Confiabilidade no Gateway de Comunicações do Azure
O Gateway de Comunicações do Azure garante que seu serviço seja confiável usando mecanismos de redundância do Azure e comportamento de repetição específico do SIP. Sua rede deve atender a requisitos específicos para garantir a disponibilidade do serviço.
Modelo de redundância do Gateway de Comunicações do Azure
As implantações do Gateway de Comunicações do Azure de produção (também chamadas de implantações padrão) consistem em três regiões separadas: uma região de gerenciamento e duas regiões de serviço. As implantações de laboratório consistem em uma região de gerenciamento e uma região de serviço.
Este artigo descreve os dois tipos de região diferentes e seus modelos de redundância distintos. Ele abrange a confiabilidade regional com zonas de disponibilidade e confiabilidade entre regiões com recuperação de desastre. Para obter uma visão geral mais detalhada da confiabilidade no Azure, confira Confiabilidade do Azure.
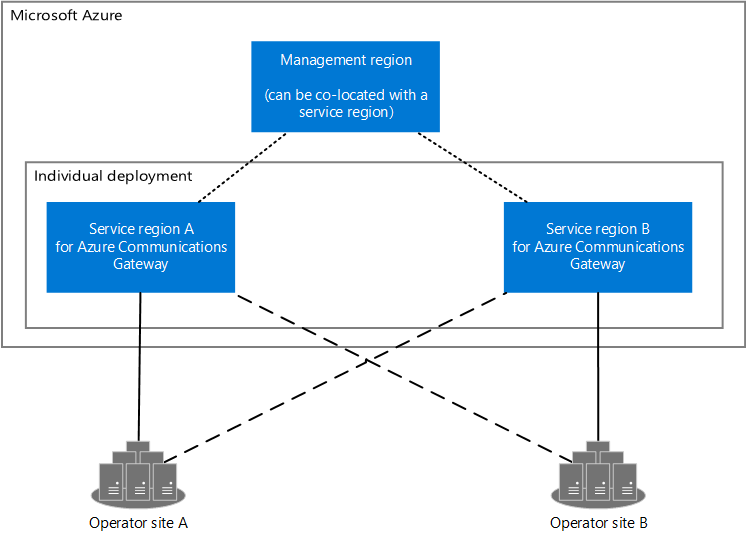
Diagrama mostrando dois sites de operadores e as regiões do Azure para o Gateway de Comunicações do Azure. O Gateway de Comunicações do Azure tem duas regiões de serviço e uma região de gerenciamento. As regiões de serviço se conectam à região de gerenciamento e aos sites do operador. A região de gerenciamento pode ser colocada com uma região de serviço.
Regiões de serviço
As regiões de serviço contêm a infraestrutura de voz e API usada para lidar com o tráfego entre a rede e os serviços de comunicação escolhidos.
As implantações do Gateway de Comunicações do Azure de produção têm duas regiões de serviço implantadas em um modo ativo-ativo (conforme exigido pelos programas Operator Connect e Teams Phone Mobile). O failover rápido entre as regiões de serviço é fornecido no nível de infraestrutura/IP e no nível do aplicativo (SIP/RTP/HTTP).
As regiões de serviço também contêm a infraestrutura da API de Provisionamento do Gateway de Comunicações do Azure.
Dica
As implantações de produção sempre devem ter duas regiões de serviço, mesmo que uma das regiões de serviço escolhidas esteja em uma geografia do Azure de região única (por exemplo, Catar). Se você escolher uma geografia do Azure de região única, escolha uma segunda região do Azure em uma Geografia do Azure diferente.
Essas regiões de serviço são idênticas na operação e fornecem resiliência a falhas regionais e de zona. Cada região de serviço pode transportar 100% do tráfego usando a instância do Gateway de Comunicações do Azure. Dessa forma, os usuários finais ainda devem ser capazes de fazer e receber chamadas com êxito durante qualquer zona ou tempo de inatividade regional.
As implantações de laboratório têm uma região de serviço.
Requisitos de roteamento de chamadas
O Gateway de Comunicações do Azure oferece um modelo de redundância "rediscagem bem-sucedida": as chamadas tratadas por pares com falha são encerradas, mas novas chamadas são roteadas para pares íntegros. Esse modelo espelha o modelo de redundância fornecido pelo Microsoft Teams.
Para implantações de produção, esperamos que sua rede tenha dois sites com redundância geográfica. Cada site deve ser emparelhado com uma região do Gateway de Comunicações do Azure. O modelo de redundância depende da conectividade cruzada entre a rede e as regiões de serviço do Gateway de Comunicações do Azure.
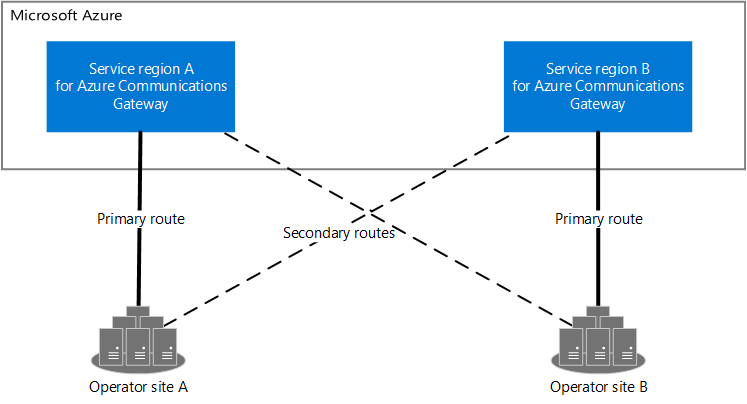
Diagrama de dois sites de operador (site do operador A e site do operador B) e duas regiões de serviço (região de serviço A e região de serviço B). O site do operador A tem uma rota primária para a região de serviço A e uma rota secundária para a região de serviço B. O site do operador B tem uma rota primária para a região de serviço B e uma rota secundária para a região de serviço A.
As implantações de laboratório devem se conectar a um site em sua rede.
Cada região de serviço do Gateway de Comunicações do Azure fornece um registro SRV. Esse registro contém todos os pares SIP que fornecem funcionalidade SBC (para roteamento de chamadas para serviços de comunicação) na região. Esse registro SRV pode apontar para qualquer endereço IP no intervalo de IP /28 fornecido pela sua equipe de integração.
Se o Gateway de Comunicações do Azure incluir o MCP (Ponto de Controle Móvel), cada região de serviço fornecerá um registro SRV extra para MCP. Cada registro MCP por região contém MCP dentro da região com prioridade máxima e MCP na outra região com prioridade mais baixa.
Cada site em sua rede deve:
- Envie o tráfego para sua região de serviço local do Gateway de Comunicações do Azure por padrão.
- Localize os pares do Gateway de Comunicações do Azure em uma região usando o DNS SRV, conforme descrito no RFC 3263.
- Faça uma pesquisa de SRV de DNS no nome de domínio para a conexão da região de serviço com sua rede, usando
_sip._tls.<regional-FQDN-from-portal>. Substitua<regional-FQDN-from-portal>pelos FQDNs por região dos campos Nome do host na página de visão geral do recurso no portal do Azure. Por exemplo, se a implantação usar nomes de domíniocommsgw.azure.com, procure_sip._tls.pstn-region1.<deployment-id>.commsgw.azure.compara a primeira região. - Se a pesquisa SRV retornar vários destinos, use o peso e a prioridade de cada destino para selecionar um único destino.
- Faça uma pesquisa de SRV de DNS no nome de domínio para a conexão da região de serviço com sua rede, usando
- Enviar novas chamadas para os pares disponíveis do Gateway de Comunicações do Azure.
- Ter a capacidade de receber tráfego de qualquer endereço IP em cada um dos intervalos de IP associados ao Gateway de Comunicações do Azure.
Quando a rede roteia chamadas para os pares SIP do Gateway de Comunicações do Azure para a função SBC, ela deve:
- Use OPÇÕES SIP (ou uma combinação de opções e tráfego SIP) para monitorar a disponibilidade dos pares SIP do Gateway de Comunicações do Azure.
- Tente novamente INVITEs que receberam 408 respostas, 503 respostas ou 504 respostas ou não receberam respostas, redirecionando-as para outros pares disponíveis no site local. Procure a outra região de serviço (definida pelo registro SRV da outra região) somente se todos os pares na região de serviço local tiverem falhado.
- Nunca tente novamente chamadas que recebam respostas de erro que não sejam 408, 503 e 504.
Se a implantação do Gateway de Comunicações do Azure incluir MCP (Ponto de Controle Móvel) integrado, sua rede deverá fazer o seguinte para MCP:
- Detecte quando o MCP em uma região não está disponível, marque os destinos para o registro SRV dessa região como indisponível e tente novamente periodicamente determinar quando a região está disponível novamente. O MCP não responde às OPÇÕES SIP.
- Manipule as respostas 5xx do MCP de acordo com a política da sua organização. Por exemplo, você pode repetir a solicitação ou permitir que a chamada continue sem passar pelo Gateway de Comunicações do Azure e entrar no Sistema de Telefonia da Microsoft.
Os detalhes desse comportamento de roteamento são específicos para sua rede. Você deve concordar com eles com sua equipe de integração durante seu projeto de integração.
Regiões de gerenciamento
As regiões de gerenciamento contêm a infraestrutura usada para ordenação, monitoramento e cobrança do Gateway de Comunicações do Azure. Toda a infraestrutura dentro dessas regiões é implantada de maneira com redundância zonal, o que significa que todos os dados são replicados automaticamente em cada Zona de Disponibilidade dentro da região. Todos os dados de configuração críticos também são replicados para cada uma das Regiões de Serviço para garantir o funcionamento adequado do serviço durante uma falha na região do Azure.
Suporte à zona de disponibilidade
As zonas de disponibilidade do Azure são pelo menos três grupos de datacenters separados fisicamente em cada região do Azure. Os datacenters dentro de cada zona são equipados com energia, resfriamento e infraestrutura de rede independentes. Em caso de falha de uma zona local, as zonas de disponibilidade foram projetadas de modo que, se uma zona é afetada, os serviços regionais, a capacidade e a alta disponibilidade têm suporte nas duas zonas restantes.
As falhas podem variar de falhas de software e hardware a eventos como terremotos, inundações e incêndios. A tolerância a falhas é obtida devido à redundância e ao isolamento lógico dos serviços do Azure. Para obter informações detalhadas sobre as zonas de disponibilidade no Azure, confira Regiões e zonas de disponibilidade.
Os serviços habilitados para zonas de disponibilidade do Azure foram projetados para fornecer o nível ideal de resiliência e flexibilidade. Eles podem ser configurados de duas maneiras. Eles podem ter redundância de zona, com replicação automática entre zonas, ou podem ser zonais, com instâncias fixadas em uma zona específica. Você também pode combinar essas abordagens. Para obter mais informações sobre a arquitetura zonal versus com redundância de zona, confira Recomendações para usar zonas e regiões de disponibilidade.
Experiência de desativação de zona para regiões de serviço
Durante uma interrupção em toda a zona, as chamadas tratadas pela zona afetada são encerradas, com uma breve perda de capacidade dentro da região até que a auto-recuperação do serviço reequilibra os recursos subjacentes para zonas saudáveis. Essa auto-recuperação não depende da restauração de zona; espera-se que o estado de recuperação automática do serviço gerenciado pela Microsoft compense uma zona perdida, usando a capacidade de outras zonas. Os recursos de transporte de tráfego são implantados de maneira com redundância de zona, mas no tráfego de menor escala pode ser tratado por um único recurso. Nesse caso, os mecanismos de failover descritos neste artigo reequilibram todo o tráfego para a outra região de serviço enquanto os recursos que transportam tráfego são reimplantados em uma zona íntegra.
Experiência de zona para baixo para a região de gerenciamento
Durante uma interrupção em toda a zona, nenhuma ação é necessária durante a recuperação de zona. A região de gerenciamento se auto-cura e se reequilibra para tirar proveito da zona íntegra automaticamente.
Recuperação de desastre: fallback para outras regiões
A DR (recuperação de desastre) trata da recuperação após eventos de alto impacto, como desastres naturais ou implantações com falha, que resultam em tempo de inatividade e perda de dados. Seja qual for a causa, a melhor solução para um desastre é um plano de DR bem definido e testado e um design de aplicativo que dê suporte ativo à DR. Antes de começar a pensar em criar seu plano de recuperação de desastre, confira Recomendações para criar uma estratégia de recuperação de desastre.
Quando o assunto é DR, a Microsoft usa o modelo de responsabilidade compartilhada. Em um modelo de responsabilidade compartilhada, a Microsoft garante que a infraestrutura de linha de base e os serviços de plataforma estejam disponíveis. Ao mesmo tempo, muitos serviços do Azure não replicam dados automaticamente nem retornam de uma região com falha para a replicação cruzada em outra região habilitada. Para esses serviços, você é responsável por configurar um plano de recuperação de desastre que funcione para sua carga de trabalho. A maioria dos serviços executados nas ofertas de PaaS (plataforma como serviço) do Azure fornece recursos e diretrizes para dar suporte à DR. Além disso, você pode usar recursos específicos do serviço para dar suporte a uma recuperação rápida, a fim de ajudar a desenvolver seu plano de DR.
Esta seção descreve o comportamento do Gateway de Comunicações do Azure durante uma interrupção em toda a região.
Recuperação de desastre: failover entre regiões
Durante uma interrupção em toda a região, os mecanismos de failover descritos neste artigo (sondagem OPTIONS e tentativa de SIP sobre falha) reequilibrarão todo o tráfego de chamadas para a outra região de serviço, mantendo a disponibilidade. Começaremos a restaurar a redundância regional. Restaurar a redundância regional durante o tempo de inatividade estendido pode exigir o uso de outras regiões do Azure. Se precisarmos migrar uma região com falha para outra região, consultaremos você antes de iniciar as migrações.
A função SBC no Gateway de Comunicações do Azure fornece sondagem OPTIONS para permitir que sua rede determine a disponibilidade de pares. Para o MCP, sua rede deve ser capaz de detectar quando o MCP não está disponível e tentar novamente periodicamente determinar quando o MCP está disponível novamente. O MCP não responde às OPÇÕES SIP.
Os clientes de API de provisionamento entram em contato com o Gateway de Comunicações do Azure usando o nome de domínio base para sua implantação. O registro DNS para esse domínio tem um TTL (vida útil) de 60 segundos. Quando uma região falha, o Azure atualiza o registro DNS para se referir a outra região, para que os clientes que fazem uma nova pesquisa DNS recebam os detalhes da nova região. Recomendamos garantir que os clientes possam fazer uma nova pesquisa de DNS e tentar novamente uma solicitação 60 segundos após um tempo limite ou uma resposta 5xx.
Dica
As implantações de laboratório não oferecem failover entre regiões (porque têm apenas uma região de serviço).
Recuperação de desastre: failover entre regiões para regiões de gerenciamento
O tráfego do Serviço de Voz e o provisionamento por meio do Portal de Gerenciamento de Números não são afetados por falhas na região de gerenciamento, pois os recursos correspondentes do Azure são hospedados em regiões de serviço. Os usuários do Portal de Gerenciamento de Números talvez precisem entrar novamente.
Os serviços de monitoramento podem ficar temporariamente indisponíveis até que o serviço seja restaurado. Se a região de gerenciamento tiver tempo de inatividade estendido, migraremos os recursos afetados para outra região disponível.
Escolhendo regiões de gerenciamento e serviço
Uma única implantação do Gateway de Comunicações do Azure foi projetada para lidar com o tráfego em uma área geográfica. Implante ambas as regiões de serviço em uma implantação de produção na mesma área geográfica (por exemplo, América do Norte). Esse modelo garante que a latência em chamadas de voz permaneça dentro dos limites exigidos pelos programas Operator Connect e Teams Phone Mobile.
Considere os seguintes pontos ao escolher os locais da região de serviço:
- Selecione na lista de regiões disponíveis do Azure. Você pode ver as regiões do Azure que podem ser selecionadas como regiões de serviço na página Produtos por região.
- Escolha regiões próximas às suas próprias instalações e os locais de emparelhamento entre sua rede e a Microsoft para reduzir a latência de chamadas.
- Prefira pares regionais para minimizar o tempo de recuperação se ocorrer uma interrupção de várias regiões.
Escolha uma região de gerenciamento na seguinte lista:
- Leste dos EUA
- Centro-Oeste dos EUA
- Europa Ocidental
- Sul do Reino Unido
- Centro da Índia
- Canadá Central
- Leste da Austrália
As regiões de gerenciamento podem ser colocadas com regiões de serviço. É recomendável escolher a região de gerenciamento mais próxima de suas regiões de serviço.
Observação
Caso esteja habilitando a Versão Prévia da Proteção de Chamadas do Operador do Azure, a região de serviço selecionada pode não ser a região do Azure em que os recursos de suporte são implantados. Consulte os Produtos do Azure por Região para acessar a lista de regiões de serviço de Proteção de Chamadas do Operador do Azure com suporte no momento, e fale com sua equipe de integração caso tenha alguma dúvida sobre qual região está selecionada.
Contratos de nível de serviço
O design de confiabilidade descrito neste documento é implementado pela Microsoft e não é configurável. Para obter mais informações sobre os SLAs (contratos de nível de serviço) do Gateway de Comunicações do Azure, consulte o SLA do Gateway de Comunicações do Azure.