Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL Database w Microsoft Fabric
SQL Database w Microsoft Fabric
Indeksy kolumnowe są standardem przechowywania i wykonywania zapytań dotyczących dużych tabel faktów w hurtowniach danych. Ten indeks wykorzystuje przechowywanie i przetwarzanie danych oparte na kolumnach, aby zwiększyć wydajność zapytań nawet do 10 razy w hurtowni danych w porównaniu z tradycyjnym przechowywaniem zorientowanym na wiersze. Możesz również osiągnąć kompresję danych zwiększoną nawet 10-krotnie w porównaniu z nieskompresowanymi danymi. Począwszy od programu SQL Server 2016 (13.x) SP1, indeksy magazynu kolumn umożliwiają analizę operacyjną: możliwość uruchamiania wydajnej analizy w czasie rzeczywistym na obciążeniu transakcyjnym.
Dowiedz się więcej o powiązanym scenariuszu:
- Indeksy kolumnowe w magazynowaniu danych
- Rozpoczynanie pracy z magazynem kolumn na potrzeby analizy operacyjnej w czasie rzeczywistym
Co to jest indeks magazynu kolumn?
Indeks magazynujący kolumny to technologia do przechowywania, pobierania i zarządzania danymi przy użyciu formatu danych kolumnowego, zwanego magazynem kolumn .
Kluczowe terminy i pojęcia
Następujące kluczowe terminy i pojęcia są skojarzone z indeksami kolumnowymi.
Magazyn kolumn
Kolumnowy magazyn danych to dane uporządkowane logicznie jako tabela z wierszami i kolumnami oraz fizycznie przechowywane w formacie kolumnowym.
Magazyn danych wierszowych
Magazyn wierszy to dane uporządkowane logicznie jako tabela z wierszami i kolumnami oraz fizycznie przechowywane w formacie danych wierszowych. Ten format jest tradycyjnym sposobem przechowywania danych tabeli relacyjnej. W programie SQL Server termin rowstore odnosi się do tabeli, w której bazowy format magazynu danych to sterta, indeks klastrowany lub tabela zoptymalizowana dla pamięci.
Notatka
W dyskusjach na temat indeksów kolumnowych terminy "rowstore" i "columnstore" są używane do podkreślania formatu przechowywania danych.
Grupa wierszy
Grupa wierszy to grupa wierszy skompresowanych w formacie magazynu kolumn w tym samym czasie. Grupa wierszy zwykle zawiera maksymalną liczbę wierszy w grupie, czyli 1 048 576 wierszy.
Dla wysokiej wydajności i wysokich współczynników kompresji, indeks magazynu kolumn dzieli tabelę na grupy wierszy, a następnie kompresuje każdą grupę wierszy kolumnowo. Liczba wierszy w grupie wierszy musi być wystarczająco duża, aby poprawić współczynniki kompresji i wystarczająco mała, aby korzystać z operacji w pamięci.
Grupa wierszy, z której usunięto wszystkie dane, przechodzi ze stanu COMPRESSED do stanu TOMBSTONE, a następnie usuwana jest przez proces działający w tle o nazwie "tuple-mover". Aby uzyskać więcej informacji na temat stanów grupy wierszy, zobacz sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Napiwek
Zbyt wiele małych grup wierszy zmniejsza jakość indeksu kolumnowego. Do programu SQL Server 2017 (14.x) wymagana jest operacja reorganizacji w celu scalenia mniejszych skompresowanych grup wierszy, zgodnie z wewnętrznymi zasadami progowymi określającymi sposób usuwania usuniętych wierszy i łączenia skompresowanych grup wierszy.
Począwszy od programu SQL Server 2019 (15.x), zadanie scalania w tle działa również w celu scalenia skompresowanych grup wierszy, z których usunięto dużą liczbę wierszy.
Po scaleniu mniejszych grup wierszy należy poprawić jakość indeksu.
