Este projeto cliente ajudou uma empresa de alimentos da Fortune 500 a melhorar sua previsão de demanda. A empresa envia produtos diretamente para vários pontos de venda. A melhoria os ajudou a otimizar a estocagem de seus produtos em diferentes lojas em várias regiões dos Estados Unidos. Para isso, a equipe de Engenharia de Software Comercial (CSE) da Microsoft trabalhou com os cientistas de dados do cliente em um estudo piloto para desenvolver modelos de machine learning personalizados para as regiões selecionadas. Os modelos levam em conta:
- Dados demográficos dos compradores
- Histórico e previsão meteorológicos
- Remessas anteriores
- Devoluções de produtos
- Eventos especiais
A meta de otimizar o estoque representou um componente importante do projeto e o cliente percebeu um aumento significativo de vendas nas primeiras avaliações de campo. Além disso, a equipe viu uma redução de 40% na previsão de mape (erro percentual absoluto médio) quando comparado com um modelo de linha de base médio histórico.
Uma parte fundamental do projeto foi descobrir como escalar verticalmente o fluxo de trabalho de ciência de dados do estudo piloto para um nível de produção. Esse fluxo de trabalho em nível de produção exigia que a equipe de CSE:
- Desenvolvesse modelos para muitas regiões.
- Atualize e monitore continuamente o desempenho dos modelos.
- Facilite a colaboração entre os dados e as equipes de engenharia.
O fluxo de trabalho típico de ciência de dados atualmente está mais próximo de um ambiente de laboratório único do que de um fluxo de trabalho de produção. Um ambiente para cientistas de dados deve ser adequado para eles:
- Preparar os dados.
- Experimentar modelos diferentes.
- Ajustar hiperparâmetros.
- Crie um ciclo build-test-evaluate-refine.
A maioria das ferramentas usadas para essas tarefas tem finalidades específicas e não são adequadas para automação. Em uma operação de aprendizado de máquina no nível de produção, deve haver mais consideração sobre o gerenciamento do ciclo de vida do aplicativo e o DevOps.
A equipe do CSE ajudou o cliente a escalar verticalmente a operação para os níveis de produção. Eles implementaram vários aspectos das funcionalidades de integração contínua e entrega contínua (CI/CD) e resolveram problemas como observabilidade e integração com as funcionalidades do Azure. Durante a implementação, a equipe descobriu lacunas nas diretrizes existentes do MLOps. Essas lacunas precisavam ser preenchidas para que o MLOps fosse melhor compreendido e aplicado em escala.
Entender as práticas de MLOps ajuda as organizações a garantir que os modelos de machine learning que o sistema produz são modelos de qualidade de produção que melhoram o desempenho dos negócios. Quando o MLOps é implementado, a organização não precisa mais gastar tanto tempo em detalhes de baixo nível relacionados ao trabalho de infraestrutura e engenharia necessários para desenvolver e executar modelos de machine learning para operações de nível de produção. A implementação do MLOps também ajuda as comunidades de ciência de dados e engenharia de software a aprender a trabalhar em conjunto para fornecer um sistema pronto para produção.
A equipe do CSE usou esse projeto para atender às necessidades da comunidade de machine learning resolvendo problemas como o desenvolvimento de um modelo de maturidade do MLOps. Esses esforços tinham como objetivo melhorar a adoção de MLOps, compreendendo os desafios típicos dos principais participantes do processo de MLOps.
Cenários técnicos e de participação
O cenário de engajamento discute os desafios reais que a equipe do CSE teve que resolver. O cenário técnico define os requisitos para criar um ciclo de vida MLOps tão confiável quanto o ciclo de vida de DevOps bem estabelecido.
Cenário de participação
O cliente entrega produtos diretamente para lojas de varejo seguindo uma agenda regular. Cada saída de varejo varia em seus padrões de uso do produto, portanto, o inventário de produtos precisa variar em cada entrega semanal. Maximizar vendas e minimizar retornos de produtos e oportunidades de vendas perdidas são as metas das metodologias de previsão de demanda que o cliente usa. Este projeto se concentrou no uso do aprendizado de máquina para melhorar as previsões.
A equipe de CSE dividiu o projeto em duas fases. A fase 1 se concentrou no desenvolvimento de modelos de machine learning para dar suporte a um estudo piloto baseado em campo sobre a eficácia da previsão de machine learning para uma região de vendas selecionada. O sucesso da Fase 1 levou à Fase 2, na qual a equipe escalou o estudo piloto inicial de um grupo mínimo de modelos que apoiavam uma única região geográfica para um conjunto de modelos de nível de produção sustentável para todas as regiões de vendas do cliente. Uma das principais considerações para a solução de expansão foi a necessidade de acomodar o grande número de regiões geográficas e seus pontos de venda locais. A equipe dedicou os modelos de machine learning a lojas de varejo grandes e pequenas em cada região.
O estudo piloto da Fase 1 determinou que um modelo dedicado aos pontos de venda de uma região poderia usar o histórico de vendas local, a demografia local, o clima e eventos especiais para otimizar a previsão de demanda para os pontos de venda na região. Quatro modelos de previsão de machine learning de conjunto atenderam pontos de venda em uma única região. Os modelos processam dados em lotes semanais. Além disso, a equipe desenvolveu dois modelos de linha de base usando dados históricos para comparação.
Para a primeira versão da solução de Fase 2 expandida, a equipe do CSE selecionou 14 regiões geográficas para participar, incluindo pequenas e grandes saídas de mercado. Eles usaram mais de 50 modelos de previsão de machine learning. A equipe esperava aumentar o sistema e realizar o refinamento contínuo dos modelos de machine learning. Rapidamente ficou claro que essa solução de machine learning em escala mais ampla só é sustentável se for baseada nos princípios de prática recomendada do DevOps para o ambiente de aprendizado de máquina.
| Environment | Região do mercado | Formatar | Modelos | Subdivisão de modelo | Descrição do modelo |
|---|---|---|---|---|---|
| Ambiente de desenvolvimento | Cada região/mercado geográfico (por exemplo, Norte do Texas) | Lojas de formato grande (supermercados, grandes lojas de caixas e assim por diante) | Dois modelos de conjunto | Produtos de movimentação lenta | Lento e rápido ambos têm um conjunto de um modelo de regressão linear de operador de redução e seleção (LASSO) mínimo absoluto e uma rede neural com inserções categóricas |
| Produtos de movimentação rápida | Lento e rápido ambos têm um conjunto de um modelo de regressão linear LASSO e uma rede neural com inserções categóricas | ||||
| Um modelo de conjunto | N/D | Média histórica | |||
| Pequenos repositórios de formato (farmácias, lojas de conveniência e assim por diante) | Dois modelos de conjunto | Produtos de movimentação lenta | Lento e rápido ambos têm um conjunto de um modelo de regressão linear LASSO e uma rede neural com inserções categóricas | ||
| Produtos de movimentação rápida | Lento e ambos têm um conjunto de um modelo de regressão linear LASSO e uma rede neural com inserções categóricas | ||||
| Um modelo de conjunto | N/D | Média histórica | |||
| O mesmo que acima para 13 regiões geográficas adicionais | |||||
| O mesmo que acima para o ambiente de prod |
O processo de MLOps forneceu uma estrutura para o sistema escalonado que abordou o ciclo de vida completo dos modelos de machine learning. A estrutura inclui desenvolvimento, teste, implantação, operação e monitoramento. Ele atende às necessidades de um processo de CI/CD clássico. No entanto, devido à sua imaturidade relativa em comparação ao DevOps, ficou evidente que as diretrizes de MLOps existentes tinham lacunas. A equipe de projeto trabalhou para preencher algumas dessas lacunas. Eles queriam fornecer um modelo de processo funcional que assegurasse a viabilidade da solução de machine learning ampliada.
O processo de MLOps desenvolvido a partir deste projeto deu um passo significativo no mundo real para mover o MLOps para um nível mais alto de maturidade e viabilidade. O novo processo é aplicável diretamente a outros projetos de machine learning. A equipe do CSE usou o que aprendeu para criar um rascunho de um modelo de maturidade do MLOps que qualquer pessoa pode aplicar a outros projetos de machine learning.
