Tutorial: configurar a replicação geográfica ativa e o failover (Banco de Dados SQL do Azure)
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Este artigo mostra como configurar a replicação geográfica ativa para o Banco de Dados SQL do Azure usando o portal do Azure, o PowerShell ou a CLI do Azure e como inicializar o failover.
A replicação geográfica ativa é configurada por banco de dados. Para fazer failover de um grupo de bancos de dados ou se seu aplicativo exigir um ponto de extremidade de conexão estável, considere grupos de failover.
Pré-requisitos
Para concluir este tutorial, é necessário um único Banco de Dados SQL do Azure. Para saber como criar um banco de dados individual com portal do Azure, CLI do Azure ou PowerShell, consulte Início Rápido: criar um banco de dados individual – banco de dados SQL do Azure.
Você pode usar o portal do Azure para configurar a replicação geográfica ativa entre assinaturas, desde que ambas as assinaturas estejam no mesmo locatário do Microsoft Entra ID.
- Para criar uma réplica secundária geográfica em uma assinatura diferente da assinatura do primário em um locatário diferente do Microsoft Entra ID, use o tutorial sobre secundário geográfico entre assinaturas e T-SQL do locatário do Microsoft Entra ID.
- O suporte para operações de replicação geográfica entre assinaturas, incluindo configuração e failover geográfico, também têm suporte usando Databases Create ou Update API REST.
Adicionar um banco de dados secundário
As etapas a seguir criam um novo banco de dados secundário em uma parceria de replicação geográfica.
Para adicionar um banco de dados secundário, você deve ser o proprietário ou coproprietário da assinatura.
O banco de dados secundário tem o mesmo nome do banco de dados primário e, por padrão, tem a mesma camada de serviço e tamanho da computação. O banco de dados secundário pode ser um banco de dados individual ou um banco de dados em pool. Para obter mais informações, consulte Modelo de compra baseado em DTU e Modelo de compra baseado em vCore. Depois que o banco de dados secundário for criado e propagado, os dados começarão a serem replicados desde o banco de dados primário até o novo banco de dados secundário.
Se sua réplica secundária for usada apenas para DR (recuperação de desastre) e não tiver cargas de trabalho de leitura ou gravação, você poderá economizar nos custos de licenciamento designando o banco de dados para espera ao configurar uma nova relação de replicação geográfica ativa. Para obter mais informações, consulte réplica em espera sem licença.
Observação
O comando falhará se o banco de dados do parceiro já existir (por exemplo, como resultado do término de uma relação de replicação geográfica anterior).
No portal do Azure, navegue até o banco de dados que você deseja configurar para a replicação geográfica.
Na página do Banco de Dados SQL, selecione o banco de dados, role até Gerenciamento de dados, selecione Réplicas e Criar réplica.
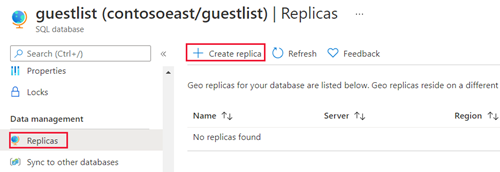
Selecione a Assinatura e o Grupo de recursos do banco de dados secundário geográfico.

Selecione ou crie o servidor para o banco de dados secundário e configure as opções de Computação + armazenamento, se necessário. Você pode selecionar qualquer região para o servidor secundário, mas recomendamos a região emparelhada.
Opcionalmente, você pode adicionar um banco de dados secundário a um pool elástico. Para criar o banco de dados secundário em um pool, clique em Sim ao lado de Quer usar um pool elástico do SQL? e selecione um pool no servidor de destino. Um pool já deve existir no servidor de destino. Esse fluxo de trabalho não cria um pool.
Selecione Examinar + criar, examine as informações e selecione Criar.
O banco de dados secundário é criado e o processo de implantação é iniciado.
Quando o processo de implantação for concluído, o banco de dados secundário exibirá seu status.
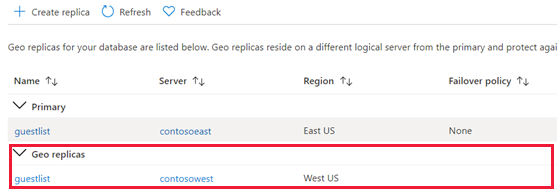
Volte para a página banco de dados primário e, em seguida, selecione Réplicas. Seu banco de dados secundário está listado em Réplicas geográficas.


Iniciar um failover
O banco de dados secundário pode ser alternado para se tornar primário.
No portal do Azure, navegue até o banco de dados primário na parceria de replicação geográfica.
Role até Gerenciamento de dados e selecione Réplicas.
Na lista Réplicas geográficas, selecione o banco de dados que você deseja tornar o novo primário, selecione as reticências e, em seguida, clique em Failover forçado.

Clique em Sim para iniciar o failover.

O comando mudará imediatamente o banco de dados secundário para a função primária. Normalmente, esse processo deverá ser concluído em 30 segundos ou menos.
Há um breve período durante o qual ambos os bancos de dados não estão disponíveis (na ordem de 0 a 25 segundos) enquanto as funções são alternadas. Se o banco de dados primário tiver vários bancos de dados secundários, o comando reconfigurará automaticamente os outros secundários para se conectarem ao novo primário. A operação inteira deve levar menos de um minuto para ser concluída em circunstâncias normais.
Remover um banco de dados secundário
Essa operação termina permanentemente a replicação para o banco de dados secundário e altera a função do secundário para um banco de dados de leitura/gravação normal. Se a conectividade com o banco de dados secundário for desfeita, o comando terá êxito, mas o banco de dados só se tornará de leitura/gravação quando a conectividade for restaurada.
- No portal do Azure, navegue até o banco de dados primário na parceria de replicação geográfica.
- Selecione Réplicas.
- Na lista Réplicas geográficas, selecione o banco de dados que você deseja remover da parceria de replicação geográfica, clique nas reticências e, em seguida, selecione Parar replicação.
- Uma janela de confirmação é aberta. Selecione Sim para remover o banco de dados da parceria de replicação geográfica. (Defina-o como um banco de dados de leitura/gravação que não faz parte de nenhuma replicação.)
Replicação geográfica entre assinaturas
- Para criar uma réplica secundária geográfica em uma assinatura diferente da primária no mesmo locatário no Microsoft Entra, use o portal do Azure ou siga as etapas nesta seção.
- Para criar uma réplica secundária geográfica em uma assinatura diferente da primária em um locatário diferente do Microsoft Entra, use a autenticação de SQL e o T-SQL conforme descrito nas etapas desta secção. Não há suporte à autenticação do Microsoft Entra para replicação geográfica entre assinaturas quando um servidor lógico está em um outro Locatário do Azure
Adicione o endereço IP do computador cliente que executa os comandos T-SQL neste exemplo, para os firewalls de servidor de ambos os servidores, tanto o primário quanto o secundário. É possível confirmar esse endereço IP executando a consulta a seguir quando conectado ao servidor primário do mesmo computador cliente.
select client_net_address from sys.dm_exec_connections where session_id = @@SPID;Para obter mais informações, consulte Banco de dados SQL do Microsoft Azure e regras de firewall IP de sinapse do Azure.
No banco de dados
masterno servidor primário, crie um logon de autenticação SQL dedicado à configuração de replicação geográfica ativa. Ajuste o nome de logon e a senha conforme necessário.create login geodrsetup with password = 'ComplexPassword01';No mesmo banco de dados, crie um usuário para o logon e adicione-o à função
dbmanager:create user geodrsetup for login geodrsetup; alter role dbmanager add member geodrsetup;Anote o valor de SID do novo logon. Para obter o valor de SID, use a consulta a seguir.
select sid from sys.sql_logins where name = 'geodrsetup';Conecte-se ao banco de dados primário (não ao
master) e crie um usuário para o mesmo logon.create user geodrsetup for login geodrsetup;No mesmo banco de dados, adicione o usuário à função
db_owner.alter role db_owner add member geodrsetup;No banco de dados
masterdo servidor secundário, crie o mesmo logon do servidor primário, usando o mesmo nome, a mesma senha e o mesmo SID. Substitua o valor de SID hexadecimal no comando de exemplo abaixo pelo obtido na Etapa 4.create login geodrsetup with password = 'ComplexPassword01', sid=0x010600000000006400000000000000001C98F52B95D9C84BBBA8578FACE37C3E;No mesmo banco de dados, crie um usuário para o logon e adicione-o à função
dbmanager.create user geodrsetup for login geodrsetup; alter role dbmanager add member geodrsetup;Conecte-se ao banco de dados
masterno servidor primário usando o novo logongeodrsetupe inicie a criação do secundário geográfico no servidor secundário. Ajuste o nome do banco de dados e o nome do servidor secundário conforme necessário. Depois da execução do comando, você pode monitorar a criação do secundário geográfico consultando a exibição sys.dm_geo_replication_link_status no banco de dados primário e a exibição sys.dm_operation_status no banco de dadosmasterdo servidor primário. O tempo necessário para criar um secundário geográfico depende do tamanho do banco de dados primário.alter database [dbrep] add secondary on server [servername];Depois da criação do secundário geográfico, os usuários, os logons e as regras de firewall criados por esse procedimento podem ser removidos.
Próximas etapas
- Replicação geográfica ativa.
- Grupos de failover
- Visão geral da continuidade dos negócios.
- Economize nos custos de licenciamento designando sua réplica secundária como Em espera.