Visão geral dos pools elásticos de Hiperescala no Banco de Dados SQL do Azure
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Este artigo fornece uma visão geral dos pools elásticos de Hiperescala no Banco de Dados SQL do Azure.
Um pool elástico do Banco de Dados SQL do Azure permite que os desenvolvedores de software como serviço (SaaS) otimizem a relação preço-desempenho para um grupo de bancos de dados em um orçamento prescrito, ao mesmo tempo que fornece elasticidade de desempenho para cada banco de dados. Os pools elásticos de Hiperescala do Banco de Dados SQL do Azure apresentam um modelo de recurso compartilhado para bancos de dados de Hiperescala.
Para obter exemplos para criar, dimensionar ou mover bancos de dados para um pool elástico de Hiperescala usando a CLI do Azure ou o PowerShell, examine Trabalhar com pools elásticos de Hiperescala usando ferramentas de linha de comando
Observação
Os pools elásticos de Hiperescala estão atualmente em versão prévia.
Visão geral
Implante seu banco de dados de Hiperescala no pool elástico para compartilhar recursos entre bancos de dados dentro do pool e otimizar o custo de ter vários bancos de dados com padrões de uso diferentes.
Cenários para usar o pool elástico com seus bancos de dados de Hiperescala:
- Quando você precisar escalar ou reduzir os recursos de computação alocados para o pool elástico verticalmente em um período previsível de tempo, independentemente da quantidade de armazenamento alocado.
- Quando você quiser escalar horizontalmente os recursos de computação alocados para o pool elástico adicionando uma ou mais réplicas de escala de leitura.
- Se você quiser usar alta taxa de transferência de log de transações para cargas de trabalho com uso intensivo de gravação, mesmo com poucos recursos de computação.
A migração de bancos de dados que não são de Hiperescala para um pool elástico de Hiperescala atualiza os bancos de dados para a camada de serviço de Hiperescala.
Arquitetura
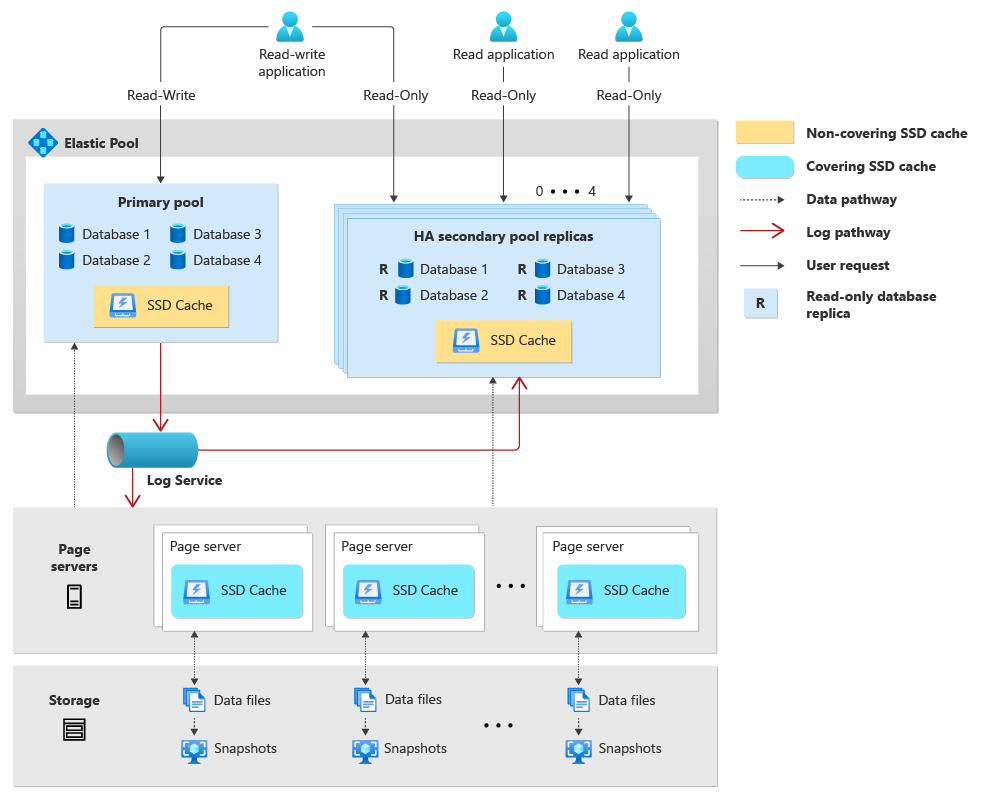
Tradicionalmente, a arquitetura de um banco de dados autônomo de Hiperescala consiste em três componentes independentes principais: Computação, Armazenamento ("Servidores de Página") e o log ("Serviço de Log"). Quando você cria um pool elástico para os bancos de dados de Hiperescala, os bancos de dados no pool compartilham os recursos de computação e log. Além disso, se você optar por configurar a alta disponibilidade, cada pool de alta disponibilidade será criado com um conjunto equivalente e independente de recursos de computação e log.
Veja a seguinte descrição da arquitetura de um pool elástico para bancos de dados de Hiperescala:
- Um pool elástico de Hiperescala consiste em um pool primário que hospeda bancos de dados primários de Hiperescala e, se configurado, até quatro pools adicionais de alta disponibilidade.
- Os bancos de dados primários de Hiperescala hospedados no pool elástico primário compartilham o processo de computação do mecanismo de banco de dados SQL Server (sqlservr.exe), os vCores, a memória e o cache SSD.
- Configurar a alta disponibilidade para o pool primário cria pools de alta disponibilidade adicionais que contêm réplicas de banco de dados somente leitura dos bancos de dados no pool primário. Cada pool primário pode ter no máximo quatro pools de réplica de alta disponibilidade. Cada pool de alta disponibilidade compartilha os recursos de computação, cache SSD e memória com todos os bancos de dados secundários somente leitura no pool.
- Todos os bancos de dados de hiperescala no pool elástico primário compartilham o mesmo serviço de log. Como os bancos de dados nos pools de alta disponibilidade não têm carga de trabalho de gravação, eles não usam o serviço de log.
- Cada banco de dados de Hiperescala tem seu próprio conjunto de servidores de página e esses servidores de página são compartilhados entre o banco de dados primário no pool primário e todos os bancos de dados de réplica secundária no pool de alta disponibilidade.
- Os bancos de dados de Hiperescala secundários de replicação geográfica podem ser colocados dentro de outro pool elástico.
- Especificar
ApplicationIntent=ReadOnlyem sua cadeia de conexão de banco de dados roteia você para o banco de dados de réplica somente leitura em um dos pools de alta disponibilidade.
Veja o seguinte diagrama que apresenta a arquitetura de um pool elástico para bancos de dados de Hiperescala:
Gerenciar bancos de dados de pool elástico de Hiperescala
Você pode usar os mesmos comandos para gerenciar seus bancos de dados de Hiperescala em pool como bancos de dados em pool nas outras camadas de serviço. Apenas certifique-se de especificar Hyperscale para edição ao criar seu pool elástico de Hiperescala.
A única diferença é a capacidade de modificar o número de réplicas de H/A (alta disponibilidade) para um pool elástico de Hiperescala existente. Para fazer isso:
- Use o parâmetro
HighAvailabilityReplicaCountdo comando Set-AzSqlElasticPool do Azure PowerShell. - Use o parâmetro
--ha-replicasdo comando az sql elastic-pool update da CLI do Azure.
Você pode usar as seguintes ferramentas de cliente para gerenciar os bancos de dados de Hiperescala em um pool elástico:
- Azure PowerShell: Az.Sql.3.11.0 ou superior. Não há suporte para o AzureRM.Sql do PowerShell.
- A CLI do Azure: Az versão 2.40.0 ou superior.
- T-SQL (Transact-SQL) começando com: SSMS (SQL Server Management Studio) v18.12.1 ou Azure Data Studio v1.39.1.
Migrar bancos de dados não Hiperescala para pools elásticos de Hiperescala
Ao migrar um banco de dados para Hiperescala, você pode adicionar o banco de dados a um pool elástico de Hiperescala existente. Para essas migrações, o pool elástico de Hiperescala precisa existir no mesmo servidor lógico que o banco de dados de origem.
Ao migrar bancos de dados para pools elásticos de Hiperescala, esteja ciente do número máximo de bancos de dados por pool elástico de hiérescala.
Migrar bancos de dados não Hiperescala para pools elásticos de Hiperescala usando T-SQL
Você pode usar comandos T-SQL para migrar vários bancos de dados de uso geral e adicioná-los a um pool elástico de Hiperescala existente chamado hsep1:
ALTER DATABASE gpepdb1 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb2 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb3 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb4 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
Neste exemplo, você está solicitando implicitamente uma migração de uso geral para Hiperescala, especificando que o destino SERVICE_OBJECTIVE é um pool elástico de Hiperescala. Cada um dos comandos acima inicia a migração do respectivo banco de dados de uso geral para Hiperescala. Esses comandos ALTER DATABASE retornam rapidamente e não esperam a conclusão da migração para conclusão. No exemplo mostrado, você teria quatro dessas migrações de uso geral para Hiperescala em execução em paralelo.
Você pode consultar a exibição de gerenciamento dinâmico sys.dm_operation_status para monitorar o status dessas operações de migração em segundo plano.
Migrar bancos de dados não Hiperescala para pools elásticos de Hiperescala usando PowerShell
Você pode usar comandos PowerShell para migrar vários bancos de dados de uso geral e adicioná-los a um pool elástico de Hiperescala existente chamado hsep1. Por exemplo, o script de exemplo a seguir executa as seguintes etapas:
- Use o cmdlet Get-AzSqlElasticPoolDatabase para listar todos os bancos de dados no pool elástico de uso geral chamado
gpep1. - O cmdlet
Where-Objectfiltra a lista apenas para os nomes de banco de dados que começam comgpepdb. - Para cada banco de dados, o cmdlet Set-AzSqlDatabase inicia uma migração. Neste caso, você está solicitando implicitamente uma migração para Hiperescala especificando como destino o pool elástico de Hiperescala chamado
hsep1.- O parâmetro
-AsJobpermite que cada uma dasSet-AzSqlDatabasesolicitações seja executada em paralelo. Se você preferir executar as migrações uma a uma, poderá remover o parâmetro-AsJob.
- O parâmetro
$dbs = Get-AzSqlElasticPoolDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -ElasticPoolName "gpep1"
$dbs | Where-Object { $_.DatabaseName -like "gpepdb*" } | % { Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -DatabaseName ($_.DatabaseName) -ElasticPoolName "hsep1" -AsJob }
Além da exibição de gerenciamento dinâmico sys.dm_operation_status , você pode usar o cmdlet Get-AzSqlDatabaseActivity do PowerShell para monitorar o status dessas operações de migração em segundo plano.
Limites de recursos
Veja os seguintes limites com suporte para trabalhar com bancos de dados de Hiperescala em pools elásticos:
- Geração de hardware suportada: Memória da série padrão (Gen5), série premium e memória da série premium otimizada.
- Máximo de vCore por pool: 80 ou 128 vCores, dependendo do objetivo de nível de serviço.
- Tamanho máximo de dados com suporte por banco de dados: 100 TB.
- Tamanho máximo de dados totais com suporte em bancos de dados no pool: 100 TB.
- Taxa de transferência máxima de log de transações com suporte por banco de dados: 100 MB.
- Máxima taxa de transferência total de log de transações suportada entre os bancos de dados no pool: 131,25 MB/segundo.
- Cada pool elástico de Hiperescala pode ter até 25 bancos de dados.
Para obter mais detalhes, consulte os limites de recursos dos pools elásticos de Hiperescala para memória da série padrão, série premium e série premium otimizada.
Observação
Perfis de desempenho, recursos com suporte e limites publicados estão sujeitos a alterações enquanto o recurso está em versão prévia. Dessa forma, é melhor validar seu caso de uso com testes funcionais, de desempenho e de escala regulares de cargas de trabalho.
Limitações
Considere as seguintes limitações:
- Não há suporte para a alteração de um pool elástico que não é de hiperescala existente para a edição de hiperescala. A seção de migração fornece algumas alternativas que você pode usar.
- Não há suporte para a alteração da edição de um pool elástico de Hiperescala para uma edição que não é de Hiperescala.
- Para reverter a migração de um banco de dados qualificado que está em um pool elástico de Hiperescala, ele deve primeiro ser removido do pool elástico de Hiperescala. O banco de dados autônomo de Hiperescala pode ser migrado de forma reversa para um banco de dados autônomo de Uso Geral.
- Para a camada de serviço de Hiperescala, o suporte à redundância de zona só pode ser especificado durante a criação do banco de dados ou do pool elástico e não pode ser modificado depois que o recurso é provisionado. Para obter mais informações, consulte Migrar banco de dados de SQL do Azure para o suporte a zonas de disponibilidade.
- Não há suporte para adicionar uma réplica nomeada a um pool elástico de Hiperescala. Tentar adicionar uma réplica nomeada um banco de dados de Hiperescala em um pool elástico de Hiperescala resulta em um erro
UnsupportedReplicationOperation. Em vez disso, crie a réplica nomeada como um único banco de dados de hiperescala.
Considerações sobre pools elásticos com redundância de zona
Para pools elásticos com redundância de zona, considere o seguinte:
Observação
Os pools elásticos de Hiperescala com redundância de zona estão disponíveis, atualmente na versão prévia. Para obter mais informações, consulte Postagem de blog: pools elásticos de Hiperescala com redundância de zona.
- Somente bancos de dados com redundância de armazenamento com redundância de zona (ZRS ou GZRS) podem ser adicionados a pools elásticos de Hiperescala com redundância de zona.
- Um banco de dados de Hiperescala autônomo deve ser criado com redundância de zona e armazenamento de backup com redundância de zona (ZRS ou GZRS) para que seja adicionado a um pool elástico de Hiperescala com redundância de zona. Para bancos de dados de Hiperescala sem redundância de zona, execute uma transferência de dados para um novo banco de dados de Hiperescala com a opção de redundância de zona habilitada. Um clone deve ser criado usando cópia de banco de dados, restauração pontual ou réplica geográfica. Para obter mais informações, consulte Reimplantação (Hiperescala).
- Para mover um banco de dados de Hiperescala de um pool elástico para outro, as configurações de redundância de zona e armazenamento de backup com redundância de zona devem corresponder.
- Para migrar um banco de dados de outra camada de serviço não de Hiperescala para um pool elástico de Hiperescala com redundância de zona:
- Por meio do portal do Azure, primeiro habilite a redundância de zona e o ZRS (armazenamento de backup com redundância de zona). Em seguida, você pode adicionar o banco de dados ao pool elástico de Hiperescala com redundância de zona.
- Por meio do PowerShell, primeiro habilite a redundância de zona. Em seguida, com Set-AzSqlDatabase, verifique se o parâmetro
-BackupStorageRedundancyé usado para especificar o armazenamento de backup com redundância de zona (ZRS ou GZRS).
Problemas conhecidos
| Problema | Recomendação |
|---|---|
Em casos raros, você pode receber o erro 45122 - This Hyperscale database cannot be added into an elastic pool at this time. In case of any questions, please contact Microsoft support ao tentar mover / restaurar / copiar um banco de dados de Hiperescala em um pool elástico. |
Essa limitação ocorre devido a detalhes específicos da implementação. Se esse erro bloquear você, gere um incidente de suporte e solicite ajuda. |
Conteúdo relacionado
- Trabalhar com pools elásticos de Hiperescala usando ferramentas de linha de comando
- Preços do pool elástico
- Dimensionar os recursos de pool elástico no banco de dados SQL do Azure
- Usar o PowerShell para monitorar e dimensionar um pool elástico no Banco de Dados SQL do Azure
- Padrões de locatário de banco de dados de SaaS multilocatários
- Introdução a um aplicativo SaaS multilocatário que usa o padrão de banco de dados por locatário com o Banco de Dados SQL do Azure
- Gerenciamento de recursos em pools elásticos densos
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de