Cenário técnico
O MLOps, também conhecido como DevOps para machine learning, é um termo guarda-chuva que abrange filosofias, práticas e tecnologias relacionadas à implementação de ciclos de vida de machine learning em um ambiente de produção. Ainda é um conceito relativamente novo. Houve muitas tentativas de definir o que é MLOps e muitas pessoas têm questionado se o MLOps pode subsume tudo, desde como os cientistas de dados preparam dados até como eles entregam, monitoram e avaliam os resultados do aprendizado de máquina. Embora o DevOps tenha tido anos para desenvolver um conjunto de práticas fundamentais, o MLOps ainda está no início de seu desenvolvimento. À medida que evolui, descobrimos os desafios de reunir duas disciplinas que geralmente operam com diferentes conjuntos de habilidades e prioridades: engenharia de software/operações e ciência de dados.
A implementação de MLOps em ambientes de produção do mundo real tem desafios exclusivos que devem ser superados. O Teams pode usar o Azure para dar suporte a padrões MLOps. O Azure também pode fornecer aos clientes serviços de gerenciamento de ativos e orquestração para gerenciar efetivamente o ciclo de vida do machine learning. Os serviços do Azure são a base para a solução MLOps que descrevemos neste artigo.
Requisitos do modelo de machine learning
Grande parte do trabalho durante o estudo de campo piloto da Fase 1 foi a criação dos modelos de machine learning que a equipe do CSE aplicou às grandes e pequenas lojas de varejo em uma única região. Requisitos notáveis para os modelos incluídos:
Uso do Serviço do Azure Machine Learning.
Modelos experimentais iniciais que foram desenvolvidos em notebooks Jupyter e implementados no Python.
Observação
O Teams usou a mesma abordagem de machine learning para repositórios grandes e pequenos, mas os dados de treinamento e pontuação dependiam do tamanho do repositório.
Dados que exigem preparação para o consumo de modelo.
Dados processados em lote e não em tempo real.
Treinar novamente o modelo sempre que o código ou os dados forem alterados ou o modelo ficar obsoleto.
Exibição do desempenho do modelo nos painéis do Power BI.
Desempenho do modelo na pontuação que é considerado significativo quando MAPE <= 45% quando comparado com um modelo de linha de base médio histórico.
Requisitos de MLOps
A equipe teve que atender a vários requisitos importantes para escalar verticalmente a solução do estudo de campo piloto da Fase 1, no qual apenas alguns modelos foram desenvolvidos para uma única região de vendas. A fase 2 implementou modelos personalizados de machine learning para várias regiões. A implementação incluiu:
Processamento semanal em lotes para repositórios grandes e pequenos em cada região para treinar novamente os modelos com novos conjuntos de dados.
Refinamento contínuo dos modelos de machine learning.
Integração do processo de desenvolvimento/teste/empacotamento/teste/implantação comum à CI/CD em um ambiente de processamento para MLOps semelhante ao de DevOps.
Observação
Isso representa uma mudança em como cientistas de dados e engenheiros de dados normalmente trabalhavam no passado.
Um modelo exclusivo que representava cada região para repositórios grandes e pequenos com base no histórico do repositório, na demografia e em outras variáveis-chave. O modelo teve que processar todo o conjunto de dados para minimizar o risco de erro de processamento.
A capacidade de escalar verticalmente inicialmente para dar suporte a 14 regiões de vendas com planos de aumentar ainda mais.
Planos para modelos adicionais para previsão de longo prazo para regiões e outros clusters de lojas.
Solução de modelo de machine learning
O ciclo de vida do aprendizado de máquina, também conhecido como ciclo de vida da ciência de dados, se encaixa aproximadamente no seguinte fluxo de processo de alto nível:
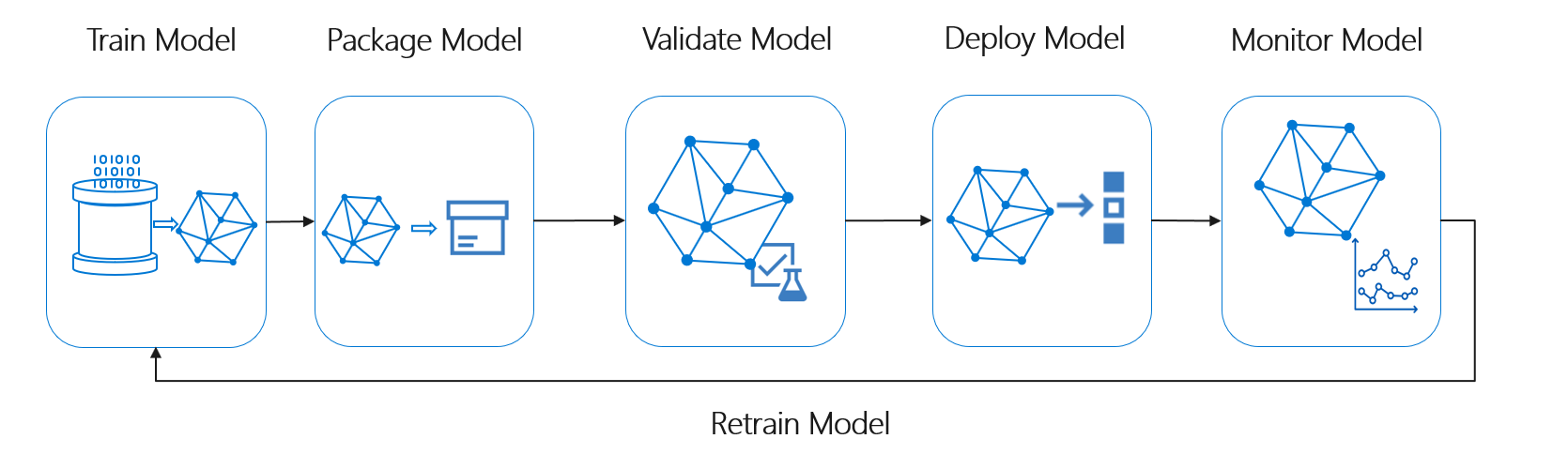
Implantar Modelo aqui pode representar qualquer uso operacional do modelo de machine learning validado. Em comparação com o DevOps, o MLOps apresenta o desafio adicional de integrar o ciclo de vida do aprendizado de máquina ao processo típico de CI/CD.
O ciclo de vida da ciência de dados não segue o ciclo de vida típico de desenvolvimento de software. Ele inclui o uso do Azure Machine Learning para treinar e pontuar os modelos, portanto, essas etapas tiveram que ser incluídas na automação de CI/CD.
O processamento em lote de dados é a base da arquitetura. Dois pipelines do Azure Machine Learning pipelines são centrais para o processo, um para treinamento e outro para pontuação. Este diagrama mostra a metodologia de ciência de dados usada para a fase inicial do projeto cliente:
A equipe testou vários algoritmos. Eles finalmente escolheram um design de conjunto de um modelo de regressão linear LASSO e uma rede neural com inserções categóricas. A equipe usou o mesmo modelo, definido pelo nível do produto que o cliente podia armazenar no site, para lojas grandes e pequenas. A equipe subdividiu ainda mais o modelo em produtos de movimentação rápida e lenta.
Os cientistas de dados treinam os modelos de machine learning quando a equipe lança um novo código e quando novos dados estão disponíveis. O treinamento normalmente acontece semanalmente. Com isso, cada execução de processamento envolve uma grande quantidade de dados. Como a equipe coleta os dados de muitas fontes em formatos diferentes, é necessário condicionamento para colocar os dados em um formato consumível antes que os cientistas de dados possam processá-los. O condicionamento de dados requer um esforço manual significativo e a equipe do CSE identificou-o como um candidato primário para automação.
