A Área de Trabalho Virtual do Azure é um amplo serviço de virtualização de aplicativo e área de trabalho em execução no Microsoft Azure. A Área de Trabalho Virtual possibilita uma experiência de área de trabalho remota segura que ajuda as organizações a aumentar a resiliência dos negócios. Ela oferece gerenciamento simplificado, várias sessões do Windows 10 e 11 Enterprise e otimizações para Microsoft 365 Apps para Grandes Empresas. Com a Área de Trabalho Virtual, você pode implantar e dimensionar suas áreas de trabalho e aplicativos do Windows no Azure em minutos, fornecendo recursos integrados de segurança e conformidade para ajudar a manter seus aplicativos e dados seguros.
Ao habilitar o trabalho remoto para sua organização com a Área de Trabalho Virtual, é importante entender seus recursos de recuperação de desastres (DR) e práticas recomendadas. Essas práticas aumentam a confiabilidade entre regiões para ajudar a manter os dados seguros e os funcionários produtivos. Este artigo fornece considerações sobre os pré-requisitos de continuidade de negócios e recuperação de desastres (BCDR), etapas de implantação e práticas recomendadas. Você aprenderá sobre opções, estratégias e orientações de arquitetura. O conteúdo deste documento permite que você prepare um plano de BCDR bem-sucedido e pode ajudar você a aumentar a resiliência para seus negócios durante eventos de tempo de inatividade planejados e não planejados.
Existem vários tipos de desastres e interrupções, e cada um pode ter um impacto diferente. A resiliência e a recuperação são discutidas detalhadamente para eventos locais e regionais, incluindo a recuperação do serviço em uma região remota diferente do Azure. Esse tipo de recuperação é chamado de recuperação de desastres geográficos. É fundamental criar sua arquitetura de Área de Trabalho Virtual para resiliência e disponibilidade. Você deve fornecer o máximo de resiliência local para reduzir o impacto de eventos de falha. Essa resiliência também reduz os requisitos para executar procedimentos de recuperação. Este artigo também fornece informações sobre alta disponibilidade e práticas recomendadas.
Objetivos e escopo
Os objetivos desse guia são:
- Garanta a máxima disponibilidade, resiliência e capacidade de recuperação de desastre geográfico, minimizando a perda de dados importantes do usuário selecionado.
- Minimize o tempo de recuperação.
Esses objetivos também são conhecidos como objetivo de ponto de recuperação (RPO) e objetivo de tempo de recuperação (RTO).
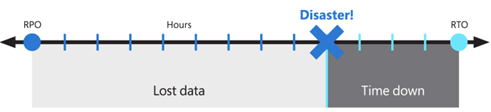
A solução proposta fornece alta disponibilidade local, proteção contra uma única falha de zona de disponibilidade e proteção contra uma falha de região inteira do Azure. Ela depende de uma implantação redundante em uma região diferente ou secundária do Azure para recuperar o serviço. Embora ainda seja uma boa prática, a Área de Trabalho Virtual e a tecnologia usada para criar o BCDR não exigem que as regiões do Azure sejam combinadas. Os locais primário e secundário podem ser qualquer combinação de região do Azure, se a latência de rede permitir. A operação de pools de host do AVD em várias regiões geográficas pode oferecer mais benefícios não limitados ao BCDR.
Para reduzir o impacto de uma única falha de zona de disponibilidade, use a resiliência para melhorar a alta disponibilidade:
- Na camada de computação, espalhe os hosts de sessão da Área de Trabalho Virtual em diferentes zonas de disponibilidade.
- Na camada de armazenamento, use a resiliência de zona sempre que possível.
- Na camada de rede, implante gateways do Azure ExpressRoute resilientes à zona e rede virtual privada (VPN).
- Para cada dependência, analise o impacto de uma única interrupção de zona e planeje mitigações. Por exemplo, implante Controladores de Domínio do Active Directory e outros recursos externos acessados por usuários da Área de Trabalho Virtual em várias zonas de disponibilidade.
Dependendo do número de zonas de disponibilidade que você usa, avalie o provisionamento excessivo do número de hosts de sessão para compensar a perda de uma zona. Por exemplo, mesmo com zonas (n-1) disponíveis, você pode garantir a experiência e o desempenho do usuário.
Observação
As zonas de disponibilidade do Azure são um recurso de alta disponibilidade que pode melhorar a resiliência. No entanto, não as considere uma solução de recuperação de desastres capaz de proteger de desastres em toda a região.

Devido às combinações possíveis de tipos, opções de replicação, recursos de serviço e restrições de disponibilidade em algumas regiões, o componente Cloud Cache do FSLogix é recomendado em vez de mecanismos específicos de replicação de armazenamento.
O OneDrive não é abordado neste artigo. Para obter mais informações sobre redundância e alta disponibilidade, consulte Resiliência de dados do SharePoint e do OneDrive no Microsoft 365.
No restante deste artigo, você aprenderá sobre soluções para os dois tipos diferentes de pool de host de Área de Trabalho Virtual. Há também observações para que você possa comparar essa arquitetura com outras soluções:
- Pessoal: nesse tipo de pool de host, um usuário tem um host de sessão permanentemente atribuído, que nunca deve ser alterado. Como é pessoal, essa VM pode armazenar dados do usuário. A suposição é usar técnicas de replicação e backup para preservar e proteger o estado.
- Em pool: os usuários recebem temporariamente uma das VMs de host de sessão disponíveis do pool, diretamente por meio de um grupo de aplicativos da área de trabalho ou usando aplicativos remotos. As VMs são sem estado, e os dados e perfis do usuário são armazenados no armazenamento externo ou no OneDrive.
As implicações de custo são discutidas, mas o objetivo principal é fornecer uma implantação eficaz de recuperação de desastre geográfico com perda mínima de dados. Para obter mais detalhes sobre BCDR, veja os seguintes recursos:
- Considerações sobre BCDR para Área de Trabalho Virtual
- Recuperação de desastre da Área de Trabalho Virtual
Pré-requisitos
Implante a infraestrutura principal e verifique se ela está disponível na região primária e secundária do Azure. Para obter orientação sobre sua topologia de rede, você pode usar os modelos de topologia de rede e conectividade do Cloud Adoption Framework do Azure:
Em ambos os modelos, implante o pool de host primário de Área de Trabalho Virtual e o ambiente de recuperação de desastre secundário dentro de redes virtuais spoke diferentes e conecte-os a cada hub na mesma região. Coloque um hub no local primário, um hub no local secundário e ative a conectividade entre os dois.
O hub eventualmente fornece conectividade híbrida para recursos locais, serviços de firewall, recursos de identidade, como Controladores de Domínio do Active Directory, e recursos de gerenciamento, como Log Analytics.
Você deve considerar todos os aplicativos de linha de negócios e a disponibilidade de recursos dependentes quando houver failover para o local secundário.
