Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Este artigo ensina como configurar um link entre o SQL Server e a Instância Gerenciada de SQL do Azure com o uso do SQL Server Management Studio (SSMS). Com o link, os bancos de dados da primária inicial são replicados para a réplica secundária quase em tempo real.
Depois que o link for criado, é possível fazer failover para a réplica secundária para fins de migração ou recuperação de desastre.
Observação
- Também é possível configurar o link usando scripts.
- A configuração da Instância Gerenciada de SQL do Azure como a sua primária inicial tem suporte a partir do SQL Server 2022 CU10.
Visão geral
Use o recurso de link para replicar bancos de dados da primária inicial para a réplica secundária. Para o SQL Server 2022, a primária inicial pode ser o SQL Server ou a Instância Gerenciada de SQL do Azure. Para o SQL Server 2019 e versões anteriores, a primária inicial deve ser o SQL Server. Depois que o link é configurado, os bancos de dados do primário inicial são replicados para a réplica secundária.
É possível optar por deixar o link no lugar para replicação contínua de dados em um ambiente híbrido entre a réplica primária e secundária, ou fazer o failover do banco de dados para a réplica secundária, para migrar para o Azure ou para recuperação de desastre. Para o SQL Server 2019 e versões anteriores, fazer failover para a Instância Gerenciada de SQL do Azure quebra o link. Assim, a operação de failback não tem suporte. Com o SQL Server 2022, você tem a opção de manter o link e alternar entre as duas réplicas.
Se planejar utilizar a instância gerenciada secundária apenas para recuperação de desastre, é possível economizar em custos de licenciamento ativando o benefício de failover híbrido.
Utilize as instruções neste artigo para configurar manualmente o link entre o SQL Server e a Instância Gerenciada de SQL do Azure. Após a criação do link, o banco de dados de origem recebe uma cópia somente leitura na réplica secundária de destino.
Pré-requisitos
Para replicar os bancos de dados para a réplica secundária por meio do link, é necessário ter os seguintes pré-requisitos:
- Uma assinatura ativa do Azure. Se você não tiver uma, crie uma conta gratuita.
- Versão com suporte do SQL Server com a atualização de serviço necessária instalada.
- Instância Gerenciada de SQL do Azure. Caso não a tenha, confira a introdução.
- SQL Server Management Studio v19.2 ou posterior.
- Um ambiente adequadamente preparado.
Considere o seguinte:
- O recurso de link suporta um banco de dados por link. Para replicar vários bancos de dados em uma instância, deve-se criar um link para cada banco de dados individual. Por exemplo, para replicar 10 bancos de dados para a Instância Gerenciada de SQL, crie 10 links individuais.
- O agrupamento entre o SQL Server e a Instância Gerenciada do SQL deve ser o mesmo. Uma incompatibilidade no agrupamento pode causar uma incompatibilidade na caixa de nome do servidor e impedir uma conexão bem-sucedida do SQL Server com a Instância Gerenciada de SQL.
- O erro 1475 no SQL Server primário inicial indica que é necessário iniciar uma nova cadeia de backup, criando um backup completo sem a
COPY ONLYopção. - Para estabelecer um link, ou failover, da Instância Gerenciada de SQL para o SQL Server 2022, sua instância gerenciada deve ser configurada com a política de atualização do SQL Server 2022. Não há suporte para a duplicação de dados e para o failover da Instância Gerenciada de SQL para o SQL Server 2022 por parte de instâncias configuradas com a política de atualizações Sempre atualizado.
- Embora você possa estabelecer um link do SQL Server 2022 para uma instância gerenciada de SQL configurada com a política de atualização Sempre atualizado, após o failover para a Instância Gerenciada de SQL, você não poderá mais replicar dados nem fazer failback para o SQL Server 2022.
Permissões
No SQL Server, você deve ter permissões sysadmin.
Na Instância Gerenciada de SQL do Azure, você deve ser membro do Colaborador de Instância Gerenciada de SQL ou ter as seguintes permissões para uma função personalizada:
| Recurso Microsoft.Sql/ | Permissões necessárias |
|---|---|
| Microsoft.Sql/managedInstances | /read, /write |
| Microsoft.Sql/managedInstances/hybridCertificate | /action |
| Microsoft.Sql/managedInstances/databases | /read, /delete, /write, /completeRestore/action, /readBackups/action, /restoreDetails/read |
| Microsoft.Sql/managedInstances/distributedAvailabilityGroups | /read, /write, /delete, /setRole/action |
| Microsoft.Sql/managedInstances/endpointCertificates | /read |
| Microsoft.Sql/managedInstances/hybridLink | /read, /write, /delete |
| Microsoft.Sql/managedInstances/serverTrustCertificates | /write, /delete, /read |
Preparar banco de dados
Se o SQL Server for a primária inicial, é necessário criar um backup do banco de dados. Como a Instância Gerenciada de SQL do Azure faz backups de forma automática, é possível ignorar esta etapa se a Instância Gerenciada de SQL for a primária inicial.