Conforme mencionado, os cientistas de dados desenvolveram e aplicaram os modelos experimentais do Azure Machine Learning a uma única região de vendas no estudo de campo piloto da Fase 1 para avaliar a utilidade dessa abordagem de previsão. A equipe do CSE julgou que o aumento das vendas das lojas no estudo piloto foi significativo. Esse sucesso justificou a aplicação da solução a níveis de produção completos na Fase 2, começando com 14 regiões geográficas e milhares de lojas. Em seguida, a equipe pôde usar o mesmo padrão para adicionar outras regiões.
O modelo piloto serviu de base para a solução escalonada, mas a equipe do CSE sabia que o modelo precisava de mais refinamento em uma base contínua para melhorar seu desempenho.
Solução de MLOps
À medida que os conceitos do MLOps amadurecem, as equipes geralmente descobrem desafios para reunir as disciplinas de ciência de dados e DevOps. O motivo é que os principais participantes das disciplinas, engenheiros de software e cientistas de dados, operam com diferentes conjuntos de habilidades e prioridades.
Mas há semelhanças para construir. O MLOps, como o DevOps, é um processo de desenvolvimento implementado por uma cadeia de ferramentas. A cadeia de ferramentas do MLOps inclui itens como:
- Controle de versão
- Análise de código
- Automação de compilação
- Integração contínua
- Testar estruturas e automação
- Políticas de conformidade integradas a pipelines de CI/CD
- Automação de implantação
- Monitoramento
- Recuperação de desastres e alta disponibilidade
- Gerenciamento de pacotes e contêineres
Conforme observado acima, a solução aproveita as diretrizes existentes do DevOps, mas é aumentada para criar uma implementação de MLOps mais madura que atenda às necessidades do cliente e da comunidade de ciência de dados. O MLOps se baseia nas diretrizes de DevOps com estes requisitos adicionais:
- O controle de versão de dados e modelos não é o mesmo que o controle de versão de código: deve haver controle de versão de conjuntos de dados à medida que os dados de esquema e de origem são alterados.
- Requisitos de trilha de auditoria digital: controle todas as alterações ao lidar com o código e os dados do cliente.
- Generalização: os modelos são diferentes do código para reutilização, pois os cientistas de dados devem ajustar modelos com base em dados de entrada e cenário. Para reutilizar um modelo em um novo cenário, talvez seja necessário ajustar/transferir/aprender sobre ele. Você precisa do pipeline de treinamento.
- Modelos obsoletos: os modelos tendem a se decair ao longo do tempo e você precisa da capacidade de retreiná-los sob demanda para garantir que permaneçam relevantes na produção.
Desafios do MLOps
Padrão de MLOps imaturo
O padrão de MLOps ainda está evoluindo. Uma solução normalmente é criada do zero e feita para atender às necessidades de um cliente ou usuário específico. A equipe de CSE identificou essa lacuna e tentou usar as melhores práticas de DevOps neste projeto. Eles aumentaram o processo de DevOps para se ajustar aos requisitos adicionais do MLOps. O processo desenvolvido pela equipe é um exemplo viável do que um padrão MLOps pode ser.
Diferenças nos conjuntos de habilidades
Engenheiros de software e cientistas de dados trazem conjuntos de habilidades exclusivos para a equipe. Esses conjuntos de habilidades diferentes podem dificultar a localização de uma solução que atenda às necessidades de todos. É importante criar um fluxo de trabalho bem compreendido para entrega de um modelo da experimentação à produção. Os membros da equipe devem compartilhar uma compreensão de como podem integrar alterações ao sistema sem interromper o processo de MLOps.
Gerenciamento de vários modelos
Geralmente, há a necessidade de vários modelos resolverem cenários difíceis de aprendizado de máquina. Um dos desafios do MLOps é gerenciar esses modelos, incluindo:
- Ter um esquema de controle de versão coerente.
- Avaliando e monitorando continuamente todos os modelos.
A linhagem rastreável de código e dados também é necessária para diagnosticar problemas de modelo e criar modelos reproduzíveis. Os painéis personalizados podem entender como os modelos implantados estão sendo executados e indicar quando intervir. A equipe criou esses dashboards para este projeto.
Necessidade de condicionamento dos dados
Os dados usados com esses modelos vêm de muitas fontes públicas e privadas. Como os dados originais são desorganizados, é impossível para o modelo de machine learning consumi-los em seu estado bruto. Os cientistas de dados devem condicioná-los em um formato padrão para consumo de modelo de machine learning.
Grande parte do teste de campo piloto se concentrou em condicionar os dados brutos para que o modelo de machine learning pudesse processá-lo. Em um sistema de MLOps, a equipe deve automatizar esse processo e acompanhar as saídas.
Modelo de maturidade de MLOps
A finalidade do modelo de maturidade do MLOps é esclarecer os princípios e as práticas e identificar lacunas em uma implementação de MLOps. Também é uma maneira de mostrar a um cliente como aumentar incrementalmente sua capacidade de MLOps em vez de tentar fazer tudo de uma vez. O cliente deve usá-lo como um guia para:
- Estimar o escopo do trabalho para o projeto.
- Estabelecer critérios de sucesso.
- Identificar entregas.
O modelo de maturidade do MLOps define cinco níveis de capacidade técnica:
| Nível | Descrição |
|---|---|
| 0 | Sem Ops |
| 1 | Com DevOps mas sem MLOps |
| 2 | Treinamento automatizado |
| 3 | Implantação de modelo automatizada |
| 4 | Operações automatizadas (MLOps completo) |
Para obter a versão atual do modelo de maturidade de MLOps, confira o artigo Modelo de maturidade de MLOps.
Definição do processo de MLOps
O MLOps inclui todas as atividades desde a aquisição de dados brutos até a entrega da saída do modelo, também conhecida como pontuação:
- Condicionamento de dados
- Treinamento do modelo
- Teste e avaliação de modelos
- Definição de build e pipeline
- Pipeline de lançamento
- Implantação
- Pontuação
Processo básico de machine learning
O processo básico de machine learning se assemelha ao desenvolvimento de software tradicional, mas há diferenças significativas. Este diagrama ilustra as principais etapas do processo de machine learning:
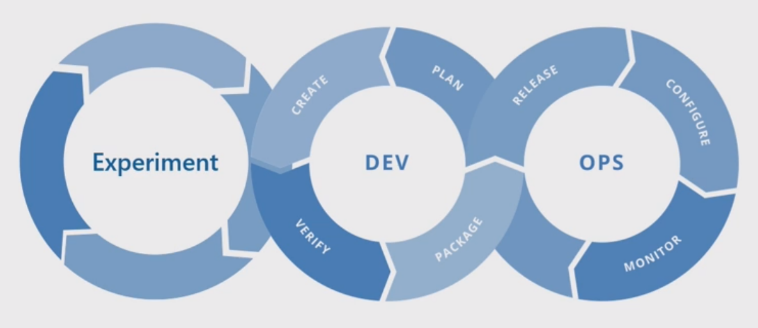
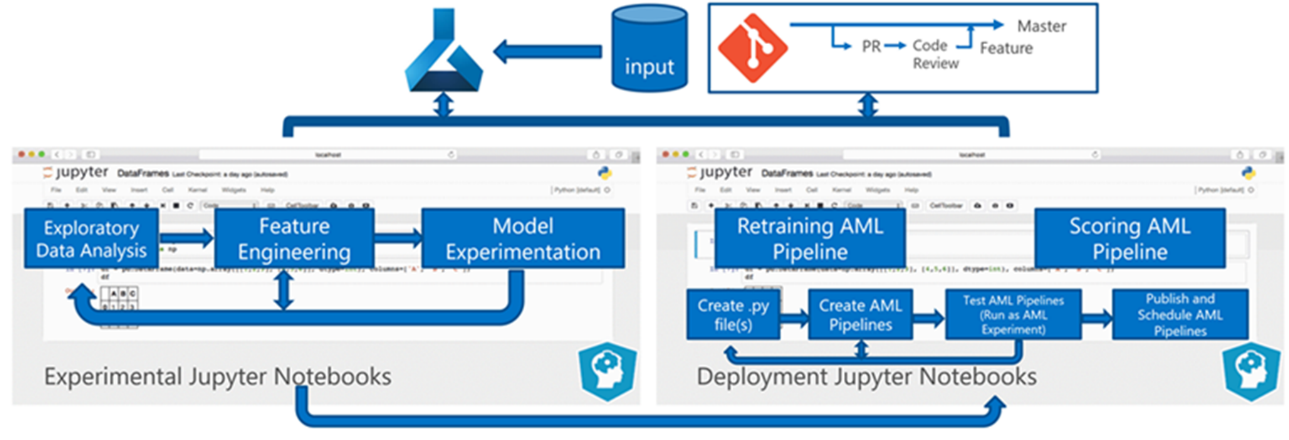
A fase experimento é exclusiva do ciclo de vida da ciência de dados, que reflete como os cientistas de dados tradicionalmente fazem seu trabalho. Ela difere de como os desenvolvedores de código fazem seu trabalho. O diagrama a seguir ilustra esse ciclo de vida em mais detalhes.
