Replicação geográfica ativa
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Este artigo fornece uma visão geral do recurso de replicação geográfica ativa para o Banco de Dados SQL do Azure, que permite replicar continuamente dados de um banco de dados primário para um banco de dados secundário legível. O banco de dados secundário para leitura pode estar na mesma região do Azure que o primário ou, mais comum, em uma diferente. Esse tipo de banco de dados da réplica secundária para leitura também é conhecido como réplica secundária geográfica ou réplica geográfica.
A replicação geográfica ativa é configurada por banco de dados. Para fazer failover de um grupo de bancos de dados ou se seu aplicativo exigir um ponto de extremidade de conexão estável, considere grupos de failover.
Você também pode Migrar um banco de Dados SQL com replicação geográfica ativa.
Visão geral
A replicação geográfica ativa foi projetada como uma solução de continuidade dos negócios. A replicação geográfica ativa executar uma recuperação de desastres rápida de bancos de dados individuais se houver um desastre regional ou de uma interrupção em grande escala. Depois de configurar a replicação geográfica, é possível iniciar um failover geográfico para um secundário geográfico em uma região diferente do Azure. O failover geográfico é iniciado programaticamente pelo aplicativo ou manualmente pelo usuário.
O diagrama a seguir ilustra uma configuração típica de um aplicativo de nuvem com redundância geográfica usando a replicação geográfica ativa.
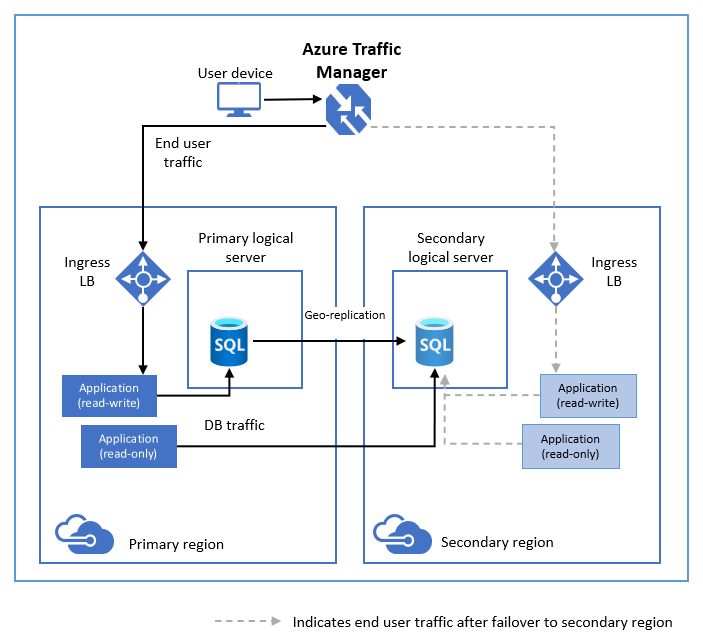
Se, por qualquer motivo, o banco de dados primário falhar, você poderá iniciar um failover geográfico para qualquer um dos seus bancos de dados secundários. Quando um secundário é promovido para a função primária, todos os outros secundários são automaticamente vinculados a ele.
É possível gerenciar a replicação geográfica e iniciar um failover geográfico usando qualquer um dos seguintes métodos:
- O Portal do Azure
- PowerShell: banco de dados único
- PowerShell: pool elástico
- Transact-SQL: banco de dados único ou pool elástico
- API REST: banco de dados único
A replicação geográfica ativa usa a tecnologia de grupo de disponibilidade Always On para replicar de forma assíncrona o log de transações gerado na réplica primária para todas as réplicas geográficas. Embora um banco de dados secundário possa estar em algum momento um pouco desatualizado com relação ao primário, os dados nele têm a garantia de nunca terem transações parciais. Em outras palavras, as alterações feitas por transações não confirmadas não são visíveis.
Observação
A replicação geográfica ativa replica as alterações transmitindo o log de transações do banco de dados da réplica primária para as secundárias. Ela não está relacionada à replicação transacional, que replica as alterações executando comandos DML (INSERT, UPDATE e DELETE) nos assinantes.
