Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() programu SQL Server
programu SQL Server
W tym artykule przedstawiono pojęcia dotyczące zawsze włączonych grup dostępności, które są centralne do konfigurowania co najmniej jednej grupy dostępności i zarządzania nimi w wersji Enterprise programu SQL Server. W przypadku wersji Standard sprawdź Podstawowe Zawsze Włączone grupy dostępności dla pojedynczej bazy danych.
Funkcja grupy dostępności Always On to rozwiązanie zapewniające wysoką dostępność i odzyskiwanie po awarii, które oferuje alternatywę na poziomie korporacyjnym dla mirroringu baz danych. Grupy dostępności Always On maksymalizują dostępność zestawu baz danych użytkowników dla przedsiębiorstwa. Grupa dostępności obsługuje środowisko trybu failover dla dyskretnego zestawu baz danych użytkowników, znanych jako bazy danych dostępności , które przełączają się jednocześnie. Grupa dostępności obsługuje zestaw podstawowych baz danych odczytu i zapisu oraz jeden do ośmiu zestawów odpowiednich pomocniczych baz danych. Opcjonalnie pomocnicze bazy danych można udostępnić na potrzeby dostępu tylko do odczytu i/lub niektórych operacji tworzenia kopii zapasowych.
W przypadku programu SQL Server włączonego przez usługę Azure Arcmożna wyświetlić grupy dostępności w witrynie Azure Portal.
Przegląd
Grupa dostępności obsługuje zreplikowane środowisko dla odrębnego zestawu baz danych użytkowników, znanych jako bazy danych dostępności . Możesz utworzyć grupę dostępności dla wysokiej dostępności (HA) lub zwiększenia skali odczytu. Grupa wysokiej dostępności to grupa baz danych, które razem przełączają się w tryb awaryjny. Grupa dostępności w skali odczytu to grupa baz danych, które są kopiowane do innych wystąpień programu SQL Server na potrzeby obciążenia tylko do odczytu. Grupa dostępności obsługuje jeden zestaw podstawowych baz danych i jeden do ośmiu zestawów odpowiednich pomocniczych baz danych. Pomocnicze bazy danych nie są kopiami zapasowymi. Kontynuuj regularne tworzenie kopii zapasowych baz danych i dzienników transakcji.
Napiwek
Możesz utworzyć dowolną kopię zapasową podstawowej bazy danych. Alternatywnie można tworzyć kopie zapasowe dzienników i kopiować pełne kopie zapasowe drugorzędnych baz danych. Aby uzyskać więcej informacji, zobacz Przekazywanie obsługiwanych kopii zapasowych do replik pomocniczych w grupie dostępności.
Każdy zestaw baz danych dostępności jest obsługiwany przez replikę dostępności . Istnieją dwa typy replik dostępności: jedna replika podstawowa, która hostuje podstawowe bazy danych, a od jednej do ośmiu replik pomocniczych, z których każda hostuje zestaw pomocniczych baz danych i służy jako potencjalne cele przełączenia awaryjnego dla grupy dostępności. Grupa dostępności przełączy się w tryb failover na poziomie repliki dostępności. Replika dostępności zapewnia nadmiarowość tylko na poziomie bazy danych dla zestawu baz danych w jednej grupie dostępności. Przełączenia awaryjne nie są spowodowane problemami z bazą danych, takimi jak oznaczenie bazy danych jako podejrzanej z powodu utraty pliku danych lub korupcji dziennika transakcji.
Podstawowa replika umożliwia dostęp do podstawowych baz danych dla połączeń klientów wymagających odczytu i zapisu. Replika podstawowa wysyła rekordy dziennika transakcji każdej podstawowej bazy danych do każdej pomocniczej bazy danych. Ten proces - znany jako synchronizacja danych - występuje na poziomie bazy danych. Każda replika pomocnicza buforuje rekordy dziennika transakcji (zabezpiecza dziennika), a następnie stosuje je do odpowiedniej pomocniczej bazy danych. Synchronizacja danych odbywa się między podstawową bazą danych a każdą połączoną pomocniczą bazą danych niezależnie od innych baz danych. W związku z tym pomocnicza baza danych może zakończyć się niepowodzeniem lub zostać zawieszona bez wpływu na inne pomocnicze bazy danych, a podstawowa baza danych może zakończyć się niepowodzeniem lub zostać zawieszona bez wpływu na inne podstawowe bazy danych.
Opcjonalnie można skonfigurować co najmniej jedną replikę pomocniczą w celu obsługi dostępu tylko do odczytu do pomocniczych baz danych i skonfigurować dowolną replikę pomocniczą tak, aby zezwalała na tworzenie kopii zapasowych w pomocniczych bazach danych.
