
Typowy przypadek użycia dopasowania rozmytego dotyczy pól tekstowych dowolnych, takich jak w ankiecie. W tym artykule przykładowa tabela została pobrana bezpośrednio z ankiety online wysłanej do grupy z tylko jednym pytaniem: Jaki jest twój ulubiony owoc?
Wyniki tej ankiety przedstawiono na poniższej ilustracji.

Zrzut ekranu przedstawiający przykładową tabelę danych wyjściowych ankiety zawierającą wykres dystrybucji kolumn przedstawiający dziewięć odrębnych odpowiedzi z unikatowymi odpowiedziami oraz odpowiedzi na ankietę ze wszystkimi literami, liczbami mnogimi lub pojedynczymi i problemami z przypadkami.
Dziewięć rekordów odzwierciedla przesłane ankiety. Problem z zgłoszeniami ankiety polega na tym, że niektóre mają literówki, niektóre są mnogią, niektóre są pojedyncze, niektóre są wielkie, a niektóre są małe.
Aby ułatwić standaryzację tych wartości, w tym przykładzie masz tabelę referencyjną Owoce .

Zrzut ekranu przedstawiający tabelę referencyjną Owoce zawierającą wykres rozkładu kolumn przedstawiający cztery odrębne owoce ze wszystkimi owocami unikatowymi oraz listę owoców: jabłko, ananas, arbu i banan.
Uwaga
Dla uproszczenia ta tabela referencyjna Owoce zawiera tylko nazwę owoców, które będą potrzebne w tym scenariuszu. Tabela referencyjna może zawierać dowolną liczbę wierszy.
Celem jest utworzenie tabeli podobnej do poniższej, w której zostały ustandaryzowane wszystkie te wartości, aby można było przeprowadzić większą analizę.
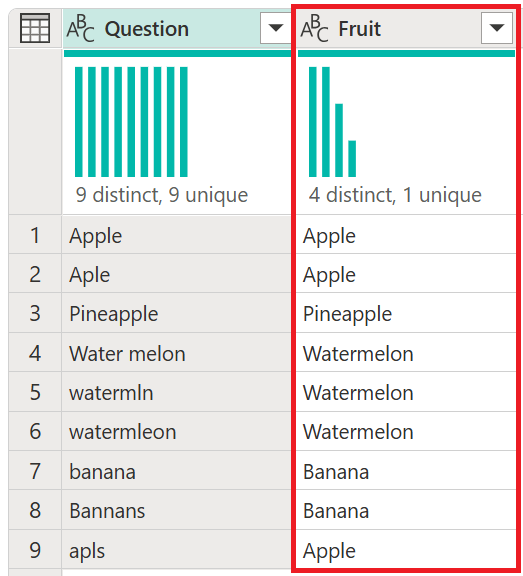
Zrzut ekranu przedstawiający przykładową tabelę danych wyjściowych ankiety z kolumną Pytanie zawierającą wykres rozkładu kolumn. Wykres przedstawia dziewięć odrębnych odpowiedzi ze wszystkimi odpowiedziami unikatowymi. Odpowiedzi na ankietę zawierają wszystkie literówki, liczbę mnogą lub pojedynczą oraz problemy z przypadkami. Tabela wyjściowa zawiera również kolumnę Fruit. Ta kolumna zawiera wykres dystrybucji kolumn przedstawiający cztery odrębne odpowiedzi z jedną unikatową odpowiedzią. Zawiera również listę wszystkich owoców prawidłowo zaklętych, pojedynczych i prawidłowych wielkości liter.
Operacja scalania rozmytego
Aby wykonać scalanie rozmyte, zacznij od scalania. W tym przypadku należy użyć lewego sprzężenia zewnętrznego, w którym lewa tabela jest jedyną z ankiety, a po prawej stronie znajduje się tabela referencyjna Owoce. W dolnej części okna dialogowego zaznacz pole wyboru Użyj dopasowywania rozmytego do wykonania scalania .
