Este artigo explica como você pode implementar cenários de mecanismo de ingestão independente de dados usando uma combinação de PowerApps, Aplicativos Lógicos do Azure e tarefas de cópia controladas por metadados no Azure Data Factory.
Os cenários de mecanismo de ingestão independente de dados normalmente se concentram em permitir que usuários não técnicos (engenheiros não relacionados a dados) publiquem ativos de dados em um Data Lake para processamento adicional. Para implementar esse cenário, você deve ter recursos de integração que permitem o seguinte:
Registro de ativos de dados
Provisionamento de fluxo de trabalho e captura de metadados
Agendamento de ingestão
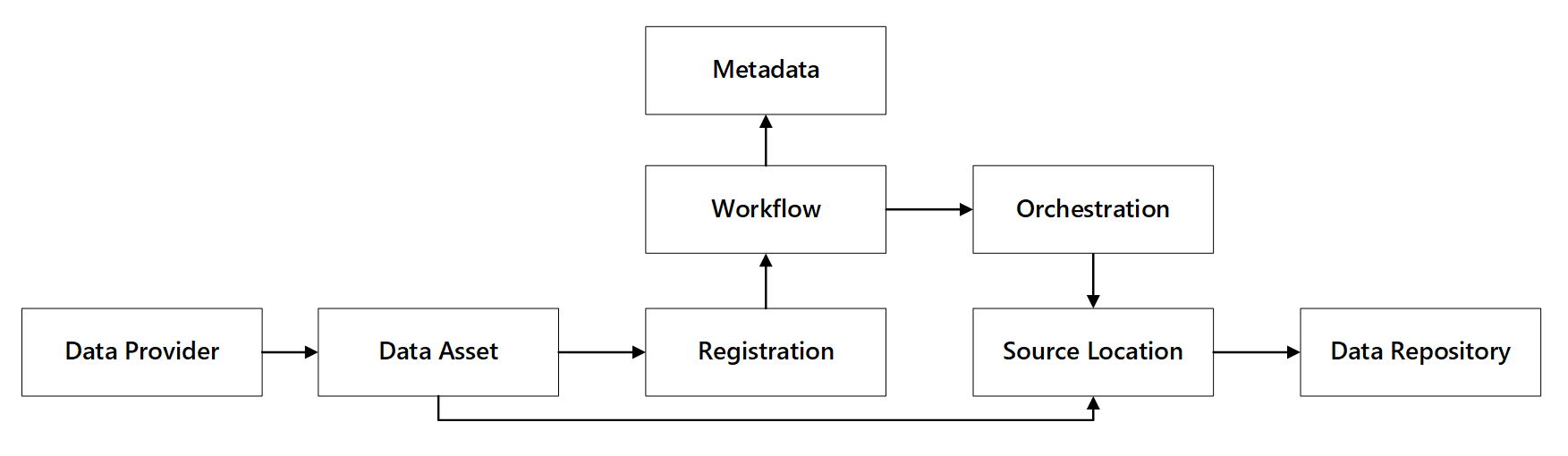
Você pode ver como esses recursos interagem:
Figura 1: interações de recursos de registro de dados.
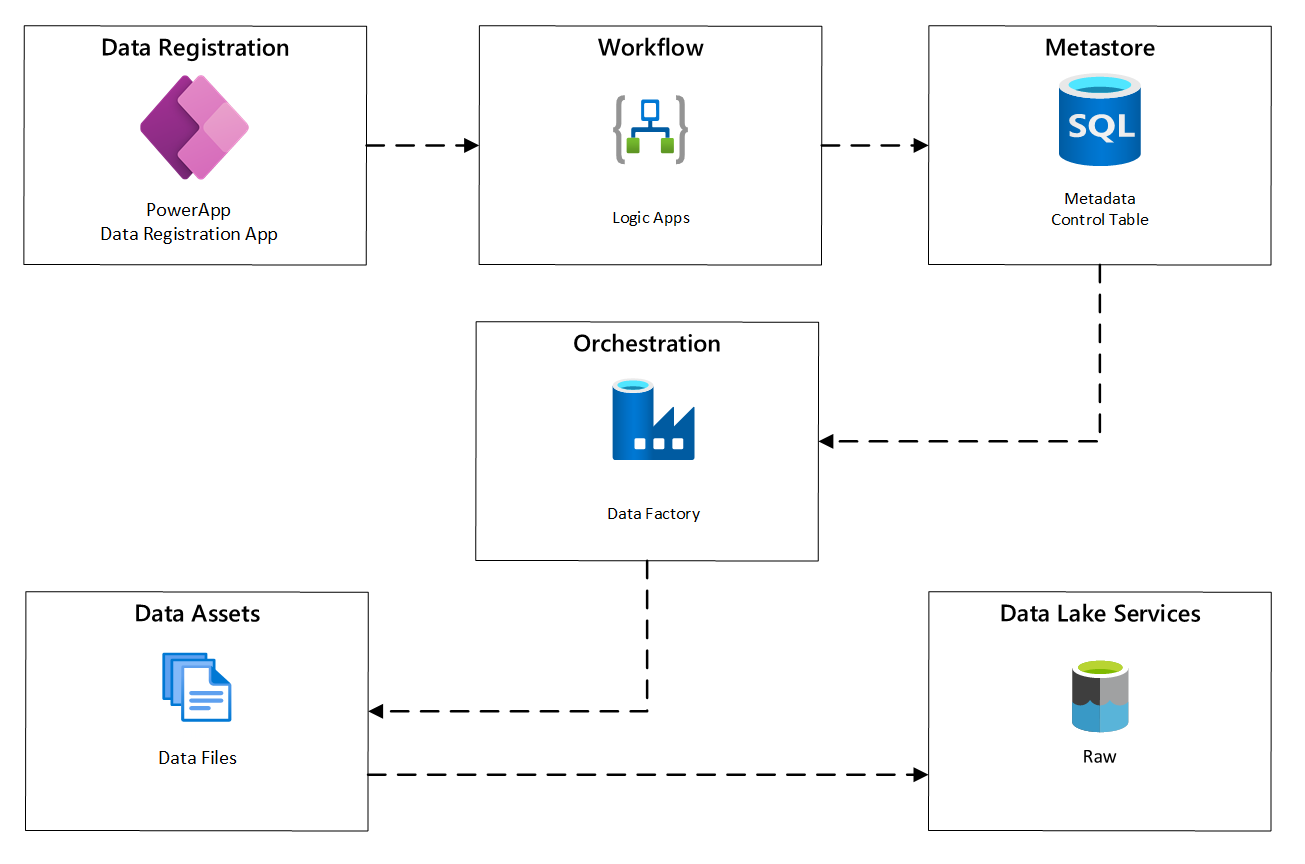
O diagrama a seguir mostra como implementar esse processo usando uma combinação de serviços do Azure:
Figura 2: processo de ingestão automatizado.
Registro de ativos de dados
Para fornecer os metadados usados para impulsionar a ingestão automatizada, você precisa do registro de ativos de dados. As informações capturadas contêm:
Informações técnicas: Nome do ativo de dados, sistema de origem, tipo, formato e frequência.
Informações de governança: proprietário, stewards, visibilidade (para fins de descoberta) e sensibilidade.
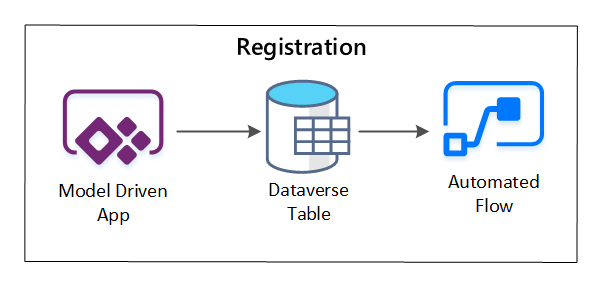
O PowerApps é usado para capturar metadados que descrevem cada ativo de dados. Use um aplicativo controlado por modelo para inserir as informações persistidas em uma tabela personalizada do Dataverse. Quando os metadados são criados ou atualizados no Dataverse, ele dispara um fluxo de nuvem automatizado que invoca etapas de processamento adicionais.
Figura 3: registro de ativos de dados.
