Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade de cópia no Azure Data Factory para copiar dados de e para o Azure Cosmos DB for NoSQL e usar o Fluxo de Dados para transformar dados no Azure Cosmos DB for NoSQL. Para saber mais, leia o artigo introdutório do Azure Data Factory e do Azure Synapse Analytics.
Observação
Esse conector dá suporte apenas ao Azure Cosmos DB for NoSQL. Para o Azure Cosmos DB for MongoDB, consulte conector para Azure Cosmos DB for MongoDB. Não há suporte para outros tipos de API.
Funcionalidades com suporte
Esse conector do Azure Cosmos DB for NoSQL tem suporte para os seguintes recursos:
| Funcionalidades com suporte | IR | Ponto de extremidade privado gerenciado |
|---|---|---|
| Atividade de cópia (origem/coletor) | ① ② | ✓ |
| Fluxo de dados de mapeamento (origem/coletor) | ① | ✓ |
| Atividade de pesquisa | ① ② | ✓ |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Para a atividade Copy, esse conector do Azure Cosmos DB for NoSQL dá suporte para:
- Copiar dados de e para o Azure Cosmos DB for NoSQL usando as autenticações de chave, de entidade de serviço ou de identidades gerenciadas para recursos do Azure.
- Gravar no Azure Cosmos DB como insert ou upsert.