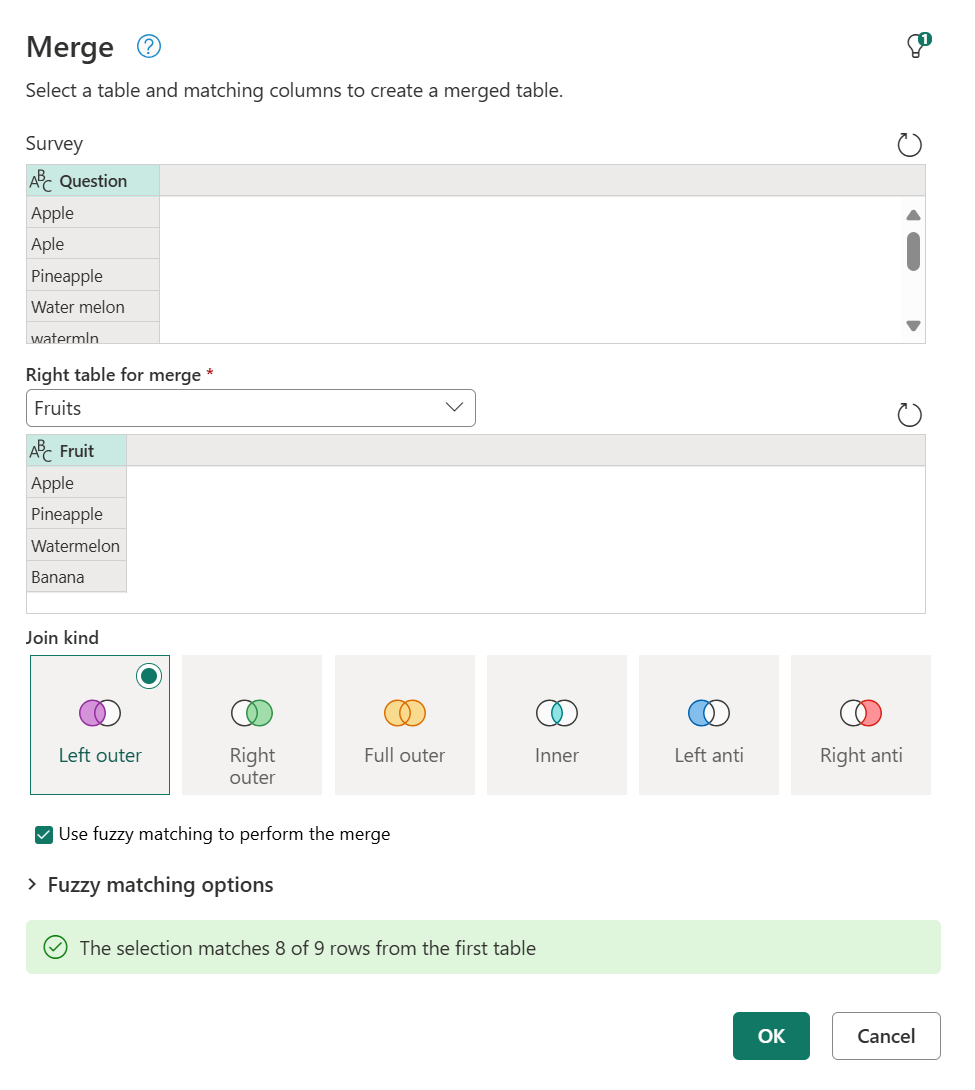
Po wybraniu przycisku OK możesz zobaczyć nową kolumnę w tabeli z powodu tej operacji scalania. Po rozwinięciu go istnieje jeden wiersz, który nie zawiera żadnych wartości. To dokładnie to, co komunikat okna dialogowego na poprzedniej ilustracji stwierdził, gdy powiedział: "Zaznaczenie pasuje do 8 z 9 wierszy z pierwszej tabeli."

Zrzut ekranu przedstawiający kolumnę owocu dodaną do tabeli Survey. Wszystkie wiersze w kolumnie Pytanie są rozwinięte, z wyjątkiem wiersza 9, który nie może rozwinąć się, a kolumna Fruit zawiera wartość null.
