Criar serviços globalmente disponíveis usando o banco de dados SQL do Azure
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Ao criar e implantar serviços em nuvem com o Banco de Dados SQL do Azure, você usa replicação geográfica ativa ou grupos de failover para fornecer resiliência a interrupções regionais e falhas catastróficas. O mesmo recurso permite que você crie aplicativos distribuídos globalmente, otimizados para acesso local aos dados. Este artigo aborda os padrões comuns de aplicativos, incluindo os benefícios e as vantagens e desvantagens de cada opção.
Observação
Se estiver utilizando bancos de dados Premium ou Comercialmente Crítico e pools elásticos, será possível torná-los resilientes a interrupções regionais convertendo-os para configuração de implantação com redundância de zona. Veja Bancos de dados com redundância de zona.
Cenário 1: Usando duas regiões do Azure para continuidade dos negócios com tempo de inatividade mínimo
Nesse cenário, os aplicativos têm as seguintes características:
- O aplicativo está ativo em uma região do Azure
- Todas as sessões do banco de dados exigem acesso de leitura e gravação (RW) nos dados
- A camada da Web e a camada de dados devem estar colocalizadas para reduzir a latência e o custo de tráfego
- Essencialmente, o tempo de inatividade é um risco maior de negócios para esses aplicativos do que a perda de dados
Nesse caso, a topologia de implantação do aplicativo é otimizada para lidar com desastres regionais quando todos os componentes do aplicativo precisam fazer failover juntos. O diagrama abaixo mostra essa topologia. Para redundância geográfica, os recursos do aplicativo são implantados nas Regiões A e B. No entanto, os recursos da Região B não