- Importar e exportar documentos JSON no estado em que se encontram, ou copiar dados de ou para um conjunto de dados tabular. Exemplos incluem um Banco de Dados SQL e um arquivo CSV. Para copiar documentos no estado em que se encontram para ou de arquivos JSON de outra coleção do Azure Cosmos DB, confira Importar ou exportar documentos JSON.
As pipelines d Data Factory e do Synapse integram-se à biblioteca de executor em massa do Azure Cosmos DB para fornecer o melhor desempenho quando você grava no Azure Cosmos DB.
Dica
O vídeo de Migração de Dados orienta você pelas etapas de copiar dados do Armazenamento de Blobs do Azure para o Azure Cosmos DB. O vídeo também descreve considerações de ajuste de desempenho para a ingestão de dados para o Azure Cosmos DB em geral.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Azure Cosmos DB usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Azure Cosmos DB na interface do usuário do portal do Microsoft Azure.
Navegue até a guia Gerenciar no workspace do Azure Data Factory ou do Synapse, selecione Serviços Vinculados e clique em Novo:
Procure o Azure Cosmos DB for NoSQL e selecione o conector do Azure Cosmos DB for NoSQL.
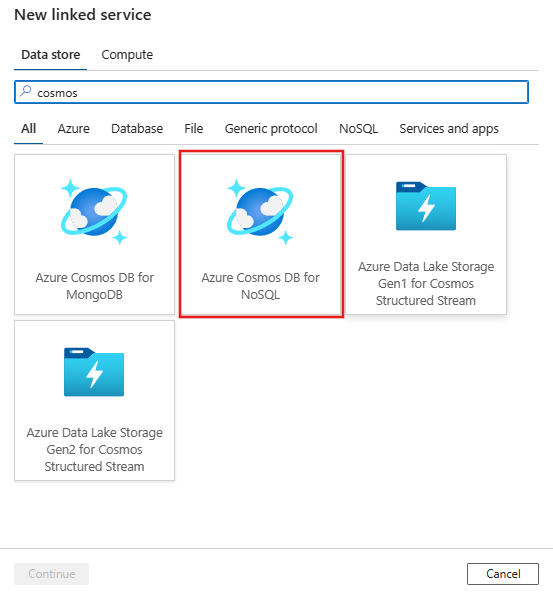
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
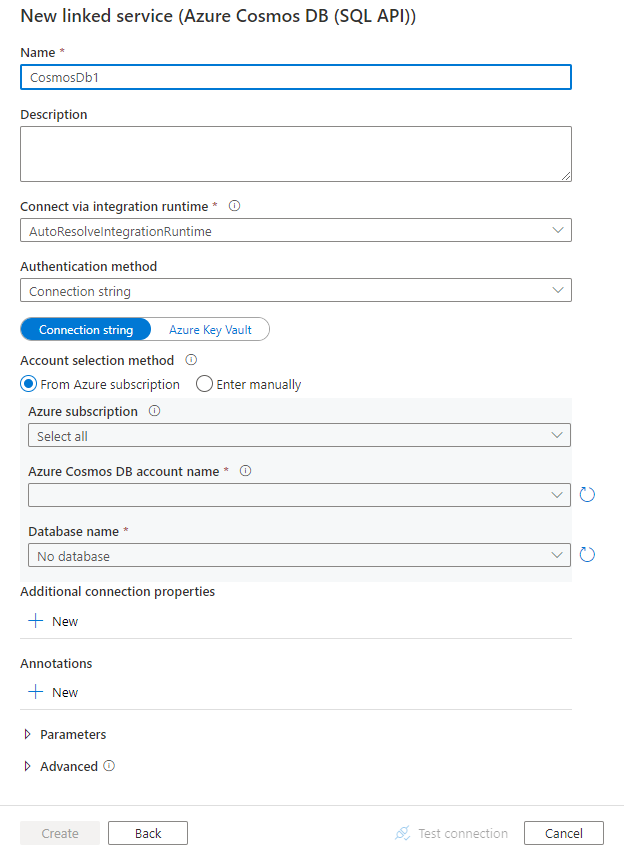
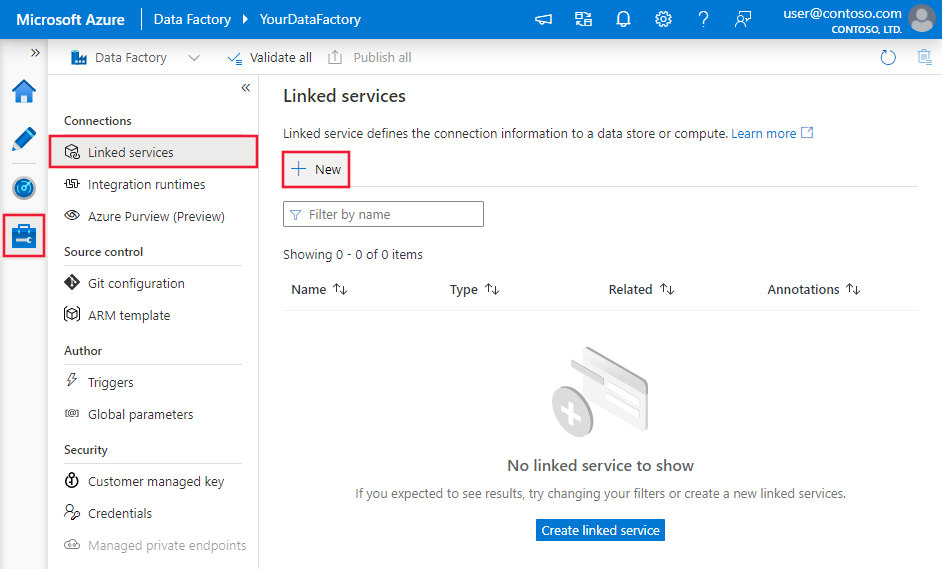
Detalhes da configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades que você pode usar para definir entidades específicas do Azure Cosmos DB for NoSQL.
Propriedades do serviço vinculado
O conector do Azure Cosmos DB for NoSQL dá suporte aos tipos de autenticação a seguir. Consulte as seções correspondentes para obter detalhes:
- Autenticação de chave
- Autenticação de entidade de serviço
- Autenticação de identidade gerenciada atribuída pelo sistema
- Autenticação de identidade gerenciada atribuída pelo usuário
Autenticação de chave
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como CosmosDb. | Sim |
| connectionString | Especifique as informações necessárias para se conectar ao banco de dados do Azure Cosmos DB. Observação: você deve especificar informações de banco de dados na cadeia de conexão conforme mostrado nos exemplos a seguir. Você também pode colocar a chave de conta no Azure Key Vault e efetuar pull da configuração accountKey da cadeia de conexão. Confira os exemplos a seguir e o artigo Armazenar credenciais no Azure Key Vault com mais detalhes. |
Sim |
| connectVia | O runtime de integração a ser usado para se conectar ao armazenamento de dados. Você poderá usar o Azure Integration Runtime ou um tempo de execução da integração auto-hospedada (se o armazenamento de dados estiver localizado em uma rede privada). Se essa propriedade não for especificada, o Azure Integration Runtime padrão será usado. | Não |
Exemplo
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;AccountKey=<AccessKey>;Database=<Database>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: armazenar a chave da conta no Azure Key Vault
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;Database=<Database>",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação de entidade de serviço
Observação
Atualmente, a autenticação da entidade de serviço não tem suporte no fluxo de dados.
Para usar a autenticação de entidade de serviço, siga estas etapas.
Registrar um aplicativo na plataforma de identidade da Microsoft. Para saber como, confira Início Rápido: registrar um aplicativo na plataforma de identidade da Microsoft. Anote estes valores; ele são usados para definir o serviço vinculado:
- ID do aplicativo
- Chave do aplicativo
- ID do locatário
Conceda a permissão adequada da entidade de serviço. Veja exemplos de como a permissão funciona no Azure Cosmos DB em Listas de controle de acesso em arquivos e diretórios. Mais especificamente, crie uma definição de função e atribua a função à entidade de serviço por meio da ID do objeto da entidade de serviço.
Estas propriedades têm suporte para o serviço vinculado:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como CosmosDb. | Sim |
| accountEndpoint | Especifique a URL do ponto de extremidade da conta para a instância do Azure Cosmos DB. | Sim |
| Banco de Dados | Especifique o nome do banco de dados. | Sim |
| servicePrincipalId | Especifique a ID do cliente do aplicativo. | Sim |
| servicePrincipalCredentialType | O tipo de credencial a ser usada para autenticação da entidade de serviço. Os valores permitidos são ServicePrincipalKey e ServicePrincipalCert. | Sim |
| servicePrincipalCredential | A credencial da entidade de serviço. Ao usar ServicePrincipalKey como o tipo de credencial, especifique a chave do aplicativo. Marque este campo como um SecureString para armazená-lo com segurança ou referencie um segredo armazenado no Azure Key Vault. Quando usar ServicePrincipalCert como credencial, faça referência a um certificado no Azure Key Vault e verifique se o tipo de conteúdo do certificado é PKCS nº 12. |
Sim |
| locatário | Especifique as informações de locatário (domínio nome ou ID do Locatário) em que o aplicativo reside. Recupere-as passando o mouse no canto superior direito do Portal do Azure. | Sim |
| azureCloudType | Para autenticação da entidade de serviço, especifique o tipo de ambiente em nuvem do Azure em que seu aplicativo do Microsoft Entra está registrado. Os valores permitidos são AzurePublic, AzureChina, AzureUsGovernment e AzureGermany. Por padrão, é usado o ambiente de nuvem do serviço. |
Não |
| connectVia | O runtime de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Azure Integration Runtime ou um runtime de integração auto-hospedada se o seu armazenamento de dados estiver em uma rede privada. Se não especificado, o Azure Integration Runtime padrão será usado. | Não |
Exemplo: usar a autenticação de chave de entidade de serviço
Você também pode armazenar a chave de entidade de serviço no Azure Key Vault.
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: usar a autenticação de certificado de entidade de serviço
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação de identidade gerenciada atribuída pelo sistema
Observação
Atualmente, a autenticação de identidade gerenciada atribuída pelo sistema é suportada em fluxos de dados por meio do uso de propriedades avançadas no formato JSON.
Um pipeline do Data Factory ou do Synapse podem ser associados a uma identidade gerenciada atribuída pelo sistema para recursos do Azure, que representa essa instância de serviço específica. Você pode usar essa identidade gerenciada diretamente para a autenticação do Azure Cosmos DB da mesma maneira que no uso de sua própria entidade de serviço. Ela permite que esse recurso designado acesse e copie dados de ou para sua instância do Azure Cosmos DB.
Para usar identidades gerenciadas atribuídas pelo sistema para autenticação de recursos do Azure, siga estas etapas.
Recuperar as informações de identidade gerenciada atribuídas pelo sistema copiando o valor de ID do objeto de identidade gerenciada gerado junto com o serviço.
Conceda a permissão apropriada de identidade gerenciada atribuída pelo sistema. Veja exemplos de como a permissão funciona no Azure Cosmos DB em Listas de controle de acesso em arquivos e diretórios. Mais especificamente, crie uma definição de função e atribua a função à identidade gerenciada atribuída pelo sistema
Estas propriedades têm suporte para o serviço vinculado:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como CosmosDb. | Sim |
| accountEndpoint | Especifique a URL do ponto de extremidade da conta para a instância do Azure Cosmos DB. | Sim |
| Banco de Dados | Especifique o nome do banco de dados. | Sim |
| connectVia | O runtime de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Azure Integration Runtime ou um runtime de integração auto-hospedada se o seu armazenamento de dados estiver em uma rede privada. Se não especificado, o Azure Integration Runtime padrão será usado. | Não |
| subscriptionId | Especificar a ID da assinatura para a instância do Azure Cosmos DB | Não para atividade Copy, Sim para o fluxo de dados de mapeamento |
| tenantId | Especificar a ID do locatário para a instância do Azure Cosmos DB | Não para atividade Copy, Sim para o fluxo de dados de mapeamento |
| resourceGroup | Especificar o nome do grupo de recursos para a instância do Azure Cosmos DB | Não para atividade Copy, Sim para o fluxo de dados de mapeamento |
Exemplo:
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"subscriptionId": "<subscription id>",
"tenantId": "<tenant id>",
"resourceGroup": "<resource group>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação de identidade gerenciada atribuída pelo usuário
Observação
Atualmente, a autenticação de identidade gerenciada atribuída pelo usuário não tem suporte em fluxos de dados por meio do uso de propriedades avançadas em formato JSON.
Um pipeline do Data Factory ou do Synapse podem ser associados a uma identidades gerenciadas atribuídas pelo usuário, que representam essa instância de serviço específica. Você pode usar essa identidade gerenciada diretamente para a autenticação do Azure Cosmos DB da mesma maneira que no uso de sua própria entidade de serviço. Ela permite que esse recurso designado acesse e copie dados de ou para sua instância do Azure Cosmos DB.
Para usar identidades gerenciadas atribuídas pelo usuário para autenticação de recursos do Azure, siga estas etapas.
Crie uma ou várias identidades gerenciadas atribuídas pelo usuário e conceda a permissão adequada de identidade gerenciada atribuída pelo usuário. Veja exemplos de como a permissão funciona no Azure Cosmos DB em Listas de controle de acesso em arquivos e diretórios. Mais especificamente, crie uma definição de função e atribua a função à identidade gerenciada atribuída pelo usuário.
Atribua uma ou várias identidades gerenciadas atribuídas pelo usuário a seu data factory e crie credenciais para cada identidade gerenciada atribuída pelo usuário.
Estas propriedades têm suporte para o serviço vinculado:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como CosmosDb. | Sim |
| accountEndpoint | Especifique a URL do ponto de extremidade da conta para a instância do Azure Cosmos DB. | Sim |
| Banco de Dados | Especifique o nome do banco de dados. | Sim |
| credenciais | Especifique a identidade gerenciada atribuída pelo usuário como o objeto da credencial. | Sim |
| connectVia | O runtime de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Azure Integration Runtime ou um runtime de integração auto-hospedada se o seu armazenamento de dados estiver em uma rede privada. Se não especificado, o Azure Integration Runtime padrão será usado. | Não |
| subscriptionId | Especificar a ID da assinatura para a instância do Azure Cosmos DB | Não para atividade Copy, Sim para o fluxo de dados de mapeamento |
| tenantId | Especificar a ID do locatário para a instância do Azure Cosmos DB | Não para atividade Copy, Sim para o fluxo de dados de mapeamento |
| resourceGroup | Especificar o nome do grupo de recursos para a instância do Azure Cosmos DB | Não para atividade Copy, Sim para o fluxo de dados de mapeamento |
Exemplo:
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"subscriptionId": "<subscription id>",
"tenantId": "<tenant id>",
"resourceGroup": "<resource group>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definição de conjuntos de dados, consulte Conjuntos de dados e serviços vinculados.
As seguintes propriedades têm suporte no conjunto de dados do Azure Cosmos DB for NoSQL:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como CosmosDbSqlApiCollection. | Sim |
| collectionName | O nome da coleção de documentos do Azure Cosmos DB. | Sim |
Se você usar o conjunto de dados do tipo "DocumentDbCollection", ainda terá suporte como está para compatibilidade com versões anteriores para a atividade de cópia e pesquisa, não há suporte para o Fluxo de Dados. A sugestão é que você use o novo modelo no futuro.
Exemplo
{
"name": "CosmosDbSQLAPIDataset",
"properties": {
"type": "CosmosDbSqlApiCollection",
"linkedServiceName":{
"referenceName": "<Azure Cosmos DB linked service name>",
"type": "LinkedServiceReference"
},
"schema": [],
"typeProperties": {
"collectionName": "<collection name>"
}
}
}
Propriedades da Atividade de Cópia
Esta seção fornece uma lista de propriedades que a fonte e o coletor do Azure Cosmos DB for NoSQL dão suporte. Para obter uma lista completa de seções e propriedades que estão disponíveis para definir atividades, consulte Pipelines.
Azure Cosmos DB for NoSQL como fonte
Para copiar dados do Azure Cosmos DB for NoSQL, defina o tipo fonte na Atividade de Cópia como DocumentDbCollectionSource.
As seguintes propriedades são suportadas na seção source da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade de cópia deve ser definida como CosmosDbSqlApiSource. | Sim |
| Consulta | Especifique a consulta do Azure Cosmos DB para ler dados. Exemplo: SELECT c.BusinessEntityID, c.Name.First AS FirstName, c.Name.Middle AS MiddleName, c.Name.Last AS LastName, c.Suffix, c.EmailPromotion FROM c WHERE c.ModifiedDate > \"2009-01-01T00:00:00\" |
Nenhum Se não for especificada, esta instrução SQL será executada: select <columns defined in structure> from mycollection |
| preferredRegions | A lista preferencial de regiões às quais se conectar ao recuperar dados do Azure Cosmos DB. | Não |
| pageSize | O número de documentos por página do resultado da consulta. O padrão é "-1", que significa usar o tamanho de página dinâmico do lado do serviço até 1.000. | Não |
| detectDatetime | Se é para detectar datetime dos valores de cadeia de caracteres nos documentos. Os valores permitidos são: true (padrão), false. | Não |
Se você usar a origem do tipo "DocumentDbCollectionSource", ainda terá suporte como está para compatibilidade com versões anteriores. É recomendável usar o novo modelo no futuro, pois ele fornece recursos mais avançados para copiar dados do Azure Cosmos DB.
Exemplo
"activities":[
{
"name": "CopyFromCosmosDBSQLAPI",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cosmos DB for NoSQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CosmosDbSqlApiSource",
"query": "SELECT c.BusinessEntityID, c.Name.First AS FirstName, c.Name.Middle AS MiddleName, c.Name.Last AS LastName, c.Suffix, c.EmailPromotion FROM c WHERE c.ModifiedDate > \"2009-01-01T00:00:00\"",
"preferredRegions": [
"East US"
]
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ao copiar dados do Azure Cosmos DB, a menos que você queira exportar documentos JSON no estado em que se encontram, a prática recomendada é especificar o mapeamento na atividade de cópia. O serviço honra o mapeamento especificado na atividade ꟷ se uma linha não contiver um valor para uma coluna, será fornecido um valor nulo para o valor da coluna. Se você não especificar um mapeamento, o serviço vai inferir o esquema usando a primeira linha nos dados. Se a primeira linha não contiver o esquema completo, algumas colunas estarão ausentes no resultado da operação de atividade.
Azure Cosmos DB for NoSQL como coletor
Para copiar dados para o Azure Cosmos DB for NoSQL, defina o tipo coletor na Atividade de Cópia como DocumentDbCollectionSink.
As seguintes propriedades são suportadas na seção Copy Activity sink:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do coletor Atividade de Cópia deve ser definido como CosmosDbSqlApiSink. | Sim |
| writeBehavior | Descreve como gravar dados no Azure Cosmos DB. Valores permitidos são insert e upsert. O comportamento de upsert é substituir o documento se um documento com a mesma ID já existir; caso contrário, inserir o documento. Nota: o serviço gera automaticamente uma ID para um documento se não for especificada uma ID no documento original ou no mapeamento de coluna. Isso significa que, para upsert funcionar conforme esperado, o documento deve ter uma ID. |
No (o padrão é insert) |
| writeBatchSize | O serviço usa a biblioteca de executor em massa do Azure Cosmos DB para gravar dados no Azure Cosmos DB. A propriedade writeBatchSize controla o tamanho dos documentos fornecidos pelo serviço à biblioteca. Você pode tentar aumentar o valor de writeBatchSize para melhorar o desempenho e diminuir o valor se o tamanho do documento for grande - veja as dicas abaixo. | Não (o padrão é 10.000) |
| disableMetricsCollection | O serviço coleta métricas como RUs do Azure Cosmos DB para recomendações e otimização de desempenho de cópia. Se você estiver preocupado com esse comportamento, especifique true para desativá-lo. |
Não (o padrão é false) |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas com o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando desejar limitar as conexões simultâneas. | Nenhum |
Dica
Para importar documentos JSON no estado em que se encontram, confira a seção Importar ou exportar documentos JSON; para copiar de dados em formato de tabela, confira Migrar de banco de dados relacional para o Azure Cosmos DB.
Dica
O Azure Cosmos DB limita o tamanho da solicitação única para 2MB. A fórmula é Tamanho da Solicitação = Tamanho Único do Documento * Tamanho do Lote de Gravação. Se você digitar o erro dizendo "O tamanho da solicitação é muito grande", reduza o writeBatchSizevalor na configuração do coletor de cópia.
Se você usar a origem do tipo "DocumentDbCollectionSink", ainda terá suporte como está para compatibilidade com versões anteriores. É recomendável usar o novo modelo no futuro, pois ele fornece recursos mais avançados para copiar dados do Azure Cosmos DB.
Exemplo
"activities":[
{
"name": "CopyToCosmosDBSQLAPI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "CosmosDbSqlApiSink",
"writeBehavior": "upsert"
}
}
}
]
Mapeamento de esquema
Para copiar dados do Azure Cosmos DB para o coletor tabular ou revertido, confira o mapeamento de esquema.
Propriedades do fluxo de dados de mapeamento
Ao transformar dados no fluxo de dados de mapeamento, você pode ler e gravar em coleções do Azure Cosmos DB. Para obter mais informações, confira transformação de origem e transformação do coletor nos fluxos de dados de mapeamento.
Observação
Não há suporte para o Azure Cosmos DB sem servidor no fluxo de dados de mapeamento.
Transformação de origem
As configurações específicas para o Azure Cosmos DB estão disponíveis na guia Opções de Origem da transformação de origem.
Incluir colunas do sistema: se verdadeiro, id, _ts e outras colunas do sistema serão incluídas nos metadados do fluxo de dados do Azure Cosmos DB. Ao atualizar as coleções, é importante incluí-las para que você possa obter a ID de linha existente.
Tamanho da página: o número de documentos por página do resultado da consulta. O padrão é "-1", que usa a página dinâmica do serviço até 1.000.
Taxa de transferência: defina um valor opcional para o número de RUs que você gostaria de aplicar à sua coleção do Azure Cosmos DB para cada execução desse fluxo de dados durante a operação de leitura. O mínimo é 400.
Regiões preferenciais: escolha as regiões de leitura preferenciais para esse processo.
Feed de alterações: se true, você obterá dados do feed de alterações do Azure Cosmos DB, que é um registro persistente de alterações em um contêiner na ordem em que ocorrem, desde a última execução automática. Ao definir como verdadeiro, não defina Inferir tipos de coluna com descompassos e Permitir o descompasso de esquema como verdadeiro ao mesmo tempo. Para obter mais detalhes, confira Feed de alterações do Azure Cosmos DB.
Começar do início (versão prévia): se verdadeiro, você obterá a carga inicial de dados de instantâneo completos na primeira execução, seguida pela captura de dados alterados nas próximas execuções. Se falso, a carga inicial será ignorada na primeira sequência, seguida pela captura de dados alterados nas próximas execuções. A configuração é alinhada com o mesmo nome de configuração na referência do Azure Cosmos DB. Para obter mais detalhes, confira Feed de alterações do Azure Cosmos DB.
Transformação de coletor
As configurações específicas para o Azure Cosmos DB estão disponíveis na guia Configurações da transformação de coletor.
Método Update: determina quais operações são permitidas no destino do banco de dados. O padrão é permitir apenas inserções. Para atualizar, fazer upsert ou excluir linhas, uma transformação alter-row é necessária para marcar as linhas para essas ações. Para atualizações, upserts e exclusões, é necessário selecionar uma coluna de chave ou colunas para determinar qual linha alterar.
Ação de coleção: determina se a coleção de destino será recriada antes da gravação.
- Nenhuma: nenhuma ação será feita na coleção.
- Recriar: a coleção será descartada e recriada
Tamanho do lote: um número inteiro que representa quantos objetos estão sendo gravados na coleção do Azure Cosmos DB em cada lote. Normalmente, iniciar do tamanho do lote padrão é suficiente. Para ajustar esse valor, observe:
- O Azure Cosmos DB limita o tamanho da solicitação única para 2MB. A fórmula é “Tamanho da solicitação = Tamanho do documento único * Tamanho do lote”. Se você encontrar um erro dizendo "O tamanho da solicitação é muito grande", reduza o valor do tamanho do lote.
- Quanto maior for o tamanho do lote, melhor será a taxa de transferência do serviço. Certifique-se de alocar RUs suficientes para capacitar sua carga de trabalho.
Chave de partição: insira uma cadeia de caracteres que represente a chave de partição para sua coleção. Exemplo: /movies/title
Taxa de transferência: defina um valor opcional para o número de RUs que você gostaria de aplicar à sua coleção do Azure Cosmos DB para cada execução desse fluxo de dados. O mínimo é 400.
Orçamento de taxa de transferência de gravação: um inteiro que representa os RUs que você deseja alocar para essa operação de gravação de Fluxo de Dados, fora da taxa de transferência total alocada para a coleção.
Observação
Para limitar o uso de RU, defina a Taxa de transferência (dimensionamento automático) do Cosmos DB para Manual.
Pesquisar propriedades de atividade
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Importar ou exportar documentos JSON
Use esse conector do Azure Cosmos DB for NoSQL para facilmente:
- Copiar documentos entre duas coleções do Azure Cosmos DB no estado em que se encontram.
- Importar documentos JSON de várias fontes para o Azure Cosmos DB, incluindo o Armazenamento de Blobs do Azure, o Azure Data Lake Storage e outros repositórios baseados em arquivo compatíveis com o serviço.
- Exportar documentos JSON de uma coleção do Azure Cosmos DB para vários repositórios baseados em arquivo.
Para obter uma cópia independente de esquema:
- Ao usar a ferramenta Copiar Dados, selecione a opção Exportar no estado em que se encontra para arquivos JSON ou uma coleção do Azure Cosmos DB.
- Ao usar a criação de atividade, escolha o formato JSON com o repositório de arquivos correspondente para a origem ou o coletor.
Migrar do banco de dados relacional para o Azure Cosmos DB
Ao migrar de um banco de dados relacional, por exemplo, SQL Server para Azure Cosmos DB, a atividade de cópia pode facilmente mapear dados tabulares de documentos JSON de origem para mesclar no Azure Cosmos DB. Em alguns casos, talvez você queira recriar o modelo de dados para otimizá-lo para os casos de uso NoSQL de acordo com Modelagem de dados no Azure Cosmos DB, por exemplo, para desnormalizar os dados inserindo todos os subitens relacionados em um único documento JSON. Nesse caso, confira este artigo com um passo a passo sobre como fazer isso usando a atividade de cópia.
Feed de alterações do Azure Cosmos DB
O Azure Data Factory pode obter dados do feed de alterações do Azure Cosmos DB habilitando-os na transformação de fonte de fluxo de dados de mapeamento. Com essa opção de conector, você pode ler feeds de alterações e aplicar transformações antes de carregar dados transformados nos conjuntos de dados de destino de sua escolha. Você não precisa usar as funções do Azure para ler o feed de alterações e depois escrever transformações personalizadas. Você pode usar essa opção para transferir dados de um contêiner para outro, preparar exibições de material controladas por feed de alterações para fins de ajuste ou automatizar o backup ou a recuperação de contêiner com base no feed de alterações e habilitar muitos outros casos de uso a partir da funcionalidade visual de arrastar e soltar do Azure Data Factory.
Mantenha o pipeline e o nome da atividade inalterados para que o ponto de verificação possa ser registrado pelo ADF para que você receba automaticamente os dados alterados da última execução. Se você alterar o nome do pipeline ou da atividade, o ponto de verificação será redefinido, o que fará com que você comece do início ou receba alterações a partir de agora na próxima execução.
Ao depurar o pipeline, esse recurso funcionará da mesma forma. Tenha em mente que o ponto de verificação será redefinido quando você atualizar o navegador durante a execução da depuração. Depois que estiver satisfeito com o resultado do pipeline da sequência de depuração, você poderá publicar e disparar o pipeline. Ao disparar pela primeira vez o pipeline publicado, ele será reiniciado automaticamente do início ou passará a obter alterações desse momento em diante.
Na seção de monitoramento, sempre existe a possibilidade de reexecutar um pipeline. Ao fazer isso, os dados alterados sempre serão capturados do ponto de verificação anterior da sua versão de pipeline selecionada.
Além disso, o repositório analítico do Azure Cosmos DB agora dá suporte à captura de dados de alterações (CDC) da API do Azure Cosmos DB for NoSQL e da API do Azure Cosmos DB for Mongo DB (pré-visualização pública). O repositório analítico do Azure Cosmos DB permite que você consuma com eficiência um feed contínuo e incremental de dados alterados (inseridos, atualizados e excluídos) do repositório analítico.
Conteúdo relacionado
Para obter uma lista de armazenamentos de dados aos quais a atividade Copy oferece suporte, como fontes e coletores, consulte Armazenamentos de dados compatíveis.