Fazer fail over de um link - Instância Gerenciada de SQL do Azure
Aplica-se a: ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Este artigo ensina como fazer fail over de um banco de dados vinculado entre o SQL Server e a Instância Gerenciada de SQL do Azure usando o SQL Server Management Studio (SSMS) ou o PowerShell.
Observação
- A configuração da Instância Gerenciada de SQL do Azure como sua primária inicial está atualmente em prévia e só tem suporte a partir do SQL Server 2022 CU10.
Pré-requisitos
Para fazer failover de bancos de dados para a réplica secundária por meio do link, é necessário ter os seguintes pré-requisitos:
- Uma assinatura ativa do Azure. Se você não tiver uma, crie uma conta gratuita.
- Versão com suporte do SQL Server com a atualização de serviço necessária instalada.
- Link configurado entre a réplica primária e secundária.
Parar carga de trabalho
Caso esteja pronto para fazer failover do seu banco de dados para a réplica secundária, primeiro interrompa todas as cargas de trabalho de aplicativos na réplica primária durante suas horas de manutenção. Isso permite que a replicação de banco de dados alcance a réplica secundária para que você possa fazer failover para ela sem perda de dados. É necessário garantir que os aplicativos não estejam realizando transações na réplica primária antes do failover.
Fazer failover de um banco de dados
Você pode fazer failover de um banco de dados vinculado usando o SQL Server Management Studio ou o PowerShell.
Utilize o assistente de Failover entre o SQL Server e a Instância Gerenciada no SSMS para fazer failover do banco de dados da réplica primária para a secundária.
É possível fazer um failover planejado a partir da réplica primária ou secundária. Para fazer um failover forçado, conecte-se à réplica secundária.
Cuidado
- Antes de fazer failover, interrompa a carga de trabalho no banco de dados de origem para permitir que o banco de dados replicado alcance completamente e fazer failover sem perda de dados. Se você estiver executando um failover forçado, os dados podem ser perdidos.
- O failover de um banco de dados no SQL Server 2019 e em versões anteriores quebra e remove o link entre as duas réplicas. Não é possível realizar o failback para a primária inicial.
- O failover de um banco de dados ao manter o vínculo com o SQL Server 2022 está, atualmente, em versão prévia.
Para fazer failover do banco de dados, siga estas etapas:
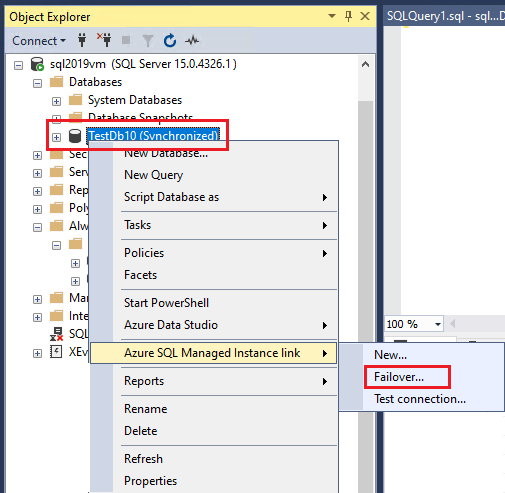
Abra o SSMS e conecte-se a qualquer réplica.
No Pesquisador de Objetos, clique com o botão direito do mouse no banco de dados replicado, passe o mouse sobre o link da Instância Gerenciada de SQL do Azure e selecione Fazer failover para abrir o assistente de Failover dentre o SQL Server e a Instância Gerenciada. Se houver vários links do mesmo banco de dados, é necessário expandir Grupos de Disponibilidade em Grupos de Disponibilidade Sempre Ativos no Pesquisador de Objetos e clicar com o botão direito no grupo de disponibilidade distribuído para o link desejado para fazer failover. Selecione Failover... para abrir o assistente de Failover entre o SQL Server e a Instância Gerenciada para o link específico.
Na página Introdução, selecione Avançar.
A página Escolher tipo de failover mostra detalhes sobre cada réplica, a função do banco de dados selecionado e os tipos de failover com suporte. Você pode iniciar o failover a partir de qualquer réplica. Caso haja a escolha de um failover forçado, é necessário marcar a caixa para indicar que entende que pode haver perda de dados em potencial. Selecione Avançar.
Observação
Se você estiver migrando para a Instância Gerenciada de SQL do Azure, escolha Recuperação planejada.
Na página Entrar no Azure e na Instância Remota:
- Selecione Iniciar sessão para fornecer suas credenciais e entrar em sua conta do Azure.
- Com base no Tipo de failover selecionado na página anterior, a opção Iniciar sessão funciona de forma diferente. Para uma recuperação planejada, entrar na instância remota (SQL Server ou Instância Gerenciada de SQL) é obrigatório. Para um failover forçado, entrar é opcional, pois há suporte para os dois cenários abaixo:
- Recuperação de desastre verdadeira: como a instância primária normalmente não está disponível durante um desastre real, o login não é possível e o usuário deve fazer failover para a instância secundária imediatamente, tornando-a a nova instância primária. Depois que a interrupção for resolvida, o link ficará em um estado inconsistente, pois ambas as réplicas estão agora na função principal (cenário de partição).
- Simulação de recuperação de desastre: não é aconselhável fazer simulações de recuperação de desastre com failover forçado, pois pode haver perda potencial de dados. No entanto, durante uma simulação, como a instância primária está disponível, há suporte para iniciar a sessão e você tem a opção de reverter funções para ambas as réplicas para evitar o cenário de partição.
Na página Operações Pós-Failover, as opções diferem entre o SQL Server 2022 e as versões anteriores e se você conseguiu ou não se conectar à instância primária.
- No SQL Server 2022, você pode optar por interromper a replicação entre as réplicas, o que descarta o link e o grupo de disponibilidade distribuída após a conclusão do failover. É possível manter o link e continuar replicando dados entre réplicas. Neste caso, deixe a caixa desmarcada. Também é possível optar por descartar o link. Neste caso, poderá marcar a caixa para descartar o grupo de disponibilidade se o tiver criado exclusivamente com a finalidade de replicar seu banco de dados para o Azure e não precisar mais dele. Marque as caixas que se ajustam ao seu cenário e selecione Avançar.
- Para o SQL Server 2019 e versões anteriores, a opção Remover o link é marcada por padrão, e você não pode desmarcá-la, pois o failover para a Instância Gerenciada de SQL interrompe a replicação, quebra o link e descarta o grupo de disponibilidade distribuída. Marque a caixa para indicar que você entende que o link será descartado e selecione Avançar.
- (Opcionalmente) Se você conseguiu entrar na instância do SQL Server na página anterior, também tem a opção de excluir o grupo de disponibilidade na instância do SQL Server após um failover forçado marcando a caixa na seção Limpeza.
Na página Resumo, revise as ações. Opcionalmente, selecione Script para gerar um script, permitindo que fazer failover facilmente do banco de dados usando o mesmo link no futuro. Quando estiver pronto para prosseguir com o failover do banco de dados, selecione Concluir.
Após a conclusão de todas as etapas, a página resultados mostrará as marcas de seleção ao lado das ações concluídas com êxito. Agora você pode fechar a janela.
Se você optar por manter o link para o SQL Server 2022, a secundária se tornará a nova primária, o link ainda estará ativo e você poderá fazer o failback para a secundária.
Se você estiver no SQL Server 2019 e em versões anteriores, ou se optar por descartar o link para o SQL Server 2022, o link será descartado e não existirá mais após a conclusão do failover. O banco de dados de origem e o banco de dados de destino em cada réplica podem executar uma carga de trabalho de leitura/escrita. Eles são completamente independentes.
Importante
Após o failover bem-sucedido para a Instância Gerenciada de SQL, reencaminhe manualmente a cadeia de conexão da aplicação para o FQDN da Instância Gerenciada de SQL para concluir o processo de migração ou falha e continuar executando no Azure.
Ver banco de dados após failover
Para o SQL Server 2022, se você optar por manter o link, poderá verificar se o grupo de disponibilidade distribuída existe em Grupos de Disponibilidade no Pesquisador de Objetos no SQL Server Management Studio.
Se você descartou o link durante o failover, poderá usar o Pesquisador de Objetos para confirmar que o grupo de disponibilidade distribuída não existe mais. Se você optar por manter o grupo de disponibilidade, o banco de dados ainda será Sincronizado.
Limpar os grupos de disponibilidade
Como o failover com o SQL Server 2022 não quebra o link, você pode manter o link após o failover, o que deixa o grupo de disponibilidade e o grupo de disponibilidade distribuída ativos. Nenhuma outra ação é necessária.
No entanto, descartar o link apenas descarta o grupo de disponibilidade distribuída e deixa o grupo de disponibilidade ativo. Você pode decidir manter o grupo de disponibilidade ou descartá-lo.
Se você decidir descartar seu grupo de disponibilidade, substitua o seguinte valor e execute o código de T-SQL de exemplo:
<AGName>com o nome do grupo de disponibilidade no SQL Server (usado para criar o link).
-- Run on SQL Server
USE MASTER
GO
DROP AVAILABILITY GROUP <AGName>
GO
Conteúdo relacionado
Para obter mais informações sobre o recurso de link, veja os seguintes artigos:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de