Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Machine Learning Studio (wersja klasyczna)
Machine Learning Studio (wersja klasyczna)  Azure Machine Learning
Azure Machine Learning
Ważne
Obsługa programu Machine Learning Studio (wersja klasyczna) zakończy się 31 sierpnia 2024 r. Zalecamy przejście do usługi Azure Machine Learning przed tym terminem.
Od 1 grudnia 2021 r. nie będzie można tworzyć nowych zasobów programu Machine Learning Studio (wersja klasyczna). Do 31 sierpnia 2024 r. można będzie nadal korzystać z istniejących zasobów programu Machine Learning Studio (wersja klasyczna).
- Zobacz informacje na temat przenoszenia projektów uczenia maszynowego z usługi ML Studio (klasycznej) do usługi Azure Machine Learning.
- Dowiedz się więcej o usłudze Azure Machine Learning
Dokumentacja programu ML Studio (wersja klasyczna) jest wycofywana i może nie być aktualizowana w przyszłości.
W tym artykule utworzysz eksperyment uczenia maszynowego w usłudze Machine Learning Studio (wersja klasyczna), który przewiduje cenę samochodu na podstawie różnych zmiennych, takich jak make i specyfikacje techniczne.
Jeśli dopiero zaczynasz korzystać z uczenia maszynowego, seria filmów wideo zatytułowana Data Science for Beginners (Analiza danych dla początkujących) stanowi znakomite wprowadzenie do uczenia maszynowego przedstawione przy użyciu codziennego języka i pojęć.
W tym przewodniku Szybki start obowiązuje domyślny przepływ pracy dla eksperymentu:
- Tworzenie modelu
- Uczenie modelu
- Generowanie wyników i testowanie modelu
Pobieranie danych
Do przeprowadzenia uczenia maszynowego potrzebne są dane. Istnieje kilka przykładowych zestawów danych dołączonych do programu Studio (wersja klasyczna), których można użyć, lub możesz zaimportować dane z wielu źródeł. W tym scenariuszu będziemy używać przykładowego zestawu danych Automobile price data (Raw) (Nieprzetworzone dane z cenami samochodów), dołączonego do obszaru roboczego. Zestaw ten zawiera dane różnych modeli samochodów, na przykład informacje dotyczące marki, ceny czy specyfikacji technicznej.
Napiwek
Funkcjonalną kopię poniższego eksperymentu można znaleźć w galerii sztucznej inteligencji platformy Azure. Przejdź do pozycji Pierwszy eksperyment nauki o danych — przewidywanie cen samochodów i kliknij pozycję Otwórz w programie Studio , aby pobrać kopię eksperymentu do obszaru roboczego usługi Machine Learning Studio (wersja klasyczna).
Poniżej przedstawiono procedurę dołączania zestawu danych do eksperymentu.
Utwórz nowy eksperyment, klikając pozycję +NOWY w dolnej części okna usługi Machine Learning Studio (wersja klasyczna). Wybierz pozycję EXPERIMENT (EKSPERYMENT)>Blank Experiment (Pusty eksperyment).
Eksperymentowi zostanie nadana domyślna nazwa, wyświetlana w górnej części obszaru roboczego. Zaznacz ten tekst i zmień jego nazwę na coś opisowego, na przykład Przewidywanie cen samochodów. Nazwa nie musi być unikatowa.
Z lewej strony obszaru roboczego eksperymentu znajduje się paleta zawierająca zestawy danych i moduły. Wpisz automobile (samochód) w polu wyszukiwania w górnej części tej palety, aby znaleźć zestaw danych z etykietą Automobile price data (Raw) (Nieprzetworzone dane z cenami samochodów). Przeciągnij ten zestaw danych do obszaru roboczego eksperymentu.
Aby wyświetlić graficzną reprezentację danych, kliknij port wyjściowy w dolnej części zestawu danych dotyczących samochodów, a następnie wybierz pozycję Visualize (Wizualizacja).
Napiwek
Zestawy danych i moduły mają porty wejściowe i wyjściowe oznaczone małymi kołami — porty wejściowe znajdują się u góry, a wyjściowe u dołu. Aby utworzyć przepływ danych w eksperymencie, połącz port wyjściowy danego modułu z portem wejściowym innego modułu. W dowolnym momencie można kliknąć port wyjściowy zestawu danych lub modułu, aby wyświetlić dane w określonym punkcie przepływu danych.
