Treinar seu modelo de compreensão da linguagem coloquial
Depois de concluir a rotulagem dos enunciados, você poderá começar a treinar um modelo. O treinamento é o processo no qual o modelo aprende com os enunciados rotulados.
Para treinar um modelo, inicie um trabalho de treinamento. Somente trabalhos concluídos com êxito criam um modelo. Os trabalhos de treinamento expiram após sete dias, e, após esse prazo, você não poderá recuperar os detalhes do trabalho. Se o trabalho de treinamento foi concluído com êxito e um modelo foi criado, ele não será afetado pela expiração do trabalho. Você só pode ter um trabalho de treinamento em execução de cada vez e não pode iniciar outros trabalhos no mesmo projeto.
Os tempos de treinamento podem estar em qualquer lugar de alguns segundos ao lidar com projetos simples, até algumas horas quando você atinge o imite máximo de declarações.
A avaliação do modelo é disparada automaticamente depois que o treinamento é concluído com êxito. O processo de avaliação começa usando o modelo treinado para executar previsões nos enunciados no conjunto de testes e compara os resultados previstos com os rótulos fornecidos (que estabelecem uma linha de base de verdade).
Pré-requisitos
- Um projeto criado com sucesso com uma conta de armazenamento de blobs do Azure configurada
- Declarações rotuladas
Balancear dados de treinamento
Você deve tentar manter seu esquema bem equilibrado quando se trata de dados de treinamento. Incluir grandes quantidades de uma intenção e muito poucas de outra resultará em um modelo fortemente tendencioso em relação a intenções específicas.
Para resolver isso, talvez seja necessário reduzir o tamanho do conjunto de treinamento ou adicioná-lo. O downsampling pode ser feito por:
- Livrar-se de uma determinada porcentagem dos dados de treinamento aleatoriamente.
- De maneira mais sistemática, analisando o conjunto de dados e removendo entradas duplicadas superrepresentadas.
Você também pode adicionar ao conjunto de treinamento selecionando Sugerir enunciados na guia Rotulagem de dados no Language Studio. A Compreensão da Linguagem Coloquial enviará uma chamada ao OpenAI do Azure para gerar enunciados semelhantes.

Você também deve procurar por "padrões" não intencionais no conjunto de treinamento. Por exemplo, se o conjunto de treinamento para uma determinada intenção for todo minúsculo ou começar com uma frase específica. Nesses casos, o modelo que você treina pode aprender esses vieses não intencionais no conjunto de treinamento, em vez de ser capaz de generalizar.
É recomendável introduzir a diversidade de maiúsculas e minúsculas no conjunto de treinamento. Se o modelo for esperado para lidar com variações, certifique-se de ter um conjunto de treinamento que também reflita essa diversidade. Por exemplo, inclua alguns enunciados em maiúsculas e minúsculas e outros em letras minúsculas.
Divisão de dados
Antes de iniciar o processo de treinamento, os enunciados rotulados no projeto são divididos em um conjunto de treinamento e um conjunto de teste. Cada um deles atua em uma função diferente. O conjunto de treinamentos é usado no treinamento do modelo, esse é o conjunto com o qual o modelo aprende os enunciados rotulados. O conjunto de teste é um conjunto cego que não é introduzido ao modelo durante o treinamento, mas somente durante a avaliação.
Depois que o modelo é treinado com êxito, ele pode ser usado para fazer previsões nos enunciados do conjunto de testes. Essas previsões são usadas para calcular as métricas de avaliação. É recomendável garantir que todas as intenções e entidades sejam representadas adequadamente nos conjuntos de treinamentos e testes.
A compreensão da linguagem coloquial dá suporte a dois métodos de divisão de dados:
- Dividir automaticamente o conjunto de testes nos dados de treinamento: o sistema dividirá os dados marcados entre os conjuntos de treinamentos e testes, de acordo com os percentuais escolhidos. A divisão percentual recomendada é de 80% para treinamento e 20% para teste.
Observação
Se você escolher a opção Dividir automaticamente o conjunto de testes nos dados de treinamento, somente os dados atribuídos ao conjunto de treinamentos serão divididos de acordo com os percentuais fornecidos.
- Usar uma divisão manual dos dados de treinamento e de teste: esse método permite que os usuários definam quais enunciados devem pertencer a qual conjunto. Essa etapa será habilitada somente se você tiver adicionado enunciados ao conjunto de testes durante a rotulagem.
Modos de treinamento
A CLU dá suporte a dois modos de treinamento de modelos
O treinamento padrão usa algoritmos de aprendizado de máquina rápidos para treinar os modelos de maneira relativamente rápida. No momento, ele só está disponível para inglês e está desabilitado para qualquer projeto que não use inglês dos EUA ou do Reino Unido como idioma principal. Essa opção de treinamento é gratuita. O treinamento padrão permite adicionar enunciados e testá-los rapidamente sem nenhum custo. As pontuações de avaliação mostradas devem guiá-lo sobre onde fazer alterações no projeto e adicionar mais enunciados. Depois de iterar algumas vezes e fazer melhorias incrementais, você pode considerar o uso do treinamento avançado para treinar outra versão do modelo.
O treinamento avançado usa as mais recentes tecnologias de aprendizado de máquina para personalizar modelos com seus dados. A expectativa é de que ele mostre melhores pontuações de desempenho para seus modelos e permita que você use as funcionalidades multilíngues da CLU também. O treinamento avançado tem um preço diferente. Consulte as informações de preços para obter detalhes.
Use as pontuações de avaliação para orientar suas decisões. Pode haver ocasiões em que um exemplo específico seja previsto incorretamente no treinamento avançado, o oposto de quando usou o modo de treinamento padrão. No entanto, se os resultados gerais da avaliação forem melhores usando o avançado, ele será o modelo final recomendado. Se esse não for o caso e você não quiser usar funcionalidades multilíngues, poderá continuar a usar o modelo treinado com o modo padrão.
Observação
Você perceberá uma diferença nos comportamentos das pontuações de confiança de intenção entre os modos de treinamento, pois cada algoritmo calibra suas pontuações de forma diferente.
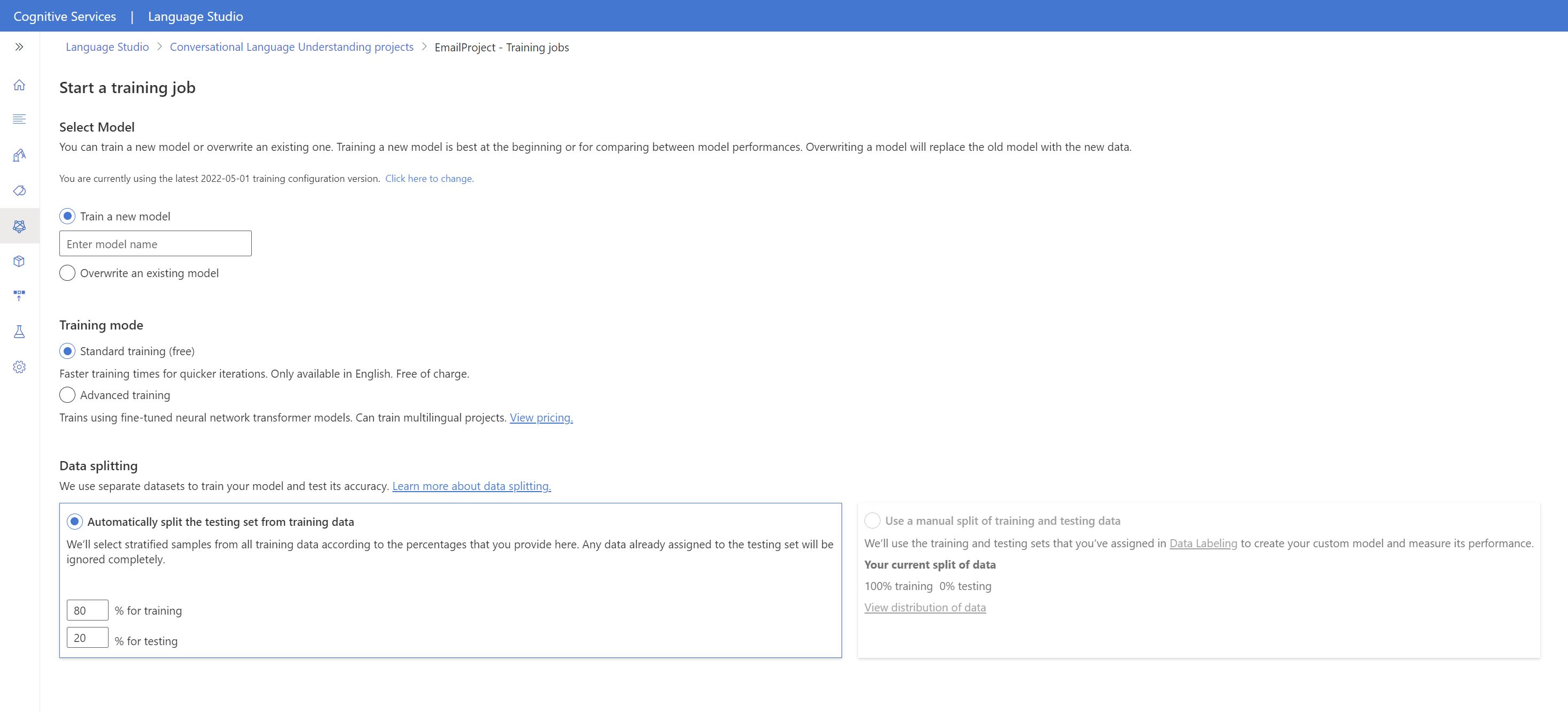
Treinar um modelo
Para começar a treinar o modelo no Language Studio:
Selecione Testar modelo no menu do lado esquerdo.
Selecione Iniciar um trabalho de treinamento no menu superior.
Selecione Treinar um novo modelo e insira um novo nome do modelo na caixa de texto. Caso contrário, para substituir um modelo existente por um modelo treinado nos novos dados, selecione Substituir um modelo existente e selecione um modelo existente. A substituição de um modelo treinado é irreversível, mas não afetará os modelos implantados até que você implante o novo modelo.
Selecione o modo de treinamento. Você pode escolher Treinamento padrão para um treinamento mais rápido, mas ele só está disponível em inglês. Ou você pode escolher Treinamento avançado que tem suporte para outros idiomas e projetos multilíngues, mas envolve tempos de treinamento mais longos. Saiba mais sobre os modos de treinamento.
Selecione o método divisão de dados. É possível optar por Dividir automaticamente o conjunto de teste dos dados de treinamento, em que o sistema dividirá os enunciados entre os conjuntos de treinamento e de teste, conforme os percentuais especificados. Ou você pode Usar uma divisão manual dos dados de treinamento e de teste. Essa opção será habilitada somente se você tiver adicionado enunciados ao conjunto de teste quando rotulou seus enunciados.
Selecione o botão Treinar.
Selecione a ID do trabalho de treinamento na lista. Um painel lateral será exibido para permitir a verificação do progresso do treinamento, do status do trabalho e de outros detalhes do trabalho.
Observação
- Somente os trabalhos de treinamento concluídos com êxito vão gerar modelos.
- O treinamento pode levar entre alguns minutos e algumas horas, de acordo com a contagem dos dados rotulados.
- É possível ter um trabalho de treinamento em execução por vez. Não é possível iniciar outros trabalhos de treinamento no mesmo projeto até que o trabalho em execução seja concluído.
- O aprendizado de máquina usado para treinar modelos é atualizado regularmente. Para treinar em uma versão de configuração anterior, selecione Selecione aqui para alterar na página Iniciar um trabalho de treinamento e escolha uma versão anterior.

Cancelar o trabalho de treinamento
Para cancelar um trabalho de treinamento no Language Studio
- Na página Treinar um modelo, selecione o trabalho de treinamento que deseja cancelar e clique em Cancelar no menu superior.