A integração desse processo de desenvolvimento de dados ao MLOps representa um desafio. Aqui você vê o padrão que a equipe usou para integrar o processo a um formulário que o MLOps pode dar suporte:
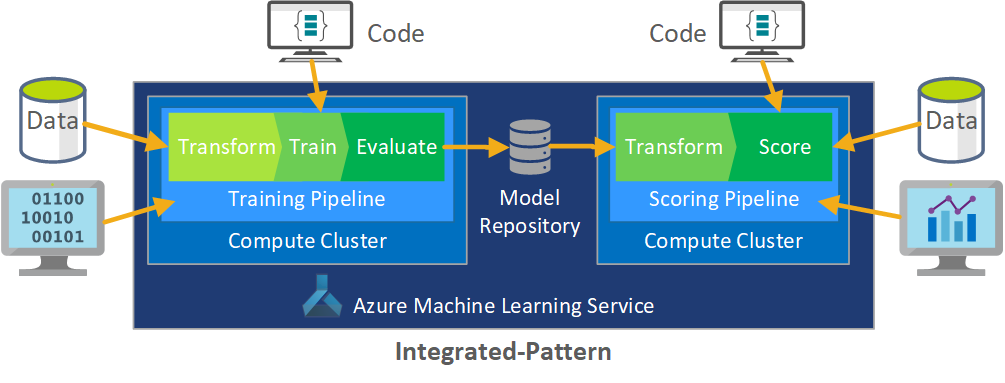
A função do MLOps é criar um processo coordenado que possa dar suporte eficiente aos ambientes de CI/CD em larga escala que são comuns em sistemas de nível de produção. Conceitualmente, o modelo de MLOps deve incluir todos os requisitos de processo, da experimentação à pontuação.
A equipe do CSE refinou o processo de MLOps para atender às necessidades específicas do cliente. A necessidade mais notável foi o processamento em lote em vez do processamento em tempo real. À medida que a equipe desenvolveu o sistema de expansão, eles identificaram e resolveram algumas deficiências. A mais significativa dessas deficiências levou ao desenvolvimento de uma ponte entre o Azure Data Factory e o Azure Machine Learning, que a equipe implementou usando um conector interno no Azure Data Factory. Eles criaram esse conjunto de componentes para facilitar o disparo e monitoramento de status necessários para fazer com que a automação do processo funcionasse.
Outra alteração fundamental foi que os cientistas de dados precisavam da capacidade de exportar código experimental de notebooks Jupyter para o processo de implantação do MLOps em vez de disparar treinamento e pontuação diretamente.
Veja o conceito final do modelo de processo MLOps:
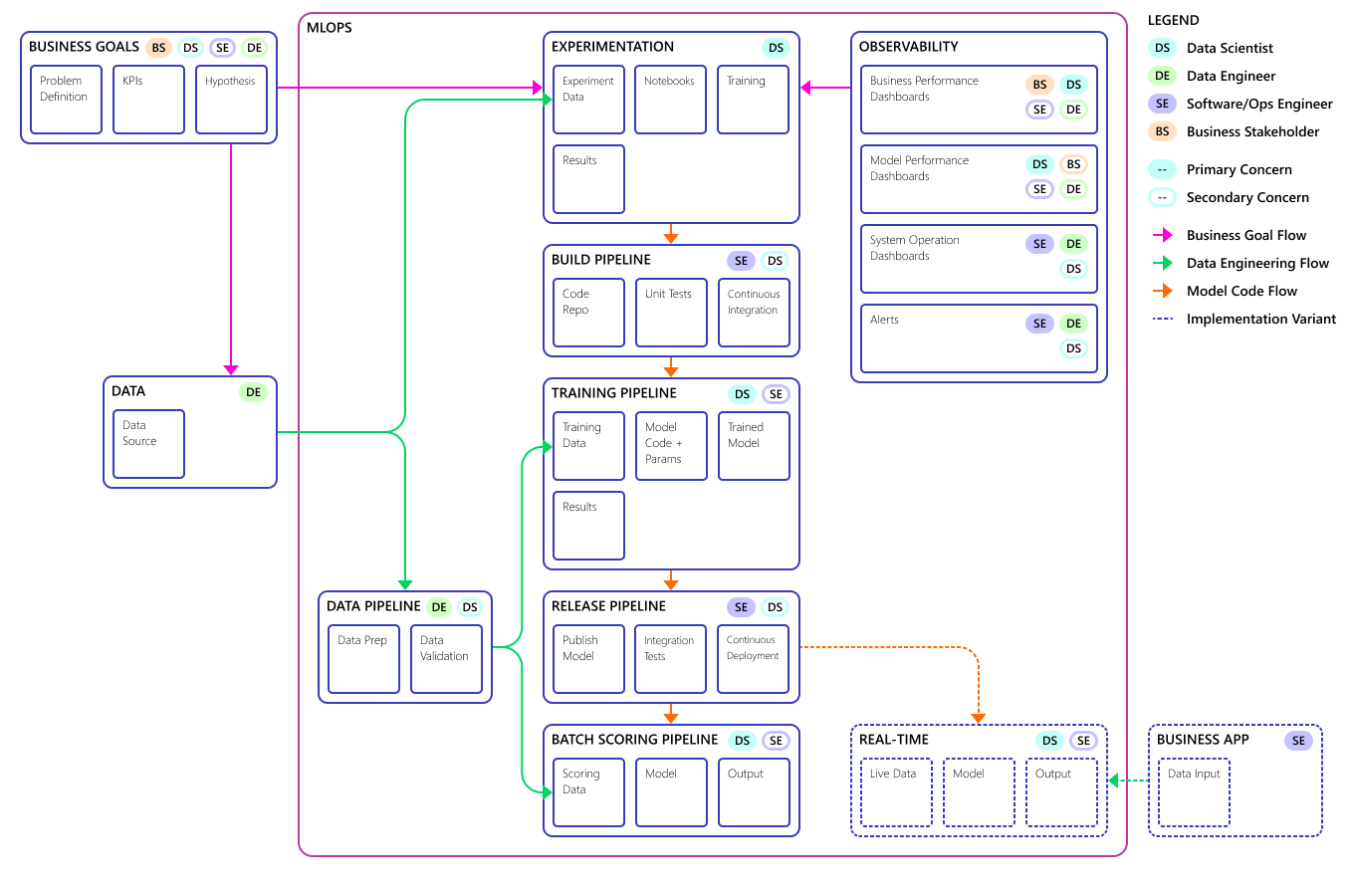
Importante
A pontuação é a etapa final. O processo executa o modelo de machine learning para fazer previsões. Isso cobre o requisito de caso de uso empresarial básico para a previsão de demanda. A equipe classifica a qualidade das previsões usando o MAPE, que é uma medida de precisão de previsão de métodos de previsão estatística e uma função de perda para problemas de regressão no aprendizado de máquina. Neste projeto, a equipe considerou um MAPE de < = 45% significativo.