Notatka
Począwszy od wersji SQL Server 2019 (15.x), usługi Azure SQL Database, usługi Azure SQL Managed Instance i dedykowanych pul SQL w usłudze Azure Synapse Analytics, mechanizm tuple-mover jest wspomagany przez zadanie scalania w tle, które automatycznie kompresuje mniejsze otwarte rowgroups delta, które istniały przez jakiś czas zgodnie z wewnętrznym progiem, lub scala skompresowane rowgroups, z których usunięto dużą liczbę wierszy. Poprawia to jakość indeksu kolumnowego w miarę upływu czasu.
Segment kolumny
Segment kolumny to kolumna danych z grupy wierszy.
- Każda grupa wierszy zawiera jeden segment kolumn dla każdej kolumny w tabeli.
- Każdy segment kolumny jest kompresowany razem i przechowywany na nośniku fizycznym.
- Istnieją metadane z każdym segmentem, aby umożliwić szybką eliminację segmentów bez ich odczytywania.
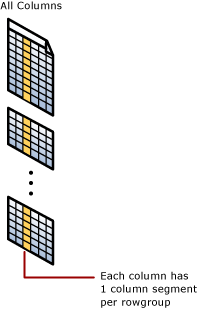
Klastrowany indeks kolumnowy
Indeks klastrowanego magazynu kolumn jest magazynem fizycznym dla całej tabeli.
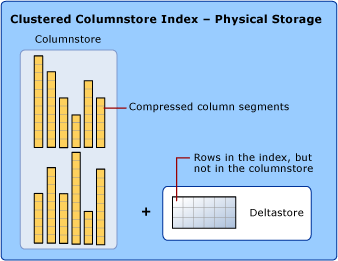
Aby zmniejszyć fragmentację segmentów kolumn i zwiększyć wydajność, indeks magazynu kolumn może tymczasowo przechowywać niektóre dane w indeksie klastrowanym nazywanym deltastore i listą identyfikatorów usuniętych wierszy w drzewie B. Operacje deltastore są obsługiwane w tle. Aby zwrócić poprawne wyniki zapytania, klastrowany indeks columnstore łączy wyniki zarówno z columnstore, jak i deltastore.
Notatka
W dokumentacji jest zwykle używany termin B-tree w odniesieniu do indeksów. W indeksach typu rowstore silnik bazy danych implementuje drzewo B+. Nie dotyczy to indeksów magazynu kolumn ani indeksów w tabelach zoptymalizowanych pod kątem pamięci. Aby uzyskać więcej informacji, zobacz architekturę i przewodnik projektowania indeksu SQL Server i Azure SQL.
Grupa wierszy delty
Grupa wierszy delta jest klastrowanym indeksem B-drzewa, który jest używany tylko z indeksami kolumnowymi. Poprawia kompresję magazynu kolumn i wydajność, przechowując wiersze, aż liczba wierszy osiągnie próg (1048 576 wierszy), a następnie zostaną przeniesione do magazynu kolumn.
Gdy grupa wierszy różnicowych osiągnie maksymalną liczbę wierszy, przechodzi z trybu OTWARTY na ZAMKNIĘTY. Proces w tle o nazwie "tuple-mover" sprawdza zamknięte grupy wierszy. Jeśli proces znajdzie zamkniętą grupę wierszy, kompresuje grupę wierszy delta i zapisuje ją w magazynie kolumn jako skompresowaną grupę wierszy.
Po skompresowaniu grupy wierszy różnicowych, istniejąca grupa wierszy różnicowych przechodzi w stan TOMBSTONE, aby mogła zostać usunięta później przez mechanizm przesuwania tuple, gdy nie ma już do niej odniesień.
Aby uzyskać więcej informacji na temat stanów grupy wierszy, zobacz sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Notatka
Począwszy od SQL Server 2019 (15.x), proces przesuwania krotek jest wspierany przez zadanie scalania w tle, które automatycznie kompresuje mniejsze otwarte grupy delta, które istnieją od pewnego czasu zgodnie z wewnętrznym progiem, lub scala skompresowane grupy wierszy, z których usunięto dużą liczbę wierszy. Poprawia to jakość indeksu kolumnowego w miarę upływu czasu.
Magazyn delty
Indeks kolumnowy może zawierać więcej niż jedną grupę wierszy delta. Wszystkie grupy wierszy różnicowych są zbiorczo nazywane deltastore.