Controlar a continuidade dos negócios e a recuperação de desastres
A Área de Trabalho Virtual oferece continuidade de negócios e recuperação de desastres para seu plano de controle para preservar os metadados do cliente durante interrupções. A plataforma do Azure gerencia esses dados e processos, e os usuários não precisam configurar ou executar nada.

A Área de Trabalho Virtual foi projetada para ser resiliente a falhas de componentes individuais e ser capaz de se recuperar de falhas rapidamente. Quando ocorrer uma interrupção em uma região, os componentes da infraestrutura de serviço realizarão failover no local secundário e continuarão funcionando normalmente. Você ainda pode acessar metadados relacionados ao serviço e os usuários ainda podem se conectar a hosts disponíveis. As conexões do usuário final permanecerão online, desde que o ambiente de locatário ou os hosts permaneçam acessíveis. Os locais de dados da Área de Trabalho Virtual são diferentes do local da implantação das máquinas virtuais (VMs) do host de sessão dos pools de host. É possível localizar metadados da Área de Trabalho Virtual em uma das regiões com suporte e, em seguida, implantar VMs em um local diferente. Veja mais detalhes no artigo Arquitetura e resiliência do serviço de Área de Trabalho Virtual.
Ativo/ativo ou ativo/passivo
Se conjuntos distintos de usuários tiverem requisitos de BCDR diferentes, a Microsoft recomenda que você use vários pools de host com configurações diferentes. Por exemplo, os usuários com um aplicativo de missão crítica podem atribuir um pool de host totalmente redundante com recursos de recuperação de desastre geográfico. No entanto, os usuários de desenvolvimento e teste podem usar um pool de host separado sem nenhuma recuperação de desastre.
Para cada pool de host de Área de Trabalho Virtual, você pode basear sua estratégia de BCDR em um modelo ativo-ativo ou ativo-passivo. Esse cenário assume que o mesmo conjunto de usuários em um local geográfico seja atendido por um pool de host específico.
- Ativo/ativo
Para cada pool de host na região primária, você implanta um segundo pool de host na região secundária.
Essa configuração fornece RTO quase zero, e o RPO tem um custo extra.
Você não precisa que um administrador intervenha ou faça failover. Durante as operações normais, o pool de host secundário fornece ao usuário recursos de Área de Trabalho Virtual.
Cada pool de host tem suas próprias contas de armazenamento (pelo menos uma) para perfis de usuário persistentes.
Você deve avaliar a latência com base na localização física do usuário e na conectividade disponível. Para algumas regiões do Azure, como a Europa Ocidental e a Europa do Norte, a diferença pode ser insignificante ao acessar as regiões primária ou secundária. Você pode validar esse cenário usando a ferramenta Avaliador de Experiência de Área de Trabalho Virtual do Azure.
Os usuários são atribuídos a diferentes grupos de aplicativos, como Grupo de Aplicativos da Área de Trabalho (DAG) e Grupo de Aplicativos RemoteApp (RAG), nos pools de host primário e secundário. Nesse caso, eles verão entradas duplicadas no seu feed de cliente de Área de Trabalho Virtual. Para evitar confusão, use espaços de trabalho de Área de Trabalho Virtual separados com nomes e rótulos claros que reflitam a finalidade de cada recurso. Informe seus usuários sobre o uso desses recursos.
Se você precisar de armazenamento para gerenciar o FSLogix Profile e os contêineres do ODFC separadamente, use o Cloud Cache para garantir RPO quase zero.
- Para evitar conflitos de perfil, não permita que os usuários acessem os dois pools de host ao mesmo tempo.
- Devido à natureza ativo-ativo desse cenário, você deve educar seus usuários sobre como usar esses recursos da maneira correta.
Observação
O uso de contêineres ODFC separados é um cenário avançado com maior complexidade. A implantação dessa maneira é recomendada apenas em alguns cenários específicos.
- Ativo/passivo
- Como ativo-ativo, para cada pool de host na região primária, você implanta um segundo pool de host na região secundária.
- A quantidade de recursos de computação ativos na região secundária é reduzida em comparação com a região primária, dependendo do orçamento disponível. Você pode usar o dimensionamento automático para fornecer mais capacidade de computação, mas isso requer mais tempo, e a capacidade do Azure não é garantida.
- Essa configuração fornece RTO mais alto quando comparada à abordagem ativo-ativo, mas é mais barata.
- Você precisará da intervenção do administrador para executar um procedimento de failover se houver uma interrupção do Azure. O pool de host secundário normalmente não fornece ao usuário acesso aos recursos da Área de Trabalho Virtual.
- Cada pool de host tem suas próprias contas de armazenamento para perfis de usuário persistentes.
- Os usuários que consomem serviços de Área de Trabalho Virtual com latência e desempenho ideais são afetados somente se houver uma interrupção do Azure. Você pode validar esse cenário usando a ferramenta Avaliador de Experiência de Área de Trabalho Virtual do Azure. O desempenho deve ser aceitável, mesmo que degradado, para o ambiente secundário de recuperação de desastres.
- Os usuários são atribuídos a apenas um conjunto de grupos de aplicativos, como aplicativos de Área de Trabalho e Remotos. Durante as operações normais, esses aplicativos estão no pool de host primário. Durante uma interrupção e após um failover, os usuários são atribuídos a Grupos de Aplicativos no pool de host secundário. Nenhuma entrada duplicada é mostrada no feed do cliente de Área de Trabalho Virtual do usuário, eles podem usar o mesmo espaço de trabalho e tudo é transparente para eles.
- Se você precisar de armazenamento para gerenciar o FSLogix Profile e os contêineres do Office, use o Cloud Cache para garantir RPO quase zero.
- Para evitar conflitos de perfil, não permita que os usuários acessem os dois pools de host ao mesmo tempo. Como esse cenário é ativo-passivo, os administradores podem impor esse comportamento no nível do grupo de aplicativos. Somente após um procedimento de failover, o usuário pode acessar cada grupo de aplicativos no pool de host secundário. O acesso é revogado no grupo de aplicativos do pool de host primário e reatribuído a um grupo de aplicativos no pool de host secundário.
- Execute um failover para todos os grupos de aplicativos. Caso contrário, quando usuários usam grupos de aplicativos diferentes em pools de host diferentes, podem haver conflitos de perfil, caso não sejam gerenciados com eficiência.
- É possível permitir que um subconjunto específico de usuários faça failover seletivamente para o pool de host secundário e forneça comportamento ativo-ativo limitado e capacidade de failover de teste. Também é possível fazer failover de grupos de aplicativos específicos, mas você deve instruir seus usuários a não usar recursos de pools de host diferentes ao mesmo tempo.
Para circunstâncias específicas, você pode criar um único pool de host com uma combinação de hosts de sessão localizados em regiões diferentes. A vantagem dessa solução é que, se você tiver um único pool de host, não será necessário duplicar definições e atribuições para aplicativos de área de trabalho e remotos. Infelizmente, a recuperação de desastre para pools de host compartilhados tem várias desvantagens:
- Para pools de host em pool, não é possível forçar um usuário a um host de sessão na mesma região.
- Um usuário pode experimentar maior latência e desempenho abaixo do ideal ao se conectar a um host de sessão em uma região remota.
- Se você precisar de armazenamento para perfis de usuário, precisará de uma configuração complexa para gerenciar atribuições para hosts de sessão nas regiões primária e secundária.
- Você pode usar o modo de drenagem para desabilitar temporariamente o acesso aos hosts de sessão localizados na região secundária. Mas esse método introduz mais complexidade, sobrecarga de gerenciamento e uso ineficiente de recursos.
- É possível manter hosts de sessão em um estado offline nas regiões secundárias, mas isso gera mais complexidade e sobrecarga de gerenciamento.
Recomendações e consideração
Geral
Para implantar uma configuração ativo-ativo ou ativo-passivo usando vários pools de host e um mecanismo de cache de nuvem FSLogix, você pode criar o pool de host dentro do mesmo espaço de trabalho ou de um espaço de trabalho diferente, dependendo do modelo. Essa abordagem exige que você mantenha o alinhamento e as atualizações, mantendo os pools de host sincronizados e no mesmo nível de configuração. Além de um novo pool de host para a região secundária de recuperação de desastres, você precisa:
- Criar novos grupos de aplicativos distintos e aplicativos relacionados para o novo pool de host.
- Para revogar atribuições de usuário ao pool de host primário e, em seguida, reatribuí-las manualmente ao novo pool de host durante o failover.
Analise as opções de continuidade de negócios e recuperação de desastres do FSLogix.
- Nenhuma recuperação de perfil é abordada neste documento.
- O cache de nuvem (ativo/passivo) está incluído neste documento, mas é implementado usando o mesmo pool de host.
- O cache de nuvem (ativo/ativo) é abordado na parte restante deste documento.
Há limites para recursos de Área de Trabalho Virtual que devem ser considerados no design de uma arquitetura de Área de Trabalho Virtual. Valide seu design com base nos limites de serviço da Área de Trabalho Virtual.
Para diagnóstico e monitoramento, use o mesmo espaço de trabalho do Log Analytics para o pool de host primário e secundário. Usando essa configuração, o Insights da Área de Trabalho Virtual do Azure oferece uma exibição unificada da implantação em ambas as regiões.
No entanto, o uso de um único destino de log pode causar problemas se toda a região primária não estiver disponível. A região secundária não poderá usar o workspace do Log Analytics na região indisponível. Se esta situação for inaceitável, poderão ser adotadas as seguintes soluções:
- Use um workspace do Log Analytics separado para cada região e aponte os componentes da Área de Trabalho Virtual para fazer logon no seu workspace local.
- Teste e examine os recursos de replicação e failover do workspace do Logs Analytics.
Computação
Para a implantação de pools de host nas regiões primárias e secundárias de recuperação de desastres, você deve distribuir sua frota de VMs de host de sessão por várias zonas de disponibilidade. Se as zonas de disponibilidade não estiverem disponíveis na região local, você poderá usar um conjunto de disponibilidade para tornar sua solução mais resiliente do que com uma implantação padrão.
A imagem dourada que você usa para a implantação do pool de host na região secundária de recuperação de desastres deve ser a mesma usada para a principal. Você deve armazenar imagens na Galeria de Computação do Azure e configurar várias réplicas de imagem nos locais primário e secundário. Cada réplica de imagem pode sustentar uma implantação paralela de um número máximo de VMs, e você pode exigir mais de uma com base no tamanho do lote de implantação desejado. Para obter mais informações, consulte Armazenar e compartilhar imagens em uma Galeria de Computação do Azure.
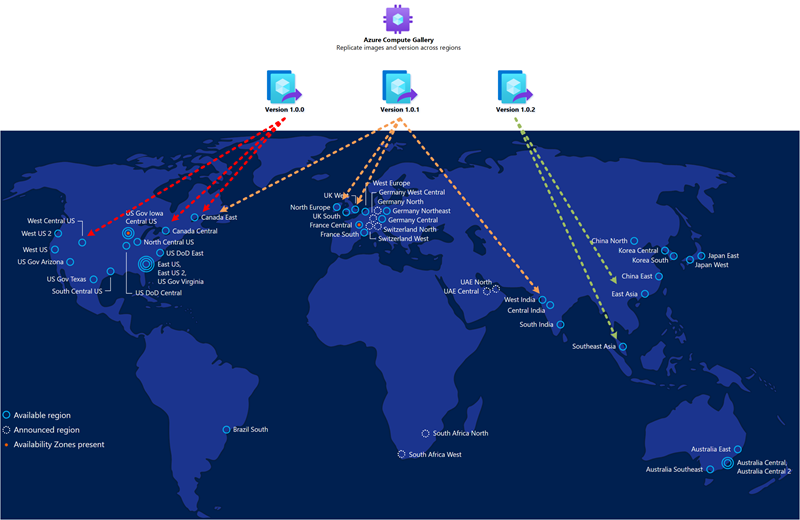
A Galeria de Computação do Azure não é um recurso global. Recomenda-se ter pelo menos uma galeria secundária na região secundária. Na sua região primária, crie uma galeria, uma definição de imagem de VM e uma versão de imagem de VM. Em seguida, crie os mesmos objetos também na região secundária. Ao criar a versão da imagem da VM, é possível copiar a versão da imagem da VM criada na região primária especificando a galeria e a definição e a versão da imagem da VM usada na região primária. O Azure copia a imagem e cria uma versão de imagem de VM local. É possível executar essa operação usando o portal do Azure ou o comando da CLI do Azure, conforme descrito abaixo:
Nem todas as VMs de host de sessão nos locais secundários de recuperação de desastres devem estar ativas e em execução o tempo todo. Inicialmente, você deve criar um número suficiente de VMs e, depois disso, usar um mecanismo de dimensionamento automático, como Planos de dimensionamento. Com esses mecanismos, é possível manter a maioria dos recursos de computação em um estado offline ou desatribuído para reduzir custos.
Também é possível usar a automação para criar hosts de sessão na região secundária somente quando necessário. Esse método otimiza os custos, mas, dependendo do mecanismo usado, pode exigir um RTO mais longo. Essa abordagem não permitirá testes de failover sem uma nova implantação e não permitirá failover seletivo para grupos específicos de usuários.

Observação
Você deve ativar cada VM do host de sessão por algumas horas, pelo menos uma vez a cada 90 dias, para atualizar o token de autenticação necessário para se conectar ao plano de controle da Área de Trabalho Virtual. Você também deve aplicar rotineiramente patches de segurança e atualizações de aplicativos.
- Ter hosts de sessão em um estado offline ou desatribuído na região secundária não garantirá que a capacidade esteja disponível se houver um desastre em uma região primária. Isso também se aplicará se novos hosts de sessão forem implantados sob demanda quando necessário e com o uso do Site Recovery. A capacidade computacional só poderá ser garantida se os recursos relacionados já estiverem alocados e ativos.
Importante
As Reservas do Azure não fornecem capacidade garantida na região.
Para cenários de uso do Cloud Cache, recomendamos usar a camada Premium para discos gerenciados.
Armazenamento
Neste guia, você usa pelo menos duas contas de armazenamento separadas para cada pool de host da Área de Trabalho Virtual. Um é para o contêiner FSLogix Profile e o outro, para os dados do contêiner do Office. Você também precisa de mais uma conta de armazenamento para pacotes MSIX. As seguintes considerações se aplicam:
- Você pode usar o compartilhamento de Arquivos do Azure e os Azure NetApp Files como alternativas de armazenamento. Para comparar as opções, consulte as opções de armazenamento de contêiner do FSLogix.
- O compartilhamento de Arquivos do Azure pode fornecer resiliência de zona usando a opção de armazenamento com redundância de zona (ZRS), se estiver disponível na região.
- Não é possível usar o recurso de armazenamento com redundância geográfica nas seguintes situações:
- Você precisa de uma região que não tenha um par. Os pares de regiões para armazenamento com redundância geográfica são fixos e não podem ser alterados.
- Você está usando a camada Premium.
- RPO e RTO são mais altos em comparação com o mecanismo FSLogix Cloud Cache.
- Não é fácil testar o failover e o failback em um ambiente de produção.
- Os Azure NetApp Files exigem considerações adicionais:
- A redundância de zona ainda não está disponível. Se o requisito de resiliência for mais importante do que o desempenho, use o compartilhamento de Arquivos do Azure.
- O Azure NetApp Files podem ser zonais, ou seja, os clientes podem decidir em qual Zona de Disponibilidade do Azure (única) alocar.
- A replicação entre zonas pode ser estabelecida no nível do volume para fornecer resiliência de zona, mas a replicação ocorre de forma assíncrona e requer failover manual. Esse processo requer um objetivo de ponto de recuperação (RPO) e um objetivo de tempo de recuperação (RTO) maiores que zero. Antes de usar esse recurso, examine os requisitos e as considerações para replicação entre zonas.
- Você poderá usar os Azure NetApp Files com gateways VPN e ExpressRoute com redundância de zona se o recurso de rede padrão for utilizado, aumentando a resiliência de rede. Para obter mais informações, confira topologias de rede compatíveis.
- A WAN Virtual do Azure tem suporte quando usada em conjunto com a rede padrão do Azure NetApp Files. Para obter mais informações, confira topologias de rede compatíveis.
- O Azure NetApp Files tem um mecanismo de replicação entre regiões. As seguintes considerações se aplicam:
- Ela não está disponível em todas as regiões.
- A replicação entre regiões de pares de regiões de volumes do Azure NetApp Files pode ser diferente dos pares de regiões de Armazenamento do Azure.
- Ela não pode ser usada ao mesmo tempo com a replicação entre zonas
- O failover não é transparente, e o failback requer reconfiguração de armazenamento.
- Limites
- Há limites no tamanho, operações de entrada/saída por segundo (IOPS), MBps de largura de banda para compartilhamento de Arquivos do Azure e contas e volumes de armazenamento de Azure NetApp Files. Se necessário, é possível usar mais de um para o mesmo pool de host na Área de Trabalho Virtual usando configurações por grupo no FSLogix. No entanto, essa configuração requer mais planejamento e configuração.
A conta de armazenamento usada para pacotes de aplicativos MSIX deve ser diferente das outras contas para contêineres do Profile e Office. As seguintes opções de recuperação de desastre geográfico estão disponíveis:
- Uma conta de armazenamento com armazenamento com redundância geográfica habilitada, na região primária
- A região secundária é fixa. Essa opção não será adequada para acesso local se houver failover da conta de armazenamento.
- Duas contas de armazenamento separadas, uma na região primária e outra na região secundária (recomendado)
- Use o armazenamento com redundância de zona para pelo menos a região primária.
- Cada pool de host em cada região tem acesso de armazenamento local a pacotes MSIX com baixa latência.
- Copie pacotes MSIX duas vezes em ambos os locais e registre os pacotes duas vezes em ambos os pools de host. Atribua usuários a grupos de aplicativos duas vezes.
FSLogix
A Microsoft recomenda que você use a seguinte configuração e recursos do FSLogix:
Se o conteúdo do contêiner do Profile precisar ter gerenciamento de BCDR separado e tiver requisitos diferentes em comparação com o contêiner do Office, você deverá dividi-los.
- O Contêiner do Office só tem conteúdo armazenado em cache que pode ser recriado ou repreenchido a partir da origem se houver um desastre. Com o Contêiner do Office, talvez você não precise manter backups, o que pode reduzir custos.
- Ao usar contas de armazenamento diferentes, você só pode habilitar backups no contêiner de perfil. Ou você deve ter configurações diferentes, como período de retenção, armazenamento usado, frequência e RTO/RPO.
O Cloud Cache é um componente FSLogix no qual você pode especificar vários locais de armazenamento de perfil e replicar dados de perfil de forma assíncrona, tudo sem depender de nenhum mecanismo de replicação de armazenamento subjacente. Se o primeiro local de armazenamento falhar ou não estiver acessível, o Cloud Cache fará failover automaticamente para usar o secundário e adicionará efetivamente uma camada de resiliência. Use o Cloud Cache para replicar contêineres do Profile e do Office entre contas de armazenamento diferentes nas regiões primária e secundária.
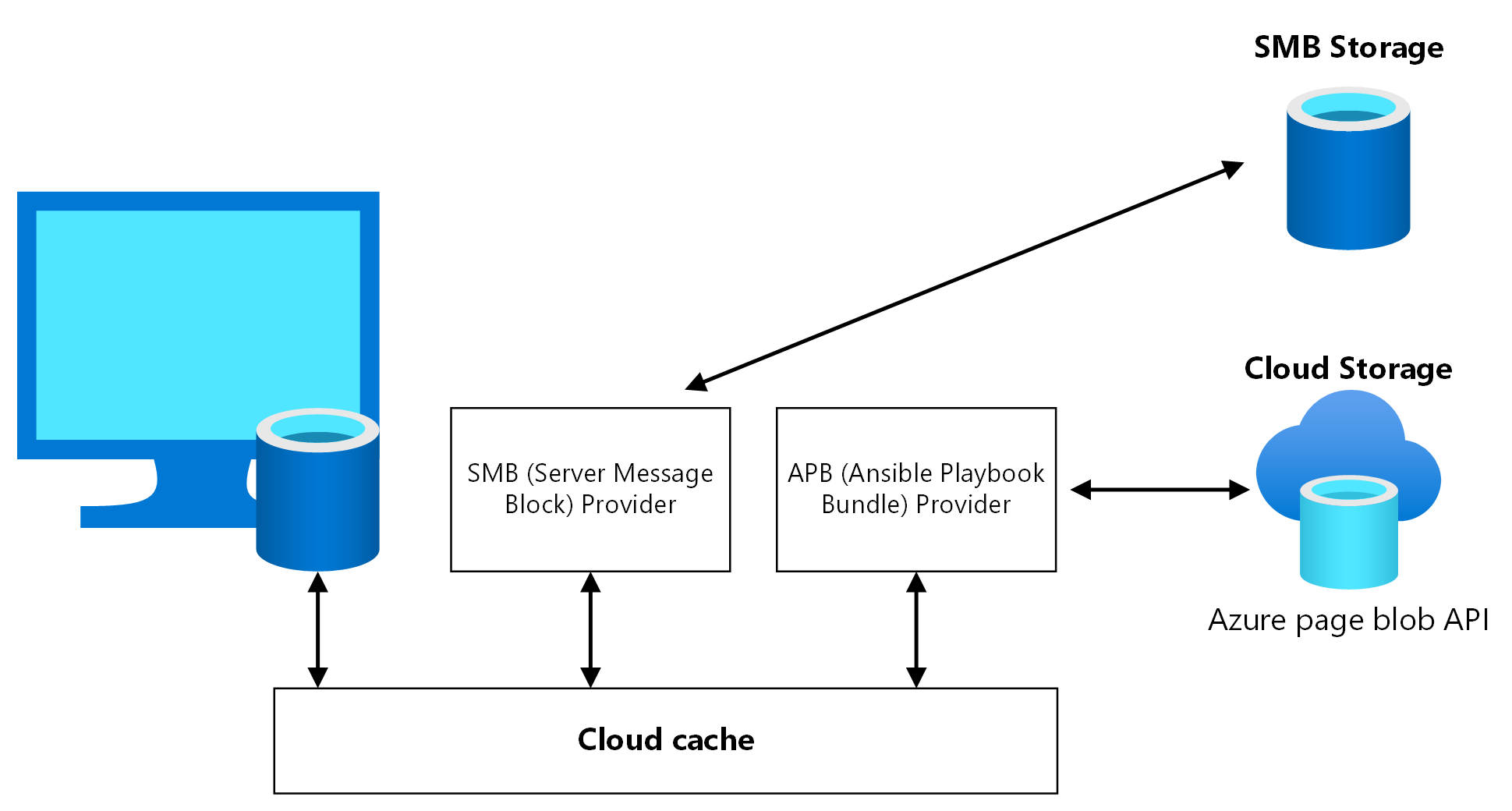
Você deve habilitar o Cloud Cache duas vezes no registro da VM do host da sessão, uma para o Contêiner do Profile e outra para o Contêiner do Office. É possível não habilitar o Cloud Cache para Contêiner do Office, mas isso pode causar um desalinhamento de dados entre a região de recuperação de desastres primária e secundária se houver failover e failback. Teste esse cenário cuidadosamente antes de usá-lo na produção.
O Cloud Cache é compatível com configurações de divisão de perfil e por grupo . Por grupo requer design e planejamento cuidadosos de grupos e associação do Active Directory. Você deve garantir que cada usuário faça parte exatamente de um grupo e que esse grupo seja usado para conceder acesso a pools de host.
O parâmetro CCDLocations especificado no registro para o pool de host na região secundária de recuperação de desastres é revertido em ordem, em comparação com as configurações na região primária. Para obter mais informações, consulte Tutorial: Configurar o Cloud Cache para redirecionar contêineres de perfil ou de escritório para vários provedores.
Dica
Este artigo se concentra em um cenário específico. Cenários adicionais são descritos em Opções de alta disponibilidade para FSLogix e Opções de continuidade de negócios e recuperação de desastre para FSLogix.

O exemplo a seguir mostra uma configuração do Cloud Cache e chaves do registro relacionadas:
Região primária = Norte da Europa
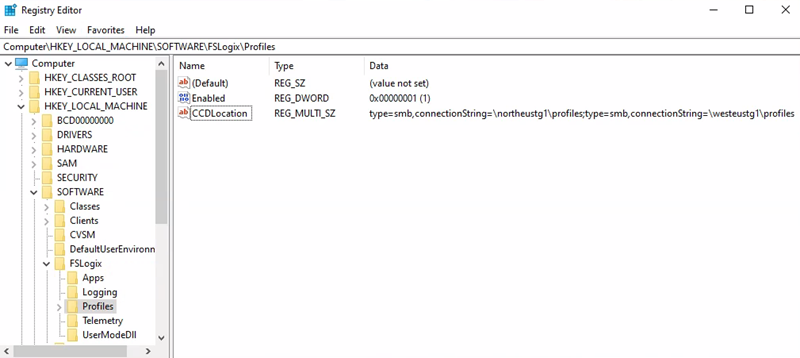
URI da conta de armazenamento de contêiner de perfil = \northeustg1\profiles
- Caminho da chave do registro = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- CCDLocations value = type=smb,connectionString=\northeustg1\profiles;type=smb,connectionString=\westeustg1\profiles
Observação
Se você baixou anteriormente os Modelos FSLogix, poderá realizar as mesmas configurações por meio do Console de Gerenciamento da Política de Grupo do Active Directory. Para obter mais detalhes sobre como configurar o Objeto de Política de Grupo para FSLogix, consulte o guia Usar Arquivos de Modelo de Política de Grupo do FSLogix.
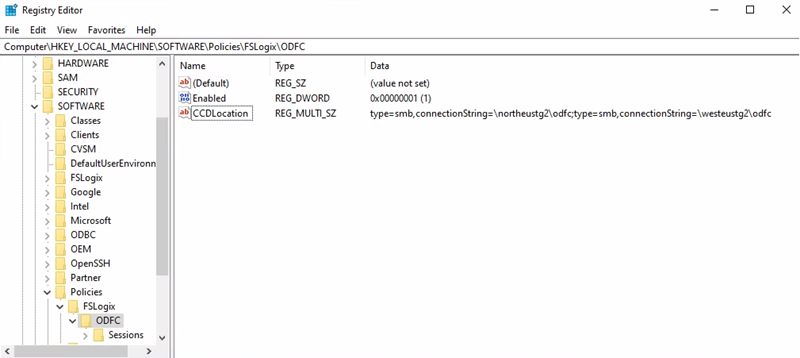
URI da conta de armazenamento de contêiner do Office = \northeustg2\odcf
Caminho da chave de registro = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
CCDLocations value = type=smb,connectionString=\northeustg2\odfc;type=smb,connectionString=\westeustg2\odfc


Observação
Nas capturas de tela acima, nem todas as chaves de registro recomendadas para FSLogix e Cloud Cache são relatadas, para fins de brevidade e simplicidade. Para obter mais informações, consulte Exemplos de configuração do FSLogix.
Região secundária = Europa Ocidental
- URI da conta de armazenamento de contêiner de perfil = \westeustg1\profiles
- Caminho da chave do registro = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- CCDLocations value = type=smb,connectionString=\westeustg1\profiles;type=smb,connectionString=\northeustg1\profiles
- URI da conta de armazenamento de contêiner do Office = \westeustg2\odcf
- Caminho da chave de registro = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
- CCDLocations value = type=smb,connectionString=\westeustg2\odfc;type=smb,connectionString=\northeustg2\odfc
Replicação do Cloud Cache
Os mecanismos de configuração e replicação do Cloud Cache garantem a replicação de dados de perfil entre diferentes regiões com perda mínima de dados. Como o mesmo arquivo de perfil de usuário pode ser aberto no modo ReadWrite por apenas um processo, o acesso simultâneo deve ser evitado, portanto, os usuários não devem abrir uma conexão com os dois pools de host ao mesmo tempo.

Baixe um Arquivo Visio dessa arquitetura.
Fluxo de dados
O usuário da Área de Trabalho Virtual inicia o cliente da Área de Trabalho Virtual e abre um Aplicativo Remoto ou de Área de Trabalho publicado atribuído ao pool de host da região primária.
O FSLogix recupera contêineres do Office e Profile do usuário e, em seguida, monta o VHD/X de armazenamento subjacente da conta de armazenamento localizada na região primária.
Ao mesmo tempo, o componente Cloud Cache inicializa a replicação entre os arquivos na região primária e os arquivos na região secundária. Para esse processo, o Cloud Cache na região primária adquire um bloqueio exclusivo de leitura-gravação nesses arquivos.
O mesmo usuário da Área de Trabalho Virtual agora deseja iniciar outro aplicativo publicado atribuído no pool de host da região secundária.
O componente do FSLogix em execução no host de sessão da Área de Trabalho Virtual na região secundária tenta montar os arquivos VHD/X do perfil de usuário da conta de armazenamento local. Mas a montagem falha, pois esses arquivos estão bloqueados pelo componente Cloud Cache em execução no host de sessão da Área de Trabalho Virtual na região primária.
Na configuração padrão do FSLogix e do Cloud Cache, o usuário não pode entrar e um erro é rastreado nos logs de diagnóstico do FSLogix, ERROR_LOCK_VIOLATION 33 (0x21).


Identidade
Uma das dependências mais importantes para a Área de Trabalho Virtual é a disponibilidade da identidade do usuário. Para acessar áreas de trabalho virtuais remotas completas e aplicativos remotos de seus hosts de sessão, os usuários precisam ser capazes de se autenticar. O Microsoft Entra ID é o serviço de identidade de nuvem centralizado da Microsoft que habilita essa capacidade. O Microsoft Entra ID é sempre usado para autenticar usuários para a Área de Trabalho Virtual. Os hosts da sessão podem ser ingressados no mesmo locatário do Microsoft Entra ou em um domínio do Active Directory usando o Active Directory Domain Services (AD DS) ou o Microsoft Entra Domain Services, fornecendo opções de configuração flexíveis.
Microsoft Entra ID
- É um serviço global multirregional e resiliente com alta disponibilidade. Nenhuma outra ação é necessária nesse contexto como parte de um plano de BCDR de Área de Trabalho Virtual.
Active Directory Domain Services
- Para que os Serviços de Domínio do Active Directory sejam resilientes e altamente disponíveis, mesmo que haja um desastre em toda a região, você deve implantar pelo menos dois controladores de domínio (DCs) na região primária do Azure. Esses controladores de domínio devem estar em zonas de disponibilidade diferentes, se possível, e você deve garantir a replicação adequada com a infraestrutura na região secundária e, eventualmente, no local. Crie pelo menos mais um controlador de domínio na região secundária com catálogo global e funções DNS. Para obter mais informações, consulte Implantar o Active Directory Domain Services (AD DS) em uma rede virtual do Azure.
Microsoft Entra Connect
Se você estiver usando o Microsoft Entra ID com os Serviços de Domínio do Active Directory e, em seguida, o Microsoft Entra Connect para sincronizar dados de identidade do usuário entre os Serviços de Domínio do Active Directory e o Microsoft Entra ID, considere a resiliência e a recuperação desse serviço para proteção contra um desastre permanente.
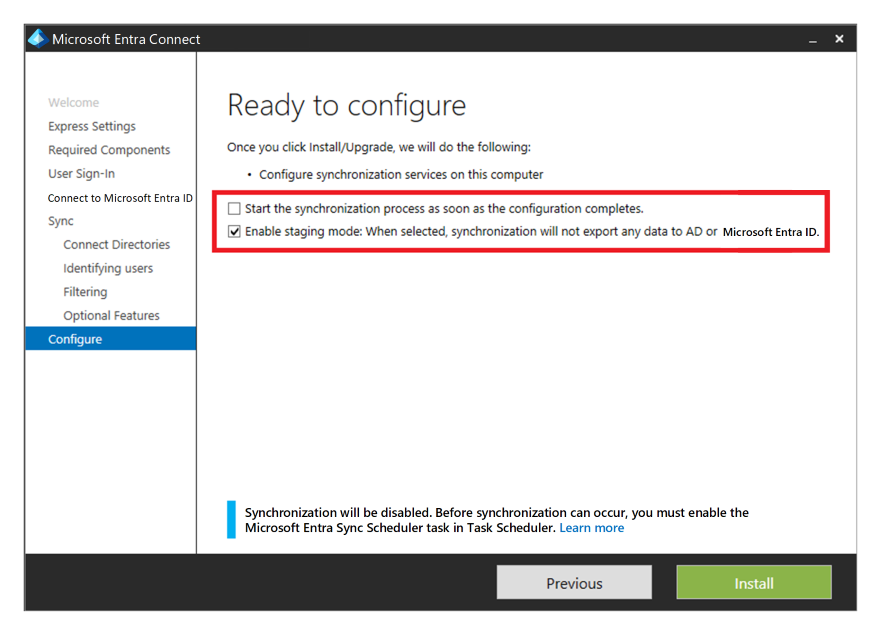
Você pode fornecer alta disponibilidade e recuperação de desastres instalando uma segunda instância do serviço na região secundária e habilitar o modo de preparo.
Se houver uma recuperação, o administrador deverá promover a instância secundária retirando-a do modo de preparo. Ele deve seguir o mesmo procedimento que colocar um servidor no modo de preparo. As credenciais de Administrador Global do Microsoft Entra são necessárias para executar essa configuração.
Serviços de Domínio do Microsoft Entra
- Você pode usar os Serviços de Domínio do Microsoft Entra em alguns cenários como uma alternativa aos Serviços de Domínio do Active Directory.
- Ele oferece alta disponibilidade.
- Se a recuperação de desastre geográfico estiver no escopo do seu cenário, você deverá implantar outra réplica na região secundária do Azure usando um conjunto de réplicas. Você também pode usar esse recurso para aumentar a alta disponibilidade na região primária.
Diagramas de arquitetura
Pool de host pessoal

Baixe um Arquivo Visio dessa arquitetura.
Pool de host em pool

Baixe um Arquivo Visio dessa arquitetura.
Failover e failback
Cenário de pool de host pessoal
Observação
Somente o modelo ativo-passivo é abordado nesta seção — um ativo-ativo não requer nenhum failover ou intervenção do administrador.
O failover e o failback para um pool de host pessoal são diferentes, pois não há Cloud Cache e armazenamento externo usados para contêineres do Profile e Office. Você ainda pode usar a tecnologia FSLogix para salvar os dados em um contêiner do host da sessão. Não há pool de host secundário na região de recuperação de desastres, portanto, não há necessidade de criar mais espaços de trabalho e recursos de Área de Trabalho Virtual para replicar e alinhar. Você pode usar o Site Recovery para replicar VMs de host de sessão.
Você pode usar a Recuperação de Site em vários cenários diferentes. Para Área de Trabalho Virtual, use a arquitetura de recuperação de desastres do Azure para Azure no Azure Site Recovery.
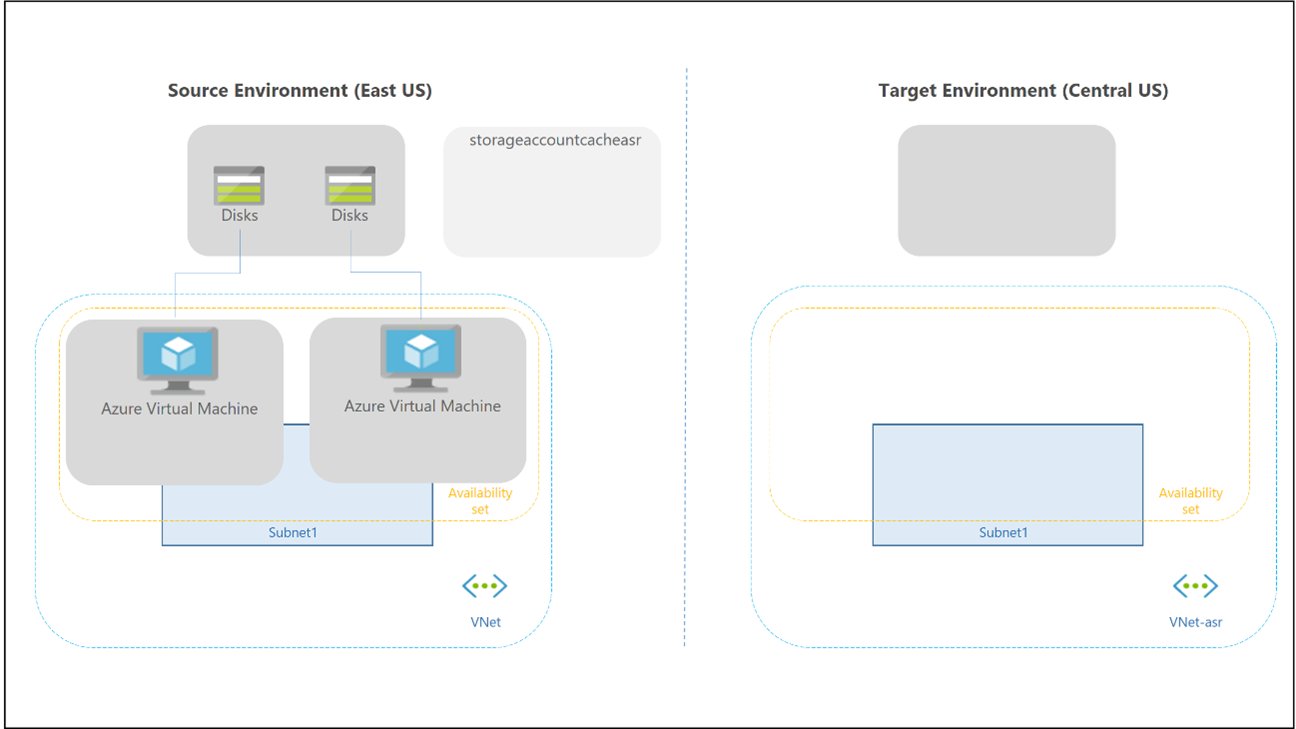
Aplicam-se as seguintes considerações e recomendações:
- O failover do Site Recovery não é automático – um administrador deve acioná-lo usando o portal do Azure ou o Powershell/API.
- Você pode criar scripts e automatizar toda a configuração e as operações do Site Recovery usando o PowerShell.
- O Site Recovery tem um RTO declarado no acordo de nível de serviço (SLA). Na maioria das vezes, o Site Recovery faz failover de VMs em minutos.
- Você pode usar o Site Recovery com o Backup do Azure. Para obter mais informações, consulte Suporte para usar o Site Recovery com o Backup do Azure.
- Você deve habilitar o Site Recovery no nível da VM, pois não há integração direta na experiência do portal da Área de Trabalho Virtual. Você também deve disparar o failover e o failback no nível de VM única.
- O Site Recovery fornece capacidade de failover de teste em uma sub-rede separada para VMs gerais do Azure. Não use esse recurso para VMs de Área de Trabalho Virtual, pois você teria dois hosts de sessão de Área de Trabalho Virtual idênticos chamando o plano de controle de serviço ao mesmo tempo.
- O Site Recovery não mantém extensões de máquina virtual durante a replicação. Se você habilitar quaisquer extensões personalizadas para VMs de host de sessão da Área de Trabalho Virtual, deverá reabilitá-las após o failover ou failback. As extensões internas da Área de Trabalho Virtual joindomain e Microsoft.PowerShell.DSC são usadas somente quando uma VM de host de sessão é criada. É comum perdê-las após um primeiro failover.
- Revise a matriz de suporte para recuperação de desastres de VM do Azure entre regiões do Azure e verifique os requisitos, limitações e a matriz de compatibilidade para o cenário de recuperação de desastres do Azure para Azure do Site Recovery, especialmente as versões do SO com suporte.
- Ao fazer failover das VMs de uma região para outra, as VMs iniciam na região de recuperação de desastre destino em um estado desprotegido. O failback é possível, mas o usuário deve proteger novamente as VMs na região secundária e, em seguida, habilitar a replicação de volta para a região primária.
- Execute testes periódicos de procedimentos de failover e failback. Em seguida, documente uma lista exata de etapas e ações de recuperação com base no seu ambiente de Área de Trabalho Virtual específico.
Cenário de pool de host em pool
Uma das características desejadas de um modelo de recuperação de desastres ativo-ativo é que a intervenção do administrador não é necessária para recuperar o serviço se houver uma interrupção. Os procedimentos de failover só devem ser necessários em uma arquitetura ativa-passiva.