Fluxo de processo de MLOps
O diagrama abaixo descreve como aplicar os fluxos de trabalho de desenvolvimento e lançamento de CI/CD para ciclo de vida de machine learning:

- Quando uma PR (solicitação de pull) é criada a partir de um branch de recursos, o pipeline executa testes de validação de código para validar a qualidade do código por meio de testes de unidade e testes de qualidade de código. Para validar o upstream de qualidade, o pipeline também executa testes básicos de validação de modelo para validar as etapas de treinamento e pontuação de ponta a ponta com um conjunto de dados fictícios de exemplo.
- Quando a PR é mesclada na ramificação principal, o pipeline de CI executará os mesmos testes de validação de código e testes básicos de validação de modelo com uma época maior. Depois, o pipeline empacotará os artefatos, que incluem o código e os binários, para executar no ambiente de machine learning.
- Depois que os artefatos estiverem disponíveis, um pipeline de CD de validação de modelo será disparado. Ele executa a validação de ponta a ponta no ambiente de machine learning de desenvolvimento. Um mecanismo de pontuação é publicado. Para um cenário de pontuação em lote, um pipeline de pontuação é publicado no ambiente de machine learning e disparado para produzir resultados. Se você quiser usar um cenário de pontuação em tempo real, poderá publicar um aplicativo Web ou implantar um contêiner.
- Depois que um marco é criado e mesclado no branch de lançamento, o mesmo pipeline de CI e pipeline de CD de validação de modelo são disparados. Desta vez, eles são executados no código do branch de lançamento.
Você pode considerar o fluxo de dados do processo MLOps mostrado acima como uma estrutura de arquétipo para projetos que fazem escolhas de arquitetura semelhantes.
Testes de validação de código
Os testes de validação de código para machine learning se concentram na validação da qualidade da base do código. É o mesmo conceito de qualquer projeto de engenharia que tenha testes de qualidade de código (linting), testes de unidade e medidas de cobertura de código.
Testes básicos de validação de modelo
A validação de modelo geralmente se refere à validação das etapas completas do processo de ponta a ponta necessárias para produzir um modelo de machine learning válido. Ele inclui etapas como:
- Validação de dados: garante que os dados de entrada são válidos.
- Validação de treinamento: garante que o modelo possa ser treinado com êxito.
- Validação de pontuação: garante que a equipe possa usar com êxito o modelo treinado para pontuação com os dados de entrada.
Executar esse conjunto completo de etapas no ambiente de machine learning é caro e demorado. Como resultado, a equipe fez testes básicos de validação de modelo localmente em um computador de desenvolvimento. Ele executou as etapas acima e usou o seguinte:
- Conjunto de dados de teste local: um pequeno conjunto de dados, geralmente um que é ofuscado, que é verificado no repositório e consumido como a fonte de dados de entrada.
- Sinalizador local: um sinalizador ou argumento no código do modelo que indica que o código deseja que o conjunto de dados seja executado localmente. O sinalizador informa ao código para ignorar qualquer chamada para o ambiente de aprendizado de máquina.
Essa meta desses testes de validação não é avaliar o desempenho do modelo treinado. Em vez disso, é para validar que o código para o processo de ponta a ponta é de boa qualidade. Ele garante a qualidade do código que é enviado por push upstream, como a incorporação de testes de validação de modelo no build de PR e CI. Também possibilita que engenheiros e cientistas de dados coloquem pontos de interrupção no código para fins de depuração.
Pipeline de CD de validação de modelo
A meta do pipeline de validação de modelo é validar as etapas de treinamento e pontuação dos modelos de ponta a ponta no ambiente de machine learning com dados reais. Qualquer modelo treinado produzido será adicionado ao registro de modelo e marcado para aguardar a promoção após a conclusão da validação. Para previsão em lote, a promoção pode ser a publicação de um pipeline de pontuação que usa essa versão do modelo. Para pontuação em tempo real, o modelo pode ser marcado para indicar que foi promovido.
Pipeline de pontuação de CD
O pipeline de CD de pontuação é aplicável ao cenário de inferência em lote, em que o mesmo orquestrador de modelo usado para validação de modelo dispara o pipeline de pontuação publicado.
Ambientes de desenvolvimento e de produção
É uma boa prática separar o ambiente de desenvolvimento (desenvolvimento) do ambiente de produção (prod). A separação permite que o sistema dispare o pipeline de CD de validação de modelo e o pipeline de CD de pontuação em agendas diferentes. Para o fluxo de MLOps descrito, os pipelines direcionados à execução da ramificação principal no ambiente de desenvolvimento e o pipeline direcionado à ramificação de lançamento são executados no ambiente de prod.
Alterações de código e alterações de dados
As seções anteriores lidam principalmente com como lidar com alterações de código do desenvolvimento para o lançamento. No entanto, as alterações de dados devem seguir o mesmo rigor que as alterações de código para fornecer a mesma qualidade de validação e consistência na produção. Com um gatilho de alteração de dados ou um gatilho de temporizador, o sistema pode disparar o pipeline de CD de validação do modelo e o pipeline de CD de pontuação do orquestrador de modelos para executar o mesmo processo executado para alterações de código no ambiente de lançamento de ramificação.
MLOps personas e funções
Um requisito fundamental para qualquer processo de MLOps é que ele atenda às necessidades dos muitos usuários do processo. Para fins de design, considere esses usuários como personas individuais. Para este projeto, a equipe identificou essas personas:
- Cientista de dados: cria o modelo de machine learning e os respectivos algoritmos.
- Engenheiro
- Engenheiro de dados: lida com o condicionamento de dados.
- Engenheiro de software: lida com a integração do modelo ao pacote de ativos no fluxo de trabalho de CI/CD.
- Operações ou TI: supervisiona as operações do sistema.
- Stakeholder de negócios: preocupado com as previsões feitas pelo modelo de machine learning e como eles ajudam a empresa.
- Usuário final de dados: consome a saída do modelo de alguma forma que ajuda na tomada de decisões de empresariais.
A equipe precisava lidar com três conclusões importantes dos estudos de função e persona:
- Os cientistas de dados e engenheiros têm uma incompatibilidade de abordagem e habilidades no trabalho. Facilitar a colaboração do cientista de dados e do engenheiro é uma grande consideração para o design do fluxo de processo do MLOps. Ele requer novas aquisições de habilidades por todos os membros da equipe.
- Há a necessidade de unificar todas as personas principais sem alienar ninguém. Uma maneira de fazer isso é:
- Certifique-se de que eles entendam o modelo conceitual para MLOps.
- Concorde com os membros da equipe que trabalharão juntos.
- Estabeleça diretrizes de trabalho para alcançar metas comuns.
- Se o stakeholder empresarial e o usuário final de dados precisarem de uma maneira de interagir com a saída de dados dos modelos, uma interface do usuário amigável será a solução padrão.
Outras equipes certamente terão problemas semelhantes em outros projetos de machine learning à medida que eles escalam verticalmente para uso em produção.
Arquitetura da solução de MLOps
Arquitetura lógica
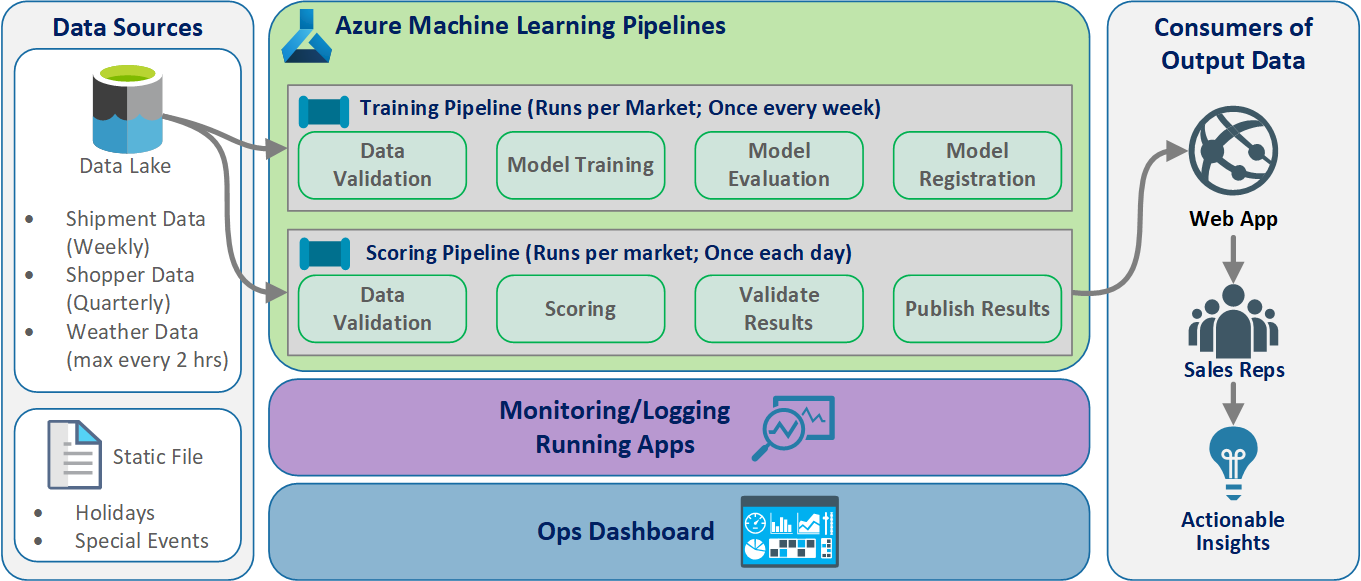
Os dados são provenientes de muitas fontes em vários formatos diferentes, portanto, são condicionadas antes de serem inseridas no data lake. O condicionamento é feito usando microsserviços que operam como Azure Functions. Os clientes personalizam os microsserviços para ajustar as fontes de dados e transformá-los em um formato csv padronizado que os pipelines de treinamento e pontuação consomem.
Arquitetura do sistema
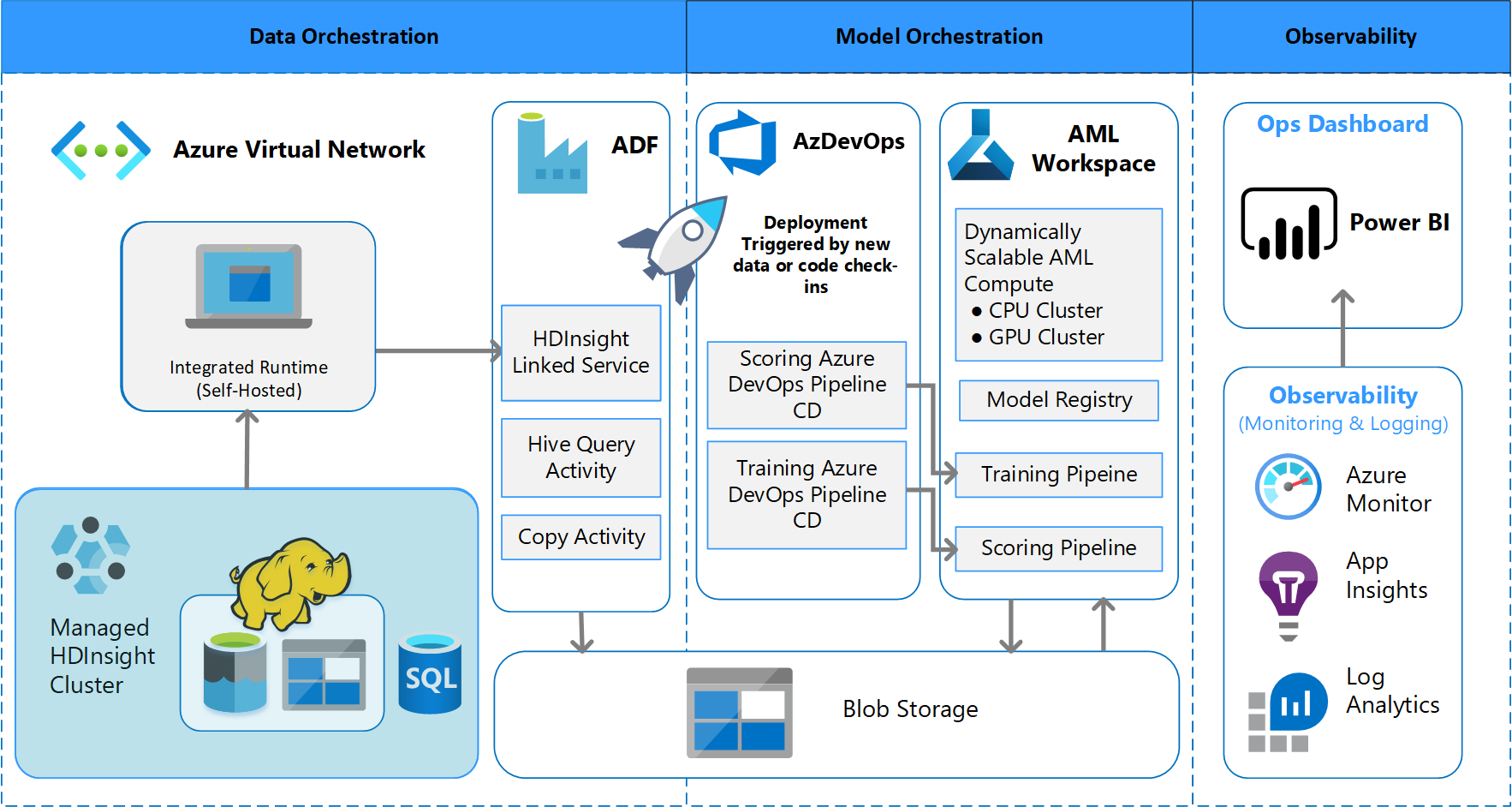
Arquitetura de processamento em lote
A equipe criou o design arquitetônico para dar suporte a um esquema de processamento de dados em lotes. Há alternativas, mas o que for usado deve dar suporte a processos de MLOps. O uso completo dos serviços do Azure disponíveis foi um requisito de design. O seguinte diagrama mostra a arquitetura:
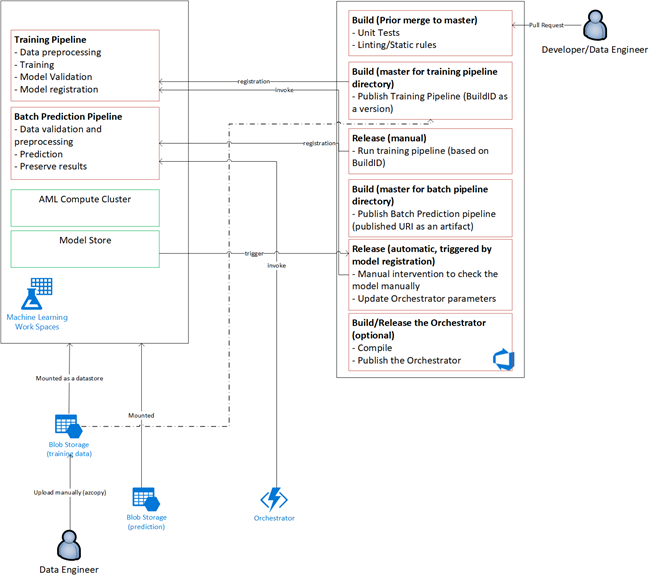
Visão geral da solução
O Azure Data Factory faz o seguinte:
- Dispara uma Função do Azure para iniciar a ingestão de dados e uma execução do pipeline do Azure Machine Learning.
- Inicia uma função durável para sondar o pipeline do Azure Machine Learning para conclusão.
Os dashboards personalizados no Power BI exibem os resultados. Outros painéis do Azure conectados ao Azure SQL, ao Azure Monitor e ao App Insights por meio do SDK do Python do OpenCensus rastreiam os recursos do Azure. Esses dashboards fornecem informações sobre a integridade do sistema de machine learning. Eles também geram dados que o cliente usa para previsão de pedidos de produto.
Orquestração de modelo
A orquestração de modelo segue estas etapas:
- Quando uma PR é enviada, o DevOps dispara um pipeline de validação de código.
- O pipeline executa testes de unidade, testes de qualidade de código e testes de validação de modelo.