Podczas dużego ładowania masowego większość wierszy trafia bezpośrednio do magazynu kolumn, bez przechodzenia przez magazyn delty. Niektóre wiersze na końcu ładowania zbiorczego mogą być zbyt nieliczne, żeby spełnić minimalny rozmiar grupy wierszy, czyli 102 400 wierszy. W rezultacie ostatnie wiersze trafiają do deltastore zamiast do magazynu kolumn. W przypadku małych obciążeń zbiorczych z mniej niż 102 400 wierszami wszystkie wiersze przechodzą bezpośrednio do magazynu delty.
Indeks kolumnowy nieklastrowy
Indeks magazynu kolumn nieklastrowanych i klastrowany indeks magazynu kolumn działają tak samo. Różnica polega na tym, że indeks nieklastrowany jest indeksem pomocniczym utworzonym w tabeli magazynu wierszy, ale indeks klastrowanego magazynu kolumn jest podstawowym magazynem dla całej tabeli.
Indeks nieklastrowany zawiera kopię części lub wszystkich wierszy i kolumn w tabeli bazowej. Indeks jest definiowany jako co najmniej jedna kolumna tabeli i ma opcjonalny warunek, który filtruje wiersze.
Nieklastrowany indeks magazynu kolumn umożliwia analizę operacyjną w czasie rzeczywistym, w której obciążenie OLTP używa bazowego indeksu klastrowanego, podczas gdy analiza jest uruchamiana współbieżnie w indeksie magazynu kolumn. Aby dowiedzieć się więcej, zobacz Wprowadzenie do kolumnowego magazynu danych na potrzeby analizy operacyjnej w czasie rzeczywistym.
Wykonywanie w trybie wsadowym
Wykonywanie w trybie wsadowym to metoda przetwarzania zapytań, która jest używana do jednoczesnego przetwarzania wielu wierszy. Wykonywanie trybu wsadowego jest ściśle zintegrowane z formatem przechowywania kolumnowego i zoptymalizowane wokół tego formatu. Wykonywanie w trybie wsadowym jest czasami określane jako wektorowe lub wektoryzowane wykonywanie. Zapytania dotyczące indeksów magazynu kolumn używają wykonywania trybu wsadowego, co zwiększa wydajność zapytań zwykle o dwa do czterech razy. Aby uzyskać więcej informacji, zobacz przewodnik dotyczący architektury przetwarzania zapytań .
Dlaczego należy używać indeksu magazynu kolumn?
Indeks magazynowy w układzie kolumnowym może oferować wysoki poziom kompresji danych, zazwyczaj nawet dziesięciokrotnie, aby znacznie zmniejszyć koszty przechowywania danych w magazynie danych. W przypadku analizy indeks kolumnowy oferuje znacznie lepszą wydajność niż indeks drzewa B. Indeksy columnstore są preferowanym formatem przechowywania danych dla obciążeń magazynów danych i analityki. Począwszy od programu SQL Server 2016 (13.x), można użyć indeksów magazynu kolumn na potrzeby analizy w czasie rzeczywistym w obciążeniu operacyjnym.
Powody, dla których indeksy kolumnowe są tak szybkie:
Kolumny przechowują wartości z tej samej domeny i często mają podobne wartości, co powoduje wysokie współczynniki kompresji. Wąskie gardła I/O w systemie są zminimalizowane lub wyeliminowane, a zużycie pamięci jest znacznie zmniejszone.
Wysokie współczynniki kompresji zwiększają wydajność zapytań przy użyciu mniejszego zużycia pamięci. Z kolei wydajność zapytań może się poprawić, ponieważ program SQL Server może wykonywać więcej operacji zapytań i danych w pamięci.
Wykonywanie wsadowe zazwyczaj zwiększa wydajność zapytań od dwóch do czterech razy, przetwarzając wiele wierszy jednocześnie.
Zapytania często wybierają tylko kilka kolumn z tabeli, co zmniejsza łączną liczbę operacji wejścia/wyjścia z nośnika fizycznego.
Kiedy powinienem używać indeksu columnstore?