Em um modelo ativo-passivo, a região secundária de recuperação de desastres deve estar ociosa, com o mínimo de recursos configurados e ativos. A configuração deve ser mantida alinhada com a região primária. Se houver um failover, as reatribuições de todos os usuários para todos os grupos de área de trabalho e aplicativos para aplicativos remotos no pool de host de recuperação de desastres secundário acontecerão ao mesmo tempo.
É possível ter um modelo ativo-ativo e failover parcial. Se o pool de host for usado apenas para fornecer grupos de área de trabalho e aplicativos, você poderá particionar os usuários em vários grupos do Active Directory não sobrepostos e reatribuir o grupo a grupos de área de trabalho e aplicativos nos pools de host de recuperação de desastres primário ou secundário. Um usuário não deve ter acesso aos dois pools de host ao mesmo tempo. Se houver vários grupos de aplicativos e aplicativos, os grupos de usuários que você utiliza para atribuir usuários podem se sobrepor. Nesse caso, é difícil implementar uma estratégia ativo-ativo. Sempre que um usuário inicia um aplicativo remoto no pool de host primário, o perfil de usuário é carregado pelo FSLogix em uma VM de host de sessão. Tentar fazer o mesmo no pool de host secundário pode causar um conflito no disco de perfil subjacente.
Aviso
Por padrão, as configurações de registro FSLogix proíbem o acesso simultâneo ao mesmo perfil de usuário a partir de várias sessões. Nesse cenário de BCDR, você não deve alterar esse comportamento e manter um valor de 0 para a chave do registro ProfileType.
Confira as hipóteses iniciais de situação e configuração:
- Os pools de host na região primária e nas regiões secundárias de recuperação de desastres são alinhados durante a configuração, incluindo o Cloud Cache.
- Nos pools de host, os grupos de aplicativos de área de trabalho DAG1 e remotos APPG2 e APPG3 são oferecidos aos usuários.
- No pool de host na região primária, os grupos de usuários do Active Directory GRP1, GRP2 e GRP3 são usados para atribuir usuários ao DAG1, APPG2 e APPG3. Esses grupos podem ter associações de usuário sobrepostas, mas, como o modelo aqui usa ativo-passivo com failover completo, isso não é um problema.
As etapas a seguir descrevem quando um failover acontece, após uma recuperação de desastre planejada ou não planejada.
- No pool de host primário, remova as atribuições de usuário dos grupos GRP1, GRP2 e GRP3 para os grupos de aplicativos DAG1, APPG2 e APPG3.
- Há uma desconexão forçada para todos os usuários conectados do pool de host primário.
- No pool de host secundário, onde os mesmos grupos de aplicativos são configurados, você deve conceder ao usuário acesso ao DAG1, APPG2 e APPG3 usando os grupos GRP1, GRP2 e GRP3.
- Revise e ajuste a capacidade do pool de host na região secundária. Aqui, convém confiar em um plano de escala automática para ligar automaticamente os hosts de sessão. Você também pode iniciar manualmente os recursos necessários.
As etapas e o fluxo de failback são semelhantes, e você pode executar todo o processo várias vezes. O Cloud Cache e a configuração das contas de armazenamento garantem que os dados de contêiner do Profile e do Office sejam replicados. Antes do failback, verifique se a configuração do pool de host e os recursos de computação serão recuperados. Para a parte de armazenamento, se houver perda de dados na região primária, o Cloud Cache replicará os dados de contêiner do Perfil e Office do armazenamento da região secundária.
Também é possível implementar um plano de failover de teste com algumas alterações de configuração, sem afetar o ambiente de produção.
- Crie algumas novas contas de usuário no Active Directory para produção.
- Crie um novo grupo do Active Directory chamado GRP-TEST e atribua usuários.
- Atribua acesso a DAG1, APPG2 e APPG3 usando o grupo GRP-TEST.
- Dê instruções aos usuários do grupo GRP-TEST para testar aplicativos.
- Teste o procedimento de failover usando o grupo GRP-TEST para remover o acesso do pool de host primário e conceder acesso ao pool de recuperação de desastres secundário.
Recomendações importantes:
- Automatize o processo de failover usando o PowerShell, a CLI do Azure ou outra API ou ferramenta disponível.
- Teste periodicamente todo o procedimento de failover e failback.
- Realize uma verificação regular de alinhamento de configuração para garantir que os pools de host na região de desastre primária e secundária estejam sincronizados.
Backup
Uma suposição neste guia é que há divisão de perfil e separação de dados entre contêineres de Profile e do Office. O FSLogix permite essa configuração e o uso de contas de armazenamento separadas. Uma vez em contas de armazenamento separadas, você pode usar políticas de backup diferentes.
Para o Contêiner do ODFC, se o conteúdo representar apenas dados armazenados em cache que podem ser recriados a partir do armazenamento de dados online, como o Microsoft 365, não será necessário fazer backup dos dados.
Se for necessário fazer backup dos dados do contêiner do Office, você poderá usar um armazenamento mais barato ou uma frequência de backup e um período de retenção diferentes.
Para um tipo de pool de host pessoal, você deve executar o backup no nível da VM do host da sessão. Esse método só se aplicará se os dados forem armazenados localmente.
Se você usar o OneDrive e o redirecionamento de pasta conhecida, o requisito para salvar dados dentro do contêiner poderá desaparecer.
Observação
O backup do OneDrive não é considerado neste artigo e cenário.
A menos que haja outro requisito, o backup para o armazenamento na região primária deve ser suficiente. O backup do ambiente de recuperação de desastres normalmente não é usado.
Para compartilhamento de Arquivos do Azure, use o Backup do Azure.
- Para o tipo de resiliência do vault, use o armazenamento com redundância de zona se o armazenamento de backup externo ou de região não for necessário. Se esses backups forem necessários, use armazenamento com redundância geográfica.
O Azure NetApp Files fornece sua própria solução de backup incorporada.
- Certifique-se de verificar a disponibilidade de recurso da região, juntamente com os requisitos e limitações.
As contas de armazenamento separadas usadas para o MSIX também devem ser cobertas por um backup se os repositórios de pacotes de aplicativos não puderem ser facilmente reconstruídos.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Principais autores:
- Ben Martin Baur | Arquiteto de Soluções de Nuvem
- Igor Pagliai | Engenheiro-chefe do FastTrack for Azure (FTA)
Outros colaboradores:
- Nelson Del Villar | Arquiteto de Soluções na Nuvem, Infraestrutura Principal do Azure
- Jason Martinez | Redator técnico
Próximas etapas
- Plano de recuperação de desastre da Área de Trabalho Virtual
- BCDR para Área de Trabalho Virtual – Cloud Adoption Framework
- Cloud Cache para criar resiliência e disponibilidade