- Quando mesclados no branch principal, os mesmos testes de validação de código são executados e o DevOps empacota os artefatos.
- A coleta de artefatos do DevOps dispara o Azure Machine Learning a ser feito:
- Validação de dados.
- Validação de treinamento.
- Validação de pontuação.
- Após a conclusão da validação, o pipeline de pontuação final é executado.
- Alterar dados e enviar uma nova PR dispara o pipeline de validação novamente, seguido pelo pipeline de pontuação final.
Habilitar experimentação
Conforme mencionado, o ciclo de vida de machine learning de ciência de dados tradicional não dá suporte ao processo de MLOps sem modificação. Ele usa diferentes tipos de ferramentas manuais e experimentação, validação, empacotamento e entrega de modelo que não podem ser facilmente dimensionados para um processo eficaz de CI/CD. O MLOps exige um alto nível de automação de processo. Se um novo modelo de machine learning está sendo desenvolvido ou um antigo é modificado, é necessário automatizar o ciclo de vida do modelo de machine learning. No projeto fase 2, a equipe usou o Azure DevOps para orquestrar e republicar pipelines do Azure Machine Learning para tarefas de treinamento. O branch principal de execução longa executa testes básicos de modelos e envia por push versões estáveis por meio do branch de lançamento de longa execução.
O controle do código-fonte se torna uma parte importante desse processo. O Git é o sistema de controle de versão usado para acompanhar o notebook e o código do modelo. Ele também dá suporte à automação de processos. O fluxo de trabalho básico implementado para o controle do código-fonte aplica os seguintes princípios:
- Use o controle de versão formal para conjuntos de dados e código.
- Use um branch para desenvolvimento de código novo até que o código seja totalmente desenvolvido e validado.
- Depois que o novo código for validado, ele poderá ser mesclado no branch principal.
- Para uma versão, um branch com versão permanente é criado separado do branch principal.
- Use versões e controle do código-fonte para os conjuntos de dados que foram condicionados para treinamento ou consumo, para que você possa manter a integridade de cada conjunto de dados.
- Use o controle do código-fonte para acompanhar seus experimentos do Jupyter Notebook.
Integração a fontes de dados
Os cientistas de dados usam muitas fontes de dados brutos e os conjuntos de dados processados para experimentar modelos de machine learning diferentes. O volume de dados em um ambiente de produção pode ser impressionante. Para que os cientistas de dados experimentem modelos diferentes, eles precisam usar ferramentas de gerenciamento como o Azure Data Lake. O requisito para identificação formal e controle de versão se aplica a todos os dados brutos, conjuntos de dados preparados e modelos de machine learning.
No projeto, os cientistas de dados condicionam os seguintes dados para entrada no modelo:
- Dados históricos de remessa semanal desde janeiro de 2017
- Dados meteorológicos diários históricos e previstos para cada código postal
- Dados do comprador para cada ID do repositório
Integração ao controle do código-fonte
Para que os cientistas de dados apliquem as melhores práticas de engenharia, é necessário integrar convenientemente as ferramentas que eles usam com sistemas de controle do código-fonte, como o GitHub. Essa prática permite o controle de versão do modelo de machine learning, a colaboração entre os membros da equipe e a recuperação de desastres caso as equipes experimentem uma perda de dados ou uma interrupção do sistema.
Modelo de suporte do conjunto
O design do modelo neste projeto era um modelo de conjunto. Ou seja, os cientistas de dados usaram muitos algoritmos no design do modelo final. Nesse caso, os modelos usaram o mesmo design básico de algoritmo. A única diferença era que eles usaram dados de treinamento e de pontuação diferentes. Os modelos usaram a combinação de um algoritmo de regressão linear de LASSO e uma rede neural.
A equipe explorou, mas não implementou, uma opção para levar o processo adiante até o ponto em que daria suporte a ter muitos modelos em tempo real em execução em produção para atender a uma determinada solicitação. Essa opção pode acomodar o uso de modelos de conjunto em testes A/B e experimentos intercalados.
Interfaces do usuário final
A equipe desenvolveu as interfaces do usuário final para oferecer observabilidade, monitoramento e instrumentação. Conforme mencionado, os dashboards exibem visualmente os dados do modelo de machine learning. Esses dashboards mostram os seguintes dados em um formato amigável:
- Etapas de pipeline, incluindo o pré-processamento dos dados de entrada.
- Para monitorar a integridade do processamento do modelo de machine learning:
- Quais métricas você coleta do modelo implantado?
- MAPE: Erro percentual absoluto médio, a métrica chave a ser controlada para o desempenho geral. (Direcione um valor MAPE de <= 0,45 para cada modelo.)
- RMSE 0: RMSE (erro raiz-médio-quadrado) quando o valor de destino real = 0.
- RMSE All: RMSE em todo o conjunto de dados.
- Como avaliar se o desempenho do modelo em produção é o esperado?
- Há uma maneira de saber se os dados de produção apresentam muitos desvios dos valores esperados?
- Seu modelo tem um desempenho ruim em produção?
- Você tem um estado de failover?
- Quais métricas você coleta do modelo implantado?
- Acompanhe a qualidade dos dados processados.
- Exiba a pontuação/previsões produzidas pelo modelo de machine learning.
O aplicativo popula os dashboards de acordo com a natureza dos dados e como ele processa e analisa os dados. Assim, a equipe deve projetar o layout exato dos dashboards para cada caso de uso. Confira abaixo dois painéis de exemplo:
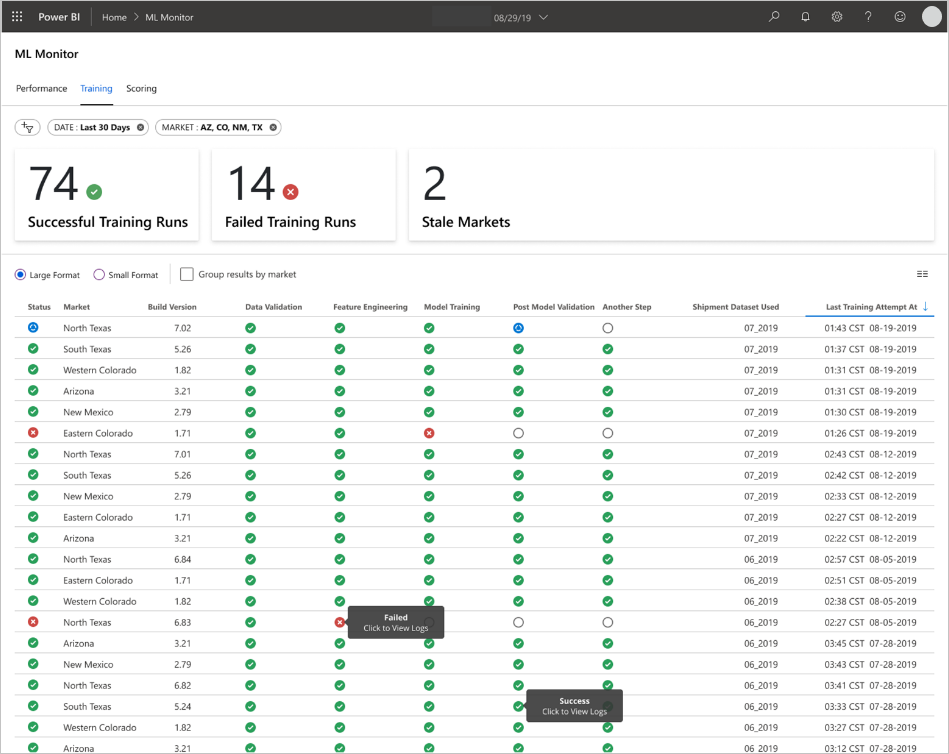
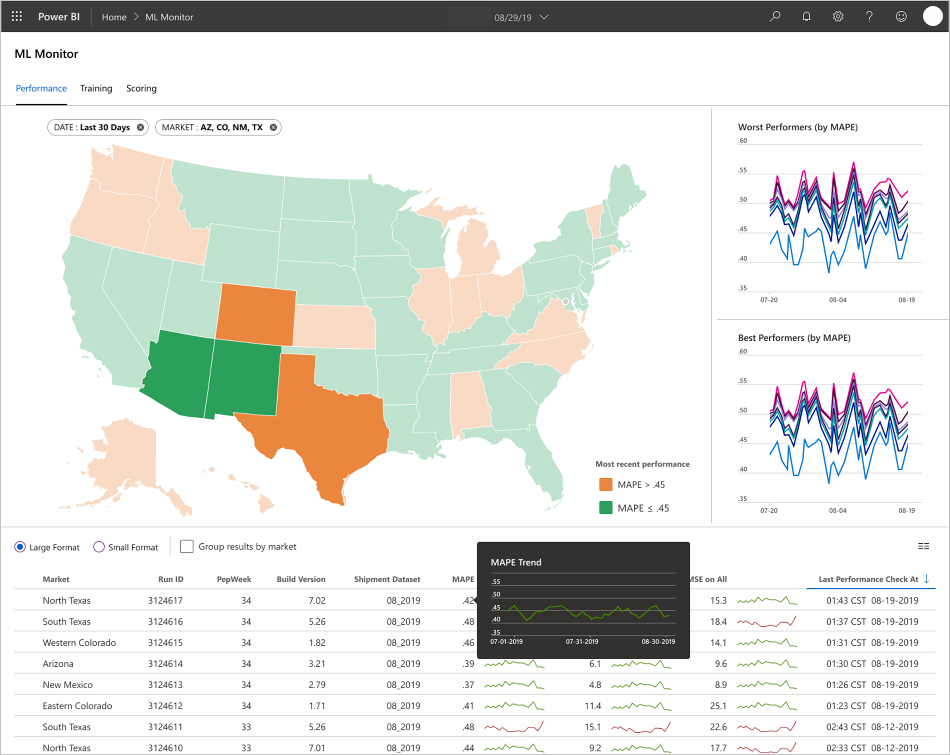
Os painéis foram projetados para fornecer informações prontamente utilizáveis para consumo pelo usuário final das previsões do modelo de machine learning.
Observação
Modelos obsoletos são execuções de pontuação em que os cientistas de dados treinaram o modelo usado para pontuar mais de 60 dias a partir de quando a pontuação ocorreu. A página Pontuação do dashboard Monitor de ML exibe essa métrica de integridade.
Componentes
- Azure Machine Learning
- Armazenamento de Blobs do Azure
- Armazenamento do Azure Data Lake
- Azure Pipelines
- Azure Data Factory
- Azure Functions para Python
- Azure Monitor
- Banco de Dados SQL do Azure
- Painéis do Azure
- Power BI
Considerações
Aqui, você encontrará uma lista de considerações a serem exploradas. Eles se baseiam nas lições que a equipe de CSE aprendeu durante o projeto.
Considerações sobre o ambiente
- Os cientistas de dados desenvolvem a maioria de seus modelos de machine learning usando Python, geralmente começando com notebooks Jupyter. Pode ser um desafio implementar esses notebooks como código de produção. Os notebooks do Jupyter são mais uma ferramenta experimental, enquanto os scripts do Python são mais apropriados para produção. As equipes geralmente precisa gastar tempo refatorando o código de criação do modelo em scripts do Python.
- Faça com que os clientes que são novos no DevOps e machine learning estejam cientes de que a experimentação e a produção exigem rigor diferente, portanto, é uma boa prática separar os dois.
- Ferramentas como o Designer Visual do Azure Machine Learning ou o AutoML podem ser eficazes para tirar modelos básicos do chão enquanto o cliente aumenta as práticas de DevOps padrão para aplicar ao restante da solução.
- O Azure DevOps tem plug-ins que podem ser integrados ao Azure Machine Learning para ajudar a disparar etapas de pipeline. O repositório MLOpsPython tem alguns exemplos desses pipelines.
- O aprendizado de máquina geralmente requer máquinas poderosas de unidade de processamento gráfico (GPU) para treinamento. Se o cliente ainda não tiver esse hardware disponível, os clusters de computação do Azure Machine Learning poderão fornecer um caminho eficaz para o provisionamento rápido de hardware eficiente e econômico que dimensiona automaticamente. Se um cliente tiver necessidades avançadas de segurança ou monitoramento, haverá outras opções, como VMs padrão, Databricks ou computação local.
- Para que um cliente seja bem-sucedido, suas equipes de criação de modelos (cientistas de dados) e de implantação (engenheiros de DevOps) precisam ter um canal de comunicação forte. Eles podem fazer isso com reuniões de stand-up diárias ou um serviço formal de chat online. Ambas as abordagens ajudam a integrar seus esforços de desenvolvimento em uma estrutura do MLOps.
Considerações sobre preparação de dados
A solução mais simples para usar o Azure Machine Learning é armazenar dados em uma solução de armazenamento de dados com suporte. Ferramentas como o Azure Data Factory são eficazes para canalizar os dados de origem e destino desses locais de acordo com uma agenda.
É importante que os clientes capturem frequentemente dados de retreinamento adicionais para manter seus modelos atualizados. Se eles ainda não tiverem um pipeline de dados, criar um será uma parte importante da solução geral. O uso de uma solução como conjuntos de dados no Azure Machine Learning pode ser útil para o uso de dados de controle de versão para ajudar na rastreabilidade de modelos.
Considerações sobre treinamento e avaliação de modelo
É impressionante para um cliente que está apenas começando em sua jornada de aprendizado de máquina para tentar implementar um pipeline de MLOps completo. Se necessário, eles podem facilitar isso usando o Azure Machine Learning para acompanhar execuções de experimentos e usando a computação do Azure Machine Learning como o destino de treinamento. Essas opções podem criar uma barreira inferior da solução de entrada para começar a integrar os serviços do Azure.
Passar de um experimento de notebook para scripts repetíveis é uma transição aproximada para muitos cientistas de dados. Quanto mais cedo você conseguir fazer com que eles gravem o código de treinamento em scripts Python, mais fácil será para eles começarem a fazer o controle de versão do código de treinamento e habilitar o treinamento novamente.
Esse não é o único método possível. O Databricks dá suporte ao agendamento de notebooks como trabalhos. Mas, com base na experiência atual do cliente, essa abordagem é difícil de instrumentar com práticas de DevOps completas devido a limitações de teste.
Também é importante entender quais métricas estão sendo usadas para considerar um modelo um sucesso. A precisão por si só geralmente não é boa o suficiente para determinar o desempenho geral de um modelo versus outro.
Considerações de computação
- Os clientes devem considerar o uso de contêineres para padronizar os ambientes de computação. Quase todos os destinos de computação do Azure Machine Learning dão suporte ao uso do Docker. Ter um contêiner manipulando as dependências pode reduzir significativamente o atrito, especialmente se a equipe usar muitos destinos de computação.
Considerações de serviço de modelo
- O SDK do Azure Machine Learning fornece uma opção para implantar diretamente no Serviço de Kubernetes do Azure (AKS) de um modelo registrado, criando limites sobre quais métricas/segurança estão em vigor. Você pode tentar encontrar uma solução mais fácil para os clientes testarem seu modelo, mas é melhor desenvolver uma implantação mais robusta no AKS para cargas de trabalho de produção.
Próximas etapas
- Saiba mais sobre o MLOps
- MLOps no Azure
- Visualizações do Azure Monitor
- Ciclo de vida de machine learning
- Extensão de Machine Learning do Azure DevOps
- CLI do Azure Machine Learning
- Disparar aplicativos, processos ou fluxos de trabalho de CI/CD com base em eventos do Azure Machine Learning
- Configurar o treinamento e a implantação de modelo com Azure DevOps
Recursos relacionados
- Modelo de maturidade do MLOps
- Orquestrar MLOps no Azure Databricks usando o Databricks Notebook
- MLOps para modelos em Python usando o Azure Machine Learning
- Ciência de dados e machine learning com Azure Databricks
- IA de cidadãos com a Power Platform
- Implantar a computação de IA e machine learning local e na borda