Provisionamento de fluxo de trabalho/captura de metadados
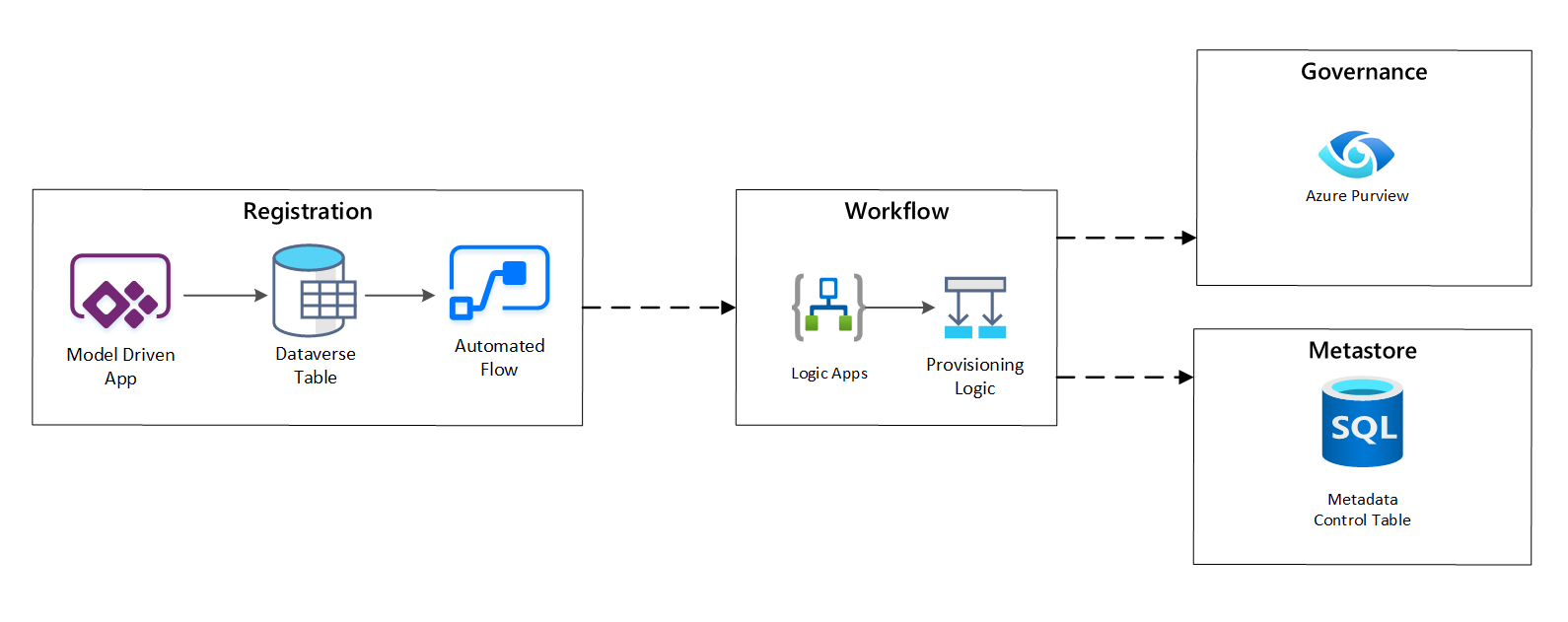
Na fase de provisionamento de fluxo de trabalho, você validará e persistirá os dados coletados na fase de registro para o metastore. As etapas de validação técnica e comercial são executadas, incluindo:
Validação do feed de dados de entrada
Gatilho de fluxo de trabalho de aprovação
Processamento lógico para disparar a persistência de metadados para o repositório de metadados
Auditoria de atividades
Figura 4: fluxo de trabalho de registro.
Depois que as solicitações de ingestão são aprovadas, o fluxo de trabalho usa a API REST do Azure Purview para inserir as fontes no Azure Purview.
Fluxo de trabalho detalhado para integrar produtos de dados
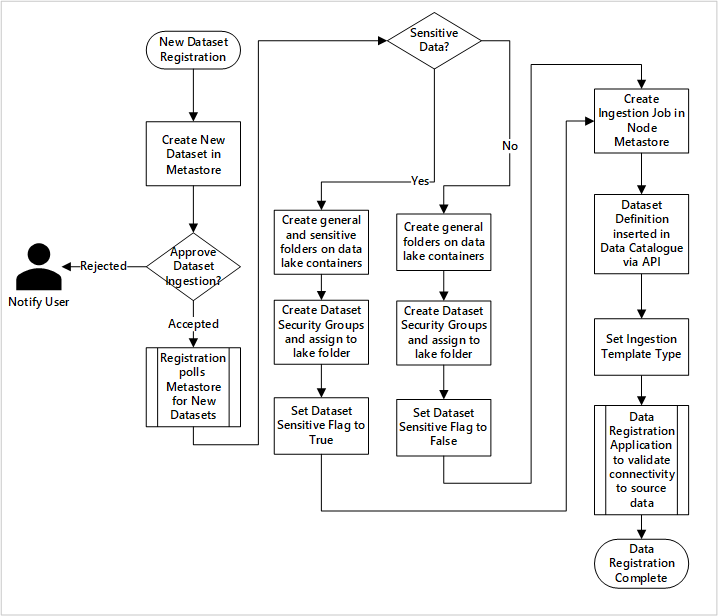
Figura 5: como novos conjuntos de dados são ingeridos (automatizados).