Zalecane przypadki użycia:
Użyj klastrowanego indeksu magazynowego kolumnowego, aby przechowywać tabele faktów i duże tabele wymiarów dla obciążeń związanych z magazynowaniem danych. Ta metoda poprawia wydajność zapytań i kompresję danych przez maksymalnie 10 razy. Aby uzyskać więcej informacji, zobacz także Indeksy kolumnowe dla magazynowania danych.
Użyj nieklastrowanego indeksu magazynu kolumn, aby przeprowadzić analizę w czasie rzeczywistym na obciążeniu OLTP. Aby dowiedzieć się więcej, zobacz Wprowadzenie do kolumnowego magazynu danych na potrzeby analizy operacyjnej w czasie rzeczywistym.
Aby uzyskać więcej scenariuszy użycia indeksów columnstore, zobacz Wybierz najlepszy indeks columnstore dla swoich potrzeb.
Jak wybrać między indeksem magazynu wierszy a indeksem magazynu kolumn?
Indeksy wierszy działają najlepiej w przypadku zapytań, które przeszukują dane, podczas wyszukiwania określonej wartości lub zapytań obejmujących niewielki zakres wartości. Używaj indeksów typu rowstore dla obciążeń transakcyjnych, ponieważ zazwyczaj wymagają głównie wyszukiwania w tabelach zamiast skanowania tabel.
Indeksy kolumnowe zapewniają znaczne zwiększenie wydajności w zapytaniach analitycznych, które przetwarzają duże ilości danych, zwłaszcza w przypadku dużych tabel. Używaj indeksów columnstore do pracy z magazynami danych i obciążeniami analitycznymi, zwłaszcza w tabelach faktów, ponieważ zwykle wymagają one pełnego skanowania tabel zamiast wyszukiwań tabel.
Uporządkowane klastrowane indeksy magazynu kolumn zwiększają wydajność zapytań na podstawie uporządkowanych predykatów kolumn. Uporządkowane indeksy kolumnowe mogą poprawić eliminację grup wierszowych, co może zwiększyć wydajność, całkowicie pomijając grupy wierszowe. Aby uzyskać więcej informacji, zobacz Optymalizacja wydajności z uporządkowanymi indeksami kolumnowymi. Aby uzyskać informacje o dostępności uporządkowanego indeksu kolumnowego, zobacz także Dostępność uporządkowanego indeksu kolumnowego.
Czy mogę połączyć rowstore i columnstore na tej samej tabeli?
Tak. Począwszy od SQL Server 2016 (13.x), można utworzyć aktualizowalny nieklastrowany indeks magazynu kolumnowego na tabeli wierszy. Indeks magazynu kolumn przechowuje kopię wybranych kolumn, więc potrzebujesz dodatkowego miejsca dla tych danych, ale wybrane dane są kompresowane średnio 10 razy. Możesz jednocześnie przeprowadzać analizy na indeksie magazynu kolumnowego oraz realizować transakcje na indeksie magazynu wierszowego. Magazyn kolumnowy jest aktualizowany, gdy dane zmieniają się w tabeli magazynu wierszowego, więc oba indeksy działają na tych samych danych.
Począwszy od programu SQL Server 2016 (13.x), można mieć jeden lub więcej nieklastrowanych indeksów magazynu wierszy w indeksie magazynu kolumn i wykonywać wydajne wyszukiwanie tabel w bazowym indeksie magazynu kolumn. Inne opcje również staną się dostępne. Można na przykład wymusić ograniczenie klucza podstawowego przy użyciu ograniczenia UNIQUE w tabeli rowstore. Ponieważ nie można wstawić nieunikalnej wartości do tabeli wierszowej, program SQL Server nie może wstawić tej wartości do magazynu kolumnowego.
Uporządkowane indeksy kolumnowe
Poprzez umożliwienie wydajnej eliminacji segmentów, uporządkowane indeksy magazynu kolumn umożliwiają szybsze działanie, pomijając duże ilości uporządkowanych danych, które nie pasują do warunku zapytania. Ładowanie danych do uporządkowanego indeksu magazynu kolumn może trwać dłużej niż w nieuporządkowanym indeksie z powodu operacji sortowania danych, jednak zapytania w uporządkowanym indeksie magazynu kolumn mogą działać szybciej później.
- Aby uzyskać więcej informacji na temat dostrajania wydajności dostosowywania obciążeń magazynowania danych w aparacie bazy danych SQL z uporządkowanymi indeksami kolumnowymi, zobacz Performance tuning with ordered columnstore indexes.
- Aby uzyskać więcej informacji na temat tego, kiedy używać rodzaju indeksu kolumnowego, zobacz Wybierz najlepszy indeks kolumnowy dla Twoich potrzeb.
Dostępność uporządkowanego indeksu kolumnowego
Uporządkowane indeksy kolumnowe są dostępne na następujących platformach:
| Platforma | Uporządkowane klastrowane indeksy kolumnowe | Uporządkowane nieklastrowane indeksy słupkowe |
|---|---|---|
| Azure SQL Database | Tak | Tak |
| Azure SQL Managed Instance AUTD | Tak | Tak |
| Azure SQL Managed Instance2022 | Tak | Nie |
| Baza danych SQL w usłudze Microsoft Fabric | Tak1 | Tak |
| SQL Server 2025 (wersja zapoznawcza 17.x) | Tak | Tak |
| SQL Server 2022 (16.x) | Tak | Nie |
| Dedykowana pula SQL w usłudze Azure Synapse Analytics | Tak | Nie |
AUTD dotyczy usługi Azure SQL Managed Instance skonfigurowanej przy użyciu always-up-to-date update policy.
2022 Dotyczy usługi Azure SQL Managed Instance skonfigurowanej przy użyciu zasad aktualizacji programu SQL Server 2022.
1W bazie danych SQL Fabric tabele z klastrowanymi indeksami kolumnowego magazynowania nie są dublowane w usłudze Fabric OneLake.
Metadane
Wszystkie kolumny w indeksie magazynu kolumn są przechowywane w metadanych jako dołączone kolumny. Indeks columnstore nie zawiera kolumn kluczowych.
Powiązane zadania
| Zadanie | Artykuły referencyjne | Notatki |
|---|---|---|
| Utwórz tabelę jako magazyn kolumn. | CREATE TABLE (Transact-SQL) | Domyślnie podczas tworzenia tabeli jest używany magazyn wierszy jako podstawowy format danych. Począwszy od programu SQL Server 2016 (13.x), możesz utworzyć tabelę z klastrowanym indeksem magazynu kolumn, określając INDEX ... CLUSTERED COLUMNSTORE opcję. Nie musisz najpierw tworzyć tabeli typu rowstore, a następnie konwertować ją na columnstore. |
| Przekonwertuj tabelę wierszową na tabelę kolumnową. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Przekonwertuj istniejącą stertę lub drzewo B na magazyn kolumnowy. Przykłady pokazują, jak obsługiwać istniejące indeksy, a także nazwę indeksu podczas przeprowadzania tej konwersji. |
| Utwórz nieklastrowany indeks magazynu kolumn w tabeli rowstore. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Tabela rowstore może zawierać jeden nieklastrowany indeks kolumnowy. Począwszy od programu SQL Server 2016 (13.x), indeks magazynu kolumn nieklastrowanych może mieć warunek filtrowany. Przykłady pokazują podstawową składnię. |
| Przekształć tabelę kolumnową na tabelę wierszową. | UTWÓRZ INDEKS SKLASTROWANY (Transact-SQL) lub Przekształć tabelę z magazynem kolumnowym z powrotem na stertę w magazynie wierszowym | Zazwyczaj ta konwersja nie jest konieczna, ale czasami może wystąpić potrzeba konwersji. Przykłady pokazują, jak przekonwertować magazyn kolumn na stertę lub indeks klastrowany. |
| Tworzenie indeksów magazynu kolumn na potrzeby magazynowania danych. | Indeksy magazynowe kolumnowe dla hurtowni danych | Opisuje sposób używania indeksów magazynu kolumn na potrzeby zapytań dotyczących szybkiego magazynowania danych. |
| Tworzenie indeksów na potrzeby analizy operacyjnej. | Rozpoczynanie pracy z magazynem kolumn na potrzeby analizy operacyjnej w czasie rzeczywistym | Opisuje sposób tworzenia komplementarnych indeksów kolumnowych i indeksów drzewa B, tak aby zapytania OLTP korzystały z indeksów drzewa B, a zapytania analityczne z indeksów kolumnowych. |
| Użyj indeksu drzewa B, aby wymusić ograniczenie klucza podstawowego w indeksie magazynu kolumn. | Indeksy magazynowe kolumnowe dla hurtowni danych | Pokazuje, jak połączyć indeksy B-tree i columnstore w celu wymuszenia ograniczenia klucza głównego w tabeli columnstore. |
| Utwórz tabelę zoptymalizowaną pod kątem pamięci z indeksem typu columnstore. | CREATE TABLE (Transact-SQL) | Począwszy od programu SQL Server 2016 (13.x), można utworzyć tabelę zoptymalizowaną pod kątem pamięci z indeksem magazynu kolumn. Indeks magazynowy kolumnowy można również dodać po utworzeniu tabeli, używając składni ALTER TABLE ADD INDEX. |
| Ładowanie danych do indeksu kolumnowego. | Ładowanie danych do kolumnowych indeksów | |
| Usuń indeks kolumnowy. | UPUŚĆ INDEKS (Transact-SQL) | Usunięcie kolumnowego indeksu magazynowego wykorzystuje standardową składnię DROP INDEX, taką samą jak ta używana w przypadku indeksów drzewa B. Usunięcie klastrowanego indeksu typu columnstore konwertuje tabelę columnstore na stertę. |
| Usuń wiersz z indeksu kolumnowego. | DELETE (Transact-SQL) | Użyj DELETE (Transact-SQL), aby usunąć wiersz. wiersz magazynu kolumn: program SQL Server oznacza wiersz jako logicznie usunięty, ale nie odzyskuje magazynu fizycznego dla wiersza do czasu odbudowy indeksu. wiersz deltastore: SQL Server logicznie i fizycznie usuwa wiersz. |
| Zaktualizuj wiersz w indeksie columnstore. | AKTUALIZACJA (Transact-SQL) | Użyj UPDATE (Transact-SQL), aby zaktualizować wiersz. wiersz magazynu kolumnowego: SQL Server oznacza wiersz jako logicznie usunięty, a następnie wstawia zaktualizowany wiersz do deltastore. wiersz deltastore: program SQL Server aktualizuje wiersz w deltastore. |
| Utrzymywanie indeksu magazynu kolumnowego. |
ALTER INDEX ... ODBUDOWAĆ REORGANIZACJA indeksu magazynu kolumn Metody konserwacji indeksu: reorganizacja i ponowne kompilowanie |
W większości przypadków ALTER INDEX ... REORGANIZE zapewnia wyniki podobne do ALTER INDEX ... REBUILD, ale przy mniejszym zużyciu zasobów.
ALTER INDEX ... REORGANIZE zawsze działa w trybie online. Obie opcje defragmentują indeks kolumnowy i wymuszają przeniesienie wierszy z deltastore do magazynu kolumn.Począwszy od programu SQL Server 2019 (15.x), w usłudze Azure SQL Database i w usłudze Azure SQL Managed Instance jakość indeksu magazynu kolumn jest utrzymywana automatycznie, co pozwala usunąć konieczność okresowej konserwacji indeksu w większości przypadków. |
Powiązana zawartość
- Co nowego w indeksach kolumnowych
- Indeksy magazynowania kolumnowego — wskazówki dotyczące ładowania danych
- Indeksy kolumnowe — wydajność zapytań
- Zacznij korzystać z Columnstore do analizy operacyjnej w czasie rzeczywistym
- Indeksy kolumnowe w magazynowaniu danych
- Defragmentacja indeksów kolumnowych
- Przewodnik po architekturze indeksów i projektowaniu w SQL Server i Azure SQL
- architektura indeksu magazynu kolumn
- CREATE COLUMNSTORE INDEX (Transact-SQL)