Opcje dopasowywania rozmytego
Możesz zmodyfikować opcje dopasowywania rozmytego, aby dostosować sposób, w jaki należy wykonać przybliżone dopasowanie. Najpierw wybierz polecenie Scal zapytania , a następnie w oknie dialogowym Scalanie rozwiń pozycję Opcje dopasowywania rozmyte.
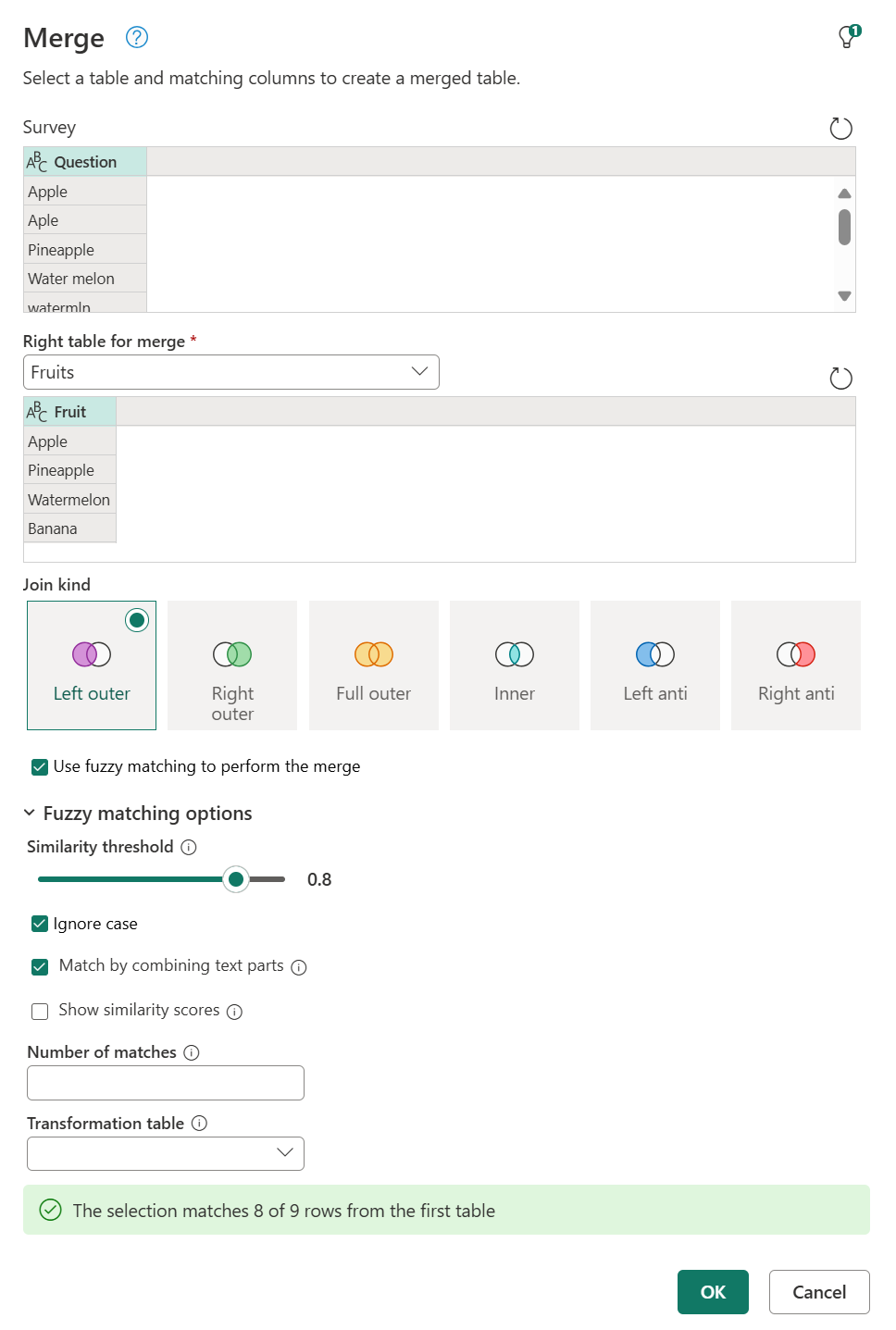
Dostępne opcje:
- Próg podobieństwa (opcjonalnie): wartość z zakresu od 0,00 do 1,00, która zapewnia możliwość dopasowania rekordów powyżej danego wyniku podobieństwa. Próg 1,00 jest taki sam jak określenie dokładnych kryteriów dopasowania. Na przykład winogrona są zgodne z Graes (brakuje litery p) tylko wtedy, gdy próg jest ustawiony na wartość mniejszą niż 0,90. Domyślnie ta wartość jest ustawiona na 0,80.