são utilizados até que a Região A falhe. Um grupo de failover é configurado entre as duas regiões para gerenciar o failover, a replicação e a conectividade do banco de dados. O serviço Web em ambas as regiões é configurado para acessar o banco de dados por meio do ouvinte de leitura/gravação <failover-group-name>.database.windows.net (1). O Gerenciador de Tráfego do Azure é configurado para usar o método de roteamento de prioridade (2).
Observação
O Gerenciador de Tráfego do Azure é usado neste artigo apenas para fins ilustrativos. Você pode usar qualquer solução de balanceamento de carga que dê suporte ao método de roteamento de prioridade.
O seguinte diagrama mostra essa configuração antes de uma interrupção:
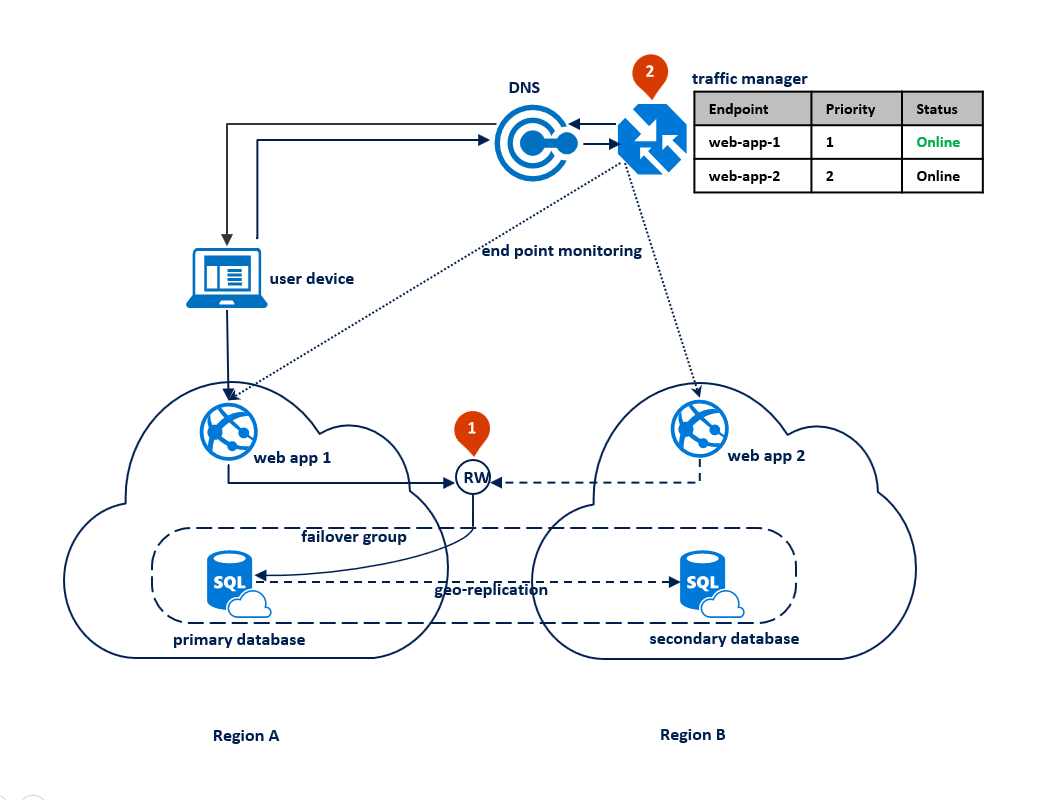
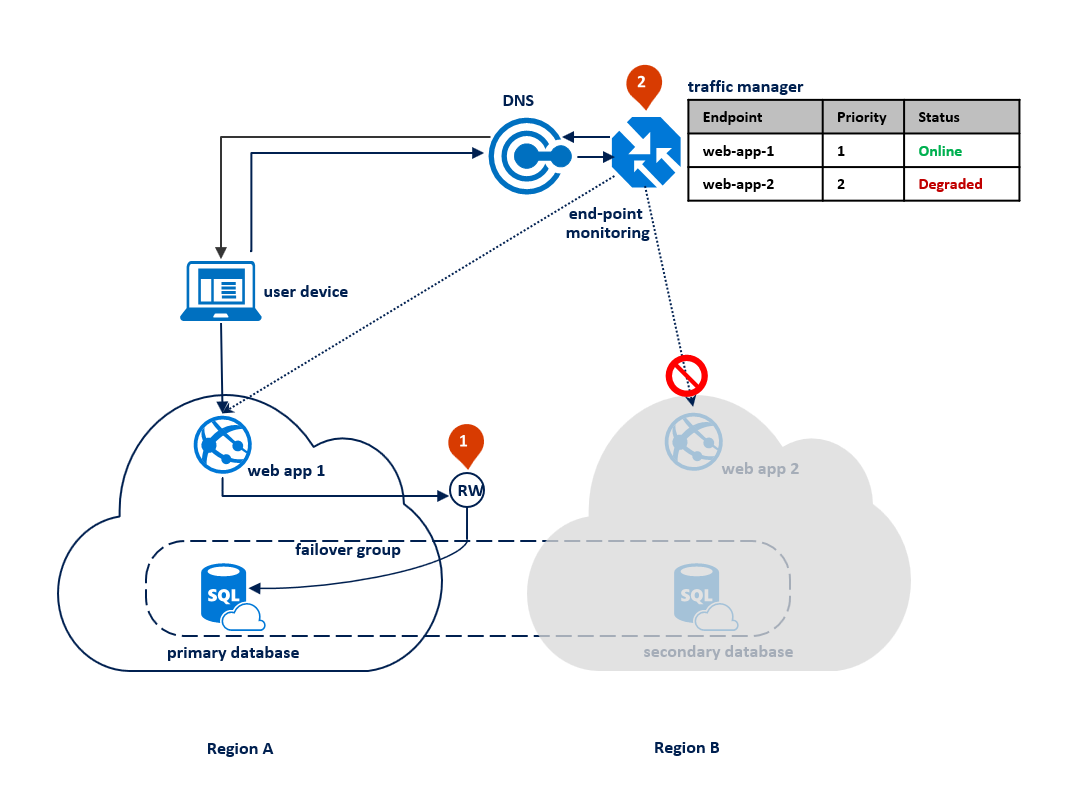
Após uma interrupção na região primária, o Banco de Dados SQL detecta que o banco de dados primário não está acessível e dispara um failover para a região secundária, com base nos parâmetros da política de failover automático (1). Dependendo do SLA do aplicativo, você pode configurar um período de carência que controla o tempo entre a detecção de interrupção e o failover em si. É possível que o Gerenciador de Tráfego do Azure inicie o failover do ponto de extremidade antes que o grupo de failover dispare o failover do banco de dados. Nesse caso, o aplicativo Web não pode se reconectar ao banco de dados imediatamente. Porém, as reconexões terão êxito automaticamente assim que o failover do banco de dados for concluído. Quando a região com falha é restaurada e colocada online novamente, o primário antigo se reconecta automaticamente como um novo secundário. O diagrama abaixo ilustra a configuração após o failover.
