Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Azure Cosmos DB pode armazenar terabytes de dados. Você pode executar uma migração de dados em larga escala para mover sua carga de trabalho de produção para o Azure Cosmos DB. Este artigo descreve os desafios envolvidos na movimentação de dados em grande escala para o Azure Cosmos DB e apresenta a ferramenta que ajuda a enfrentá-los e migra os dados para o Azure Cosmos DB. Nesse estudo de caso, o cliente usou a API para NoSQL do Azure Cosmos DB.
Antes de migrar toda a carga de trabalho para o Azure Cosmos DB, você pode migrar um subconjunto de dados para validar alguns dos aspectos, como: escolha de chave de partição, desempenho de consulta e modelagem de dados. Depois de validar a prova de conceito, você pode mover toda a carga de trabalho para o Azure Cosmos DB.
Ferramentas para migração de dados
Atualmente, as estratégias de migração do Azure Cosmos DB são diferentes com base na escolha da API e no tamanho dos dados. Para migrar conjuntos de dados menores – para validar a modelagem de dados, o desempenho da consulta, a opção de chave de partição etc. – você pode usar o conector do Azure Cosmos DB do Azure Data Factory. Se você tiver familiaridade com o Spark, também pode optar por usar o conector Spark do Azure Cosmos DB para migrar os dados.
Desafios de migrações em larga escala
As ferramentas existentes capazes de migrar dados para o Azure Cosmos DB têm algumas limitações que se tornam especialmente aparentes em migrações em larga escala:
Capacidades de expansão limitadas: Para migrar terabytes de dados para o Azure Cosmos DB o mais rápido possível e consumir efetivamente toda a capacidade de processamento provisionada, os clientes de migração devem ter a capacidade de escalar horizontalmente indefinidamente.
Falta de acompanhamento do progresso e de pontos de verificação: É importante acompanhar o progresso da migração e estabelecer pontos de controle durante a migração de grandes conjuntos de dados. Caso contrário, qualquer erro que ocorra durante a migração interromperá a migração e você precisará iniciar o processo do zero. Não seria produtivo reiniciar todo o processo de migração quando já estiver 99% concluído.
Ausência de fila de mensagens não entregues: Em conjuntos de dados extensos, em alguns casos podem ocorrer problemas com partes dos dados de origem. Paralelamente, pode haver problemas transitórios com o cliente ou com a rede. Qualquer um desses casos não deve fazer com que toda a migração falhe. Embora a maioria das ferramentas de migração tenha recursos robustos de repetição para se proteger contra problemas intermitentes, isso nem sempre é suficiente. Por exemplo, se menos de 0,01% dos documentos de dados de origem tiverem mais de 2 MB de tamanho, isso fará com que a gravação do documento falhe no Azure Cosmos DB. Idealmente, é útil que a ferramenta de migração persista esses documentos 'com falha' para outra fila de mensagens mortas, que pode ser processada após a migração.
Muitas dessas limitações estão sendo corrigidas para ferramentas como o Azure Data Factory, serviço de migração de dados do Azure.
Ferramenta personalizada com biblioteca de executor em massa
Os desafios descritos na seção anterior podem ser resolvidos usando uma ferramenta personalizada que pode ser facilmente dimensionada em várias instâncias e resiliente a falhas transitórias. Além disso, a ferramenta personalizada pode pausar e retomar a migração em vários pontos de verificação. O Azure Cosmos DB já fornece a biblioteca de executores em massa que incorpora alguns desses recursos. Por exemplo, a biblioteca do executor em massa já tem a funcionalidade de lidar com erros transitórios e pode dimensionar threads em um único nó para consumir cerca de 500 K RUs por nó. A biblioteca de executores em massa também particiona o conjunto de dados de origem em micro lotes, que são operados de forma independente, como uma forma de ponto de verificação.
A ferramenta personalizada usa a biblioteca do executor em massa e oferece suporte ao dimensionamento entre vários clientes e ao rastreamento de erros durante o processo de ingestão. Para usar essa ferramenta, os dados de origem devem ser particionados em arquivos distintos no ADLS (Azure Data Lake Storage) para que os diferentes operadores de migração possam pegar cada arquivo e ingeri-los no Azure Cosmos DB. A ferramenta personalizada usa uma coleção separada, que armazena metadados sobre o progresso da migração para cada arquivo de origem individual no ADLS e rastreia os erros associados a eles.
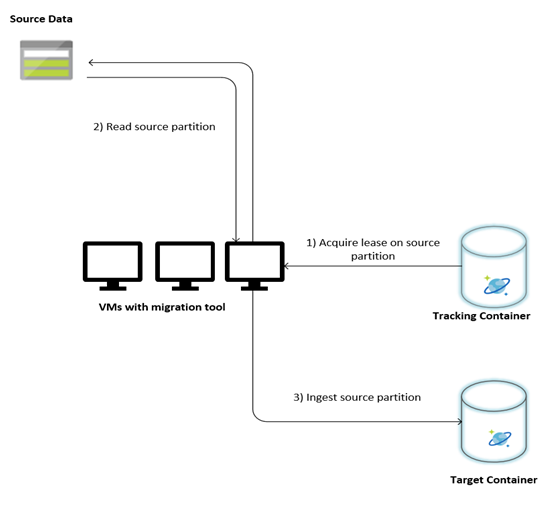
A imagem a seguir descreve o processo de migração usando essa ferramenta personalizada. A ferramenta está em execução em um conjunto de máquinas virtuais, e cada máquina virtual consulta a coleção de rastreamento no Azure Cosmos DB para adquirir uma concessão em uma das partições de dados de origem. Assim que isso for feito, a partição de dados de origem é lida pela ferramenta e ingerida no Azure Cosmos DB usando a biblioteca de executor em massa. Em seguida, a coleção de rastreamento é atualizada para registrar o progresso da ingestão de dados e todos os erros encontrados. Depois que uma partição de dados é processada, a ferramenta tenta consultar a próxima partição de origem disponível. Ele continua processando a próxima partição de origem até que todos os dados sejam migrados. O código-fonte da ferramenta está disponível no repositório de ingestão em massa do Azure Cosmos DB.
A coleção de rastreamento contém documentos, conforme mostrado no exemplo a seguir. Você verá esses documentos como um para cada partição nos dados de origem. Cada documento contém os metadados para a partição de dados de origem, como seu local, status de migração e erros (se houver):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Pré-requisitos para a migração de dados
Antes de iniciar a migração de dados, há alguns pré-requisitos a considerar:
Estime o tamanho dos dados:
O tamanho dos dados de origem pode não mapear exatamente para o tamanho dos dados no Azure Cosmos DB. Alguns documentos de exemplo da fonte podem ser inseridos para verificar o tamanho dos dados no Azure Cosmos DB. Dependendo do tamanho do documento de exemplo, o tamanho total dos dados após migração no Azure Cosmos DB poderá ser estimado.
Por exemplo, se cada documento após a migração para o Azure Cosmos DB estiver em cerca de 1 KB e se houver cerca de 60.000.000.000 documentos no conjunto de dados de origem, significaria que o tamanho estimado no Azure Cosmos DB seria próximo de 60 TB.
Pré-criar contêineres com RUs suficiente:
Embora o Azure Cosmos DB dimensione o armazenamento automaticamente, não é aconselhável começar do menor tamanho de contêiner. Contêineres menores têm disponibilidade de taxa de transferência mais baixa, o que significa que a migração levará muito mais tempo para ser concluída. Em vez disso, é útil criar os contêineres com o tamanho de dados final (conforme estimado na etapa anterior) e garantir que a carga de trabalho de migração esteja consumindo totalmente a taxa de transferência provisionada.
Na etapa anterior, como o tamanho dos dados foi estimado em torno de 60 TB, um contêiner de pelo menos 2,4 M RUs é necessário para acomodar todo o conjunto de dados.
Estimar a velocidade de migração:
Supondo que a carga de trabalho de migração possa consumir todo o taxa de transferência provisionado, o provisionamento total forneceria uma estimativa da velocidade da migração. Continuando o exemplo anterior, cinco RUs são necessárias para gravar um documento de 1 KB na API do Azure Cosmos DB para a conta NoSQL. 2,4 milhões de RUs permitiriam uma transferência de 480.000 documentos por segundo (ou 480 MB/s). Isso significa que a migração completa de 60 TB leva 125.000 segundos ou cerca de 34 horas.