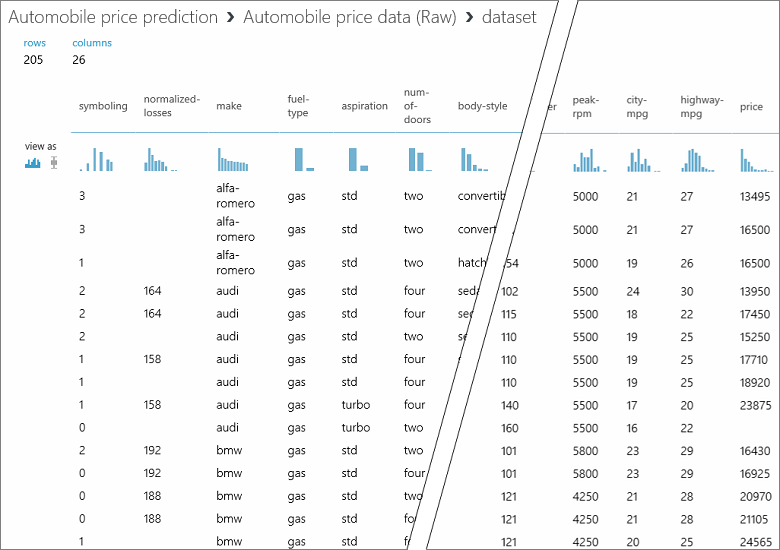
W tym zestawie danych poszczególne wiersze reprezentują samochody, a zmienne skojarzone z samochodami są wyświetlane jako kolumny. Cenę będziemy przewidywać w skrajnej prawej kolumnie (kolumna 26 o nazwie „price” [cena]), używając zmiennych dotyczących konkretnego samochodu.
Aby zamknąć okno wizualizacji, kliknij znak „x” w prawym górnym rogu.
Przygotowywanie danych
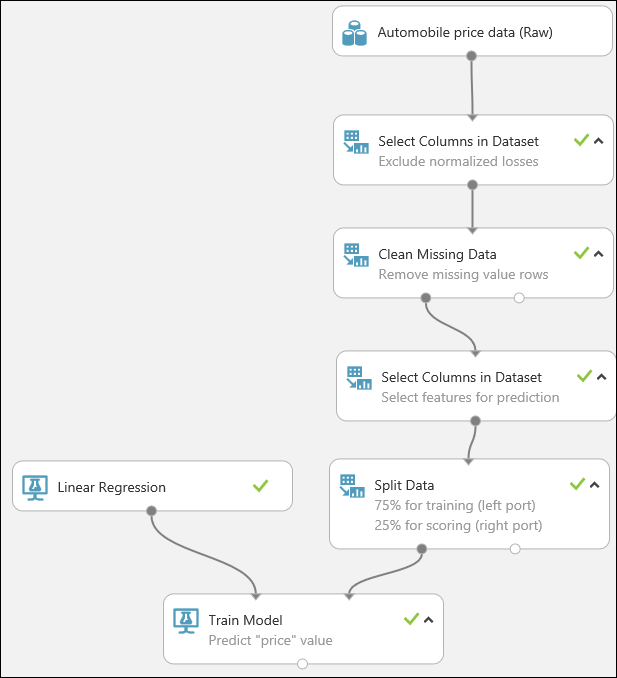
Zestawy danych zwykle wymagają przetworzenia wstępnego przed rozpoczęciem analizy. Może zauważyłeś, że w kolumnach niektórych wierszy brakuje wartości. Te brakujące wartości muszą zostać wyczyszczone, aby umożliwić modelowi wykonanie poprawnej analizy danych. Usuniemy wszystkie wiersze z brakującymi wartościami. Ponadto w kolumnie normalized-losses (znormalizowane straty) występuje wiele przypadków brakujących wartości, dlatego całkowicie wykluczymy tę kolumnę z modelu.
Wskazówka
Większość modułów wymaga wyczyszczenia brakujących wartości w danych wejściowych.
Najpierw dodamy moduł, który całkowicie usunie kolumnę normalized-losses (znormalizowane straty). Następnie dodamy kolejny moduł usuwający wszystkie wiersze, w których brakuje danych.