Utilize o SSMS para realizar o backup do banco de dados no SQL Server. Siga estas etapas:
- Conecte-se ao SQL Server no SQL Server Management Studio (SSMS).
- No Pesquisador de Objetos, clique com o botão direito do mouse no banco de dados, aponte para Tarefas e selecione Fazer Backup.
- Escolha Completo para o tipo de backup.
- Verifique-se de que a opção Fazer backup em tenha o caminho de backup para um disco com espaço de armazenamento livre suficiente disponível.
- Clique em OK para concluir o backup completo.
Para saber mais, confira Criar um backup completo de banco de dados.
Observação
O link suporta apenas a replicação de bancos de dados de usuários. Não há suporte para a replicação de bancos de dados do sistema. Para replicar objetos de nível de instância (armazene em master ou msdb), faça os scripts deles e execute scripts o T-SQL scripts na instância de destino.
Criar link para replicar banco de dados
Nos etapas a seguir, utilize o assistente Novo Link de Instância Gerenciada no SSMS para criar um link entre a primária inicial e sua réplica secundária.
Após criar o link, o banco de dados de origem obterá uma cópia somente leitura em sua réplica secundária de destino.
Abra o SSMS e conecte-se à primária inicial.
No Pesquisador de Objetos, clique com o botão direito no banco de dados ao qual deseja vincular a réplica secundária, passe o cursor sobre Link da Instância Gerenciada de SQL do Azure e selecione Novo... para abrir o assistente Novo Link de Instância Gerenciada. Se não houver suporte para a versão do SQL Server, essa opção não estará disponível no menu de contexto.
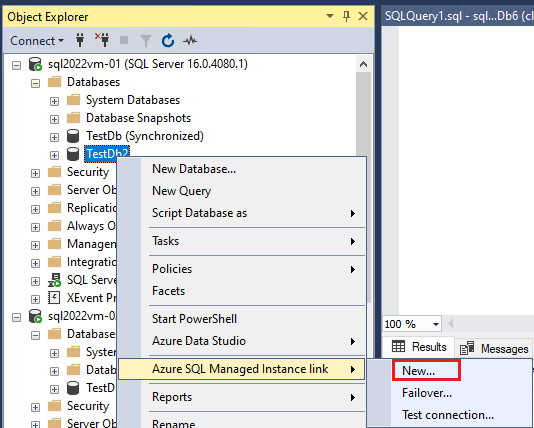
Na página Introdução do assistente, selecione Próximo.
Na página Especificar Opções de Link, deve-se fornecer um nome para o link. Caso selecionar vários bancos de dados, então o nome do banco de dados é acrescentado de forma automática ao final do nome que fornecido, para que não seja necessário incluí-lo manualmente. Marque as caixas se desejar habilitar a solução de problemas de conectividade e, para o SQL Server 2022, se planeja usar o link para recuperação de desastre bidirecional. Selecione Avançar.
Na página Requisitos, o assistente valida os requisitos para estabelecer um link com a sua réplica secundária. Selecione Avançar depois que todos os requisitos forem validados ou resolva os requisitos que não forem atendidos e, em seguida, selecione Executar novamente a validação.
Na página Selecionar Bancos de Dados, escolha o banco de dados que deseja replicar para sua réplica secundária por meio do link. Selecionar vários bancos de dados cria vários grupos de disponibilidade distribuídos, um para cada link. Selecione Avançar.
Na página Especificar Réplica Secundária, selecione Adicionar réplica secundária e adicione a réplica secundária. Se a primária inicial for o SQL Server, isso abre a janela Entrar no Azure. Se a primária inicial for Instância Gerenciada de SQL, isso abrirá a caixa de diálogo Conecte-se ao servidor.
- Para uma primária inicial do SQL Server, conecte-se ao Azure, escolha a assinatura, o grupo de recursos e a instância gerenciada secundária do SQL Server no menu suspenso. Selecione Logon para abrir a caixa de diálogo Conectar ao Servidor e conecte-se à Instância Gerenciada de SQL para a qual você deseja replicar o banco de dados. Ao ver Logon bem-sucedido na janela Entrar, selecione OK para fechar a janela e volte ao assistente de Novo link de Instância Gerenciada.
- Para uma Instância Gerenciada de SQL primária inicial, conecte-se à instância do SQL Server para a qual você deseja replicar seu banco de dados.
Observação
Se você quiser estabelecer um link para um grupo de disponibilidade existente, forneça o endereço IP do ouvinte existente no campo URL do Ponto de Extremidade na guia Pontos de Extremidade da página Especificar Réplica Secundária.
Depois de adicionar a réplica secundária, use as guias do assistente para modificar as configurações do Ponto de Extremidade, se necessário, e rever as informações sobre backups e o ponto de extremidade do link nas guias restantes. Quando estiver pronto para continuar, selecione Avançar.