A Figura 5 mostra o processo de registro detalhado para automatizar a ingestão de novas fontes de dados:
Os detalhes da fonte são registrados, incluindo ambientes de produção e do data factory.
As restrições de forma, formato e qualidade de dados são capturadas.
As equipes de aplicação de dados devem indicar se os dados são confidenciais (dados pessoais) Essa classificação conduz o processo em que as pastas do data lake são criadas para ingerir dados brutos, enriquecidos e coletados. A fonte nomeia dados brutos e enriquecidos e o produto de dados nomeia dados coletados.
A entidade de serviço e os grupos de segurança são criados para ingerir e dar acesso a um conjunto de dados.
Um trabalho de ingestão é criado no metastore do Data Factory da zona de destino de dados.
Uma API insere a definição de dados no Azure Purview.
Sujeito à validação da fonte de dados e à aprovação pela equipe de operações, os detalhes são publicados em um metastore do Data Factory.
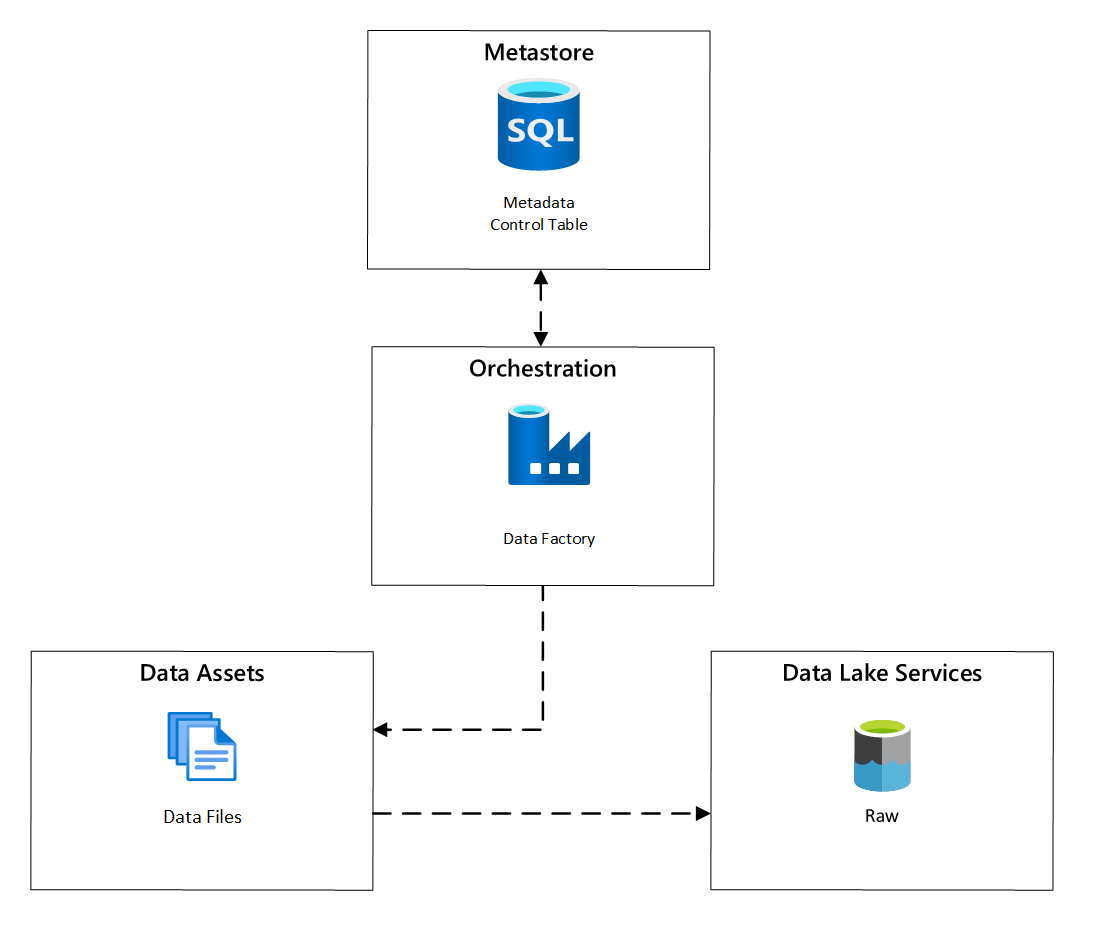
Agendamento de ingestão
No Azure Data Factory, as tarefas de cópia controladas por metadados fornecem a funcionalidade que permite que os pipelines de orquestração sejam controlados por linhas em uma Tabela de Controle armazenada no Banco de Dados SQL do Azure. Você pode usar a Ferramenta Copiar Dados para pré-criar pipelines controlados por metadados.