Program SQL Server 2017 (14.x) wprowadził dwie różne architektury dla grup dostępności. zawsze włączone grupy dostępności zapewniają wysoką dostępność, odzyskiwanie po awarii i równoważenie skali odczytu. Te grupy dostępności wymagają menedżera klastra. W systemie Windows funkcja klastrowania typu failover zapewnia menedżera klastra. W systemie Linux można użyć narzędzia Pacemaker. Druga architektura to grupa dostępności skalowana do odczytu. Grupa dostępności do skalowania odczytu zapewnia repliki dla obciążeń tylko do odczytu, ale nie zapewnia wysokiej dostępności. W grupie dostępności skalowania odczytu nie ma menedżera klastra, ponieważ przełączanie awaryjne nie może być automatyczne.
Wdrażanie grup dostępności Always On dla wysokiej dostępności (HA) w systemie Windows wymaga klastra trybu failover Windows Server (WSFC). Każda replika dostępności danej grupy dostępności musi znajdować się w innym węźle tego samego programu WSFC. Jedynym wyjątkiem jest to, że podczas migracji do innego klastra WSFC grupa dostępności może tymczasowo znajdować się pomiędzy dwoma klastrami.
Notatka
Aby uzyskać informacje o grupach dostępności w systemie Linux, zobacz Grupy dostępności dla programu SQL Server w systemie Linux.
Dla każdej utworzonej grupy dostępności w konfiguracji wysokiej dostępności tworzona jest rola klastra. Klaster WSFC monitoruje tę rolę w celu oceny kondycji repliki podstawowej. Kworum dla zawsze włączonych grup dostępności jest oparte na wszystkich węzłach w klastrze WSFC niezależnie od tego, czy dany węzeł klastra hostuje jakiekolwiek repliki dostępności. W przeciwieństwie do mirroring bazy danych nie ma roli świadka w grupach dostępności Always On.
Notatka
Aby uzyskać informacje na temat relacji składników programu SQL Server Always On z klastrem WSFC, zobacz Klaster trybu failover systemu Windows Server za pomocą programu SQL Server.
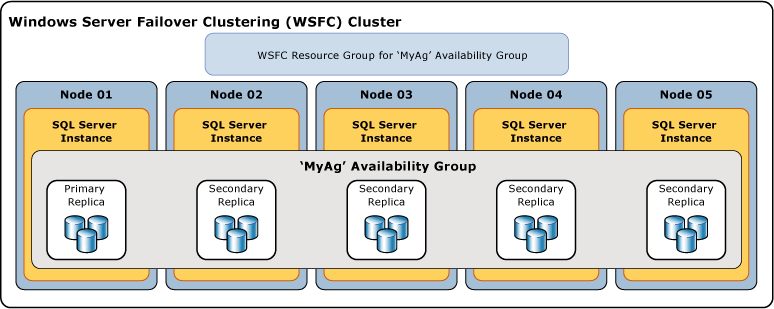
Poniższa ilustracja przedstawia grupę dostępności zawierającą jedną replikę podstawową i cztery repliki pomocnicze. Obsługiwane są maksymalnie osiem replik pomocniczych, w tym jedna replika podstawowa i cztery repliki pomocnicze zatwierdzane synchronicznie.
Konfigurowanie szyfrowania TLS 1.3
Program SQL Server 2025 (17.x) wprowadza obsługę Strumienia Danych Tabelarycznych 8.0, co umożliwia wymuszanie szyfrowania TLS 1.3 na potrzeby komunikacji między klastrem trybu failover w systemie Windows Server a replikami grupy dostępności Always On.
Aby uzyskać więcej informacji, zobacz Obsługa TDS 8 w programie SQL Server 2025 w dalszej części tego artykułu.
Aby rozpocząć, zapoznaj się z artykułem Nawiązywanie połączenia za pomocą ścisłego szyfrowania.
Terminy i definicje
| Termin | Opis |
|---|---|
| grupy dostępności | Kontener dla zestawu baz danych, baz danych dostępności, które przechodzą w tryb failover razem. |
| bazy danych dostępności | Baza danych należąca do grupy dostępności. Dla każdej bazy danych dostępności grupa dostępności utrzymuje pojedynczą kopię do odczytu i zapisu (podstawowa baza danych ) oraz od jednej do ośmiu kopii tylko do odczytu (pomocnicze bazy danych). |
| podstawowa baza danych | Kopia odczytu i zapisu bazy danych dostępności. |
| pomocniczej bazy danych | Kopia bazy danych dostępnej tylko do odczytu. |
| replika dostępności | Utworzenie instancji grupy dostępności przez określone wystąpienie programu SQL Server, które hostuje i utrzymuje lokalną kopię każdej bazy danych należącej do grupy dostępności. Istnieją dwa typy replik dostępności: pojedyncza replika podstawowa i jedna do ośmiu replik pomocniczych. |
| podstawowa replika | Replika dostępności, która udostępnia podstawowe bazy danych do połączeń odczytu i zapisu od użytkowników, a także wysyła rekordy dziennika transakcji dla każdej podstawowej bazy danych do każdej repliki pomocniczej. |
| replika pomocnicza | Replika dostępności, która utrzymuje pomocniczą kopię każdej bazy danych dostępności i służy jako potencjalny cel przełączenia awaryjnego dla grupy dostępności. Opcjonalnie replika pomocnicza może obsługiwać dostęp tylko do odczytu do pomocniczych baz danych może obsługiwać tworzenie kopii zapasowych w pomocniczych bazach danych. |
| słuchacz grupy dostępności | Nazwa serwera, z którym klienci mogą się łączyć w celu uzyskania dostępu do bazy danych w podstawowej lub pomocniczej repliki grupy dostępności. Słuchawki grupy dostępności kierują połączenia przychodzące do repliki podstawowej lub do repliki pomocniczej w trybie tylko do odczytu. |
Bazy danych dostępności
Aby dodać bazę danych do grupy dostępności, baza danych musi być online, z możliwością odczytu i zapisu, która istnieje w wystąpieniu serwera, które hostuje replikę podstawową. Gdy dodasz bazę danych, dołącza ona do grupy dostępności jako główna baza danych, jednocześnie pozostając dostępną dla klientów. Nie istnieje odpowiednia pomocnicza baza danych, aż do chwili przywrócenia kopii zapasowych nowej podstawowej bazy danych do instancji serwera, która hostuje replikę pomocniczą (przy użyciu polecenia RESTORE WITH NORECOVERY). Nowa drugorzędna baza danych znajduje się w RESTORING stanie, dopóki nie zostanie dołączona do grupy dostępności. Aby uzyskać więcej informacji, zobacz Rozpoczynanie ruchu danych na zawsze aktywnej bazie danych podrzędnej (SQL Server).
Dołączanie powoduje umieszczenie pomocniczej bazy danych w ONLINE stanie i zainicjowanie synchronizacji danych z odpowiednią podstawową bazą danych.
synchronizacja danych jest procesem, w którym zmiany w głównej bazie danych są replikowane w pomocniczej bazie danych. Synchronizacja danych obejmuje podstawową bazę danych wysyłającą rekordy dziennika transakcji do pomocniczej bazy danych.
Ważny
Baza danych dostępności jest czasami nazywana repliką bazy danych w nazwach, takich jak Transact-SQL, PowerShell i SQL Server Management Objects (SMO). Na przykład termin "replika bazy danych" jest używany w nazwach dynamicznych widoków zarządzania Always On, które zwracają informacje o bazach danych dostępności: sys.dm_hadr_database_replica_states i sys.dm_hadr_database_replica_cluster_states. Jednak w dokumentacji online programu SQL Server termin "replika" zwykle odnosi się do replik dostępności. Na przykład "replika podstawowa" i "replika pomocnicza" zawsze odwołują się do replik wysokiej dostępności.
Repliki dostępności
Każda grupa dostępności definiuje zestaw co najmniej dwóch partnerów trybu failover nazywanych replikami dostępności. repliki dostępności są składnikami grupy dostępności. Każda replika dostępności hostuje kopię baz danych dostępności w grupie dostępności. W przypadku danej grupy dostępności oddzielne instancje SQL Server znajdujące się na różnych węzłach klastra WSFC muszą hostować repliki dostępności. Każde z tych wystąpień serwera musi być włączone dla funkcji Always On.
Program SQL Server 2019 (15.x) zwiększa maksymalną liczbę replik synchronicznych do 5, z 3 w programie SQL Server 2017 (14.x). Tę grupę pięciu replik można skonfigurować tak, aby w grupie występowało automatyczne przełączanie awaryjne. Istnieje jedna replika podstawowa oraz cztery synchroniczne repliki pomocnicze.
Dana instancja może hostować tylko jedną replikę dostępności na grupę dostępności. Można jednak użyć każdego wystąpienia dla wielu grup dostępności. Dane wystąpienie może być wystąpieniem autonomicznym lub wystąpieniem klastra trybu failover programu SQL Server . Jeśli potrzebujesz redundancji na poziomie serwera, użyj wystąpień klastra przełączania awaryjnego.
Każda replika dostępności ma przypisaną rolę początkową — rolę podstawową lub rolę pomocniczą, którą dziedziczą bazy danych dostępności tej repliki. Rola danej repliki określa, czy hostuje bazy danych do odczytu i zapisu, czy bazy danych tylko do odczytu. Jedna replika, znana jako replika podstawowa , ma przypisaną rolę podstawową i hostuje bazy danych do odczytu i zapisu, które są znane jako podstawowe bazy danych . Co najmniej jedna inna replika, znana jako replika pomocnicza, ma przypisaną rolę pomocniczą. Replika pomocnicza hostuje bazy danych tylko do odczytu, znane jako pomocnicze bazy danych.
Notatka
Gdy rola repliki wysokiej dostępności jest nieokreślona, na przykład podczas przełączenia awaryjnego, jej bazy danych są tymczasowo w NOT SYNCHRONIZING stanie. Ich rola jest ustawiana na RESOLVING, dopóki rola repliki dostępności nie zostanie rozstrzygnięta. Jeśli replika dostępności przyjmie rolę podstawową, jej bazy danych staną się bazami danych podstawowymi. Jeśli replika dostępności przyjmuje rolę pomocniczą, jej bazy danych stają się pomocniczymi bazami danych.
Tryby dostępności
Każda replika dostępności ma właściwość trybu dostępności. Tryb dostępności określa, czy replika podstawowa czeka na zatwierdzenie transakcji w bazie danych, dopóki dana replika pomocnicza nie zapisze rekordów dziennika transakcji na dysku (wzmacnia zabezpieczenia dziennika). Grupy dostępności Always On obsługują dwa tryby dostępności: tryb zatwierdzania asynchronicznego i tryb zatwierdzania synchronicznego.
tryb zatwierdzania asynchronicznego
Replika dostępności korzystająca z tego trybu dostępności jest nazywana repliką asynchroniczną. W trybie zatwierdzania asynchronicznego replika podstawowa zatwierdza transakcje bez oczekiwania na potwierdzenie z replik pomocniczych zatwierdzeń asynchronicznych w celu zabezpieczenia dzienników transakcji. Tryb zatwierdzania asynchronicznego minimalizuje opóźnienie transakcji w pomocniczych bazach danych, ale pozwala im pozostać w tyle za podstawowymi bazami danych, co może prowadzić do utraty niektórych danych.
tryb zatwierdzania synchronicznego
Replika dostępności, która używa tego trybu dostępności, jest znana jako replika synchronicznego zatwierdzenia. W trybie zatwierdzania synchronicznego, przed zatwierdzeniem transakcji, replika podstawowa czeka na potwierdzenie od repliki pomocniczej, że zakończono utrwalenie dziennika. Tryb zatwierdzania synchronicznego zapewnia, że po zsynchronizowaniu danej pomocniczej bazy danych z podstawową bazą danych zatwierdzone transakcje są w pełni chronione. Ta ochrona wiąże się z kosztem zwiększonego opóźnienia transakcji. Opcjonalnie program SQL Server 2017 (14.x) wprowadził wymaganą funkcję synchronizowanych modułów pomocniczych w celu dalszego zwiększenia bezpieczeństwa kosztem opóźnienia w razie potrzeby. Tę funkcję
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITmożna włączyć, aby wymagać określonej liczby replik synchronicznych do zatwierdzenia transakcji, zanim podstawowa replika będzie mogła zatwierdzić.
Aby uzyskać więcej informacji, zobacz Różnice między trybami dostępności dla zawsze włączonej grupy dostępności.
Typy przełączenia awaryjnego
W kontekście sesji między repliką podstawową a repliką wtórną role podstawowe i wtórne mogą przełączać się w procesie znanym jako failover. Podczas pracy w trybie failover docelowa replika pomocnicza przechodzi do roli podstawowej i staje się nową repliką podstawową. Nowa replika podstawowa przenosi swoje bazy danych w tryb online jako podstawowe bazy danych, a aplikacje klienckie mogą się z nimi łączyć. Gdy dawna replika podstawowa jest dostępna, zmienia się na stanowisko drugorzędne i staje się repliką drugorzędną. Poprzednie podstawowe bazy danych stają się pomocniczymi bazami danych, a synchronizacja danych zostanie wznowione.
Grupa dostępności przełączy się w tryb failover na poziomie repliki dostępności. Zdarzenia failover nie występują z powodu problemów z bazą danych, na przykład uznania bazy danych za podejrzaną w wyniku utracenia pliku danych, usunięcia bazy danych lub uszkodzenia dziennika transakcji.
Istnieją trzy formy trybu failover: automatyczne, ręczne i wymuszone (z możliwością utraty danych). Forma lub formy przełączenia awaryjnego obsługiwane przez daną replikę pomocniczą zależą od trybu jej dostępności. W trybie zatwierdzania synchronicznego zależy to również od trybu failover dla repliki podstawowej i docelowej kopii zapasowej, jak opisano poniżej.
Tryb zatwierdzania synchronicznego obsługuje dwie formy trybu failover: planowany ręczny tryb failover i automatyczny tryb failover, jeśli docelowa replika pomocnicza jest obecnie synchronizowana z repliką podstawową. Ustawienie właściwości trybu failover dla partnerów trybu failover określa obsługę tych form trybu failover. Jeśli ustawisz tryb awaryjny na ręczny na którejkolwiek z replik podstawowej lub pomocniczej, replika pomocnicza obsługuje tylko ręczne przełączenie awaryjne. Jeśli tryb failover zostanie ustawiony na automatyczny zarówno w replikach głównych, jak i pomocniczych, replika pomocnicza obsługuje zarówno automatyczne, jak i ręczne przejście do trybu failover.
planowane ręczne przełączenie awaryjne (bez utraty danych)
Ręczne awaryjne przełączenie następuje po wydaniu przez administratora bazy danych polecenia failover. Powoduje to przejście zsynchronizowanej repliki pomocniczej do roli podstawowej (z gwarantowaną ochroną danych) i zmienia replikę podstawową na rolę pomocniczą. Ręczne przejście w tryb failover wymaga, aby zarówno replika podstawowa, jak i docelowa replika pomocnicza były uruchamiane w trybie zatwierdzania synchronicznego, a replika pomocnicza musi być już zsynchronizowana.
automatyczne przełączenie awaryjne (bez utraty danych)
Automatyczne przejście w tryb failover odbywa się w odpowiedzi na awarię. Powoduje, że zsynchronizowana replika pomocnicza przechodzi do roli podstawowej (z gwarantowaną ochroną danych). Gdy była replika podstawowa stanie się dostępna, przyjmuje rolę pomocniczą. Automatyczne przełączanie w tryb failover wymaga, aby zarówno replika podstawowa, jak i docelowa replika pomocnicza były uruchamiane w trybie synchronicznego zatwierdzania z trybem trybu failover ustawionym na Wartość Automatyczna. Ponadto replika pomocnicza musi być już zsynchronizowana, mieć kworum WSFC i spełniać warunki określone przez elastyczną politykę failover grupy dostępności.
W trybie zatwierdzania asynchronicznego jedyną formą trybu failover jest wymuszone ręczne przejście w tryb failover (z możliwością utraty danych), zwykle nazywane wymuszonym trybem failover. Wymuszone przełączenie w tryb failover to forma ręcznego przełączenia, ponieważ musi być zainicjowane ręcznie. Wymuszone przejście w tryb failover to opcja odzyskiwania po awarii. Jest to jedyna forma mechanizmu przełączania awaryjnego, która jest możliwa, gdy docelowa replika pomocnicza nie jest zsynchronizowana z repliką podstawową.
Aby uzyskać więcej informacji, zobacz tryby failover i tryby działania trybu failover (grupy dostępności Always On).
Ważny
- Instancje klastra trybu failover SQL Server (FCI) nie obsługują automatycznego przełączenia przez grupy dostępności, więc można skonfigurować ręczny failover tylko dla dowolnej repliki dostępności, którą hostuje instancja klastra trybu failover.
- Jeśli wydasz polecenie wymuszonego przełączenia awaryjnego na zsynchronizowanej replice pomocniczej, replika pomocnicza zachowuje się tak samo jak w przypadku planowanego ręcznego przełączenia awaryjnego.
Korzyści
Zawsze włączone grupy dostępności udostępniają bogaty zestaw opcji, które zwiększają dostępność bazy danych i zwiększają wykorzystanie zasobów. Kluczowe składniki są następujące:
Obsługuje maksymalnie dziewięć replik dostępności. Replika dostępności jest wystąpieniem grupy dostępności, które hostuje określone wystąpienie programu SQL Server. Przechowuje lokalną kopię każdej bazy danych dostępności, która należy do grupy dostępności. Każda grupa dostępności obsługuje jedną replikę podstawową i maksymalnie osiem replik pomocniczych. Aby uzyskać więcej informacji, zobacz Co to jest grupa dostępności Always On?
Ważny
Każda replika dostępności musi znajdować się w innym węźle pojedynczego klastra trybu failover systemu Windows Server (WSFC). Aby uzyskać więcej informacji na temat wymagań wstępnych, ograniczeń i zaleceń dotyczących grup dostępności, zobacz Wymagania wstępne, ograniczenia i zalecenia dotyczące zawsze włączonych grup dostępności.
Obsługuje alternatywne tryby dostępności w następujący sposób:
tryb zatwierdzania asynchronicznego. Ten tryb dostępności to rozwiązanie odzyskiwania po awarii, które działa dobrze, gdy repliki dostępności są rozproszone na znaczne odległości.
tryb zatwierdzania synchronicznego. Ten tryb dostępności podkreśla wysoką dostępność i ochronę danych w zakresie wydajności, kosztem zwiększonego opóźnienia transakcji. Dana grupa dostępności może obsługiwać maksymalnie pięć replik z synchronizowanym zatwierdzaniem dostępności, wliczając obecną replikę podstawową.
Aby uzyskać więcej informacji, zobacz Różnice między trybami dostępności dla zawsze włączonej grupy dostępności.
Obsługuje kilka form przełączenia grupy dostępności: automatyczne przełączanie, planowane ręczne przełączenie (zazwyczaj nazywane ręcznym przełączeniem) oraz wymuszone ręczne przełączenie (zazwyczaj nazywane wymuszonym przełączeniem). Aby uzyskać więcej informacji, zobacz tryby failover i tryby działania trybu failover (grupy dostępności Always On).
Umożliwia skonfigurowanie danej repliki dostępności w celu obsługi jednej z poniższych lub obu aktywnych funkcji pomocniczych:
Dostęp do połączeń tylko do odczytu, który umożliwia nawiązywanie takich połączeń z repliką w celu uzyskania dostępu do jej baz danych i ich odczytu, gdy działa jako replika wtórna. Aby uzyskać więcej informacji, zobacz Odciążanie obciążenia tylko do odczytu do pomocniczej repliki zawsze włączonej grupy dostępności.
Wykonywanie operacji tworzenia kopii zapasowych w bazach danych, gdy jest uruchomiona jako replika pomocnicza. Aby uzyskać więcej informacji, zobacz Przekazywanie obsługiwanych kopii zapasowych do replik pomocniczych w grupie dostępności.
Korzystanie z aktywnych funkcji pomocniczych zwiększa wydajność IT i zmniejsza koszty dzięki lepszemu wykorzystaniu zasobów pomocniczego sprzętu. Ponadto przenoszenie aplikacji ukierunkowanych na odczyt i zadań tworzenia kopii zapasowych do replik drugorzędnych pomaga zwiększyć wydajność repliki podstawowej.
Obsługuje odbiornik grupy dostępności dla każdej grupy dostępności. Nasłuchiwacz grupy dostępności Always On to nazwa serwera, z którą klienci mogą się łączyć, aby uzyskać dostęp do bazy danych w podstawowej lub wtórnej repliki grupy dostępności Always On. Słuchawki grupy dostępności kierują połączenia przychodzące do repliki podstawowej lub do repliki pomocniczej w trybie tylko do odczytu. Nasłuchiwacz zapewnia szybkie awaryjne przełączenie aplikacji po przełączeniu grupy dostępności. Aby uzyskać więcej informacji, zobacz Połącz się z odbiornikiem grupy dostępności Always On.
Obsługuje elastyczną politykę przełączania awaryjnego, zapewniającą większą kontrolę nad przełączaniem w grupach dostępności. Aby uzyskać więcej informacji, zobacz tryby failover i tryby działania trybu failover (grupy dostępności Always On).
Obsługuje automatyczną naprawę strony w celu ochrony przed uszkodzeniem strony. Aby uzyskać więcej informacji, zobacz automatyczna naprawa strony (grupy dostępności: dublowanie bazy danych).
Obsługuje szyfrowanie i kompresję, która zapewnia bezpieczny, wydajny transport.
Zapewnia zintegrowany zestaw narzędzi upraszczających wdrażanie grup dostępności i zarządzanie nimi, w tym:
Transact-SQL instrukcje DDL służące do tworzenia grup dostępności i zarządzania nimi. Aby uzyskać więcej informacji, zobacz dokumentację Transact-SQL dla Always On grup dostępności.
Narzędzia SQL Server Management Studio w następujący sposób:
Kreator nowej grupy dostępności tworzy i konfiguruje grupę dostępności. W niektórych środowiskach ten kreator może również automatycznie przygotować pomocnicze bazy danych i rozpocząć synchronizację danych dla każdego z nich. Aby uzyskać więcej informacji, zobacz Okno dialogowe Używanie nowej grupy dostępności (SQL Server Management Studio).
Kreator dodawania bazy danych do grupy dostępności dodaje jedną lub więcej podstawowych baz danych do istniejącej grupy dostępności. W niektórych środowiskach ten kreator może również automatycznie przygotować pomocnicze bazy danych i rozpocząć synchronizację danych dla każdego z nich. Aby uzyskać więcej informacji, zobacz Dodawanie bazy danych do zawsze włączonej grupy dostępności za pomocą Kreatora grupy dostępności.
Kreator dodawania repliki do grupy dostępności dodaje jedną lub więcej replik wtórnych do istniejącej grupy dostępności. W niektórych środowiskach ten kreator może również automatycznie przygotować pomocnicze bazy danych i rozpocząć synchronizację danych dla każdego z nich. Aby uzyskać więcej informacji, zobacz Dodawanie repliki do grupy dostępności Always On przy użyciu kreatora grupy dostępności w programie SQL Server Management Studio.
Kreator grupy dostępności trybu failover inicjuje ręczne przejście w tryb failover w grupie dostępności. W zależności od konfiguracji i stanu repliki pomocniczej, którą określisz jako docelową dla trybu failover, kreator może wykonać zaplanowane lub wymuszone ręczne przełączenie. Aby uzyskać więcej informacji, zobacz Skorzystaj z kreatora grupy dostępności FailOver (SQL Server Management Studio).
Pulpit nawigacyjny Always On monitoruje grupy dostępności Always On, repliki dostępności i bazy danych dostępności oraz ocenia wyniki dla zasad Always On. Aby uzyskać więcej informacji, zobacz używanie konsoli Always On Availability Group (SQL Server Management Studio).
W okienku Szczegóły Eksploratora obiektów są wyświetlane podstawowe informacje o istniejących grupach dostępności. Aby uzyskać więcej informacji, zobacz Używanie szczegółów Eksploratora obiektów do monitorowania grup dostępności.
Polecenia cmdlet programu PowerShell. Aby uzyskać więcej informacji, zobacz Omówienie poleceń cmdlet programu PowerShell dla zawsze włączonych grup dostępności.
Połączenia klienta
Możesz zapewnić łączność klienta z repliką podstawową danej grupy dostępności, tworząc odbiornik grupy dostępności. Odbiornik grupy dostępności udostępnia zestaw zasobów dołączonych do danej grupy dostępności w celu kierowania połączeń klientów z odpowiednią repliką dostępności.
Nasłuchiwacz grupy dostępności jest skojarzony z unikatową nazwą DNS, która służy jako nazwa sieci wirtualnej (VNN), jednym lub wieloma wirtualnymi adresami IP (VIP) oraz numerem portu TCP. Aby uzyskać więcej informacji, zobacz Połącz się z odbiornikiem grupy dostępności Always On.
Jeśli grupa dostępności ma tylko dwie repliki dostępności i nie jest skonfigurowana tak, aby zezwalała na dostęp do odczytu do repliki pomocniczej, klienci mogą łączyć się z repliką podstawową przy użyciu parametrów połączenia dublowania bazy danych. Takie podejście może być przydatne tymczasowo po migracji bazy danych z mirroringu bazy danych do Grup dostępności Always On. Przed dodaniem replik pomocniczych należy utworzyć listener dla grupy dostępności i zaktualizować aplikacje tak, aby używały nazwy sieciowej listenera.
Obsługa TDS 8 w programie SQL Server 2025
Program SQL Server 2025 (17.x) wprowadza obsługę protokołu TDS 8.0, co umożliwia wymuszanie ścisłego szyfrowania TLS 1.3 dla połączeń z replikami i odbiornikiem zawsze włączonej grupy dostępności.
Wymagania dotyczące konfiguracji:
-
Istniejące grupy dostępności: Zmień AG używając klauzuli
CLUSTER_CONNECTION_OPTIONS, aby ustawićEncrypt=Strict, oraz przeprowadź failover w celu zastosowania tych ustawień. - Wymuś ścisłe szyfrowanie: ustaw tę opcję na Wartość Tak w menedżerze konfiguracji programu SQL Server dla każdej repliki i uruchom ponownie repliki programu SQL Server.
-
Wymagania dotyczące certyfikatu: po
Encrypt=StrictustawieniuTrustServerCertificatejest ignorowany.
Aby rozpocząć, zapoznaj się z artykułem Nawiązywanie połączenia za pomocą ścisłego szyfrowania.
Aktywne repliki wtórne
Grupy dostępności Always On obsługują aktywne wtórne repliki. Aktywne możliwości pomocnicze obejmują obsługę:
wykonywanie operacji tworzenia kopii zapasowych na replikach pomocniczych
Repliki pomocnicze obsługują wykonywanie kopii zapasowych dziennika i kopii tylko do kopiowania kopii zapasowych pełnej bazy danych, pliku lub grupy plików. Możesz skonfigurować grupę dostępności, aby określić preferencje dotyczące miejsca wykonywania kopii zapasowych. Ważne jest, aby zrozumieć, że program SQL Server nie wymusza preferencji, dlatego nie ma wpływu na kopie zapasowe ad hoc. Interpretacja tej preferencji zależy od logiki, o ile w ogóle taka istnieje, zapisanej w skryptach zadań tworzenia kopii zapasowej dla każdej z baz danych w danej grupie dostępności. W przypadku pojedynczej repliki dostępności można określić priorytet wykonywania kopii zapasowych tej repliki względem innych replik w tej samej grupie dostępności. Aby uzyskać więcej informacji, zobacz Przekazywanie obsługiwanych kopii zapasowych do replik pomocniczych w grupie dostępności.
Dostęp tylko do odczytu do jednej lub więcej replik pomocniczych (replik z możliwością odczytu)
Można skonfigurować dowolną replikę dostępności pomocniczej tak, aby zezwalała na dostęp tylko do odczytu do lokalnych baz danych, chociaż niektóre operacje nie są w pełni obsługiwane. Ta konfiguracja uniemożliwia próby nawiązania połączenia odczytu i zapisu z repliką pomocniczą. Istnieje również możliwość zapobiegania obciążeniom z dostępem tylko do odczytu na podstawowej replice poprzez zezwalanie jedynie na dostęp do odczytu i zapisu. Ta konfiguracja uniemożliwia nawiązywanie połączeń do repliki podstawowej w trybie tylko do odczytu. Aby uzyskać więcej informacji, zobacz Odciążanie obciążenia tylko do odczytu do pomocniczej repliki zawsze włączonej grupy dostępności.
Jeśli grupa dostępności ma obecnie nasłuchiwacz grupy dostępności i co najmniej jedną replikę pomocniczą z możliwością odczytu, program SQL Server może kierować żądania połączeń z intencją odczytu do jednej z nich (routing tylko do odczytu). Aby uzyskać więcej informacji, zobacz Połącz się z odbiornikiem grupy dostępności Always On.
Okres limitu czasu sesji
Okres czasu limitu sesji jest parametrem availability-replica, który określa, jak długo połączenie z inną repliką może pozostać nieaktywne przed zamknięciem połączenia. Podstawowe i zapasowe repliki przesyłają między sobą sygnał, aby zasygnalizować, że nadal są aktywne. Odbieranie polecenia ping z drugiej repliki w trakcie okresu limitu czasu wskazuje, że połączenie jest nadal otwarte i że instancje serwera komunikują się. Po otrzymaniu polecenia ping replika dostępności wyzerowuje licznik czasu wygaśnięcia sesji w tym połączeniu.
Okres limitu czasu sesji zapobiega temu, aby któraś z replik czekała na czas nieokreślony na odebranie polecenia ping od drugiej repliki. Jeśli polecenie ping nie zostanie odebrane z innej repliki w okresie limitu czasu sesji, replika przekracza limit czasu. Jej połączenie zostaje zamknięte, a replika, która przekroczyła limit czasu, wchodzi w stan DISCONNECTED. Nawet jeśli rozłączona replika jest skonfigurowana dla trybu zatwierdzania synchronicznego, transakcje nie czekają na ponowne nawiązanie połączenia z repliką i ponowną synchronizację.
Domyślny okres limitu czasu sesji dla każdej repliki dostępności wynosi 10 sekund. Możesz skonfigurować tę wartość, przy czym minimum wynosi 5 sekund. Ogólnie rzecz biorąc, utrzymuj czas oczekiwania na poziomie 10 sekund lub dłużej. Ustawienie wartości na mniej niż 10 sekund stwarza możliwość, że system o dużym obciążeniu błędnie zadeklaruje awarię.
Notatka
W roli rozwiązywania limit czasu sesji nie ma zastosowania, ponieważ pingowanie nie występuje.
Automatyczna naprawa strony
Każda replika dostępności próbuje automatycznie odzyskać uszkodzone strony w lokalnej bazie danych, usuwając niektóre typy błędów, które uniemożliwiają odczytywanie strony danych. Jeśli replika pomocnicza nie może odczytać strony, replika żąda nowej kopii strony z repliki podstawowej. Jeśli replika podstawowa nie może odczytać strony, replica wysyła żądanie nowej kopii do wszystkich replik zapasowych i pobiera stronę od pierwszej, która odpowiedziała. Jeśli to żądanie powiedzie się, nieczytelna strona zostanie zamieniona na kopię, co zwykle rozwiązuje błąd.
Aby uzyskać więcej informacji, zobacz automatyczna naprawa strony (grupy dostępności: dublowanie bazy danych).
Współdziałanie i współistnienie z innymi funkcjami aparatu bazy danych
Grupy dostępności Always On współdziałają z następującymi funkcjami lub składnikami programu SQL Server:
- Co to jest przechwytywanie danych zmian (CDC)?
- Informacje o usłudze Change Tracking (SQL Server)
- Zamknięte bazy danych
- Przezroczyste szyfrowanie danych (TDE)
- Migawki bazy danych z zawsze włączonymi grupami dostępności (SQL Server)
- FILESTREAM (SQL Server)
- FileTables (SQL Server)
- Informacje o wysyłaniu dzienników (SQL Server)
- Zdalny Magazyn Obiektów Blob (RBS) (SQL Server)
- Replikacja SQL Server
- Broker usług
- agenta programu SQL Server
- Reporting Services z zawsze włączonymi grupami dostępności (SQL Server)
- Zarządca zasobów
- TDS 8.0, począwszy od programu SQL Server 2025 (17.x)
Powiązane zadania
- Wymagania wstępne, ograniczenia i zalecenia dotyczące Always On availability groups
- Referencja dotycząca tworzenia i konfigurowania Always On grup dostępności
- Administracja grupy dostępności
- Narzędzia do monitorowania Zawsze Włączonych Grup Dostępności
- Przeniesienie obciążenia tylko do odczytu do pomocniczej repliki Always On grupy dostępności
- Przeniesienie obsługiwanych kopii zapasowych na repliki pomocnicze w grupie dostępności
- Nawiązywanie połączenia z odbiornikiem zawsze włączonej grupy dostępności
- oświadczenia Transact-SQL dla grup dostępności Always On
- Omówienie poleceń cmdlet programu PowerShell dla grup dostępności Always On
- Blog programu SQL Server — wysoka dostępność
- SQL Server Blog
- Archiwum : Blog zespołu SQL Server Always On: oficjalny blog zespołu SQL Server Always On
- Archiwum : Blogi inżynierów programu SQL Server CSS
- Przewodnik rozwiązań Microsoft SQL Server Always On dla wysokiej dostępności i odzyskiwania po awarii