Migrar dados relacionais um-para-poucos para uma conta do Azure Cosmos DB for NoSQL
APLICA-SE A: ![]() NoSQL
NoSQL
Para migrar de um banco de dados relacional para o Azure Cosmos DB for NoSQL, pode ser necessário fazer alterações no modelo de dados para otimização.
Uma transformação comum é a desnormalização de dados inserindo subitens relacionados em um documento JSON. Aqui, vamos examinar algumas opções para isso usando o Azure Data Factory ou o Azure Databricks. Para obter mais informações sobre a modelagem de dados no Azure Cosmos DB, confira Modelagem de dados no Azure Cosmos DB.
Cenário de Exemplo
Suponha que tenhamos as duas tabelas a seguir em nosso banco de dados SQL, Orders e OrderDetails.

Queremos combinar essa relação de um para poucos em um documento JSON durante a migração. Para criar um documento individual, crie uma consulta T-SQL usando FOR JSON:
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
Os resultados dessa consulta incluem dados da tabela Orders:

O ideal é que você use uma única atividade de cópia do Azure Data Factory (ADF) para consultar os dados do SQL como a origem e gravar a saída diretamente no coletor do Azure Cosmos DB como objetos JSON. Atualmente, não é possível executar a transformação JSON necessária em uma atividade de cópia. Se tentarmos copiar os resultados da consulta acima para um contêiner do Azure Cosmos DB for NoSQL, veremos o campo OrderDetails como uma propriedade de cadeia de caracteres do documento, em vez da matriz JSON esperada.
Podemos solucionar essa limitação atual de uma das seguintes maneiras:
- Usar o Azure Data Factory com duas atividades de cópia:
- Obtenha os dados formatados em JSON do SQL para um arquivo de texto em um local de armazenamento de blob intermediário
- Carregue os dados do arquivo de texto JSON em um contêiner no Azure Cosmos DB.
- Use o Azure Databricks para fazer leituras no SQL e gravações no Azure Cosmos DB – Apresentaremos duas opções aqui.
Vamos examinar essas abordagens mais detalhadamente:
Fábrica de dados do Azure
Embora não seja possível inserir OrderDetails como uma matriz JSON no documento do Azure Cosmos DB de destino, podemos contornar o problema usando duas atividades Copy separadas.
Copy Activity #1: SqlJsonToBlobText
Para os dados de origem, usamos uma consulta SQL para obter o conjunto de resultados como uma única coluna com um objeto JSON (representando a coluna Order) por linha usando os recursos OPENJSON e FOR JSON PATH do SQL Server:
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)

Para o coletor da atividade de cópia SqlJsonToBlobText, escolhemos “Texto Delimitado” e o apontamos para uma pasta específica no Armazenamento de Blobs do Azure. Esse coletor inclui um nome de arquivo exclusivo gerado dinamicamente (por exemplo, @concat(pipeline().RunId,'.json').
Como nosso arquivo de texto não é realmente "delimitado" e não queremos que ele seja analisado em colunas separadas usando vírgulas. Também queremos preservar as aspas duplas ("), definimos "Delimitador de coluna" como uma Tabulação ("\t") ou outro caractere que não ocorre nos dados e "Caractere de aspas" como "Nenhum caractere de aspas".

Copy Activity #2: BlobJsonToCosmos
Em seguida, modificamos o pipeline do ADF adicionando a segunda atividade Copy que procura no Armazenamento de Blobs do Azure o arquivo de texto criado pela primeira atividade. Ele o processa como origem “JSON” para inserir no coletor do Azure Cosmos DB como um documento por linha JSON encontrado no arquivo de texto.

Opcionalmente, também adicionamos uma atividade “Excluir” ao pipeline para que ele exclua todos os arquivos anteriores restantes na pasta /Orders/ antes de cada execução. Nosso pipeline do ADF agora é semelhante a este:

Depois de disparar o pipeline mencionado anteriormente, vemos um arquivo criado em nosso local intermediário do Armazenamento de Blobs do Azure que contém um objeto JSON por linha:

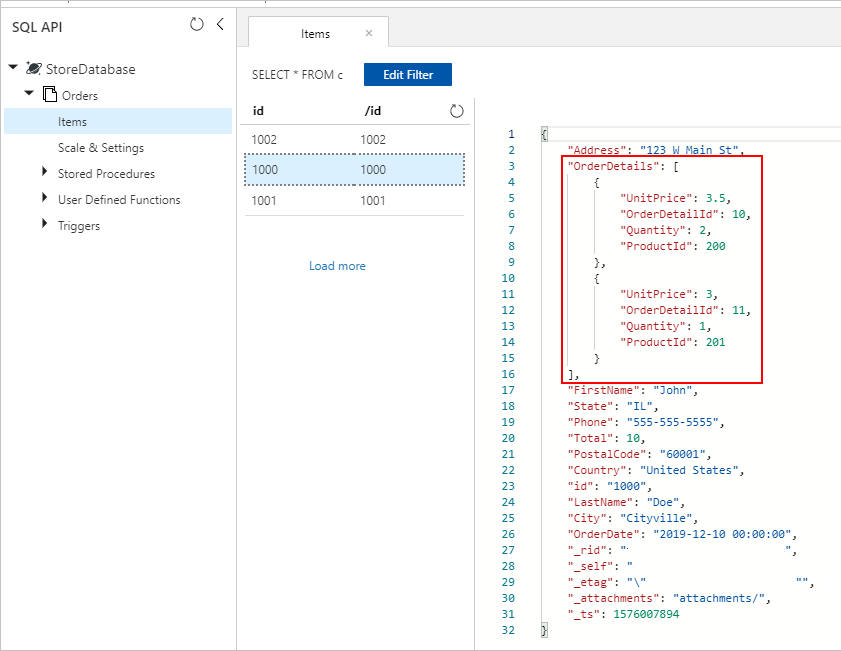
Também vemos documentos as pasta Orders com OrderDetails corretamente inserido em nossa coleção do Azure Cosmos DB:

Azure Databricks
Também podemos usar o Spark no Azure Databricks para copiar os dados de nossa origem do Banco do Dados SQL para o destino do Azure Cosmos DB sem criar os arquivos de texto/JSON intermediários no Armazenamento de Blobs do Azure.
Observação
Para fins de clareza e simplicidade, os snippets de código incluem senhas do banco de dados fictícias explicitamente embutidas, mas o ideal é que você use os segredos do Azure Databricks.
Primeiro, criamos e anexamos as bibliotecas do Conector do SQL e do Conector do Azure Cosmos DB ao nosso cluster de Azure Databricks. Reinicie o cluster para garantir que as bibliotecas sejam carregadas.

Em seguida, apresentamos dois exemplos, para Scala e Python.
Scala
Aqui, obtemos os resultados da consulta SQL com a saída “FOR JSON” em um DataFrame:
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)

Em seguida, nos conectamos ao nosso banco de dados e coleção do Azure Cosmos DB:
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
Por fim, definimos nosso esquema e usamos from_json para aplicar o DataFrame antes de salvá-lo na coleção do Cosmos DB.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)

Python
Como uma abordagem alternativa, talvez seja necessário executar transformações JSON no Spark se o banco de dados de origem não der suporte a FOR JSON ou a uma operação semelhante. Como alternativa, você pode usar operações paralelas para um conjunto de dados grande. Aqui, apresentamos um exemplo do PySpark. Comece configurando as conexões do banco de dados de origem e de destino na primeira célula:
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Em seguida, consultamos o banco de dados de origem (neste caso, o SQL Server) para os registros do pedido e de detalhe do pedido, colocando os resultados em Dataframes do Spark. Também criamos uma lista que contém todas as IDs dos pedidos e um pool de threads para operações paralelas:
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Em seguida, crie uma função para gravar os pedidos na API de destino para a coleção NoSQL. Essa função filtra todos os detalhes do pedido para a ID de pedido fornecida, converte-os em uma matriz JSON e insere a matriz em um documento JSON. Em seguida, o documento JSON é gravado no contêiner da API de destino para NoSQL para essa ordem:
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#https://learn.microsoft.com/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Por fim, chamamos a função writeOrder do Python usando uma função de mapa no pool de threads, para execução em paralelo, transmitindo a lista de IDs de pedidos que criamos anteriormente:
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
Em qualquer abordagem, no final, devemos receber OrderDetails inserido corretamente em cada documento Order na coleção do Azure Cosmos DB:
Próximas etapas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de