Observação
Todas as transações confirmadas após o failover são perdidas durante a reconexão. Após a conclusão do failover, o aplicativo da região B consegue se reconectar e reiniciar o processamento das solicitações do usuário. O aplicativo Web e o banco de dados primário agora estão na região B e permanecem colocalizados.
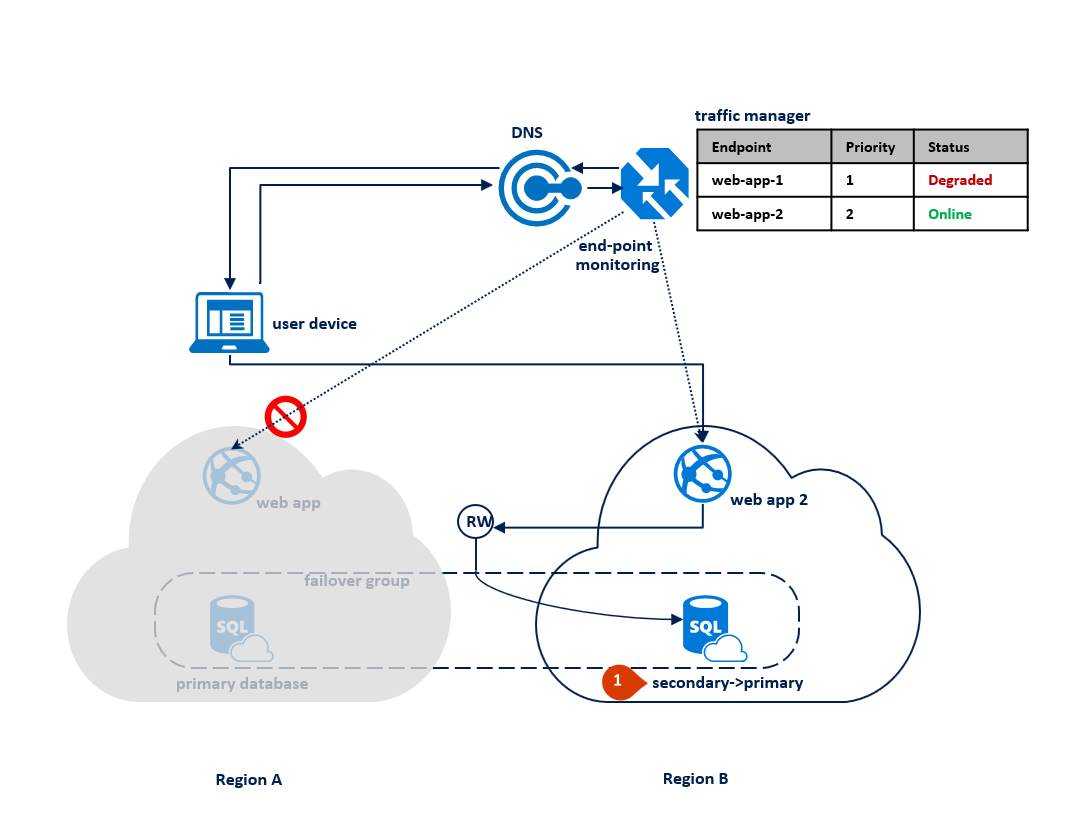
Se ocorrer uma interrupção na região B, o processo de replicação entre o banco de dados primário e secundário será suspenso, mas o vínculo entre os dois permanecerá intacto (1). O Gerenciador de Tráfego detecta que a conectividade com a região B está interrompida e marca o aplicativo Web do ponto de extremidade 2 como Degradado (2). O desempenho do aplicativo não é afetado nesse caso, mas o banco de dados fica exposto e, portanto, corre um risco maior de perda de dados, no caso de falha da região A em sucessão.