A replicação geográfica fornece redundância regional. A redundância regional permite que os aplicativos se recuperem rapidamente da perda permanente de uma região inteira ou de partes dela, causada por desastres naturais, falhas humanas catastróficas ou crimes. O RPO da replicação geográfica pode ser encontrado em Visão geral da Continuidade dos negócios do Banco de Dados SQL do Azure.
A figura a seguir mostra um exemplo de replicação geográfica ativa configurada com um banco de dados primário na região Oeste dos EUA 2 e um secundário na região Leste dos EUA.

Além da recuperação de desastres, a replicação geográfica ativa pode ser usada nos seguintes cenários:
- Migração de banco de dados: é possível usar a replicação geográfica ativa para migrar um banco de dados de um servidor para outro com tempo de inatividade mínimo.
- Atualizações de aplicativos: você pode criar um secundário extra como uma cópia de failback durante as atualizações de aplicativos.
Adicionar a redundância regional do banco de dados é apenas uma parte da solução para obter uma continuidade de negócios completa. A recuperação de um aplicativo (serviço) de ponta a ponta após uma falha catastrófica exige a recuperação de todos os componentes que constituem o serviço e quaisquer serviços dependentes. O software cliente (por exemplo, um navegador com um JavaScript personalizado), front-ends da Web, armazenamento e DNS são exemplos desses componentes. É fundamental que todos os componentes sejam resilientes às mesmas falhas e fiquem disponíveis dentro do RTO (objetivo de tempo de recuperação) de seu aplicativo. Portanto, você precisa identificar todos os serviços dependentes e entender as garantias e os recursos que eles fornecem. Em seguida, você deve tomar as medidas necessárias para garantir que seu serviço funcione durante o failover dos serviços dos quais ele depende. Para obter mais informações sobre como criar soluções para recuperação de desastre, confira Como criar serviços globalmente disponíveis usando o Banco de Dados SQL do Azure.
Terminologia e recursos
Replicação assíncrona automática
Você só pode criar um secundário geográfico para um banco de dados existente. O secundário geográfico pode ser criado em qualquer servidor lógico diferente daquele com o banco de dados primário. Depois de criada, a réplica geográfica secundária é preenchida com os dados do banco de dados primário. Este processo é conhecido como propagação. Depois de criar e propagar a réplica geográfica secundária, as atualizações no banco de dados primário serão replicadas nela automaticamente e de maneira assíncrona. A replicação assíncrona significa que as transações são confirmadas no banco de dados primário antes de serem replicadas.
Réplicas geográficas secundárias legíveis
Um aplicativo pode acessar uma réplica geográfica secundária para executar operações somente leitura usando as mesmas entidades de segurança usadas para acessar o banco de dados primário ou entidades diferentes. Para obter detalhes, confira Usar réplicas somente leitura para descarregar cargas de trabalho de consulta somente leitura.
Importante
É possível usar a replicação geográfica para criar réplicas secundárias na mesma região do banco de dados primário. Você pode usar esses secundários para atender aos cenários de expansão de leitura na mesma região. No entanto, uma réplica secundária na mesma região não fornece resiliência adicional a falhas catastróficas ou interrupções de grande escala e, portanto, não é um destino de failover adequado para fins de recuperação de desastres. Ele também não garantirá o isolamento da zona de disponibilidade. Use a configuração de redundância de zona da camada de serviço Comercialmente Crítico ou Premium ou a configuração de redundância de zona da camada de serviço Uso Geral para obter o isolamento de zona de disponibilidade.
Failover (sem perda de dados)
O failover alterna as funções dos bancos de dados geográficos primário e secundário após a conclusão da sincronização de dados completa para que não haja perda de dados. A duração do failover depende do tamanho do log de transações no primário que precisa ser sincronizado com o secundário geográfico. O failover foi projetado para os seguintes cenários:
- Executar testes de recuperação de desastre na produção quando a perda de dados não é aceitável
- Relocar o banco de dados para uma região diferente
- Retornar o banco de dados para a região primária após a redução da interrupção (failback).