- Ignoruj wielkość liter: umożliwia dopasowywanie rekordów niezależnie od wielkości liter tekstu.
- Dopasowanie przez połączenie części tekstu: umożliwia łączenie części tekstu w celu znalezienia dopasowań. Na przykład mikro soft jest dopasowywany do firmy Microsoft, jeśli ta opcja jest włączona.
- Pokaż wyniki podobieństwa: pokazuje wyniki podobieństwa między danymi wejściowymi a dopasowanymi wartościami po dopasowaniu rozmyte.
- Liczba dopasowań (opcjonalnie): określa maksymalną liczbę pasujących wierszy, które mogą być zwracane dla każdego wiersza wejściowego.
- Tabela przekształcania (opcjonalnie): umożliwia dopasowywanie rekordów na podstawie niestandardowych mapowań wartości. Na przykład winogrona są dopasowywane do wartości Raisins, jeśli zostanie podana tabela przekształceń, w której kolumna From zawiera winogrona i kolumnę Do zawiera rodzynki.
Tabela przekształceń
Na przykład w tym artykule możesz użyć tabeli przekształceń, aby zamapować wartość, która ma brakującą parę. Ta wartość to apls, które należy zamapować na firmę Apple. Tabela przekształceń zawiera dwie kolumny:
- Z zawiera wartości do znalezienia.
- Aby zawierać wartości używane do zastępowania wartości znalezionych przy użyciu kolumny Od .
W tym artykule tabela przekształceń wygląda następująco:
| Źródło | Działanie |
|---|---|
| apls | Apple |
Możesz wrócić do okna dialogowego Scalanie, a w obszarze Rozmyte opcje dopasowania w obszarze Liczba dopasowań wprowadź wartość 1. Włącz opcję Pokaż wyniki podobieństwa, a następnie w obszarze Tabela przekształceń wybierz pozycję Przekształć tabelę z menu rozwijanego.
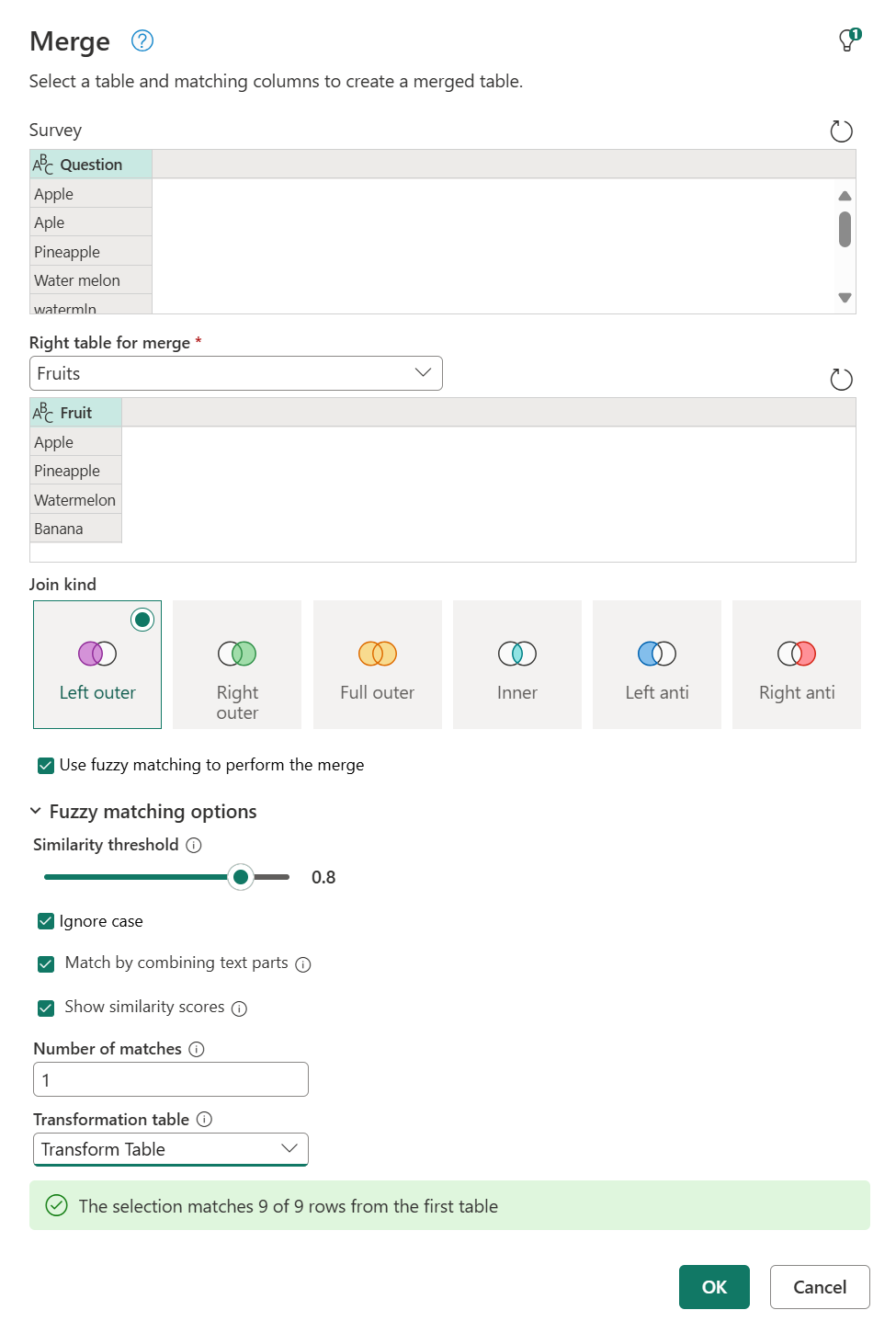
Po wybraniu przycisku OK możesz przejść do kroku scalania. Po rozwinięciu kolumny z wartościami tabeli oprócz pola Fruit zostanie również wyświetlone pole Wynik podobieństwa. Zaznacz je i rozwiń bez dodawania prefiksu.
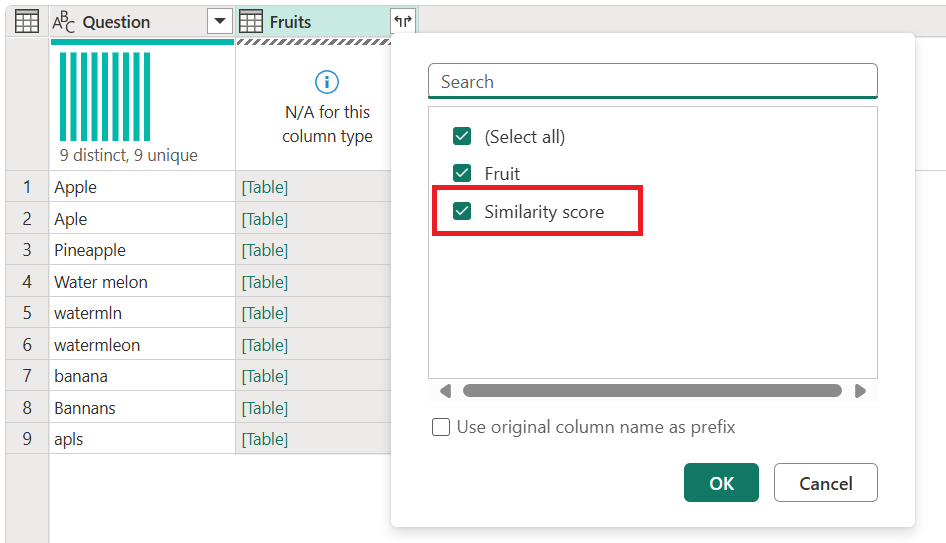
Po rozwinięciu tych dwóch pól zostaną one dodane do tabeli. Zanotuj wartości, które otrzymujesz dla wyników podobieństwa każdej wartości. Te wyniki mogą pomóc w dalszym przekształceniu, jeśli jest to konieczne, aby określić, czy należy obniżyć lub zwiększyć próg podobieństwa.
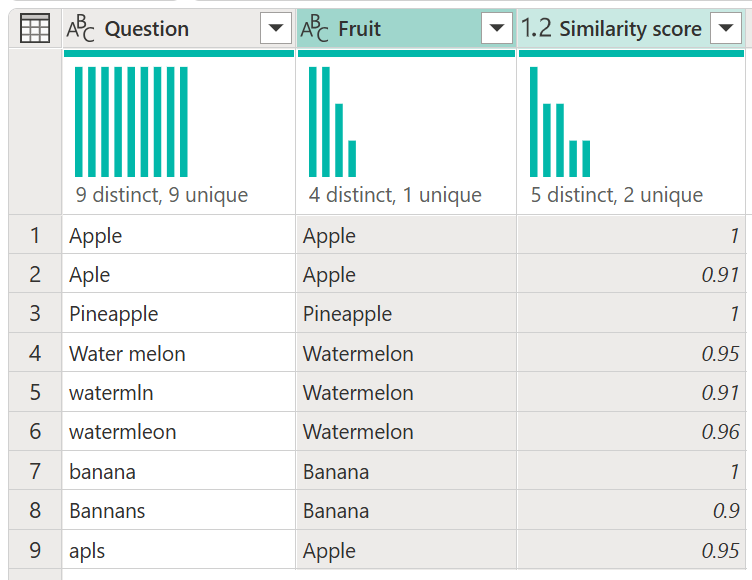
W tym przykładzie wynik podobieństwa służy tylko jako dodatkowe informacje i nie jest potrzebny w danych wyjściowych tego zapytania, aby można było go usunąć. Zwróć uwagę, jak przykład rozpoczął się od dziewięciu odrębnych wartości, ale po scaleniu rozmytym istnieją tylko cztery odrębne wartości.
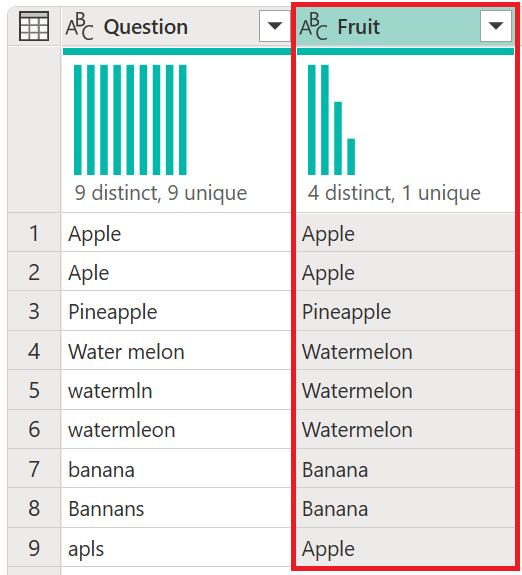
Zrzut ekranu przedstawiający tabelę danych wyjściowych ankiety scalania rozmytego z kolumną Question zawierającą wykres dystrybucji kolumn przedstawiający dziewięć odrębnych odpowiedzi z unikatowymi odpowiedziami oraz odpowiedzi na ankietę ze wszystkimi literami, mnogą lub pojedynczą i problemami z przypadkami. Zawiera również kolumnę Fruit z wykresem rozkładu kolumn z czterema odrębnymi odpowiedziami z jedną unikatową odpowiedzią i wyświetla listę wszystkich owoców odpowiednio zaklętych, pojedynczych i prawidłowych liter.
Aby uzyskać więcej informacji na temat sposobu działania tabel przekształceń, przejdź do sekcji Wymagania dotyczące tabeli przekształcania.