Caso você queira que a migração seja concluída em um dia, aumente o taxa de transferência provisionado para 5 milhões de RUs.
Desligue a indexação:
Como a migração deve ser concluída o mais rápido possível, é aconselhável minimizar o tempo e as RUs gastas na criação de índices para cada um dos documentos ingeridos. O Azure Cosmos DB indexa automaticamente todas as propriedades, vale a pena minimizar a indexação para alguns termos selecionados ou desativá-la completamente durante a migração. Você pode desativar a política de indexação do contêiner alterando o indexingMode para nenhum, conforme mostrado aqui:
{
"indexingMode": "none"
}
Quando a migração for concluída, você pode atualizar a instância de indexação.
Processo de migração
Quando os pré-requisitos forem concluídos, você poderá migrar dados reproduzindo as seguintes etapas:
Primeiro, importe os dados da origem para o armazenamento de Blobs do Azure. Para aumentar a velocidade da migração, é útil paralelizar entre partições de origem distintas. Antes de iniciar a migração, o conjunto de dados de origem deve ser particionado em arquivos de aproximadamente 200 MB.
A biblioteca de executores em massa pode escalar verticalmente para consumir 500.000 RUs em uma única VM de cliente. Como a taxa de transferência disponível é 5 milhões de RUs, as 10 VMs Ubuntu 16.04 (Standard_D32_v3) devem ser provisionadas na mesma região em que o banco de dados do Azure Cosmos DB está localizado. Prepare essas VMs com a ferramenta de migração e seu arquivo de configurações.
Execute a etapa da fila em uma das máquinas virtuais do cliente. Esta etapa cria a coleção de acompanhamento, que examina o contêiner do ADLS e cria um documento de acompanhamento de progresso para cada um dos arquivos de partição do conjunto de dados de origem.
Em seguida, execute a etapa de importação em todas as VMs do cliente. Cada um dos clientes pode assumir a propriedade em uma partição de origem e ingerir os dados no Azure Cosmos DB. Depois que for concluído e seu status for atualizado na coleção de acompanhamento, os clientes poderão consultar a próxima partição de origem disponível na mesma coleção.
Esse processo continua até que todo o conjunto de partições de origem tenha sido ingerido. Depois que todas as partições de origem forem processadas, a ferramenta deve ser executada novamente na mesma coleção de controle, mas agora no modo de correção de erro. Essa etapa é necessária para identificar as partições de origem que devem ser reprocessadas devido a erros.
Alguns desses erros podem ocorrer devido a documentos incorretos nos dados de origem. Eles devem ser identificados e corrigidos. Em seguida, você deve executar novamente a etapa de importação nas partições com falha para ingeri-las novamente.
Quando a migração for concluída, você poderá confirmar que a contagem de documentos no Azure Cosmos DB é igual à contagem de documentos no banco de dados de origem. Neste exemplo, o tamanho total no Azure Cosmos DB foi de 65 terabytes. Após a migração, a indexação pode ser ativada seletivamente e as RUs podem ser reduzidas para o nível exigido pelas operações da carga de trabalho.
Próximas Etapas
- Saiba mais experimentando os aplicativos de exemplo que consumem a biblioteca de executor em massa em .NET e Java.
- A biblioteca do executor em massa é integrada ao conector Spark do Azure Cosmos DB. Para saber mais, veja artigo Conector Spark do Azure Cosmos DB.
- Entre em contato com a equipe de produtos do Azure Cosmos DB abrindo um tíquete de suporte no tipo de problema "Consultoria Geral" e no subtipo de problema "Migrações grandes (TB+) para obter mais ajuda com migrações em grande escala.
- Tentando fazer o planejamento de capacidade para uma migração para Azure Cosmos DB? Você pode usar informações sobre o seu cluster de banco de dados existente para planejamento de capacidade.
- Se você sabe apenas o número de vCores e servidores do cluster de banco de dados existente, leia sobre como estimar unidades de solicitação com vCores ou vCPUs
- Se você souber as taxas de solicitação típicas para a carga de trabalho de banco de dados atual, leia sobre como estimar unidades de solicitação usando o planejador de capacidade do Microsoft Azure Cosmos DB