Depois que um pipeline é criado, o fluxo de trabalho de provisionamento adiciona entradas à Tabela de Controle para dar suporte à ingestão de origens identificadas pelos metadados de registro de ativos de dados. Os pipelines do Azure Data Factory e o Banco de Dados SQL do Azure que contém o metastore da Tabela de Controle podem existir em cada zona de destino de dados, para criar novas fontes de dados e ingeri-las nas zonas de destino de dados.
Figura 6: agendamento de ingestão de ativos de dados.
Fluxo de trabalho detalhado para ingerir novas fontes de dados
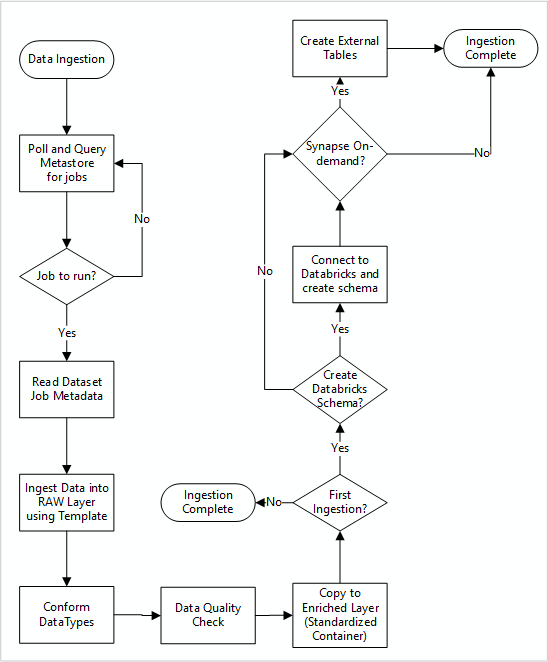
O diagrama a seguir mostra como extrair as fontes de dados registradas em um metastore do Banco de Dados SQL do Data Factory e como os dados são ingeridos primeiro:
O pipeline mestre de ingestão do Data Factory lê as configurações de um Banco de Dados SQL do Data Factory e é executado iterativamente com os parâmetros corretos. Os dados percorrem da fonte para a camada bruta no Azure Data Lake com pouca ou nenhuma alteração. A forma dos dados é validada com base no metastore do Data Factory. Os formatos de arquivo são convertidos nos formatos Apache Parquet ou Avro e, em seguida, copiados para a camada enriquecida.
Os dados que estão sendo ingeridos se conectam a um workspace de engenharia e ciência de dados do Azure Databricks, e uma definição de dados é criada no metastore do Apache Hive da zona de destino de dados.
Se você precisar usar um pool de SQL sem servidor do Azure Synapse para expor os dados, a solução personalizada deve criar exibições sobre os dados no data lake.
Se você precisar de criptografia no nível de linha ou de coluna, a solução personalizada deve colocar os dados no data lake e ingerir os dados diretamente nas tabelas internas nos pools de SQL e configurar a segurança apropriada na computação dos pools de SQL.
Metadados capturados
Ao usar a ingestão de dados automatizada, você pode consultar os metadados associados e criar painéis para:
Acompanhar os trabalhos e os carimbos de data/hora de carregamento de dados mais recentes para produtos de dados relacionados às funções.
Acompanhar os produtos de dados disponíveis.
Aumente os volumes de dados.
Obtenha atualizações em tempo real sobre falhas de trabalho.
Os metadados operacionais podem ser usados para rastrear:
Trabalhos, etapas de trabalho e suas dependências.
Histórico de desempenho e desempenho do trabalho.
Aumento do volume de dados.
Falhas de trabalho.
Alterações de metadados de origem.
Funções de negócios que dependem dos produtos de dados.
Usar a API REST do Azure Purview para descobrir dados
As APIs REST do Azure Purview devem ser usadas para registrar dados durante a ingestão inicial. Você pode usar as APIs para enviar dados ao catálogo de dados logo após a ingestão.
Demonstre a compreensão das tarefas comuns de engenharia de dados para implementar e gerenciar cargas de trabalho de engenharia de dados no Microsoft Azure, usando vários serviços do Azure.