Observação
Para a recuperação de desastre, recomendamos a configuração com implantação de aplicativo limitada a duas regiões. Isso ocorre porque a maioria das regiões geográficas do Azure tem somente duas regiões. Essa configuração não protege o aplicativo contra uma falha catastrófica simultânea nas duas regiões. Caso ocorra essa falha improvável, você poderá recuperar seus bancos de dados em uma terceira região usando a operação de restauração geográfica. Para obter mais informações, confira diretrizes de recuperação de desastre do Banco de Dados SQL do Azure.
Depois que a interrupção é atenuada, o banco de dados secundário é sincronizado novamente de forma automática com o primário. Durante a sincronização, o desempenho do primário pode ser afetado. O impacto específico depende da quantidade de dados que o novo primário adquiriu desde o failover.
Observação
Depois que a interrupção for atenuada, o Gerenciador de Tráfego começará a rotear as conexões para o aplicativo na região A como um ponto de extremidade de prioridade mais alta. Se você pretende manter o primário na região B por um tempo, altere a tabela de prioridade no perfil do Gerenciador de Tráfego de acordo.
O seguinte diagrama ilustra uma interrupção na região secundária:
As principais vantagens desse padrão de design são:
- O mesmo aplicativo Web é implantado em ambas as regiões sem nenhuma configuração específica à região e não exige nenhuma lógica adicional para gerenciar o failover.
- O desempenho do aplicativo não é afetado pelo failover, pois o aplicativo Web e o banco de dados sempre estão co-localizados.
A principal desvantagem é que os recursos do aplicativo na Região B são subutilizados na maioria das vezes.
Cenário 2: regiões do Azure para continuidade dos negócios com preservação máxima de dados
Essa opção é mais adequada para aplicativos com as seguintes características:
- Qualquer perda de dados é um risco comercial elevado. O failover de banco de dados só poderá ser usado como último recurso, se a interrupção for causada por uma falha catastrófica.
- O aplicativo oferece suporte aos modos somente leitura e leitura/gravação de operações e pode operar em “modo somente leitura” por um período de tempo específico.
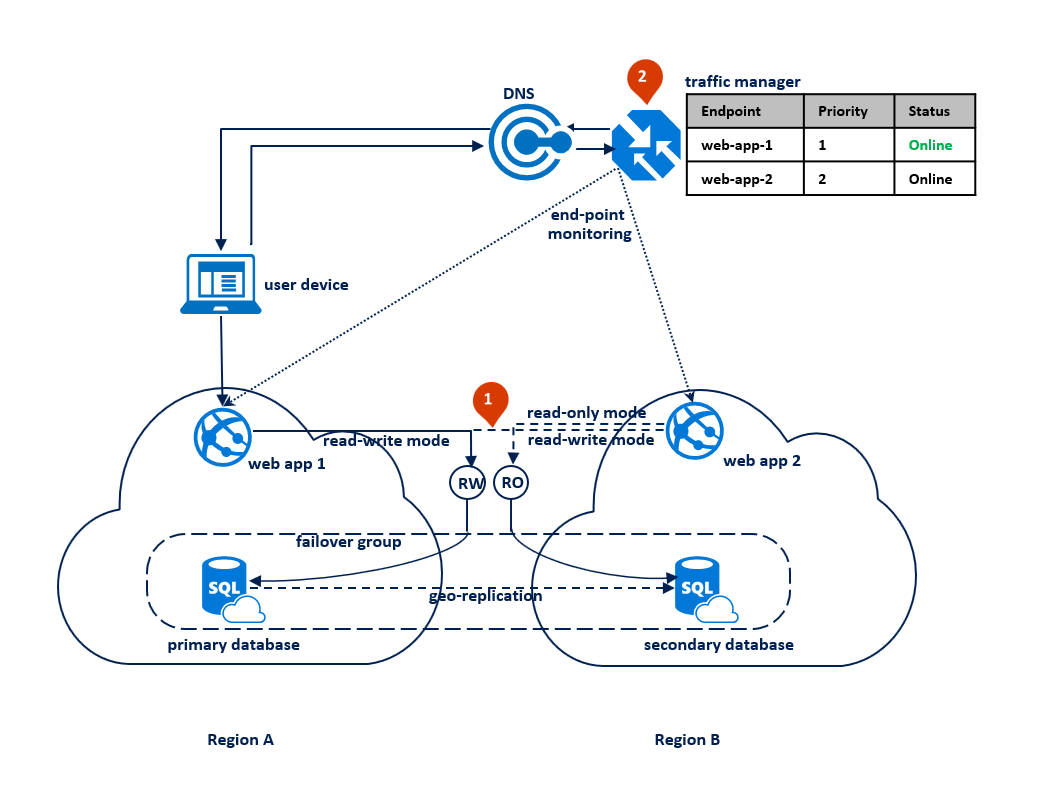
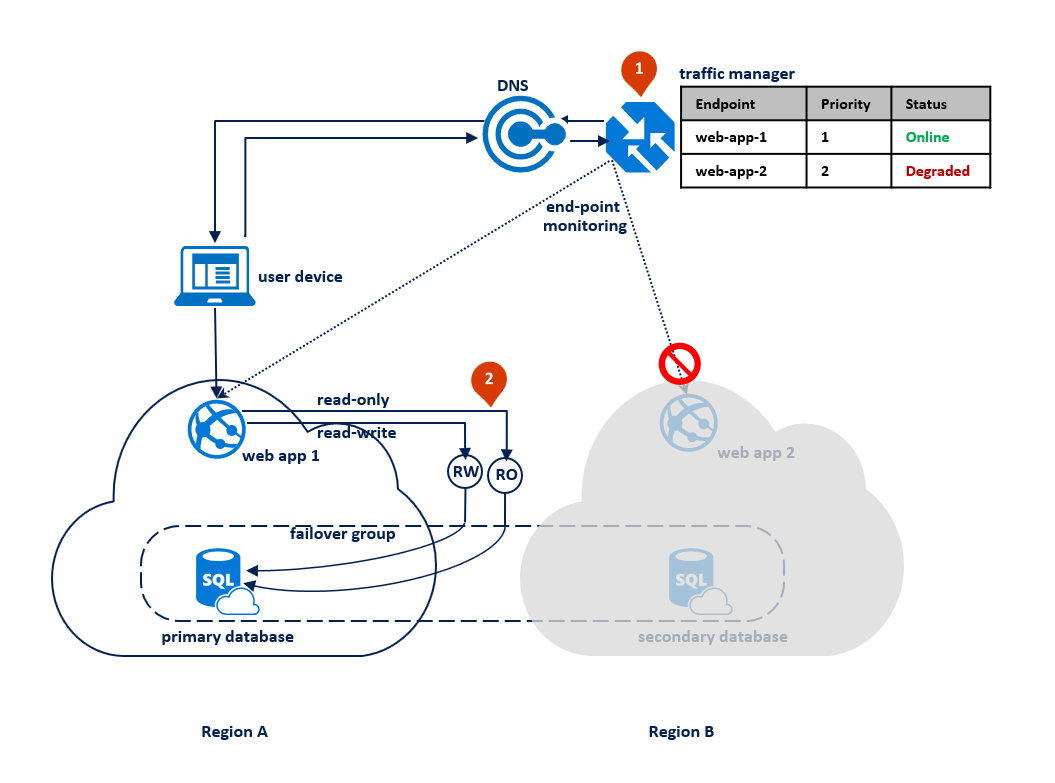
Nesse padrão, o aplicativo alterna para o modo somente leitura quando as conexões de leitura/gravação começam a receber erros de tempo limite. O aplicativo Web é implantado nas duas regiões e inclui uma conexão com o ponto de extremidade do ouvinte de leitura/gravação e uma conexão diferente com o ponto de extremidade do ouvinte somente leitura (1). O perfil do Gerenciador de Tráfego deve usar o roteamento de prioridade. O monitoramento de ponto de extremidade deve ser habilitado para o ponto de extremidade do aplicativo em cada região (2).
O seguinte diagrama ilustra essa configuração antes de uma interrupção:
Quando o Gerenciador de Tráfego detecta uma falha de conectividade na região A, ele alterna automaticamente o tráfego de usuário para a instância do aplicativo na região B. Com esse padrão, é importante definir o período de cortesia com perda de dados com um valor suficientemente alto, por exemplo, 24 horas. Ele garante que a perda de dados é impedida se a interrupção é atenuada dentro desse período. Quando o aplicativo Web na região B é ativado, as operações de leitura/gravação começam a falhar. Nesse ponto, ele deve alternar para o modo somente leitura (1). Nesse modo, as solicitações são encaminhadas automaticamente para o banco de dados secundário. Se a interrupção for causada por uma falha catastrófica, muito provavelmente, ela não poderá ser atenuada dentro do período de carência. Quando ele expirar, o grupo de failover disparará o failover. Depois disso, o ouvinte de leitura/gravação fica disponível e as conexões com ele param de falhar (2). O diagrama a seguir ilustra os dois estágios do processo de recuperação.
Observação
Se a interrupção na região primária é atenuada dentro do período de cortesia, o Gerenciador de Tráfego detecta a restauração da conectividade na região primária e alterna o tráfego do usuário novamente para a instância do aplicativo na região A. Essa instância do aplicativo é retomada e opera no modo leitura/gravação usando o banco de dados primário na região A, conforme ilustrado no diagrama anterior.
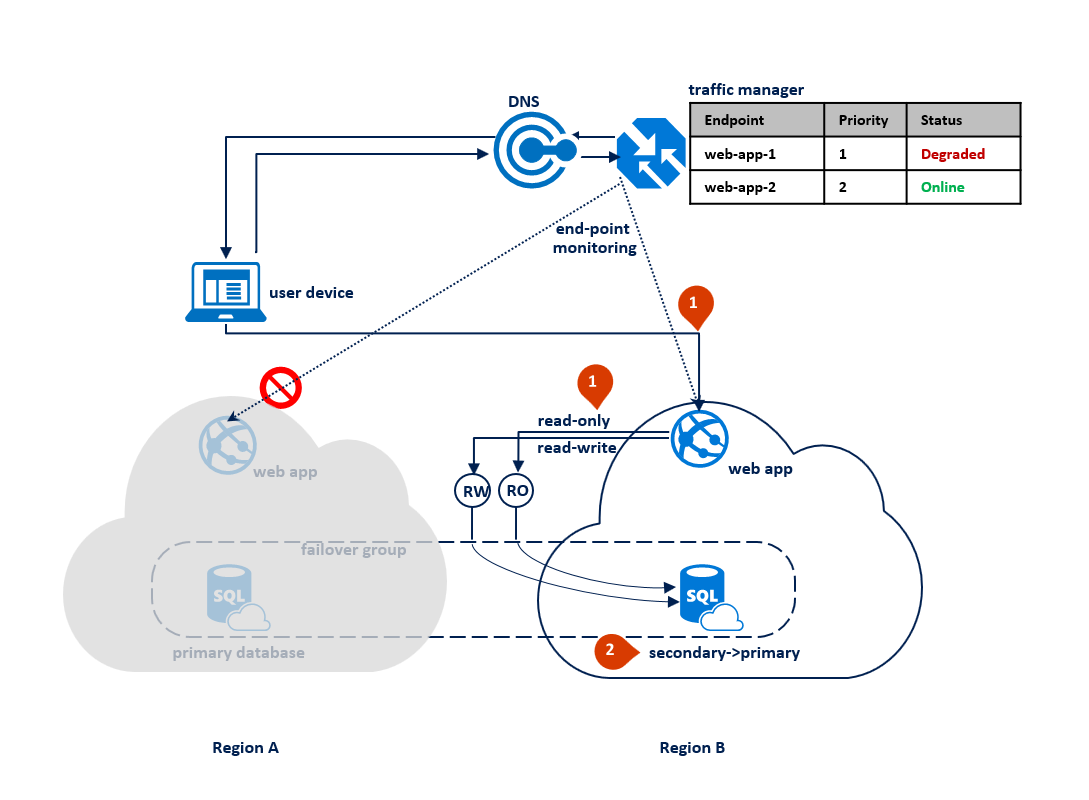
Se ocorrer uma interrupção na região B, o Gerenciador de Tráfego detectará a falha do aplicativo Web do ponto de extremidade 2 na região B e o marcará como Degradado (1). Enquanto isso, o grupo de failover alterna o ouvinte somente leitura para a região A (2). Essa interrupção não afeta a experiência do usuário final, mas o banco de dados primário fica exposto durante a interrupção. O seguinte diagrama ilustra uma falha na região secundária:
Após a interrupção ser atenuada, o banco de dados secundário é sincronizado imediatamente com o primário e o ouvinte de somente leitura é revertido para o banco de dados secundário na região B. Durante a sincronização, o desempenho do banco de dados primário pode ser afetado ligeiramente dependendo da quantidade de dados que precisam ser sincronizados.
Esse padrão de design apresenta várias vantagens:
- Ele evita a perda de dados durante as interrupções temporárias.
- O tempo de inatividade depende somente da velocidade com a qual o Gerenciador de Tráfego detecta a falha de conectividade, o que pode ser configurado.
A desvantagem é que o aplicativo deve poder operar no modo somente leitura.
Planejamento de continuidade de negócios: escolher um design de aplicativo para recuperação de desastre em nuvem
A estratégia específica de recuperação de desastre em nuvem pode combinar ou estender esses padrões de design para atender da melhor forma às necessidades do aplicativo. Como mencionado anteriormente, a estratégia escolhida é baseada no SLA que você deseja oferecer a seus clientes e na topologia de implantação do aplicativo. Para ajudar a orientar sua decisão, a tabela a seguir compara as opções com base no RPO (objetivo de ponto de recuperação) e no ERT (tempo de recuperação estimado).
| Padrão | RPO | ERT |
|---|---|---|
| Implantação ativa-passiva para recuperação de desastres com acesso de banco de dados colocalizado | Acesso de leitura/gravação < 5 seg. | Tempo de detecção de falha + TTL do DNS |
| Implantação ativa-ativa para balanceamento de carga de aplicativo | Acesso de leitura/gravação < 5 seg. | Tempo de detecção de falha + TTL do DNS |
| Implantação ativa-passiva para preservação de dados | Acesso somente leitura < 5 seg | Acesso somente leitura = 0 |
| Acesso de leitura/gravação = zero | Acesso de leitura/gravação = Tempo de detecção de falha + período de carência de perda de dados |
Próximas etapas
- Para obter uma visão geral e os cenários de continuidade dos negócios, confira Visão geral da continuidade dos negócios
- Para saber mais sobre a replicação geográfica ativa, consulte Replicação geográfica ativa.
- Para saber mais sobre grupos de failover, consulte Grupos de failover.
- Para obter informações sobre a replicação geográfica ativa com pools elásticos, confira Estratégias de recuperação de desastre do pool elástico.