Failover forçado (potencial perda de dados)
Um failover forçado alternará imediatamente o secundário geográfico para a função primária, sem esperar pela sincronização com o primário. Todas as transações confirmadas no primário, mas não replicadas no secundário, serão perdidas. Essa operação foi projetada como um método de recuperação durante interrupções quando o primário não está acessível, mas a disponibilidade precisa ser restaurada rapidamente. Quando o primário original estiver online novamente, ele será reconectado automaticamente, propagado novamente com os dados atuais do primário e se tornará um novo secundário geográfico.
Importante
Após o failover ou failover planejado, o ponto de extremidade de conexão para o novo primário é alterado porque o novo primário agora está em um servidor lógico diferente.
Vários secundários geográficos legíveis
Até quatro secundários geográficos podem ser criados para um primário. Se houver apenas um secundário e ele falhar, o aplicativo será exposto a um risco maior até que um novo secundário seja criado. Se houver vários secundários, o aplicativo permanecerá protegido mesmo em caso de falha em um dos secundários. Secundários adicionais também podem ser usados para escalar horizontalmente as cargas de trabalho somente leitura.
Dica
Ao usar a replicação geográfica ativa para compilar um aplicativo distribuído globalmente, se for necessário fornecer acesso somente leitura aos dados em mais de quatro regiões, você poderá criar um secundário de outro secundário (um processo conhecido como encadeamento), a fim de criar réplicas geográficas adicionais. O retardo de replicação em réplicas geográficas encadeadas pode ser maior do que em réplicas geográficas conectadas diretamente ao primário. A configuração de topologias de replicação geográfica encadeada só tem suporte por meio de programação e não do portal do Azure.
Replicação geográfica de bancos de dados em um pool elástico
Cada secundário geográfico pode ser um banco de dados individual ou um banco de dados em um pool elástico. A escolha do pool elástico para cada banco de dados geográfico secundário é distinta e não depende da configuração de qualquer outra réplica na topologia (primária ou secundária). Cada pool elástico está contido em um único servidor lógico. Como os nomes de banco de dados em um servidor lógico devem ser exclusivos, vários secundários geográficos do mesmo primário nunca podem compartilhar um pool elástico.
Failover e failback geográficos e controlados pelo usuário
Um secundário geográfico que concluiu a propagação inicial pode ser alternado explicitamente para a função primária (failover) a qualquer momento pelo aplicativo ou pelo usuário. Durante uma interrupção em que o primário está inacessível, somente o failover forçado pode ser usado, o que promove imediatamente um secundário geográfico para ser o novo primário. Quando a interrupção é reduzida, o sistema transforma o primário recuperado automaticamente em um secundário geográfico e o vincula atualizado ao novo primário. Devido à natureza assíncrona da duplicação geográfica, as transações recentes podem ser perdidas durante failovers forçados caso o primário falhe antes dessas transações serem replicadas em um secundário geográfico. Quando um primário com vários secundários geográficos passa por failover, o sistema reconfigura automaticamente as relações de replicação e vincula os secundários geográficos restantes ao primário recém-promovido, sem a necessidade de intervenção do usuário. Depois que a interrupção que causou o failover geográfico é reduzida, recomenda-se retornar o primário para a região original. Para fazer isso, execute um failover manual.
Réplica em espera
Se sua réplica secundária for usada apenas para recuperação de desastres (DR) e não tiver cargas de trabalho de leitura ou gravação, você poderá designar a réplica como em espera para economizar nos custos de licenciamento.
Preparar-se para o failover geográfico
Para garantir que o aplicativo consiga acessar imediatamente o novo primário após o failover geográfico, confirme se o acesso de rede e a autenticação do servidor secundário estão configurados corretamente. Para obter detalhes, confira Configurar e gerenciar a segurança do Banco de Dados SQL do Azure para restauração ou failover geográfico. Confirme também se a política de retenção de backup no banco de dados secundário corresponde à do primário. Essa configuração não faz parte do banco de dados e não é replicada do primário. Por padrão, o secundário geográfico será configurado com um período de retenção de PITR padrão de sete dias. Para obter mais informações, confira Backups automatizados no Banco de Dados SQL do Azure.
Importante
Se o banco de dados for membro de um grupo de failover, não será possível iniciar o failover usando o comando de failover de replicação geográfica. Use o comando de failover para o grupo. Se precisar fazer failover de um banco de dados individual, você deverá primeiro removê-lo do grupo de failover. Confira grupos de failover para mais detalhes.
Configurar o secundário geográfico
O primário e o secundário devem ter a mesma camada de serviço. Também é altamente recomendado que o secundário geográfico seja configurado com a mesma redundância de armazenamento de backup, nível de computação (provisionado ou sem servidor) e tamanho de computação (DTUs ou vCores) que o primário. Se o primário estiver com uma carga de trabalho de gravação pesada, um secundário com um tamanho de computação menor poderá não ser capaz de ser atualizado. Isso causa retardo de replicação no secundário geográfico e, eventualmente, pode causar a indisponibilidade dele. Para reduzir esses riscos, a replicação geográfica ativa limita (restringe) a taxa do log de transações do primário, se necessário, para permitir que os secundários possam ser atualizados.
Outra consequência de uma configuração geográfica secundária desbalanceada é que, após o failover, o desempenho do aplicativo pode ser afetado devido à capacidade de computação insuficiente do novo primário. Nesse caso, é necessário escalar verticalmente o banco de dados para que ele tenha recursos suficientes, o que pode exigir tempo, e fazer um failover de alta disponibilidade no final do processo de escala vertical, o que pode interromper as cargas de trabalho do aplicativo.
Se você decidir criar o secundário geográfico com uma configuração diferente, monitore a taxa de E/S de log no primário ao longo do tempo. Isso permite estimar o tamanho mínimo de computação do secundário geográfico que é necessário para sustentar a carga de replicação. Por exemplo, se o banco de dados primário for P6 (1000 DTUs) e seu percentual de E/S de log for sustentado em 50%, o secundário geográfico precisará ser pelo menos P4 (500 DTUs). Para recuperar dados de E/S de log históricos, use a exibição sys.resource_stats. Para recuperar dados de E/S de log recentes com maior granularidade para refletir melhor os picos de curto prazo, use a exibição sys.dm_db_resource_stats.
Dica
Pode ocorrer limitação de E/S do log de transações:
- Quando o secundário geográfico está em um tamanho da computação inferior ao primário. Procure o tipo de espera HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO em sys.dm_exec_requests e sys.dm_os_wait_stats exibições de banco de dados.
- Motivos não relacionados ao tamanho da computação. Para saber mais, incluindo tipos de espera para diferentes tipos de limitação de E/S de log, confira Governança de taxa de log de transações.
Por padrão, a redundância de armazenamento de backup do secundário geográfico é a mesma do banco de dados primário. É possível optar por configurar o secundário geográfico com uma redundância de armazenamento de backup diferente. Os backups são sempre feitos no banco de dados primário. Se o secundário estiver configurado com uma redundância de armazenamento de backup diferente, após o failover geográfico, quando ele for promovido a primário, os novos backups serão armazenados e cobrados de acordo com o tipo de armazenamento (RA-GRS, ZRS, LRS) selecionado nele.
Economize nos custos com a réplica em espera
Se sua réplica secundária for usada apenas para DR (recuperação de desastre) e não tiver cargas de trabalho de leitura ou gravação, você poderá economizar nos custos de licenciamento designando o banco de dados para espera ao configurar uma nova relação de replicação geográfica ativa.
Examine Réplica de espera sem licença para saber mais.
Replicação geográfica entre assinaturas
Você pode usar o portal do Azure para configurar a replicação geográfica ativa entre assinaturas, desde que ambas as assinaturas estejam no mesmo locatário do Microsoft Entra.
- Para criar uma réplica secundária geográfica em uma assinatura diferente da primária em um locatário diferente do Microsoft Entra, use a autenticação de SQL e o T-SQL. Não há suporte à autenticação do Microsoft Entra para replicação geográfica entre assinaturas quando um servidor lógico está em um outro Locatário do Azure
- O suporte para operações de replicação geográfica entre assinaturas, incluindo configuração e failover geográfico, também têm suporte usando Databases Create ou Update API REST.
A criação de um secundário geográfico entre assinaturas em um servidor lógico no mesmo locatário do Microsoft Entra ou em um diferente não tem suporte quando a autenticação somente do Microsoft Entra está habilitada no servidor lógico primário ou secundário e a criação é feita usando um usuário do Microsoft Entra ID.
Para obter métodos e instruções passo a passo, veja Tutorial: Configurar a replicação geográfica ativa e o failover (Banco de Dados SQL do Azure).
Pontos de extremidade privados
Não há suporte para a adição de uma localização geográfica secundária usando T-SQL ao se conectar com o servidor primário em um ponto de extremidade privado.
- Se um ponto de extremidade privado estiver configurado, mas o acesso à rede pública for permitido, haverá suporte para a adição de uma localização geográfica secundária quando conectada ao servidor primário por um endereço IP público.
- Depois que uma localização geográfica é adicionada, o acesso à rede pública pode ser negado.
Manter credenciais e regras de firewall em sincronização
Ao usar o acesso de rede pública para se conectar ao banco de dados, recomenda-se usar regras de firewall de IP de nível de banco de dados para os bancos de dados replicados através da replicação geográfica. Essas regras são replicadas com o banco de dados, o que garante que todos os secundários geográficos tenham as mesmas regras de firewall de IP que o primário. Essa abordagem evita que os clientes tenham de configurar e manter manualmente as regras de firewall nos servidores que hospedam os bancos de dados primários e secundários. Da mesma forma, o uso de usuários de banco de dados independente para acesso a dados garante que os bancos de dados primário e secundário sempre tenham as mesmas credenciais de autenticação. Dessa forma, após um failover geográfico, não há interrupções devido a incompatibilidades de credenciais de autenticação. Se você estiver usando logons e usuários (em vez de usuários independentes), precisará realizar etapas extras para garantir que os mesmos logons existam no banco de dados secundário. Para obter detalhes da configuração confira Configurar e gerenciar a segurança do Banco de Dados SQL do Azure para restauração geográfica ou failover .
Escalar banco de dados primário
É possível escalar ou reduzir verticalmente o banco de dados primário para um tamanho de computação diferente (na mesma camada de serviço) sem desconectar nenhum banco de dados secundário. Ao escalar verticalmente, recomenda-se fazê-lo primeiro no secundário geográfico e, em seguida, no primário. Ao reduzir verticalmente, faça o oposto: primeiro reduza o primário e, em seguida, o secundário.
Para obter informações sobre grupos de failover, confira escalar uma réplica em um grupo de failover .
Evitar a perda de dados críticos
Devido à alta latência das redes de longa distância, a replicação geográfica usa um mecanismo de replicação assíncrona. Com a replicação assíncrona, é impossível evitar a perda de dados em caso de falha no primário. Para proteger as transações críticas contra a perda de dados, um desenvolvedor de aplicativos pode chamar o procedimento armazenado sp_wait_for_database_copy_sync imediatamente após a confirmação da transação. Chamar sp_wait_for_database_copy_sync bloqueia o thread de chamada até que a última transação confirmada seja transmitida e persistida no log de transações do banco de dados secundário. Contudo, a chamada não aguarda a reprodução (confirmação) das transações transmitidas no secundário. sp_wait_for_database_copy_sync tem escopo para um link de replicação geográfica específico. Qualquer usuário com os direitos de conexão para o banco de dados primário pode chamar este procedimento.
Observação
sp_wait_for_database_copy_sync impede a perda de dados após o failover geográfico para transações específicas, mas não garante a sincronização completa para acesso de leitura. A demora causada por uma chamada de procedimento sp_wait_for_database_copy_sync pode ser significativa e depende do tamanho, no momento da chamada, do log de transações ainda não transmitido no primário.
Monitoramento do retardo da replicação geográfica
Para monitorar o retardo em relação ao RPO, use a coluna replication_lag_sec de sys.dm_geo_replication_link_status no banco de dados primário. Ela mostra o retardo em segundos entre as transações confirmadas no primário e persistidas no log de transações do secundário. Por exemplo, se o retardo for de um segundo, isso significará que, se o primário for afetado por uma interrupção neste momento e um failover geográfico for iniciado, as transações confirmadas no último segundo serão perdidas.
Para medir o retardo em relação às alterações no banco de dados primário que foram protegidas no secundário geográfico, compare o tempo last_commit no secundário geográfico com o mesmo valor no primário.
Dica
Se replication_lag_sec no primário tiver um valor NULL, ele não saberá o quão atrasado está um secundário geográfico no momento. Isso normalmente ocorre depois que o processo é reiniciado e deve ser uma condição transitória. Considere o envio de um alerta se replication_lag_sec retornar o valor NULL por um longo período de tempo. Isso pode indicar que o secundário geográfico não é capaz de se comunicar com o primário devido a uma falha de conectividade.
Também há condições que podem causar um aumento na diferença entre o tempo last_commit no secundário geográfico e no primário. Por exemplo, se uma confirmação for feita no primário após um longo período sem alterações, a diferença saltará para um valor grande antes de retornar rapidamente para zero. Considere o envio de um alerta se a diferença entre esses dois valores permanecer grande por um longo tempo.
Gerenciar a replicação geográfica ativa programaticamente
A replicação geográfica ativa pode ser gerenciada programaticamente usando o T-SQL, o Azure PowerShell e a API REST. As tabelas a seguir descrevem o conjunto de comandos disponíveis. A replicação geográfica ativa inclui um conjunto de APIs do Azure Resource Manager para gerenciamento, incluindo a API REST do Banco de Dados SQL do Azure e cmdlets do Azure PowerShell. Essas APIs dão suporte ao RBAC (controle de acesso baseado em função) do Azure. Para obter mais informações sobre como implementar funções de acesso, confira RBAC (controle de acesso baseado em função) do Azure.
Importante
Esses comandos T-SQL só se aplicam à replicação geográfica ativa, não a grupos de failover.
| Comando | Descrição |
|---|---|
| ALTER DATABASE | Usar o argumento ADD SECONDARY ON SERVER para criar um banco de dados secundário para um banco de dados existente e iniciar a replicação de dados |
| ALTER DATABASE | Usar FAILOVER ou FORCE_FAILOVER_ALLOW_DATA_LOSS para alternar um banco de dados secundário para primário a fim de iniciar o failover |
| ALTER DATABASE | Usar REMOVE SECONDARY ON SERVER para encerrar uma replicação de dados entre um Banco de Dados SQL e o banco de dados secundário especificado. |
| sys.geo_replication_links | Retorna informações sobre todos os links de replicação existentes para cada banco de dados em um servidor. |
| sys.dm_geo_replication_link_status | Obtém a hora da última replicação, retardo da última replicação e outras informações sobre o link de replicação para um determinado banco de dados. |
| sys.dm_operation_status | Mostra o status de todas as operações de banco de dados, incluindo alterações em links de replicação. |
| sys.sp_wait_for_database_copy_sync | Faz com que o aplicativo aguarde até que todas as transações confirmadas sejam persistidas no log de transações de um secundário geográfico. |
Conteúdo relacionado
Configurar a replicação geográfica ativa:
- Para um banco de dados usando o portal do Azure
- Para criar um Banco de Dados Individual usando o PowerShell
- Para um banco de dados em pool usando o PowerShell
Outros conteúdos de continuidade dos negócios: