Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł zawiera wskazówki dotyczące rozwiązywania problemów, w których zapytanie programu Microsoft SQL Server zajmuje zbyt dużo czasu (godziny lub dni).
Objawy
Ten artykuł koncentruje się na zapytaniach, które wydają się być uruchamiane lub kompilowane bez końca. Oznacza to, że ich użycie procesora nadal rośnie. Ten artykuł nie ma zastosowania do zapytań, które są blokowane lub oczekują na zasób, który nigdy nie został wydany. W takich przypadkach użycie procesora CPU pozostaje stałe lub zmienia się tylko nieznacznie.
Ważne
Jeśli zapytanie pozostanie w stanie kontynuować pracę, może zostać ostatecznie zakończone. Ten proces może potrwać zaledwie kilka sekund lub kilka dni. W niektórych sytuacjach zapytanie może być naprawdę nieskończone, na przykład gdy pętla WHILE nie kończy się. Termin "niekończące się" jest używany tutaj do opisania wrażenia, że zapytanie się nie kończy.
Przyczyna
Typowe przyczyny długotrwałych (niekończących się) zapytań obejmują:
-
Sprzężenia zagnieżdżonej pętli (NL) w bardzo dużych tabelach: Ze względu na charakter sprzężeń NL, zapytanie, które łączy tabele z dużą liczbą wierszy, może działać przez długi czas. Aby uzyskać więcej informacji, zobacz Joins (Sprzężenia).
- Jednym z przykładów sprzężenia NL jest użycie elementu
TOP,FASTlubEXISTS. Nawet jeśli sprzężenia skrótu lub scalania mogą być szybsze, optymalizator nie może użyć operatora z powodu celu wiersza. - Innym przykładem sprzężenia NL jest zastosowanie predykatu sprzężenia z warunkiem nierówności w zapytaniach. Na przykład
SELECT .. FROM tab1 AS a JOIN tab 2 AS b ON a.id > b.id. Optymalizator nie może tutaj używać Merge ani Hash joins.
- Jednym z przykładów sprzężenia NL jest użycie elementu
- Nieaktualne statystyki: Zapytania, które wybierają plan na podstawie nieaktualnych statystyk, mogą być nieoptymalne i trwają długo.
- Pętle nieskończone: Zapytania T-SQL korzystające z pętli WHILE mogą być niepoprawnie zapisywane. Wynikowy kod nigdy nie opuszcza pętli i działa bez końca. Te zapytania są naprawdę niekończące się. Uruchamiają się, dopóki nie zostaną zabici ręcznie.
- Złożone zapytania, które mają wiele sprzężeń i dużych tabel: Zapytania obejmujące wiele tabel sprzężonych zwykle mają złożone plany zapytań, które mogą zająć dużo czasu. Ten scenariusz jest typowy w przypadku zapytań analitycznych, które nie filtrują wierszy i obejmują dużą liczbę tabel.
- Brakujące indeksy: Zapytania mogą działać znacznie szybciej, jeśli odpowiednie indeksy są używane w tabelach. Indeksy umożliwiają wybór podzestawu danych w celu zapewnienia szybszego dostępu.
Rozwiązanie
Krok 1. Odnajdywanie niekończących się zapytań
Wyszukaj niekończące się zapytanie, które jest uruchomione w systemie. Musisz określić, czy zapytanie ma długi czas wykonywania, długi czas oczekiwania (zablokowane w wąskim gardle) lub długi czas kompilacji.
1.1 Uruchamianie diagnostyki
Uruchom następujące zapytanie diagnostyczne w instancji programu SQL Server, w której aktywne jest zapytanie niekończące się.
DECLARE @cntr INT = 0
WHILE (@cntr < 3)
BEGIN
SELECT TOP 10 s.session_id,
r.status,
CAST(r.cpu_time / (1000 * 60.0) AS DECIMAL(10,2)) AS cpu_time_minutes,
CAST(r.total_elapsed_time / (1000 * 60.0) AS DECIMAL(10,2)) AS elapsed_minutes,
r.logical_reads,
r.wait_time,
r.wait_type,
r.wait_resource,
r.reads,
r.writes,
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count,
atrn.name as transaction_name,
atrn.transaction_id,
atrn.transaction_state
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id
CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
LEFT JOIN (sys.dm_tran_session_transactions AS stran
JOIN sys.dm_tran_active_transactions AS atrn
ON stran.transaction_id = atrn.transaction_id)
ON stran.session_id =s.session_id
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
SET @cntr = @cntr + 1
WAITFOR DELAY '00:00:05'
END
1.2 Sprawdzanie danych wyjściowych
Istnieje kilka scenariuszy, które mogą powodować uruchamianie zapytania przez długi czas: długie wykonywanie, długie oczekiwanie i długa kompilacja. Aby uzyskać więcej informacji o tym, dlaczego zapytanie może działać wolno, zobacz Running vs. Waiting: why are slow query? (Uruchamianie i oczekiwanie: dlaczego zapytania są powolne?
Długi czas wykonywania
Kroki rozwiązywania problemów opisane w tym artykule mają zastosowanie w przypadku otrzymania danych wyjściowych podobnych do poniższych, w których czas procesora CPU wzrasta proporcjonalnie do czasu, który upłynął bez znaczących czasów oczekiwania.
| session_id | stan | czas_procesora_minuty | czas_upływu_minuty | logical_reads | czas_oczekiwania_minuty | wait_type |
|---|---|---|---|---|---|---|
| 56 | uruchomiono | 64.40 | 23.50 | 0 | 0.00 | NULL |
Zapytanie jest stale uruchomione, jeśli ma:
- Zwiększający się czas procesora
- Stan
runninglubrunnable - Minimalny lub zerowy czas oczekiwania
- Brak wait_type
W takiej sytuacji zapytanie odczytuje wiersze, dołącza, przetwarza wyniki, oblicza lub formatuje. Te działania są akcjami powiązanymi z procesorem CPU.
Uwaga 16.
Zmiany w logical_reads nie są istotne w tym przypadku, ponieważ niektóre żądania T-SQL obciążające CPU, takie jak wykonywanie obliczeń lub pętla WHILE, mogą w ogóle nie wykonywać żadnych operacji logicznego odczytu.
Jeśli wolne zapytanie spełnia te kryteria, skup się na zmniejszeniu jego czasu działania. Zazwyczaj zmniejszenie środowiska uruchomieniowego polega na zmniejszeniu liczby wierszy, które zapytanie musi przetwarzać przez cały czas, stosując indeksy, ponownie zapisując zapytanie lub aktualizując statystyki. Aby uzyskać więcej informacji, zobacz sekcję Rozwiązanie .
Długi czas oczekiwania
Ten artykuł nie ma zastosowania do przypadków długiego oczekiwania. W scenariuszu oczekiwania możesz otrzymać dane wyjściowe podobne do następującego przykładu, w którym użycie procesora CPU nie zmienia się lub zmienia się nieznacznie, ponieważ sesja czeka na zasób:
| session_id | stan | czas_procesora_minuty | czas_upływu_minuty | logical_reads | czas_oczekiwania_minuty | wait_type |
|---|---|---|---|---|---|---|
| 56 | zawieszony | 0.03 | 4.20 | 50 | 4.10 | LCK_M_U |
Typ oczekiwania wskazuje, że sesja czeka na zasób. Długi czas realizacji i długi czas oczekiwania wskazują, że sesja przez większość czasu czeka na ten zasób. Krótki czas pracy procesora wskazuje, że niewiele czasu zostało faktycznie spędzone na przetwarzanie zapytania.
Aby rozwiązać problemy z zapytaniami, które są długie z powodu oczekiwania, zobacz Rozwiązywanie problemów z powolnymi zapytaniami w programie SQL Server.
Długi czas kompilacji
W rzadkich przypadkach można zauważyć, że użycie procesora CPU stale wzrasta w czasie, ale nie jest napędzane przez wykonywanie zapytania. Zamiast tego przyczyną może być zbyt długa kompilacja (analizowanie i kompilowanie zapytania). W takich przypadkach sprawdź kolumnę danych wyjściowych transaction_name pod kątem wartości sqlsource_transform. Ta nazwa transakcji wskazuje kompilację.
Krok 2. Ręczne zbieranie dzienników diagnostycznych
Po ustaleniu, że w systemie istnieje niekończące się zapytanie, możesz zebrać dane planu zapytania w celu dalszego rozwiązywania problemów. Aby zebrać dane, użyj jednej z następujących metod, w zależności od używanej wersji programu SQL Server.
- SQL Server 2008 — SQL Server 2014 (starsze niż SP2)
- SQL Server 2014 (nowsze niż SP2) i SQL Server 2016 (starsze niż SP1)
- SQL Server 2016 (nowsze niż SP1) i SQL Server 2017
- SQL Server 2019 i nowsze wersje
Aby zebrać dane diagnostyczne przy użyciu programu SQL Server Management Studio (SSMS), wykonaj następujące kroki:
Przechwyć szacowany kod XML planu wykonywania zapytania.
Zapoznaj się z planem zapytania, aby dowiedzieć się, czy dane pokazują oczywiste wskazania tego, co powoduje spowolnienie. Przykłady typowych wskazówek obejmują:
- Skanowanie tabeli lub indeksu (zwróć uwagę na szacowane wiersze)
- Zagnieżdżone pętle napędzane przez ogromny zewnętrzny zbiór danych tabeli
- Zagnieżdżone pętle, które mają dużą gałąź w wewnętrznej części pętli
- Bufory tabel
- Funkcje na
SELECTliście, które zajmują dużo czasu na przetworzenie każdego wiersza
Jeśli zapytanie jest uruchamiane szybciej w dowolnym momencie, możesz przechwycić "szybkie" uruchomienia (rzeczywisty plan wykonywania XML), aby porównać wyniki.
Używanie funkcji SQL LogScout do przechwytywania niekończących się zapytań
Funkcję SQL LogScout można użyć do przechwytywania dzienników, gdy jest uruchomione niekończące się zapytanie. Użyj scenariusza niekończącego się zapytania za pomocą następującego polecenia:
.\SQL_LogScout.ps1 -Scenario "NeverEndingQuery" -ServerName "SQLInstance"
Uwaga 16.
Ten proces przechwytywania dzienników wymaga, aby długie zapytanie zużywało co najmniej 60 sekund czasu procesora.
Funkcja SQL LogScout przechwytuje co najmniej trzy plany zapytań dla każdego zapytania zużywających wysokie użycie procesora CPU. Można znaleźć nazwy plików, które są podobne do servername_datetime_NeverEnding_statistics_QueryPlansXml_Startup_sessionId_#.sqlplan. Te pliki można użyć w następnym kroku podczas przeglądania planów, aby zidentyfikować przyczynę długiego wykonywania zapytań.
Krok 3. Przeglądanie zebranych planów
W tej sekcji omówiono sposób przeglądania zebranych danych. Używa wielu planów zapytań XML (przy użyciu rozszerzenia .sqlplan), które są zbierane w programie Microsoft SQL Server 2016 SP1 i nowszych kompilacjach i wersjach.
Porównaj plany wykonywania , wykonując następujące kroki:
Otwórz wcześniej zapisany plik planu wykonywania zapytania (
.sqlplan).Kliknij prawym przyciskiem myszy na pustym obszarze planu wykonania, a następnie wybierz opcję Porównaj Showplan.
Wybierz drugi plik planu zapytania, który chcesz porównać.
Poszukaj grubych strzałek, które wskazują dużą liczbę wierszy przepływających między operatorami. Następnie wybierz operator przed strzałką lub po nim i porównaj liczbę rzeczywistych wierszy w dwóch planach.
Porównaj drugie i trzecie plany, aby dowiedzieć się, czy największy przepływ wierszy występuje w tych samych operatorach.