Se a Instância Gerenciada de SQL for sua primária inicial, a próxima página do assistente será a página Logon no Azure. Entre novamente, se necessário, e selecione Avançar. Esta página não está disponível quando o SQL Server é a primária inicial.
Na página Validação, certifique-se de que todas as validações sejam aprovadas com sucesso. Se algum falhar, resolva-os e execute novamente a validação. Ao estar tudo pronto, selecione Avançar.
Na página Resumo, revise sua configuração mais uma vez. Opcionalmente, selecione Script para gerar um script, permitindo recriar facilmente o mesmo link no futuro. Quando tudo estiver pronto para criar o link, selecione Concluir.
A página Ações em execução exibe o progresso de cada ação.
Após a conclusão de todas as etapas, a página resultados mostrará as marcas de seleção ao lado das ações concluídas com êxito. Agora você pode fechar a janela.
Exibir um banco de dados replicado
Depois que o link é criado, o banco de dados é replicado para a réplica secundária. Dependendo do tamanho do banco de dados e da velocidade da rede, o banco de dados pode inicialmente estar em um estado de Restauração na réplica secundária. Após concluir a propagação inicial, o banco de dados é restaurado para a instância gerenciada e está pronto para cargas de trabalho em uma versão somente leitura.
Em qualquer réplica, use o Pesquisador de Objetos no SSMS para exibir o estado Sincronizado do banco de dados replicado.
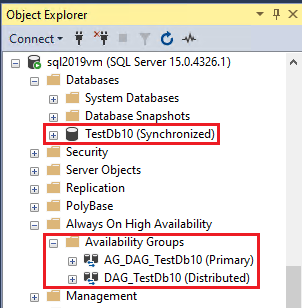
Expanda Alta Disponibilidade Always On e Grupos de Disponibilidade para visualizar o grupo de disponibilidade distribuído criado para cada link.
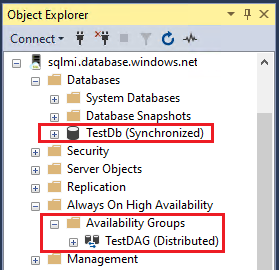
Independentemente de qual instância é primária, você também pode clicar com o botão direito do mouse no grupo de disponibilidade distribuído vinculado no SQL Server e selecionar Mostrar Painel para exibir o painel do grupo de disponibilidade distribuído, que mostra o status do banco de dados vinculado no grupo.
Fazer o primeiro backup de log de transações
Se o SQL Server for o primário inicial, é importante fazer o primeiro backup de log de transações no SQL Server após a conclusão do posicionamento inicial, quando o banco de dados não estiver mais no estado Restaurando... na Instância Gerenciada de SQL do Azure. Em seguida, faça backups de log de transações do SQL Server regularmente para minimizar o crescimento excessivo do log enquanto o SQL Server estiver na função primária.
Se a Instância Gerenciada de SQL for primária, não será necessário executar nenhuma ação, pois a Instância Gerenciada de SQL do Azure realiza backups de log automaticamente.
Descartar um link
Se você quiser descartar o link, seja porque ele não é mais necessário ou porque está em um estado irreparável e precisa ser recriado, poderá fazer isso com o SSMS (SQL Server Management Studio).
Você pode excluir o link das seguintes opções de menu no Pesquisador de Objetos do SSMS, depois de se conectar à sua instância:
- Grupos de Disponibilidade Sempre Ativados>Grupos de Disponibilidade> Clique com o botão direito do mouse no nome do grupo de disponibilidade distribuído associado ao link >Excluir...
- Bancos de dados> Clique com o botão direito do mouse no banco de dados associado ao link >Link da Instância Gerenciada de SQL do Azure>Excluir...
Solucionar problemas
Se você encontrar uma mensagem de erro ao criar o link, selecione o erro para abrir uma janela com detalhes adicionais sobre o erro.
Se você encontrar um erro ao trabalhar com o link, o assistente do SSMS interromperá a execução na etapa que falhou e não poderá ser reiniciado novamente. Resolva o problema e, se necessário, limpe o ambiente para reverter ao estado original removendo o grupo de disponibilidade distribuída e o grupo de disponibilidade, se ele tiver sido criado durante a configuração do link. Em seguida, inicie o assistente novamente para recomeçar.
Para obter mais informações, analise solucionar problemas com o link.
Conteúdo relacionado
Para usar o link:
- Prepare environment for the Managed Instance link
- Configurar o link entre o SQL Server e a instância gerenciada de SQL com os scripts
- Fazer failover do link
- Migrar com o link
- Práticas recomendadas para manter o link
- Solucionar problemas com o link
Para saber mais sobre o link:
- Visão geral do Link da Instância Gerenciada
- Recuperação de desastre com link de instância gerenciada
Para outros cenários de replicação e migração, considere: