Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server 2017 (14.x) i nowsze wersje
SQL Server 2017 (14.x) i nowsze wersje
W tym artykule opisano rozszerzenie języka Python do uruchamiania zewnętrznych skryptów języka Python za pomocą usług SQL Server Machine Learning Services. Rozszerzenie dodaje:
- Środowisko wykonywania języka Python
- Dystrybucja anaconda ze środowiskiem uruchomieniowym i interpreterem języka Python 3.5
- Standardowe biblioteki i narzędzia
- Pakiety języka Microsoft Python:
- revoscalepy na potrzeby analizy na dużą skalę.
- microsoftml dla algorytmów uczenia maszynowego.
Instalacja środowiska uruchomieniowego i interpretera języka Python 3.5 zapewnia niemal pełną zgodność ze standardowymi rozwiązaniami języka Python. Język Python działa w osobnym procesie od programu SQL Server, aby zagwarantować, że operacje bazy danych nie zostaną naruszone.
Składniki języka Python
Program SQL Server zawiera zarówno pakiety open source, jak i zastrzeżone. Środowisko uruchomieniowe języka Python zainstalowane przez instalatora to Anaconda 4.2 z językiem Python 3.5. Środowisko uruchomieniowe języka Python jest instalowane niezależnie od narzędzi SQL i jest wykonywane poza podstawowymi procesami silnika w ramach struktury rozszerzeń. W ramach instalacji usług Machine Learning Services w języku Python musisz wyrazić zgodę na warunki licencji publicznej GNU.
Program SQL Server nie modyfikuje plików wykonywalnych języka Python, ale należy użyć wersji języka Python zainstalowanej przez Instalatora, ponieważ jest to wersja, na której są kompilowane i testowane zastrzeżone pakiety. Aby uzyskać listę pakietów obsługiwanych przez dystrybucję anaconda, zobacz witrynę analizy Continuum: listę pakietów Anaconda.
Dystrybucja Anaconda skojarzona z określonym wystąpieniem silnika bazy danych znajduje się w folderze skojarzonym z tym wystąpieniem. Na przykład, jeśli zainstalowano silnik bazodanowy programu SQL Server 2017 z usługami Machine Learning Services i językiem Python na wystąpieniu domyślnym, poszukaj pod C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Pakiety języka Python dodane przez firmę Microsoft dla obciążeń równoległych i rozproszonych obejmują następujące biblioteki.
| Biblioteka | Description |
|---|---|
| revoscalepy | Obsługuje obiekty źródła danych i eksplorację danych, manipulowanie, przekształcanie i wizualizacje. Obsługuje tworzenie zdalnych kontekstów obliczeniowych, a także różne skalowalne modele uczenia maszynowego, takie jak rxLinMod. Aby uzyskać więcej informacji, zobacz moduł revoscalepy w programie SQL Server. |
| microsoftml | Zawiera algorytmy uczenia maszynowego zoptymalizowane pod kątem szybkości i dokładności, a także przekształcenia wbudowane do pracy z tekstem i obrazami. Aby uzyskać więcej informacji, zobacz moduł microsoftml z programem SQL Server. |
Microsoftml i revoscalepy są ściśle powiązane; źródła danych używane w języku microsoftml są definiowane jako obiekty revoscalepy. Ograniczenia kontekstu obliczeniowego w transferze revoscalepy do microsoftml. Mianowicie wszystkie funkcje są dostępne dla operacji lokalnych, ale przejście do zdalnego kontekstu obliczeniowego wymaga serwera RxInSqlServer.
Używanie języka Python w programie SQL Server
Zaimportujesz moduł revoscalepy do kodu języka Python, a następnie wywołasz funkcje z modułu, podobnie jak w przypadku innych funkcji języka Python.
Obsługiwane źródła danych obejmują bazy danych ODBC, program SQL Server i format plików XDF do wymiany danych z innymi źródłami lub z rozwiązaniami języka R. Dane wejściowe dla języka Python muszą być tabelaryczne. Wszystkie wyniki języka Python muszą być zwracane w postaci ramki danych pandas.
Obsługiwane konteksty obliczeniowe obejmują lokalny lub zdalny kontekst obliczeniowy programu SQL Server. Zdalny kontekst obliczeniowy odnosi się do wykonywania kodu uruchamianego na jednym komputerze, takim jak stacja robocza, ale następnie przełącza wykonywanie skryptu na komputer zdalny. Przełączenie kontekstu obliczeniowego wymaga, aby oba systemy miały tę samą bibliotekę revoscalepy.
Lokalny kontekst obliczeniowy, zgodnie z oczekiwaniami, obejmuje wykonywanie kodu Python na tym samym serwerze co silnik bazy danych, z kodem wewnątrz T-SQL lub osadzonym w procedurze składowanej. Możesz również uruchomić kod z lokalnego środowiska IDE języka Python i wykonać skrypt na komputerze z programem SQL Server, definiując zdalny kontekst obliczeniowy.
Architektura wykonywania
Na poniższych diagramach przedstawiono interakcję składników programu SQL Server ze środowiskiem uruchomieniowym języka Python w każdym z obsługiwanych scenariuszy: uruchamianie skryptu w bazie danych i zdalne wykonywanie z terminalu języka Python przy użyciu kontekstu obliczeniowego programu SQL Server.
Skrypty języka Python wykonane w bazie danych
Po uruchomieniu języka Python "wewnątrz" programu SQL Server należy hermetyzować skrypt języka Python wewnątrz specjalnej procedury składowanej, sp_execute_external_script.
Po osadzie skryptu w procedurze składowanej każda aplikacja, która może wykonać wywołanie procedury składowanej, może zainicjować wykonywanie kodu w języku Python. Następnie program SQL Server zarządza wykonywaniem kodu zgodnie z podsumowaniem na poniższym diagramie.
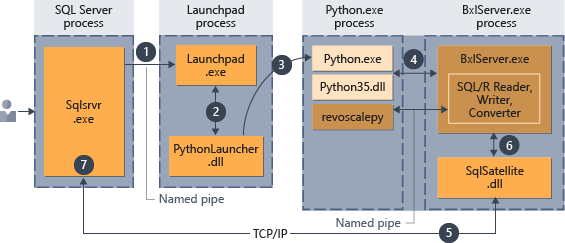
- Żądanie środowiska uruchomieniowego języka Python jest wskazywane przez parametr
@language='Python'przekazany do procedury składowanej. Program SQL Server wysyła to żądanie do usługi launchpad. W systemie Linux usługa SQL używa usługi launchpadd do komunikowania się z oddzielnym procesem launchpada dla każdego użytkownika. Aby uzyskać szczegółowe informacje, zobacz diagram architektury rozszerzalności . - Usługa launchpad uruchamia odpowiedni program uruchamiający; w tym przypadku PythonLauncher.
- PythonLauncher uruchamia zewnętrzny proces języka Python35.
- Serwer BxlServer koordynuje się ze środowiskiem uruchomieniowym języka Python, aby zarządzać wymianami danych i magazynem wyników roboczych.
- Program SQL Satellite zarządza komunikacją na temat powiązanych zadań i procesów za pomocą programu SQL Server.
- Serwer BxlServer używa programu SQL Satellite do przekazywania stanu i wyników do programu SQL Server.
- Program SQL Server pobiera wyniki i zamyka powiązane zadania i procesy.
Skrypty języka Python wykonywane z klienta zdalnego
Skrypty języka Python można uruchamiać z komputera zdalnego, takiego jak laptop, i wykonywać je w kontekście komputera z programem SQL Server, jeśli są spełnione następujące warunki:
- Projektujesz skrypty odpowiednio
- Na komputerze zdalnym zainstalowano biblioteki rozszerzalności, które są używane przez usługi Machine Learning Services. Pakiet revoscalepy jest wymagany do korzystania ze zdalnych kontekstów obliczeniowych.
Na poniższym diagramie przedstawiono podsumowanie ogólnego przepływu pracy podczas wysyłania skryptów z komputera zdalnego.
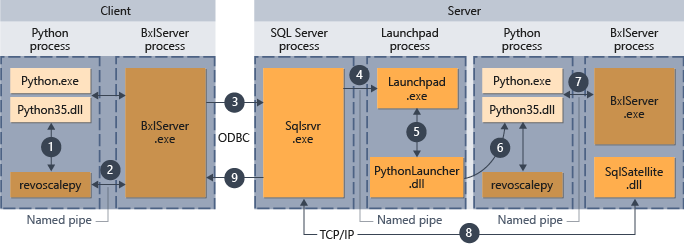
- W przypadku funkcji obsługiwanych w programie revoscalepy środowisko uruchomieniowe języka Python wywołuje funkcję łączenia, która z kolei wywołuje serwer BxlServer.
- Serwer BxlServer jest dołączony do usług Machine Learning Services (In-Database) i działa w osobnym procesie od środowiska uruchomieniowego języka Python.
- BxlServer określa obiekt docelowy połączenia i inicjuje połączenie przy użyciu odBC, przekazując poświadczenia podane jako część parametrów połączenia w skrypcie języka Python.
- BxlServer otwiera połączenie z wystąpieniem programu SQL Server.
- Po wywołaniu środowiska uruchomieniowego skryptu zewnętrznego uruchamiana jest usługa launchpad, która z kolei uruchamia odpowiedni launcher: w tym przypadku PythonLauncher.dll. Następnie przetwarzanie kodu w języku Python jest obsługiwane w przepływie pracy podobnym do tego, gdy kod języka Python jest wywoływany z procedury składowanej w języku T-SQL.
- PythonLauncher wykonuje wywołanie do instancji Pythona zainstalowanej na komputerze z SQL Server.
- Wyniki są zwracane do serwera BxlServer.
- Program SQL Satellite zarządza komunikacją z programem SQL Server i oczyszczaniem powiązanych obiektów zadań.
- Program SQL Server przekazuje wyniki z powrotem do klienta.