Wpisz ciąg select columns (wybieranie kolumn) w polu wyszukiwania w górnej części palety modułów, aby znaleźć moduł Select Columns in Dataset (Wybieranie kolumn w zestawie danych). Następnie przeciągnij go do obszaru roboczego eksperymentu. Ten moduł pozwala wybierać kolumny danych, które mają zostać dołączone do modelu lub wykluczone z niego.
Połącz port wyjściowy zestawu danych Automobile price data (Raw) (Nieprzetworzone dane z cenami samochodów) z portem wejściowym modułu Select Columns in Dataset (Wybieranie kolumn w zestawie danych).
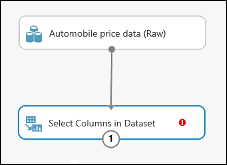
Kliknij moduł Select Columns in Dataset (Wybieranie kolumn w zestawie danych) i kliknij pozycję Launch column selector (Uruchom selektora kolumn) w okienku Properties (Właściwości).
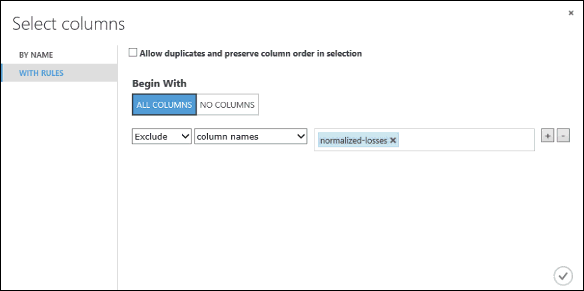
Po lewej stronie kliknij pozycję Za pomocą reguł.
W obszarze Begin With (Rozpocznij od) kliknij pozycję All columns (Wszystkie kolumny). Te zasady kierują Select Columns in Dataset do przepuszczenia wszystkich kolumn (z wyjątkiem tych kolumn, które zamierzamy wykluczyć).
Z list rozwijanych wybierz pozycje Exclude (Wyklucz) i column names (nazwy kolumn), a następnie kliknij wewnątrz pola tekstowego. Zostanie wyświetlona lista kolumn. Wybierz pozycję normalized-losses (znormalizowane straty) i zostanie dodana do pola tekstowego.
Kliknij przycisk znacznika wyboru (OK), aby zamknąć selektora kolumn (w prawym dolnym rogu).
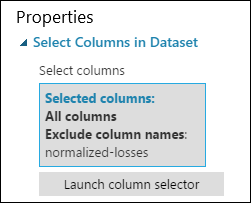
Zawartość okienka właściwości modułu Select Columns in Dataset (Wybieranie kolumn w zestawie danych) określa, że zostaną przetworzone wszystkie kolumny zestawu danych z wyjątkiem kolumny normalized-losses (znormalizowane straty).
Napiwek
Aby dodać komentarz do modułu, kliknij dwukrotnie moduł i wpisz tekst. Pozwoli to od razu sprawdzić rolę modułu w eksperymencie. W tym przypadku kliknij dwukrotnie moduł Select Columns in Dataset (Wybieranie kolumn w zestawie danych) i dodaj komentarz „Wykluczenie kolumny znormalizowanych strat”.
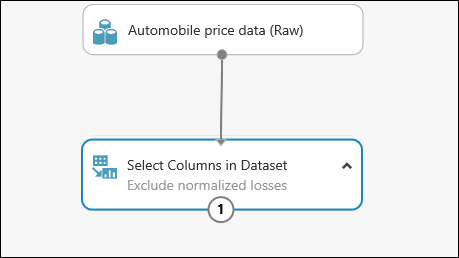
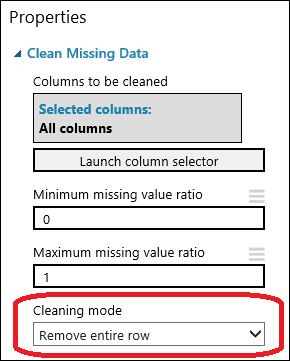
Przeciągnij moduł Clean Missing Data (Czyszczenie brakujących danych) do obszaru roboczego eksperymentu i połącz go z modułem Select Columns in Dataset (Wybieranie kolumn w zestawie danych). W okienku Właściwości wybierz Usuń cały wiersz w sekcji Tryb czyszczenia. Te opcje spowodują wyczyszczenie danych przez moduł Clean Missing Data (Czyszczenie brakujących danych) — zostaną usunięte wiersze, w których brakuje wartości. Kliknij dwukrotnie moduł i wpisz komentarz „Usunięcie wierszy z brakującymi wartościami”.
