Zonas de destino de dados
As zonas de destino de dados são conectadas à zona de destino de gerenciamento de dados pelo Emparelhamento VNET (rede virtual). Cada zona de destino de dados é considerada uma zona de destino relacionada à arquitetura da zona de destino do Azure.
Importante
Antes de provisionar uma zona de destino de dados, tenha um modelo operacional de DevOps e de CI/CD em vigor e uma zona de destino de gerenciamento de dados implantada.
Cada zona de destino de dados tem várias camadas que permitem agilidade nas integrações de dados de serviço e nos produtos de dados contidos neles. É possível implantar uma nova zona de destino de dados com um conjunto padrão de serviços que permita que a zona de destino de dados comece a ingerir e analisar dados.
Sua assinatura do Azure associada à zona de destino de dados tem a seguinte estrutura:
Observação
Um aplicativo de dados produz um ou mais produtos de dados.
Arquitetura da zona de destino de dados
A arquitetura da zona de destino de dados ilustra as camadas, os respectivos grupos de recursos e os serviços que cada grupo de recursos contém. A arquitetura também fornece uma visão geral de todos os grupos e as funções associadas à zona de destino de dados, além da extensão do acesso dela aos planos de dados e ao painel de controle.

Dica
Antes de implantar uma zona de destino de dados, considere o número de zonas de destino de dados iniciais que deseja implantar.
Use essa arquitetura como um ponto de partida. Baixe o arquivo Visio e modifique-o para ajustá-lo aos seus requisitos técnicos e comerciais específicos ao planejar a implementação da zona de destino de dados.
Camada de serviços principais
A camada de serviços principais inclui todos os serviços necessários para habilitar sua zona de destino de dados no contexto da análise em escala de nuvem. A tabela a seguir lista os grupos de recursos que fornecem o pacote padrão de serviços disponíveis em cada zona de destino de dados implantada.
| Grupo de recursos | Obrigatório | Descrição |
|---|---|---|
network-rg |
Sim | Rede |
databricks-monitoring-rg |
Opcional | Monitoramento de workspaces do Azure Databricks |
hive-rg |
Opcional | Metastore do Hive para Azure Databricks |
storage-rg |
Sim | Serviços de data lakes |
external-data-rg |
Sim | Armazenamento de ingestão de upload |
runtimes-rg |
Sim | Runtimes de integração compartilhada |
mgmt-rg |
Sim | Agentes de CI/CD |
metadata-ingestion-rg |
Opcional | Ingestão independente de dados |
databricks-monitoring-rg |
Opcional | Workspace do Log Analytics para workspaces do Databricks na zona de destino |
shared-synapse-rg |
Opcional | Azure Synapse compartilhado |
shared-databricks-rg |
Opcional | Workspace do Azure Databricks compartilhado |
Rede
O grupo de recursos de rede contém componentes básicos, incluindo o Observador de Rede do Azure, os NSGs (grupos de segurança de rede) e a rede virtual. Todos esses serviços são implantados em um único grupo de recursos.
A rede virtual da zona de destino de dados é emparelhada automaticamente com a VNet da zona de destino de gerenciamento de dados e com a VNet da sua assinatura de conectividade.
Monitoramento de workspaces do Azure Databricks
Esse grupo de recursos é opcional e só é implantado com o Azure Databricks.
O padrão de zona de destino do Azure recomenda que você envie todos os logs para um workspace central do Log Analytics. No entanto, cada zona de destino de dados também inclui um grupo de recursos de monitoramento para capturar os logs do Spark por meio do Databricks. Cada grupo de recursos contém um workspace compartilhado do Log Analytics e um Azure Key Vault para armazenar as chaves do Log Analytics.
Importante
Use apenas o workspace do Log Analytics no seu grupo de recursos de monitoramento do Databricks para capturar os logs do Spark no Azure Databricks.
Para obter mais informações, consulte Monitorar o Azure Databricks.
Metastore do Hive para Azure Databricks
Esse grupo de recursos é opcional e só deve ser implantado com o Azure Databricks.
O metastore do Hive para o Azure Databricks provisiona um banco de dados do Banco de Dados do Azure para MySQL e um cofre de chaves. Todos os workspaces do Azure Databricks na zona de destino de dados usam esse metastore como o metastore externo do Apache Hive.
Para obter mais informações, confira Metastore externo do Apache Hive.
Serviços de data lake
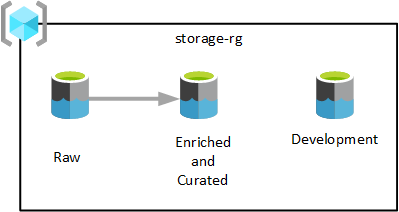
Conforme mostrado no diagrama anterior, três contas do Azure Data Lake Storage Gen2 são provisionadas em um só grupo de recursos dos serviços de data lake. Os dados transformados em diferentes fases são salvos em um dos data lakes da zona de destino de dados. Os dados ficam disponíveis para consumo pelas suas equipes de análise, de ciência de dados e de visualização.
As camadas do data lake usam uma terminologia diferente conforme a tecnologia e o fornecedor. Esta tabela fornece diretrizes de como aplicar os termos à análise em escala de nuvem:
| Análise em escala de nuvem | Delta Lake | Outros termos | Descrição |
|---|---|---|---|
| Bruta | Bronze | Destino e conformidade | Tabelas de ingestão |
| Enriquecido | Prata | Zona de padronização | Tabelas refinadas. Entidade completa armazenada, conjuntos de registros prontos para consumo nos sistemas de registro. |
| Selecionado | Ouro | Zona de produto | Recurso ou tabelas agregadas. Zona primária para aplicativos, equipes e usuários consumirem produtos de dados. |
| Desenvolvimento | -- | Zona de desenvolvimento | Local para engenheiros de dados e cientistas, compreendendo uma área restrita de análise e uma zona de desenvolvimento de produtos. |
Observação
No diagrama anterior, cada zona de destino de dados tem três data lakes. No entanto, dependendo dos seus requisitos, o ideal é consolidar suas camadas brutas, enriquecidas e coletadas em uma só conta de armazenamento e manter outra conta de armazenamento chamada 'desenvolvimento' para que os consumidores de dados tragam outros produtos de dados úteis.
Para saber mais, veja:
- Visão geral do Azure Data Lake Storage para análise de escala de nuvem
- Padronização de dados
- Provisionar contas do Azure Data Lake Storage Gen2 para cada zona de destino de dados
- Considerações importantes para o Azure Data Lake Armazenamento
- Configurações de data lake e controle de acesso no Armazenamento do Azure Data Lake
Armazenamento de ingestão de upload
Os editores de dados de terceiros precisam colocar dados na sua plataforma para que as suas equipes de aplicativos de dados possam extraí-los para os respectivos data lakes. Como será visto no diagrama a seguir, o grupo de recursos de armazenamento de ingestão de upload permite provisionar repositórios de blobs para terceiros.
Suas equipes de aplicativos de dados solicitam esses blobs de armazenamento. Em seguida, as solicitações são aprovadas pela equipe de operações da zona de destino de dados. Os dados devem ser removidos do blob de armazenamento de origem depois de serem extraídos do blob de armazenamento em dados brutos.
Importante
Como o provisionamento de blobs do Armazenamento do Azure ocorre conforme a necessidade, recomendamos implantar inicialmente um grupo de recursos de serviços de armazenamento vazio em cada zona de destino de dados.
Runtimes de integração compartilhada
Implante uma máquina virtual com tempos de execução de integração auto-hospedados em sua zona de aterrissagem de dados. Hospede-o no grupo de recursos de integração compartilhada. Essa implantação permite que você integre rapidamente produtos de dados à zona de destino de dados.
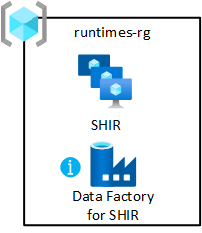
Para habilitar o grupo de recursos:
- Crie, pelo menos, um Azure Data Factory no grupo de recursos de integração compartilhada da zona de destino de dados. Use-o somente para vincular o runtime de integração auto-hospedada compartilhado, não para pipelines de dados.
- Crie e configure um tempo de execução de integração auto-hospedado na máquina virtual.
- Associe o tempo de execução de integração auto-hospedado às fábricas de dados do Azure na(s) sua(s) zona(s) de aterrissagem de dados.
- Configure a Automação do Azure para atualizar periodicamente o runtime de integração auto-hospedada.
Observação
A implantação acima fornece uma única implantação de máquina virtual com tempos de execução de integração auto-hospedados. Você pode associar um runtime de integração auto-hospedada a vários computadores locais ou máquinas virtuais no Azure. Esses computadores são chamados de nós. Você pode ter até quatro nós associados a um runtime de integração auto-hospedada. Os benefícios de ter vários nós nos computadores locais com um gateway instalado para um gateway lógico são:
- Disponibilidade superior do runtime de integração auto-hospedada para que ele não seja o único ponto de falha na sua solução de Big Data ou integração de dados de nuvem. Essa disponibilidade ajuda a garantir a continuidade quando você usa até quatro nós.
- Desempenho e taxa de transferência aprimorados durante a movimentação de dados entre os armazenamentos de dados de nuvem e locais. Obtenha mais informações sobre comparações de desempenho.
Para associar vários nós, instale o software do runtime de integração auto-hospedada no Centro de Download. A seguir, registre-o usando uma das chaves de autenticação obtidas do cmdlet New-AzDataFactoryV2IntegrationRuntimeKey, conforme descrito no tutorial.
Outras informações são detalhadas em Alta disponibilidade e escalabilidade do Azure Datafactory.
Importante
Implante os runtimes de integração compartilhada o mais próximo possível da fonte de dados. A implantação deles não restringe a implantação dos runtimes de integração em uma zona de destino de dados ou em nuvens de terceiros. Em vez disso, ela fornece um fallback para fontes de dados nativas de nuvem na região.
Agentes de CI/CD
Os agentes de CI/CD ajudam você a implantar aplicativos de dados e alterações na zona de destino de dados.
Para obter mais informações, confira Agente de pipeline do Azure.
Ingestão independente de dados
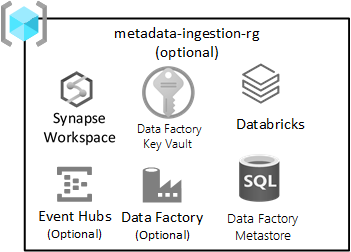
Esse grupo de recursos é opcional e não proíbe a implantação da zona de destino.
Ele se aplica se você tem (ou está desenvolvendo) um mecanismo de ingestão independente de dados para ingerir dados automaticamente com base no registro de metadados (incluindo cadeias de conexão, caminho para cópia bidirecional de dados e agendamento de ingestão). O grupo de recursos de ingestão e processamento tem serviços essenciais para esse tipo de estrutura.
Implante uma instância do Banco de Dados SQL do Azure para armazenar os metadados usados pelo Azure Data Factory. Provisione um Azure Key Vault para armazenar os segredos relacionados aos serviços de ingestão automatizados. Esses segredos podem incluir:
- Credenciais de metastore do Azure Data Factory
- Credenciais da entidade de serviço para o processo automatizado de ingestão
Para obter mais informações, confira Como as estruturas de ingestão automatizadas dão suporte à análise em escala de nuvem no Azure.
Os serviços incluídos neste grupo de recursos incluem:
| Serviço | Obrigatório | Diretrizes |
|---|---|---|
| Fábrica de dados do Azure | Sim | O data factory do Azure é o seu mecanismo de orquestração para a ingestão independente de dados. |
| Azure SQL DB | Sim | O BD SQL do Azure é o metastore para o Azure Data Factory. |
| Hubs de Eventos ou Hub IoT | Opcional | Os Hubs de Eventos ou o hub IoT pode fornecer streaming em tempo real para os Hubs de Eventos, além de processamento em lote e streaming por meio de um workspace de engenharia do Databricks. |
| Azure Databricks | Opcional | Você pode implantar o Azure Databricks ou o Azure Synapse Spark para uso com o mecanismo de ingestão independente de dados. |
| Azure Synapse | Opcional | Você pode implantar o Azure Databricks ou o Azure Synapse Spark para usá-lo com o mecanismo de ingestão independente de dados. |
Databricks compartilhado
Esse grupo de recursos é opcional e só é implantado com o Azure Databricks. Todos na zona de destino de dados podem usar um workspace do Databricks.
O Azure Databricks é um consumidor essencial do serviço Azure Data Lake Storage. As operações de arquivo atômico são otimizadas para os mecanismos de análise do Spark. A otimização acelera a conclusão dos trabalhos do Spark emitidos pelo serviço Azure Databricks.
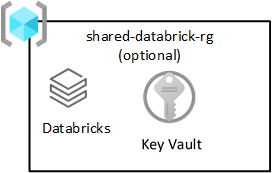
Importante
Um workspace do Azure Databricks chamado workspace do Azure Databricks (análise) é provisionado para todos os cientistas de dados e o DataOps, conforme mostrado no grupo de recursos de produtos compartilhados.
Você pode configurar esse espaço de trabalho para se conectar ao Azure Data Lake usando o controle de acesso de passagem ou tabela do Microsoft Entra. Dependendo do seu caso de uso, configure o acesso condicional como outra medida de segurança.
Siga as melhores práticas da análise em escala de nuvem para integrar o Azure Databricks:
- Proteger o acesso ao Azure Data Lake Gen2 por meio do Azure Databricks
- Melhores práticas do Azure Databricks
O padrão de zona de destino do Azure recomenda que você envie todos os logs para um workspace central do Log Analytics. No entanto, cada zona de destino de dados também contém um grupo de recursos de monitoramento para capturar os logs do Spark por meio do Databricks.
Azure Synapse Analytics compartilhado
Esse grupo de recursos é opcional.
Durante a configuração inicial de uma zona de destino de dados, um workspace individual do Azure Synapse Analytics é implantado para uso por todos os cientistas e analistas de dados no grupo de recursos de produtos compartilhados.
Você pode configurar mais workspaces do Azure Synapse para produtos de dados se o gerenciamento de custos e de recarga forem necessários. As equipes de aplicativos de dados podem usar os workspaces dedicados do Azure Synapse Analytics para criar pools dedicados do Banco de Dados SQL do Azure como um armazenamento de dados de leitura usado pela camada de visualização.
Importante
Evite o uso do seu workspace compartilhado do Azure Synapse para a criação de produtos de dados bloqueando o workspace para permitir apenas consultas SQL sob demanda. Ele existe apenas para fins exploratórios.
Aplicativo de dados
Cada zona de destino de dados pode ter vários produtos de dados. Você pode criar esses produtos de dados ingerindo dados da fonte. Também é possível criar produtos de dados por meio de outros produtos de dados na mesma zona de destino de dados ou em outras zonas de destino de dados. A criação de produtos de dados está sujeita à aprovação do administrador de dados.
Grupo de recursos de produto de dados
O produto do grupo de recursos de produto de dados inclui todos os serviços necessários para compor esse produto de dados. Por exemplo, um Banco de Dados do Azure é necessário para o MySQL, que é usado por uma ferramenta de visualização. Os dados precisam ser ingeridos e transformados antes de serem inseridos nesse banco de dados MySQL. Nesse caso, você pode implantar o Banco de Dados do Azure para MySQL e um Azure Data Factory no grupo de recursos de produto de dados.
Dica
Se você optar por não implementar um mecanismo independente de dados para ingestão única de fontes operacionais ou se as conexões complexas não forem facilitadas no mecanismo independente de dados, crie um aplicativo de dados alinhado à fonte. Para saber mais, confira Aplicativos de dados (alinhado à origem)
Para saber como integrar produtos de dados, confira Produtos de dados da análise em escala de nuvem no Azure.
Visualização
Um grupo de recursos de visualização vazio é criado para cada zona de destino de dados. Preencha esse grupo de recursos com os serviços necessários para implementar sua solução de visualização. O uso da VNet existente permite que a sua solução se conecte aos produtos de dados.
Esse grupo de recursos pode hospedar máquinas virtuais para serviços de visualização de terceiros.
Dica
Devido aos custos de licenciamento, pode ser mais econômico implantar produtos de visualização de terceiros na zona de destino de gerenciamento de dados e conectar os produtos entre as zonas de destino de dados para recuperar dados.
Próximas etapas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de