Przykład:
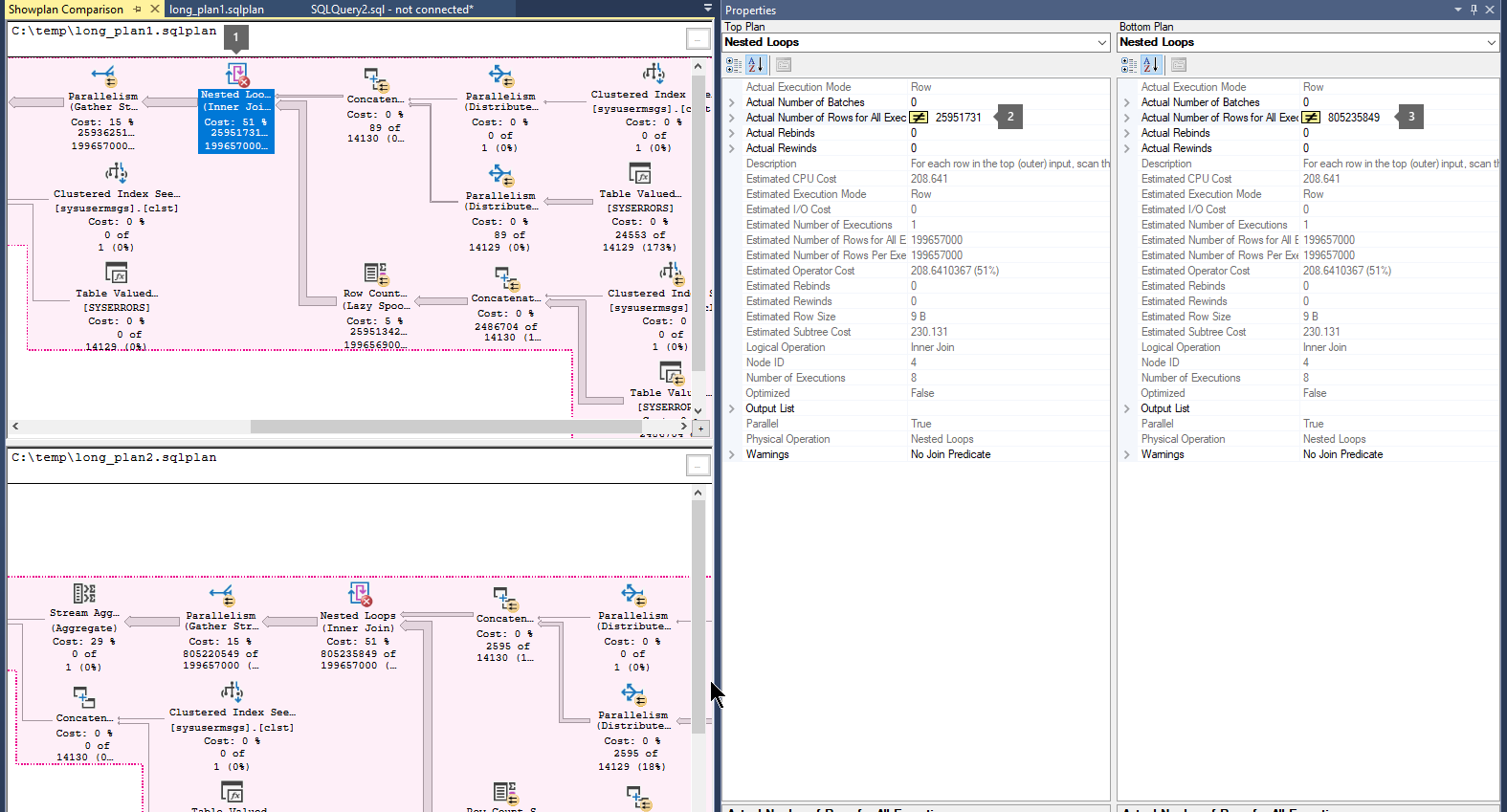

Krok 4. Rozwiązanie
Upewnij się, że statystyki są aktualizowane dla tabel używanych w zapytaniu.
Poszukaj brakujących zaleceń dotyczących indeksu w planie zapytania i zastosuj wszystkie, które znajdziesz.
Uprość zapytanie:
- Użyj bardziej selektywnych
WHEREpredykatów, aby zmniejszyć ilość przetwarzanych danych z góry. - Rozbić go od siebie.
- Wybierz niektóre części w tabelach tymczasowych i dołącz je później.
- Usuń
TOP,EXISTSiFAST(T-SQL) w zapytaniach, które wykonują się długo z powodu operacji docelowego wiersza w optymalizatorze.- Alternatywnie użyj
DISABLE_OPTIMIZER_ROWGOALwskazówki. Aby uzyskać więcej informacji, zobacz Row Goals Gone Rogue.
- Alternatywnie użyj
- Unikaj używania typowych wyrażeń tabel (CTE) w takich przypadkach, ponieważ łączą instrukcje w jednym dużym zapytaniu.
- Użyj bardziej selektywnych
Spróbuj użyć wskazówek dotyczących zapytań , aby utworzyć lepszy plan:
-
HASH JOINlubMERGE JOINwskazówka -
FORCE ORDERaluzja -
FORCESEEKaluzja RECOMPILE- USE
PLAN N'<xml_plan>'(jeśli masz szybki plan zapytania, który możesz wymusić)
-
Użyj magazynu zapytań (QDS), aby wymusić dobry plan, jeśli taki plan istnieje i czy wersja programu SQL Server obsługuje magazyn zapytań.