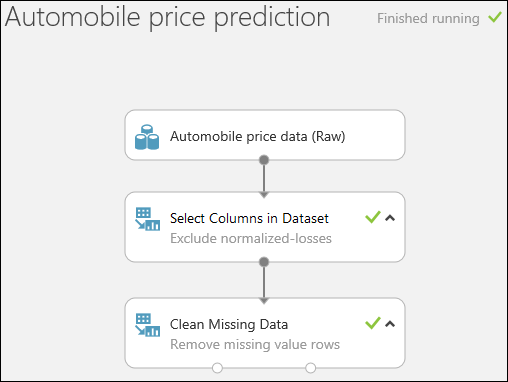
Uruchom eksperyment, klikając pozycję URUCHOM u dołu strony.
Po zakończeniu eksperymentu na wszystkich modułach są widoczne zielone znaczniki wyboru. Oznacza to, że działanie modułów zakończyło się pomyślnie. Zwróć również uwagę na informację o zakończeniu działania wyświetlaną w prawym górnym rogu.
Napiwek
Dlaczego teraz uruchomiliśmy eksperyment? Poprzez uruchomienie eksperymentu definicje kolumn dla naszych danych są przekazywane z zestawu danych przez moduł Select Columns in Dataset (Wybieranie kolumn w zestawie danych) i moduł Clean Missing Data (Czyszczenie brakujących danych). Oznacza to, że informacje te będą dostępne dla wszystkich modułów połączonych z modułem Clean Missing Data (Czyszczenie brakujących danych).
Teraz mamy czyste dane. Jeśli chcesz wyświetlić oczyszczony zestaw danych, kliknij lewy port wyjściowy modułu Clean Missing Data (Czyszczenie brakujących danych) i wybierz pozycję Visualize (Wizualizacja). Zwróć uwagę na to, że kolumna normalized-losses (znormalizowane straty) nie jest już uwzględniana i nie ma brakujących wartości.
Po oczyszczeniu danych można określić, jakie cechy zostaną użyte w modelu predykcyjnym.
Definiowanie funkcji
W uczeniu maszynowym funkcje są poszczególnymi mierzalnymi właściwościami czegoś, co cię interesuje. W naszym zestawie danych poszczególne wiersze odpowiadają różnym samochodom, a kolumny — cechom tych samochodów.
Znalezienie odpowiedniego zestawu cech, który ma służyć do utworzenia modelu predykcyjnego, wymaga eksperymentowania oraz dysponowania wiedzą na temat bieżącego problemu. Niektóre cechy lepiej nadają się do przewidywania celu niż inne. Niektóre cechy są ściśle powiązane z innymi, dlatego można je usunąć. Na przykład dane dotyczące zużycia paliwa w mieście i w trasie mają bliski związek ze sobą, co sprawia, że usunięcie jednej z tych cech nie będzie miało zasadniczego wpływu na prognozę.
