Usar pacotes externos com notebooks Jupyter em clusters Apache Spark no HDInsight
Aprenda a configurar um Jupyter Notebook no cluster do Apache Spark no HDInsight para usar pacotes externos do Apache maven contribuídos pela comunidade, que não são incluídos no cluster de fábrica.
Você pode pesquisar o Repositório do Maven para obter uma lista de pacotes que estão disponíveis. Você também pode obter uma lista de pacotes disponíveis de outras fontes. Por exemplo, uma lista completa dos pacotes enviados pela comunidade está disponível em Pacotes do Spark.
Neste artigo, você aprenderá a usar o pacote spark csv com o Jupyter Notebook.
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Para obter instruções, consulte o artigo sobre como Criar clusters do Apache Spark no Azure HDInsight.
Familiaridade com o uso de anotações do Jupyter com Spark no HDInsight. Para obter mais informações, confira Carregar dados e executar consultas com o Apache Spark no HDInsight.
O esquema de URI do seu armazenamento primário de clusters. Isso seria
wasb://para o Armazenamento do Azure,abfs://para o Azure Data Lake Storage Gen2 ouadl://para o Azure Data Lake Storage Gen1. Se a transferência segura estiver habilitada para o Armazenamento do Azure ou para o Data Lake Storage Gen2, o URI seráwasbs://ouabfss://, respectivamente. Confira também transferência segura.
Usar pacotes externos com Jupyter Notebooks
Navegue até
https://CLUSTERNAME.azurehdinsight.net/jupyterem queCLUSTERNAMEé o nome do cluster do Spark.Crie um novo bloco de anotações. Selecione Novo e depois Spark.
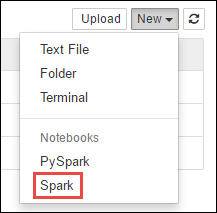
Um novo bloco de anotações é criado e aberto com o nome Untitled.pynb. Selecione o nome do notebook na parte superior e digite um nome amigável.
Você usará a mágica
%%configurepara configurar o notebook para usar um pacote externo. Em blocos de notas que usam pacotes externos, não deixe de chamar a mágica%%configurena primeira célula de código. Isso garante que o kernel está configurado para usar o pacote antes de iniciar a sessão.Importante
Se esquecer de configurar o kernel na primeira célula, você poderá usar
%%configurecom o parâmetro-f, mas isso reiniciará a sessão e todo o progresso será perdido.Versão do HDInsight Comando Para HDInsight 3.5 e HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Para HDInsight 3.3 e HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }O snippet de código acima espera as coordenadas do maven para o pacote externo no Repositório Central do Maven. Nesse snippet de código,
com.databricks:spark-csv_2.11:1.5.0é a coordenada do maven para o pacote spark-csv. Veja como você constrói as coordenadas de um pacote.a. Localize o pacote no Repositório Maven. Para este artigo, usamos spark-csv.
b. No repositório, colete os valores para GroupId, ArtifactId e Version. Certifique-se de que os valores que você coletar correspondam ao cluster. Nesse caso, estamos usando um pacote de Spark 1.5.0 e Scala 2.11, mas talvez seja necessário selecionar versões diferentes para a versão apropriada do Spark ou do Scala no cluster. Você pode encontrar a versão do Scala no cluster executando
scala.util.Properties.versionStringno kernel Jupyter do Spark ou em Spark submit. Para encontrar a versão do Spark no cluster, executesc.versionem Notebooks Jupyter.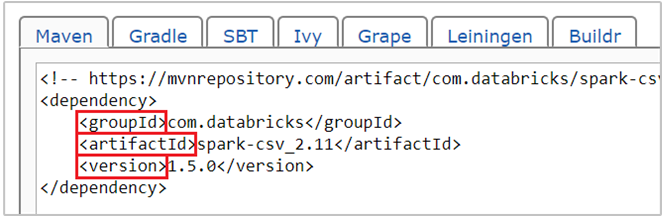
c. Concatene os três valores, separados por dois pontos (:).
com.databricks:spark-csv_2.11:1.5.0Execute a célula de código com a mágica
%%configure. Isso irá configurar a sessão Livy subjacente para usar o pacote fornecido. Nas células subsequentes no bloco de notas, você agora pode usar o pacote conforme mostrado abaixo.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Para o HDInsight 3.4 e anterior, você deve usar o snippet abaixo.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Você pode executar os snippets de código, como mostrado abaixo, para exibir os dados do dataframe que você criou na etapa anterior.
df.show() df.select("Time").count()
Confira também
Cenários
- Apache Spark com BI: execute análise de dados interativa usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever os resultados da inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Criar e executar aplicativos
- Criar um aplicativo autônomo usando Scala
- Execute trabalhos remotamente em um cluster do Apache Spark usando o Apache Livy
Ferramentas e extensões
- Usar pacotes Python externos com Jupyter Notebooks em clusters do Apache Spark no HDInsight Linux
- Use o Plug-in de Ferramentas do HDInsight para IntelliJ IDEA para criar e enviar aplicativos Spark Scala
- Use o Plugin do HDInsight Tools para o IntelliJ IDEA para depurar os aplicativos do Apache Spark remotamente
- Use os blocos de anotações do Apache Zeppelin com um cluster do Apache Spark no HDInsight
- Kernels disponíveis para o Jupyter Notebook no cluster do Apache Spark para HDInsight
- Instalar o Jupyter em seu computador e conectar-se a um cluster Spark do HDInsight