Utworzymy model, który korzysta z podzbioru cech zawartych w naszym zestawie danych. Możesz wrócić później, wybrać inne cechy, ponownie uruchomić eksperyment i sprawdzić, czy uzyskasz lepsze wyniki. Jednak aby rozpocząć, wypróbujmy następujące funkcje:
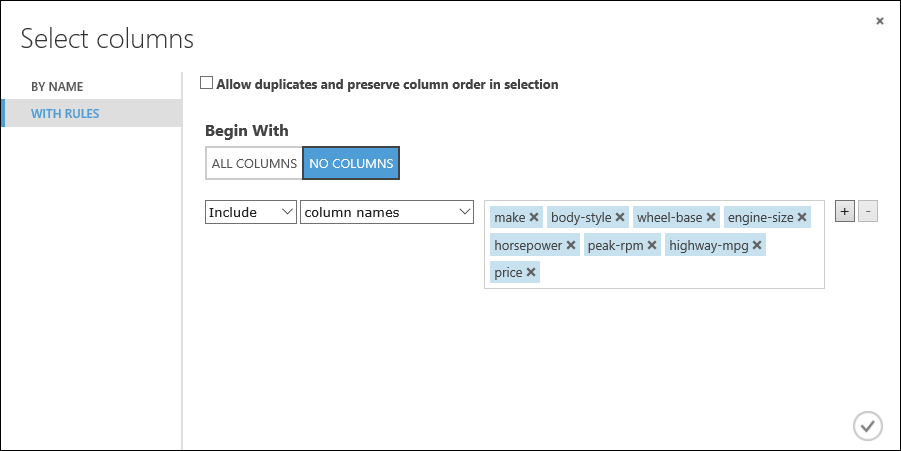
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
Przeciągnij kolejny moduł Select Columns in Dataset (Wybieranie kolumn w zestawie danych) do obszaru roboczego eksperymentu. Połącz lewy port wyjściowy modułu Clean Missing Data (Czyszczenie brakujących danych) z wejściem modułu Select Columns in Dataset (Wybieranie kolumn w zestawie danych).
Kliknij dwukrotnie moduł i wpisz „Wybieranie cech w celu prognozowania”.
Kliknij pozycję Launch column selector (Uruchom selektora kolumn) w okienku Properties (Właściwości).
Kliknij pozycję With rules (Za pomocą reguł).
W obszarze Begin With (Rozpocznij od) kliknij pozycję No columns (Brak kolumn). W wierszu filtru wybierz pozycje Include (Dołącz) i column names (nazwy kolumn), a następnie wybierz nazwy kolumn w polu tekstowym. Ten filtr kieruje moduł, aby nie przepuszczał żadnych kolumn (cech) z wyjątkiem tych, które określimy.
Kliknij przycisk znacznika wyboru (OK).
Ten moduł spowoduje powstanie filtrowanego zestawu danych zawierającego tylko cechy, które chcemy przekazać do algorytmu uczenia. Algorytm ten zostanie użyty w następnym kroku. Możesz później wrócić i spróbować ponownie, wybierając inną kombinację funkcji.
Wybieranie i stosowanie algorytmu
Po przygotowaniu danych można przystąpić do konstruowania modelu predykcyjnego, co obejmuje uczenie i testowanie. Użyjemy danych do nauczenia modelu, a następnie przetestujemy go, aby sprawdzić dokładność przewidywanych cen.
Algorytmy klasyfikacji i regresji to dwa typy nadzorowanego uczenia maszynowego. Klasyfikacja przewiduje odpowiedź na podstawie zdefiniowanego zestawu kategorii, takich jak kolory (czerwony, niebieski lub zielony). Regresja służy do prognozowania liczby.
Ponieważ chcemy przewidzieć cenę, która jest liczbą, użyjemy algorytmu regresji. W tym przykładzie użyjemy modelu regresji liniowej.
Uczenie modelu polega na przekazaniu mu zestawu danych zawierających cenę. Model skanuje dane i szuka korelacji między cechami samochodu a jego ceną. Następnie przetestujemy model — damy mu zestaw cech samochodów, które dobrze znamy i zobaczymy, jak blisko model przewidzi znane ceny.
Dane dzielimy na dwa oddzielne zestawy, aby użyć ich do celów szkoleniowych i do testów.
Wybierz moduł Split Data (Podział danych) i przeciągnij go do obszaru roboczego eksperymentu, a następnie połącz go z ostatnim modułem Select Columns in Dataset (Wybieranie kolumn w zestawie danych).
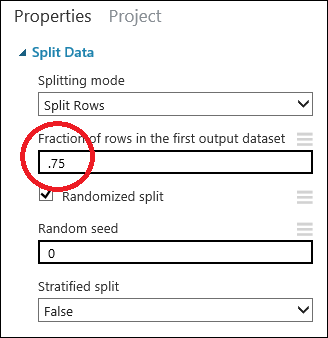
Wybierz moduł Split Data (Podział danych), klikając go. Znajdź opcję Fraction of rows in the first output dataset (Odsetek wierszy w pierwszym zestawie danych wyjściowych) (w okienku Właściwości po prawej stronie obszaru roboczego) i ustaw dla niej wartość 0,75. Dzięki temu 75% danych zostanie użytych do nauczenia modelu, a pozostałe 25% do testów.
Napiwek
Zmieniając wartość parametru Random seed, można uzyskać różne próbki losowe na potrzeby szkolenia i testowania. Ten parametr umożliwia sterowanie inicjacją pseudolosowego generatora liczb.
Uruchom eksperyment. Po uruchomieniu eksperymentu moduły Select Columns in Dataset (Wybieranie kolumn w zestawie danych) i Split Data (Podział danych) przekażą definicje kolumn do modułów, które będą dodawane później.
Aby wybrać algorytm uczenia, rozwiń kategorię Machine Learning (Uczenie maszynowe) na palecie modułów wyświetlanej z lewej strony obszaru roboczego, a następnie rozwiń węzeł Initialize Model (Inicjacja modelu). Zostaną wyświetlone różne kategorie modułów, których można użyć do zainicjowania algorytmów uczenia maszynowego. W tym eksperymencie wybierz moduł Linear Regression (Regresja liniowa) z kategorii Regression (Regresja) i przeciągnij go do obszaru roboczego eksperymentu. (Możesz również znaleźć go, wpisując „linear regression” [regresja liniowa] w polu wyszukiwania palety).
Znajdź moduł Train Model i przeciągnij go na płótno eksperymentu. Połącz wyjście modułu Linear Regression (Regresja liniowa) z lewym wejściem modułu Train Model (Uczenie modelu) i połącz wyjście danych szkoleniowych (lewy port) modułu Split Data (Podział danych) z prawym wejściem modułu Train Model (Uczenie modelu).
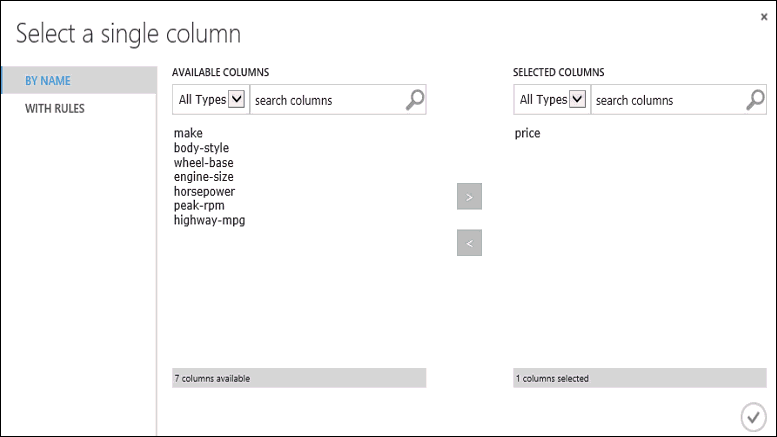
Kliknij moduł Train Model, kliknij pozycję Uruchom selektor kolumn w okienku Właściwości, a następnie wybierz kolumnę cena. Price (Cena) to wartość, która będzie prognozowana przez nasz model.
Kolumnę price (cena) możesz wybrać, przenosząc ją z listy Available columns (Dostępne kolumny) do listy Selected columns (Wybrane kolumny) w selektorze kolumn.
Uruchom eksperyment.
W efekcie powstał nauczony model regresji, który może służyć do generowania wyników na podstawie nowych danych samochodów w celu prognozowania cen.
Przewidywanie nowych cen samochodów
Teraz gdy wytrenowaliśmy model, możemy użyć go do oceny pozostałych 25% danych, aby zobaczyć, jak dobrze działa nasz model.
Znajdź moduł Score Model i przeciągnij go na płótno eksperymentu. Połącz wyjście modułu Train Model z lewym portem wejściowym modułu Score Model. Połącz wyjście danych testowych (prawy port) modułu Split Data z prawym portem wejściowym modułu Score Model.
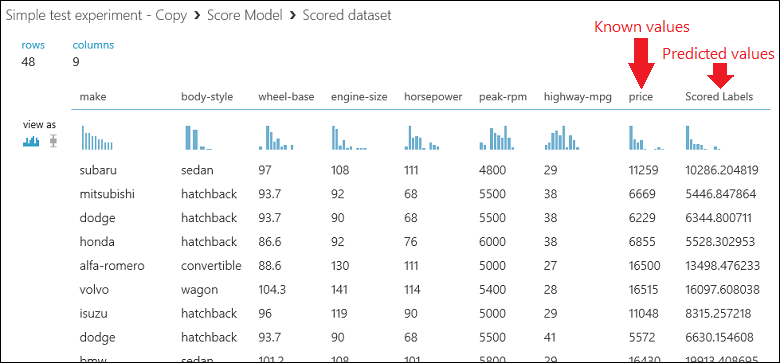
Uruchom eksperyment i wyświetl dane wyjściowe z modułu Score Model, klikając port wyjściowy Score Model i wybierając opcję Visualize. Dane wyjściowe zawierają przewidywane wartości cen oraz znane wartości pochodzące z danych testowych.
Na koniec przetestujemy jakość wyników. Wybierz moduł Evaluate Model (Ocena modelu) i przeciągnij go do obszaru roboczego eksperymentu, a następnie połącz wyjście modułu Score Model (Generowanie wyników przez model) z lewym wejściem modułu Evaluate Model (Ocena modelu). Końcowy eksperyment powinien wyglądać następująco:
Uruchom eksperyment.
Aby wyświetlić dane wyjściowe z modułu Evaluate Model (Ocena modelu), kliknij port wyjściowy i wybierz pozycję Visualize (Wizualizacja).
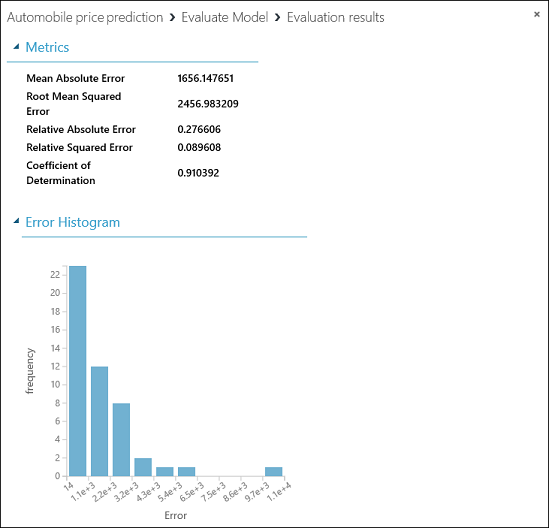
Wyświetlane są następujące statystyki dla modelu:
- Średni bezwzględny błąd (MAE, Mean Absolute Error): wartość średnia bezwzględnych błędów (błąd odpowiada różnicy między wartością prognozowaną a wartością rzeczywistą).
- Pierwiastek błędu średniokwadratowego (RMSE, Root Mean Squared Error): pierwiastek kwadratowy ze średniej kwadratów błędów prognoz dla zestawu danych testowych.
- Względny błąd absolutny: średnia z błędów absolutnych w odniesieniu do bezwzględnej różnicy między wartościami rzeczywistymi a średnią wszystkich wartości rzeczywistych.
- Błąd względny średniokwadratowy: Średnia kwadratów błędów względem kwadratowej różnicy między wartościami rzeczywistymi a średnią wszystkich wartości rzeczywistych.
- Współczynnik determinacji: znany także jako wartość R-kwadrat jest miarą statystyczną jakości dopasowania modelu do danych.
W przypadku każdej z tych statystyk, mniejsze wartości są lepsze. Mniejsze wartości błędów wskazują na ściślejsze dopasowanie prognoz do rzeczywistych wartości. W przypadku współczynnika determinacji prognozy są tym lepsze, im jego wartość jest bliższa jedności (1,0).
Czyszczenie zasobów
Jeśli nie potrzebujesz już zasobów, które zostały utworzone w tym artykule, usuń je, aby uniknąć ponoszenia opłat. Aby dowiedzieć się, jak to zrobić, zapoznaj się z artykułem Export and delete in-product user data (Eksportowanie i usuwanie danych użytkownika w produkcie).
Następne kroki
W tym szybkim przewodniku utworzyłeś prosty eksperyment przy użyciu przykładowego zestawu danych. Aby bardziej szczegółowo zapoznać się z procesem tworzenia i wdrażania modelu, przejdź do samouczka dotyczącego rozwiązań do analizy predykcyjnej.